Command Palette
Search for a command to run...
マルチティンバーのミキシングとクローン作成を3秒で実現! F5/E2 TTS チュートリアルがオンラインになり、心理カウンセラーの言語スタイルを正確にシミュレートする PsyDTCorpus 5k 心理対話データ セットがリリースされました。

音声クローンの急速な発展の波の中で、AI はますます現実的な人間の音声効果をシミュレートできるようになりましたが、ゼロサンプル学習とマルチ感情制御にはまだ多くの課題があります。
今年の初めに、E2 TTS は、テキスト入力を入力音声と同じ長さまでパディング マーカーでパディングし、ノイズ除去を実行して音声を生成する、単純化されたテキスト読み上げ生成メソッドを実装しました。最近、F5 TTS はこの手法を参照し、フロー マッチングの非自己回帰生成手法に基づいてモデルのパフォーマンスをさらに向上させ、多言語合成をサポートするだけでなく、言語に応じて感情や話す速度を調整します。テキストコンテンツを強化し、長いテキストをより繊細かつスムーズに音声合成します。
F5 TTS、E2 TTSの発音効果を皆様に体感していただくために、F5/E2 TTS 統合チュートリアルは、現在 hyper.ai 公式 Web サイトでオンラインで公開されており、ワンクリックのクローン作成で体験できます。
オンラインで実行:https://go.hyper.ai/SZxqv
11 月 4 日から 11 月 8 日までの hyper.ai 公式 Web サイトの更新の概要:
* 高品質の公開データセット: 10
* 高品質なチュートリアルのセレクション: 3
* コミュニティ記事選択: 4 記事
* 人気のある百科事典のエントリ: 5
※11月提出締切:6日
公式ウェブサイトにアクセスしてください: hyper.ai
公開データセットの選択
1. 髪のタイプのデータセット 髪のタイプのデータセット
Hair Type Dataset は、さまざまなヘアスタイルを分類するために使用される画像データセットです。ストレート、ウェーブ、カーリー、ドレッドヘアの 4 種類のヘアスタイル (合計 1,992 枚) の高品質の画像が含まれています。このデータセットは、髪のタイプを識別して分類するための機械学習モデルをトレーニングするのに役立ちます。
直接使用します:https://go.hyper.ai/aXYcj

2. AllClear パブリック クラウド削除データセット
AllClear データセットは現在最大のパブリック クラウド除去データセットであり、世界中に分散された 23,742 の関心領域 (ROI) を含み、多様な土地利用パターンをカバーし、合計 400 万枚の画像が含まれています。これは、雲除去研究におけるベンチマークと多様なトレーニング データの不足の問題に対処します。
直接使用します:https://go.hyper.ai/e2BYC

3. ムハラフ氏手書きのアラビア語データセット
Muharaf データセットは、手書きのアラビア語認識に焦点を当てた機械学習データセットです。このデータセットには、アラビア語の専門家によって転写された歴史的な手書きのページの 1.6k 以上の画像が含まれています。各ドキュメント画像には、そのテキスト行の空間ポリゴン座標と、基礎となるページ要素に関する情報が伴います。
直接使用します:https://go.hyper.ai/NN2UR
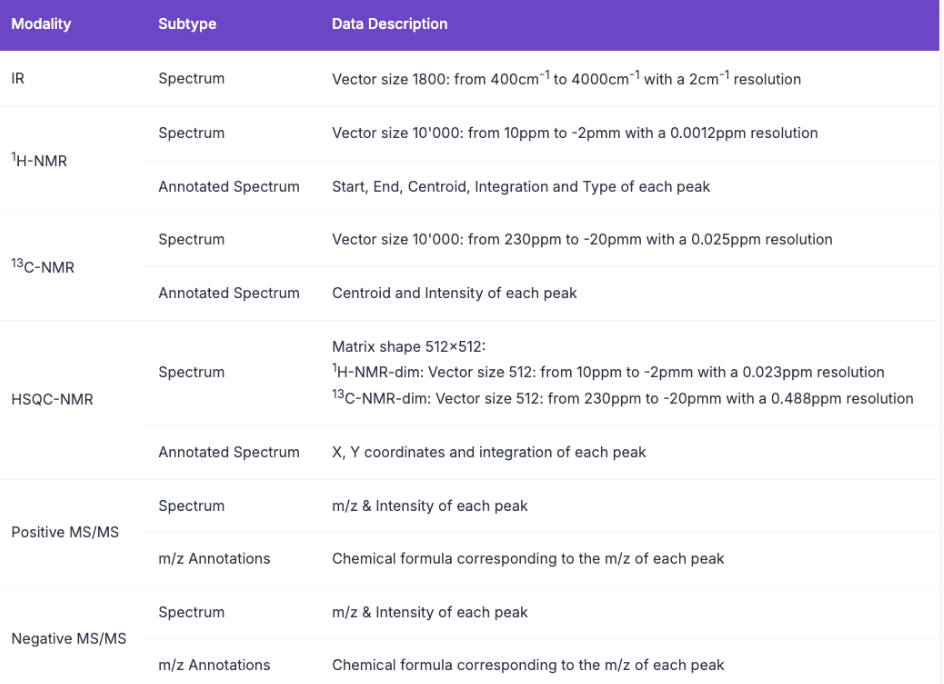
4. マルチモーダル分光化学マルチモードスペクトルデータセット
このデータセットには、特許データの化学反応から抽出された 790,000 個の分子のシミュレートされた 1H-NMR、13C-NMR、HSQC-NMR、赤外および質量分析 (正イオンおよび負イオン モード) のスペクトル データが含まれています。複数のスペクトルモダリティからの情報を統合し、人間の専門家が分子構造を分析するために使用する方法をシミュレートできます。これにより、構造分析が自動化され、合成から構造決定に至る分子発見プロセスが簡素化されることが期待されます。
直接使用します:https://go.hyper.ai/Z7zlr
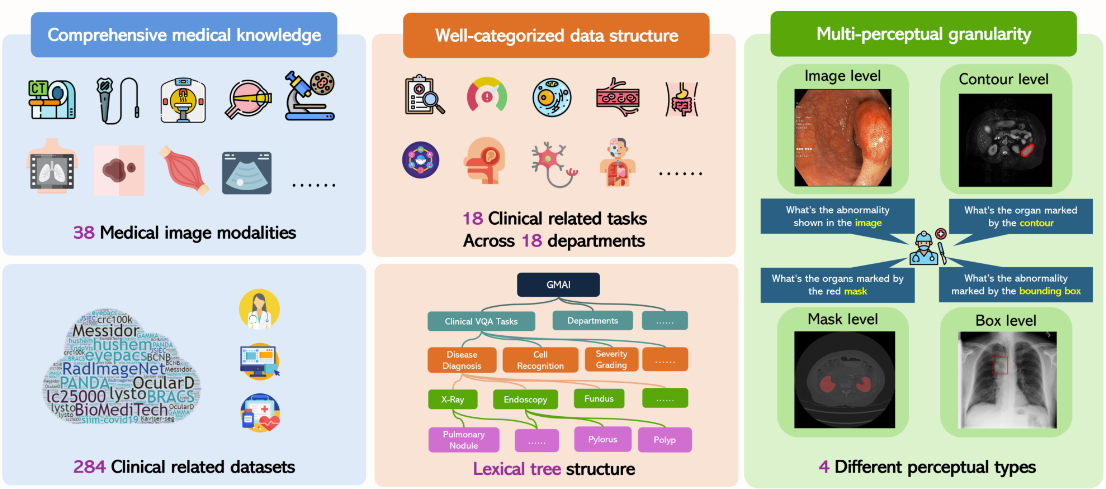
5. GMAI-MMBench 医療複合評価ベンチマーク データセット
GMAI-MMBench は、一般的な医療用人工知能の分野を進歩させるために設計されたマルチモーダル評価ベンチマークです。これには、18 の異なる診療科をカバーする 38 の医用画像モダリティと 18 の臨床関連タスクを含む、さまざまなソースからの 284 のデータセットが含まれており、複数のことから学ぶために 4 つの異なる知覚粒度で評価されます。LVLM のパフォーマンスは、いくつかの次元で考慮されます。
直接使用します:https://go.hyper.ai/FL799
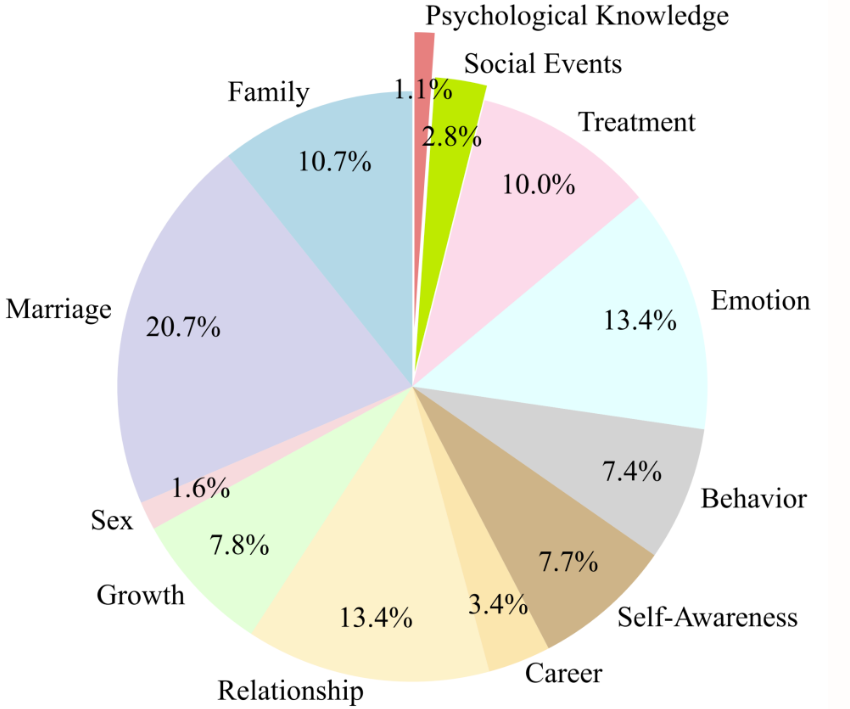
6. PsyDTCorpus 心理カウンセラーのデジタル ツイン データ セット
PsyDTCorpus データセットの中核的な目標は、特定の心理カウンセラーの言語スタイルとカウンセリング技術をシミュレートして、心理カウンセラーの大規模なデジタル ツイン モデルである SoulChat2.0 の開発とトレーニングをサポートすることです。このデータ セットには、カウンセラーの言語スタイルと治療技術の適用を含む、5,000 の高品質のメンタルヘルス会話データが含まれています。
直接使用します:https://go.hyper.ai/hGi4O
7. GTSinger 歌唱音声データセット
このデータ セットは、大規模なオープンソースの高品質歌唱データ セットで、20 名のプロの歌手が歌った、スタジオで録音された 80.59 時間の歌声が含まれており、中国語、英語、日本語、韓国語などを含む 9 か国語をカバーしています。 、音色とスタイルの非常に豊富なリソース ライブラリを研究者に提供します。
直接使用します:https://go.hyper.ai/wBcBz
8. OC22 触媒シミュレーション データセット
このデータ セットは、触媒シミュレーション データ セット、つまり Open Catalyst 2022 (OC22) データセットです。このデータ セットは、より複雑な触媒構造と新しい反応タイプを含む、OC20 データ セットに基づいて拡張および補足され、より豊富なデータが提供されます。 AI モデルのトレーニングとテストに使用されます。
直接使用します:https://go.hyper.ai/M8Cpn
9. OQMD オープンソース量子材料データセット
OQMD データセットには、密度汎関数理論 (DFT) を通じて計算された 122 万を超える材料の熱力学的特性と構造特性が含まれています。データセット内のデータは、約 300,000 の化合物の DFT 総エネルギー計算と一般的な結晶構造の修飾を含む、無機結晶構造データベース (ICSD) から取得されています。
直接使用します:https://go.hyper.ai/dGOKs
10. Materials Project のオンライン材料データベース
Materials Project データベースのデータには、結晶構造とエネルギー特性に加え、電子構造と熱力学特性に関する詳細情報が含まれています。このデータセットは、ハイスループットの第一原理計算を使用して 100 万を超える無機材料の包括的な性能データ、構造情報、計算シミュレーション結果を提供することにより、新材料の発見と革新を加速するように設計されています。
直接使用します:https://go.hyper.ai/tGIVs
その他の公開データセットについては、次のサイトをご覧ください。:
選択された公開チュートリアル
1. AnyText 多言語ビジュアル テキストの生成と編集
AnyText は、多言語ビジュアル テキストの生成および編集モデルです。中国語、英語、日本語、韓国語などの言語でのテキスト生成をサポートし、入力画像内のテキスト コンテンツの編集もサポートします。このモデルに含まれるテキスト生成テクノロジは、電子商取引ポスター、ロゴ デザイン、創造的な落書き、絵文字などの新しい AIGC アプリケーションの可能性を提供します。
以下のリンクをクリックし、チュートリアルの手順に従ってコンテナーを複製して起動すると、創造力を発揮してイメージをデザインできます。
オンラインで実行:https://go.hyper.ai/uMcNa
2. F5/E2 TTS わずか 3 秒であらゆるサウンドのクローンを作成
このチュートリアルには、F5 TTS と E2 TTS の 2 つのモデルのデモ使用が含まれています。 F5 TTS は、追加の監視なしでゼロショット学習を通じて、自然でスムーズかつ忠実な音声を迅速に生成できます。 E2 TTS は音声シーケンス全体を一度に生成できるため、高品質の音声出力を維持しながら生成速度が大幅に向上します。
このプロジェクトでは、Gradio インターフェイスを通じてフロントエンドのインタラクティブ インターフェイスを生成でき、関連するモデルと依存関係がデプロイされており、ワンクリックでサウンドのクローン作成を体験できます。
オンラインで実行:https://go.hyper.ai/SZxqv
Stable Diffusion 3.5 Large モデルは、画質、タイポグラフィ、複雑で迅速な理解、およびリソース効率の大幅な向上を特徴とするマルチモーダル拡散ジェネレーター (MMDiT) テキスト生成画像モデルであり、80 億のパラメーターという大規模なスケールにより、プロ レベルの画像生成機能を提供します。 、特に高解像度の画像生成のニーズに適しています。
このチュートリアルでは環境がデプロイされており、チュートリアルのガイドラインに従って高解像度の画像を直接生成できます。
オンラインで実行:https://go.hyper.ai/w5k5V

💡安定拡散チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] にメモし、グループに参加してさまざまな技術的な問題について話し合い、アプリケーションの効果を共有してください。

注目のコミュニティ記事
1. 元素の周期表をほぼカバーしています。 Meta が 1 億 1,000 万件の DFT 計算結果を含むオープンソースの OMat24 データセットをリリース
最近、Meta は Open Materials 2024 大規模なオープンソース データ セットとサポートする事前トレーニング済みモデルのセットをリリースしました。その中で、OMat24 データセットには、構造的および組成的多様性に焦点を当てた 1 億 1,000 万件を超える密度汎関数理論の計算結果が含まれています。データセットは現在、HyperAI 公式 Web サイトでオンラインになっています。この記事は研究論文の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/3wP7R
2. 活動レビュー丨上海交通大学/浙江大学/清華大学/OpenBayes 医療/地理情報/都市複合システム/科学研究の新たなパラダイムをカバーする多くの専門家
COSCon'24 の期間中、HyperAI は共同制作コミュニティとして、科学のための AI の方向に向けたオープンソース AI フォーラムを開催しました。上海交通大学、浙江大学、清華大学、オープンベイズ ベイジアン コンピューティングの専門家や学者は、医療用人工知能、地理情報人工知能、科学研究用インテリジェント コンピューティング クラウド プラットフォーム、および AI 主導の都市に関するさまざまな側面から詳細な研究を実施しました。複雑なシステムを共有します。この記事はフォーラムのハイライトをレビューしたものです。詳細なレポートについてはここをクリックしてください。
イベントの概要を確認してください:https://go.hyper.ai/s2RQU
3. NVIDIAより二度目の出資を受けました! AI 製薬会社 Terray が世界最大の化学データセットを構築するために 1 億 2,000 万米ドルの資金調達を完了
AI 製薬会社 Terray Therapeutics は、1 億 2,000 万ドルのシリーズ B ラウンドを完了しました。この資金調達ラウンドは、NVIDIA のベンチャー キャピタル部門 NVentures と新規投資家 Bedford Ridge Capital によって主導されました。これは、NVIDIA による Terray への 2 回目の投資です。同社はまた、世界最大の化学データセットを構築し、AI と湿式実験を組み合わせてデータ側で閉ループを形成しました。クリックすると詳細な説明が表示されます。
レポート全体を表示します。https://go.hyper.ai/AWojF
4. うつ病の初期スクリーニングにご協力ください!上海交通大学のチームがエージェント心理クリニックを構築 この論文の最初の論文はデモとしてオンラインで公開され、技術的なハイライトが共有されています。
生放送「Meet AI4S」シリーズの第 4 話では、上海交通大学クロスメディア言語知能研究室の Lan Kunyao 博士が「AI4S に基づくメンタルヘルス相談と相談プラットフォーム」というタイトルで心理クリニックについて詳しく紹介しました。この記事は、インテリジェント心理クリニックのデモを含む講演の要旨を書き起こしたものです。クリックするとすぐにご覧いただけます。
レポート全体を表示します。https://go.hyper.ai/CHhKC
人気のある百科事典の項目を厳選
1. トランスモデル
2. 変分オートエンコーダ VAE
3. 人工ニューラルネットワーク NN
4. パレートフロント パレートフロント
5. 大規模マルチタスク言語理解MMLU
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。

主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
* 1,300 を超える公開データセットに対して国内の高速ダウンロード ノードを提供
* 400 以上の古典的で人気のあるオンライン チュートリアルが含まれています
* 100 以上の AI4Science 論文ケースを解釈
* 500 以上の関連用語クエリをサポート
*Apache TVM の最初の完全な中国語ドキュメントを中国でホストします
学習の旅を始めるには、公式 Web サイトにアクセスしてください。
最後に、「クリエイター インセンティブ プログラム」をおすすめします。興味のあるお友達はコードをスキャンして参加してください。









