Command Palette
Search for a command to run...
初め! 4 つの主要大学が共同で医薬品研究開発用の大規模言語モデル Y-Mol を立ち上げ、全体的なパフォーマンスが LLaMA2 をリード

ChatGPT、ChatGLM、LLaMA に代表される大規模な言語モデルは、数十億のパラメータを備えたこれらのモデルは、大規模なテキスト コーパスでの慎重なトレーニングを通じて、テキストの生成とコンテキストの理解において優れたパフォーマンスを実証しました。強力な機能。ただし、これらのモデルのほとんどは一般的なタスクでは良好に機能しますが、特定の特定の分野、特に医薬品開発ではかなりの課題に直面しています。
自然言語処理の分野とは異なり、医薬品の研究開発の分野には統一された標準パラダイムが存在せず、研究開発プロセスは複雑でコストがかかります。さらに、計算化学、構造生物学、バイオインフォマティクスなどの複数の分野も関係しており、関連データの入手が困難であり、医薬品関連エンティティ間の相互作用データに注釈を付けるには高度な専門知識が必要です。これらの要因により、医薬品の研究開発分野における大規模な言語モデルの適用が制限されます。
これに関して、湖南大学、中南大学、湖南師範大学、翔潭大学の研究チームは共同で、マルチスケールの生物医学知識ガイダンスのための大規模言語モデル Y-Mol を提案しました。 Y-Mol は、さまざまなテキスト コーパスや指示に合わせて微調整できる自己回帰配列間モデルであり、医薬品の研究開発におけるモデルのパフォーマンスと可能性を大幅に強化します。これは、大規模な言語モデルの利点です。医薬品の研究開発の分野で新たな進歩を遂げます。
この研究のタイトルは「Y-Mol: 医薬品開発のためのマルチスケール生物医学知識に導かれた大規模言語モデル」で、arxiv でプレプリントとして公開されています。
研究のハイライト:
* Y-Mol は、医薬品開発のために構築された大規模な言語モデルの最初の例です。
* Y-Mol は、マルチスケールの生物医学知識を統合することにより、情報豊富な指導データセットを構築します
※Y-Molは薬物間相互作用、薬物-標的相互作用、分子物性予測などにおいて優れた性能を有しており、様々な創薬課題の理解と汎用性において高い能力を発揮しています。

用紙のアドレス:
https://doi.org/10.48550/arXiv.2410.11550
公式アカウントをフォローし、バックグラウンドで「創薬研究開発ビッグモデル」に返信すると全文PDFが入手できます
オープンソース プロジェクト「awesome-ai4s」は、100 を超える AI4S 論文の解釈をまとめ、大規模なデータ セットとツールを提供します。
https://github.com/hyperai/awesome-ai4s
2 つの主要なタイプのデータセットを完全にマイニングし、包括的な生物医学コーパスを構築します
Y-Mol の事前トレーニング データセットの構築に関して、この研究では 2 種類のデータセットを選択しました。生物医学の PubMed 出版物からのテキスト コーパス。生物医学の知識グラフに基づいて構築された教師付きの指示と、専門家モデルから抽出された推論データ。
出版物の豊富な生物医学知識をさらに深く掘り下げるには、この研究では、PubMed などのオンライン出版プラットフォームから複数の分野をカバーする 3,300 万件以上の出版物を抽出して前処理しました。以下の図 A に示すように、研究者らは、コーパスの品質と関連性を確保するために、これらの出版物から目に見える要約と紹介文を生物医学テキスト データ (再構成テキスト) として抽出しました。
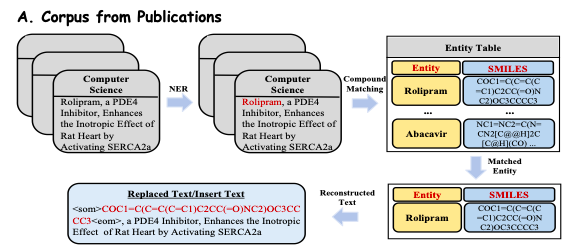
生物医学知識ベースからドメイン知識を効率的に抽出するために、この研究では知識ベース内の事実を自然言語プロンプトに変換します。以下の図 B に示すように、この研究では、サブグラフ内の各推論チェーン (Reasoning Chains) には明確なリレーショナル セマンティクスがあると考えられているため、各一貫したパス (Pathway) が抽出され、プロンプト コンテキストとして自然言語記述に変換されます。次に、この研究では、これらの構築されたコンテキストを、Y-Mol への入力として対応する質問と組み合わせて、教師付き回答を出力します。
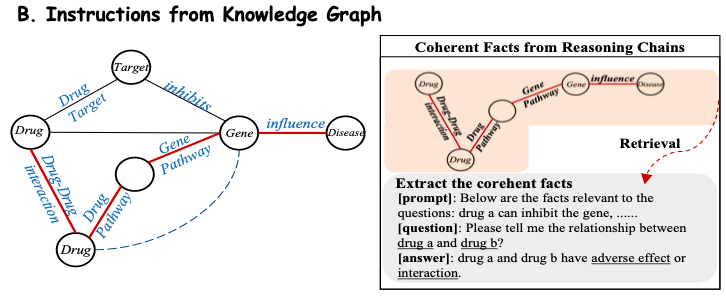
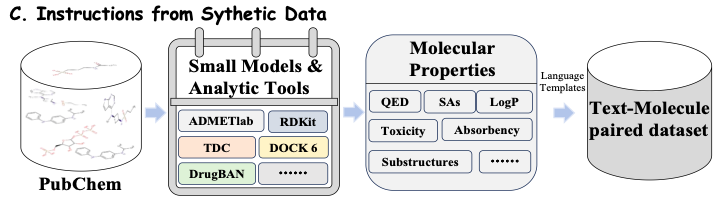
さらに、薬物の属性と領域知識に基づいて大規模な指示を取得するために、この研究では既存の小規模モデルの専門家による合成データを使用して指示を構築し、薬物知識スペクトルを Y-Mol に洗練します。最終的に、この研究では 1,120 万件のコーパス エントリと 230 万件の作成された命令が収集されました。
以下の図 C に示すように、特定の薬物分子について、より包括的な分子特性 (分子特性) を抽出するために、この研究では、ADMETlab、RDKit、TDC、DrugBAN などの一連の高度な分子ツールと計算モデルが統合されました。これらのツールとモデルは、QED、SA、LogP、毒性、吸収性、部分構造などを含む、公開されているデータセットからさまざまな特性を持つ分子情報を抽出します。このようにして、研究では最新のモデルとツールを継続的に統合し、その予測データを使用してモデルをトレーニングすることができるため、Y-Mol はリアルタイムで進化し、医薬品の研究開発における主導的地位を維持することができます。
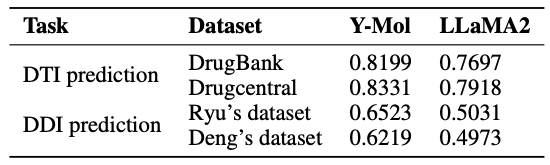
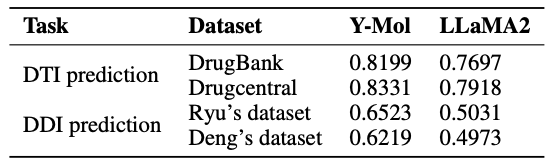
最後に、下の図に示すように、この研究では、事前トレーニング段階と教師付き微調整段階におけるさまざまなタスクに対する Y-Mol のデータ分布を示しています。推論能力の評価に関しては、薬物標的相互作用(DTI)予測および薬物間相互作用(DDI)予測におけるY-Molの性能を総合的にテストするために、研究チームは、DTI 予測を行うために、業界で広く認知されているベンチマーク データ セット DrugBank と DrugCentral を選択しました。
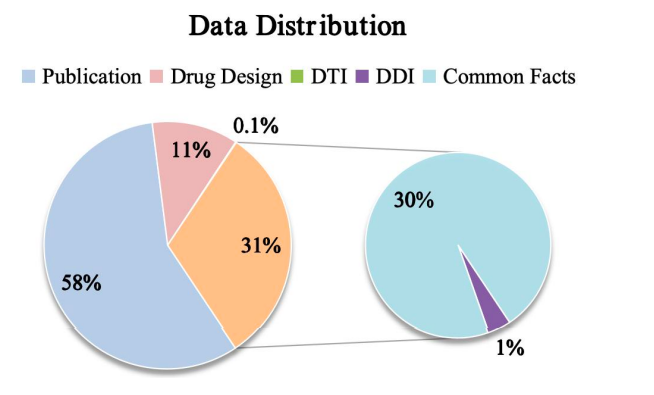
同時に、DDI 予測のパフォーマンスを評価するために、研究者らは Ryu 氏と Deng 氏が提供したデータセットを使用しました。これらの評価方法は、Y-Mol が医薬品開発分野の業界標準に基づいて公平かつ包括的に試験され、その有効性が証明されることを保証するために慎重に選択されています。
Ryu のデータセット: https://doi.org/10.1073/pnas.1803294115
鄧小平のデータセット: https://doi.org/10.1093/bioinformatics/btaa501
Y-Mol: LLaMA2-7b をベースとし、医薬品開発に特化
この研究では、医薬品の研究開発に特化した高度なトレーニングと推論フレームワークを構築するための基本的な大規模言語モデルとして LLaMA2-7b を選択しました - Y-Mol。以下の図に示すように、Y-Mol の開発は 2 つの主要な段階に分かれていました。
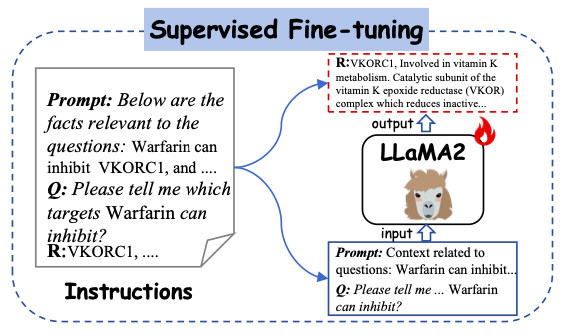
初め、Y-Mol は生物医学出版物の大規模コーパスで事前トレーニングされており、自己教師付き事前トレーニングを通じて LLaMA2 を微調整することで、Y-Mol が医薬品開発の背景知識の基本を把握できるようにします。それから、LLaMA2 をさらに監視し、医薬品関連のドメイン知識と専門家の合成データを微調整に使用します。このプロセスにより、大量の薬物関連情報が Y-Mol に入力され、薬物開発プロセスにおける相互作用メカニズムに対するモデルの理解が強化されます。
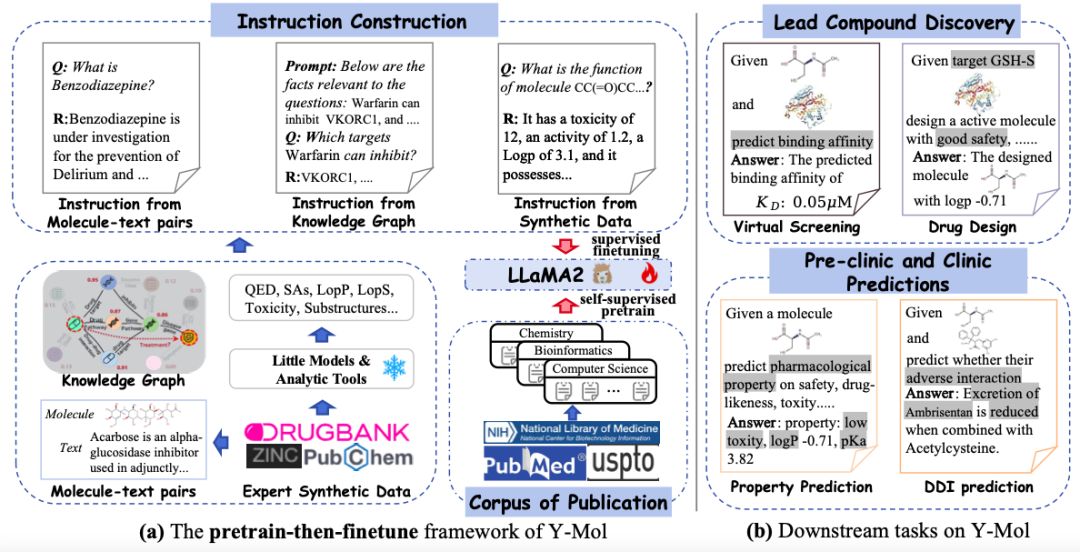
この研究では、Y-Mol を微調整するためのさまざまな指示が注意深く設計されています。これらの指示には、分子テキストペアからの指示と薬物データベースから抽出された説明が含まれており、これらの説明は薬物の特性、構造、機能を形式で示しています。自然言語の豊富な意味情報が含まれており、薬物実体の認識において人間と大規模な言語モデルの間の一貫性を強化するのに役立ちます。
本研究では、下図に示すように、生成された命令を教師あり学習の入力としてY-Molに入力します。具体的には、構築されたプロンプト コンテキストと質問が Y-Mol に入力され、これらの構築された回答はモデルによって生成された出力を監視するために使用されます。
これらの生成された指示に基づいて Y-Mol を慎重に微調整した後、研究者らはそれを、リード化合物の発見から前臨床および臨床予測に至るまで、さまざまな下流タスクに適用しました。この教師あり微調整メソッドを通じて、Y-Mol は医薬品開発における複雑な問題をより正確に理解して処理できるようになり、コンピューター支援医薬品開発のための強力なツールを提供します。
研究結果:Y-Molが最高の予測性能を発揮
医薬品の研究開発分野におけるY-Molの有効性を包括的に検証するために、この研究では、リード化合物の発見(リード化合物発見)、前臨床研究(前臨床)などのさまざまな段階をカバーする一連の実験を慎重に設計しました。 ) および臨床予測 (臨床予測) タスク。具体的には、さまざまな重要なタスクは次のとおりです。(1) リード化合物発見のための仮想スクリーニングと薬剤設計、(2) 前臨床段階での発見されたリード化合物の物理的および化学的特性の予測、(3) 臨床段階の予測。潜在的な薬物有害事象。
バーチャル上映では、未知の薬物と標的の相互作用ペアを同定することは重要です。以下の表に示すように、LLaMA2 と比較して、DrugBank および DrugCentral データセット上の Y-Mol の AUC スコアは、それぞれ 5.02% および 4.13% 増加しました。これは、Y-Mol がマルチスケール データ ソースの DTI 予測で優れたパフォーマンスを発揮し、仮想スクリーニングにおける優れたパフォーマンスを証明していることを示しています。
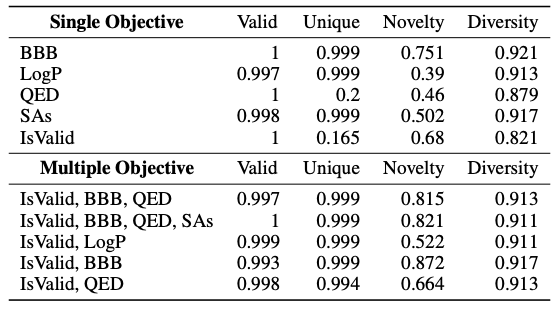
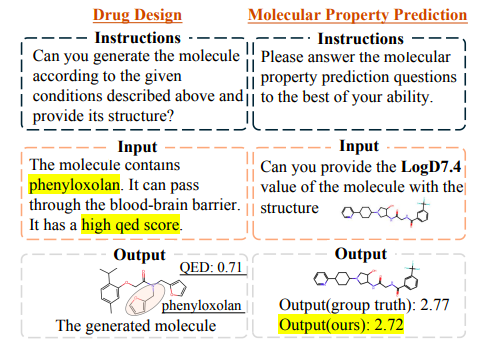
ドラッグデザインでは、新しいリード化合物を発見する際の Y-Mol のパフォーマンスを検証するために、この研究では、特定の条件に対して効果的な化合物を生成するタスクも設計しました。つまり、ターゲット条件と記述クエリが与えられた場合、Y-Mol が有効な化合物を生成できるかどうかを評価します。コンテキスト情報から化合物を生成し、対応する SMILES 配列分子を正確に生成します。
以下の表に示すように、この調査では、BBB や LogP などのさまざまな単一目標 (単一目標) を予測するために、有効性、独自性、新規性、多様性などの標準指標が導入されています。結果は、Y-Mol が全体的なパフォーマンスに優れていることを示しています。対照的に、LLaMA2-7b モデルのみがドメイン適応性が低く、有効な分子を生成できないことがわかります。同時に、この研究では複数の目的(複数の目的)の下で Y-Mol の薬剤設計パフォーマンスもテストされました。この場合、Y-Mol も良好なパフォーマンスを発揮することがわかりました。
分子物性予測では、以下の図に示すように、Y-Mol はすべてのタスクにおいて LLaMA2 よりも低い R² スコアを示し、Y-Mol が物理的および化学的特性の予測においてより強い一般化能力を持っていることを示しています。
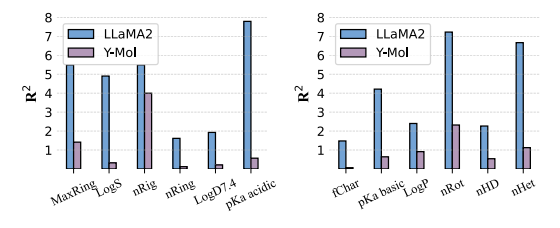
医薬品開発の臨床段階では、潜在的な薬物間相互作用を予測することが、医薬品の安全な使用を確保するための鍵となります。以下に示すように、Y-Mol は潜在的な薬物相互作用 (DDI) を特定するタスクで優れたパフォーマンスを発揮します。
以下の図に示すように、Y-Mol によって設計された薬剤は、クエリで提案された制約を効果的に満たします。同様に、Y-Mol は特定の分子の LogD7.4 を正確に予測でき、予測結果は実際の値に非常に近くなっています。これは、医薬品開発課題の解決における Y-Mol の有効性を示しています。
AI テクノロジー: 創薬と開発のための新しいエンジン
実際、創薬の長い旅の中で、科学者たちはプロセスをスピードアップできる新しいテクノロジーを探してきました。近年、AI技術はこの分野で大きな応用可能性を示しており、疾患のメカニズムを深く理解できるだけでなく、創薬や臨床試験などの重要な段階でも重要な役割を果たしています。
企業の世界では、AI創薬の研究開発ではすでに目覚ましい成果を上げている企業もある。例えば、AI医薬品開発会社インシリコ・メディシンは、まったく新しいメカニズムを備えた特発性肺線維症治療のための新たな臨床薬候補を発見したことを今年初めに発表し、その薬は複数のヒトの細胞で検証されたと発表しました。そして動物モデル実験。さらに、ファーウェイクラウドは、中国科学院上海マテリアメディカ研究所と協力して、小分子医薬品の全プロセスで人工知能支援の医薬品設計を実現できる盤古医薬品分子大型モデルを立ち上げ、効率と効率を向上させた。医薬品の研究開発の正確性。
科学研究の分野では、この研究の著者の一人である湖南大学のZeng Xiangxiang教授のチームも、ペプチド配列の大規模な言語モデルを設計し、計算条件とフィルタリング条件を徐々に追加することでモデルをトレーニングしました。わずか 3 か月で、このモデルは 29 個の潜在的な抗菌ペプチドの設計と合成に成功し、そのうち 26 個が広域スペクトルの抗菌活性を示しました。マウス実験では、3 つの抗菌ペプチドが FDA 承認の抗生物質と同等の抗菌効果を示し、最大 25 日間の連続培養およびモニタリング中に明らかな耐性は観察されませんでした。この成果は「Nature Communications」社に正式に認められました。
論文リンク:
https://www.nature.com/articles/s41467-024-51933-2
さらに、この研究のもう一人の著者である中南大学のCao Dongsheng教授も、浙江大学のHou Tingjun教授およびXie Changyu教授とともに、分子最適化ツールPrompt-MolOptを最近共同開発した。このアルゴリズムは、キュー学習のトレーニング戦略を使用して、マルチプロパティの最適化におけるゼロショット学習と少数ショット学習の適用を実現します。
論文リンク:
https://www.nature.com/articles/s42256-024-00916-5
疾患メカニズムの深い理解から創薬の加速、臨床試験設計の最適化に至るまで、AI テクノロジーは医薬品研究開発の新しいエンジンとなりつつあり、テクノロジーが進歩し続けるにつれて、将来の医学研究においてますます重要な役割を果たすことになります。









