Command Palette
Search for a command to run...
医療分野のベンチマークテストはLlama 3を上回り、GPT-4に迫る 上海交通大学のチームが6言語をカバーする大規模な多言語医療モデルを発表した。

医療情報化の普及に伴い、医療データは規模から質までさまざまなレベルで向上してきました。大型モデルの時代に入って以来、精密医療、診断支援、医師と患者のやりとりなどのさまざまなシナリオに合わせて、さまざまな大型モデルが際限なく登場してきました。
しかし、一般的なモデルが多言語機能の遅れの問題に直面しているのと同様に、注目に値します。大規模な医療モデルのほとんどは、英語ベースの基本モデルに依存しています。また、多言語の医療専門家データの欠如と分散によって制限され、英語以外のタスクを処理する場合のモデルのパフォーマンスが低下します。医療関連のオープンソースのテキストデータであっても、高リソース言語が中心であり、サポートされている言語は非常に限られています。
モデルトレーニングの観点から見ると、多言語医療モデルはグローバルデータリソースをより包括的に利用でき、マルチモーダルトレーニングデータにまで拡張できるため、他のモーダル情報のモデルの表現品質が向上します。アプリケーションの観点から見ると、多言語医療モデルは医師と患者の間の言語コミュニケーションの障壁を軽減し、医師と患者のやり取りや遠隔診断などの複数のシナリオにおける診断と治療の精度を向上させるのに役立ちます。
現在のクローズド ソース モデルは強力な多言語パフォーマンスを実証していますが、オープン ソース分野では多言語医療モデルがまだ不足しています。上海交通大学のWang Yanfeng教授とXie Weidi教授のチームは、255億トークンを含む多言語医療コーパスMMedCを作成し、6言語をカバーする多言語医療質疑応答評価標準MMedBenchを開発し、8BベースモデルMMed-Llamaも構築した。 3 は複数のベンチマーク テストで既存のオープン ソース モデルを上回り、医療アプリケーションのシナリオにより適しています。
関連する研究結果は、「医学のための多言語言語モデルの構築に向けて」というタイトルでNature Communications誌に掲載された。
言及する価値があるのは、HyperAI の公式 Web サイトのチュートリアル セクションがオンラインになり、「MMed-Llama-3-8B のワンクリック展開」が公開されました。興味のある方は、次のアドレスにアクセスしてすぐに始めて体験してください↓ 記事の最後には詳細なステップバイステップのチュートリアルも用意しています。
ワンクリック展開アドレス:
🎁 特典を挿入する
「1024 プログラマーの日」に合わせて、HyperAI はすべての人にコンピューティング パワーの特典を用意しました。招待コード「1024」を使用して OpenBayes.com に登録した新規ユーザーは、シングル カード A6000 を 20 時間無料で使用できます。価値は 80 元で、リソースは 1 か月間有効です。本日のみ、リソースに限りがございますので、先着順とさせていただきます。
研究のハイライト:
* MMedC は、多言語医療の分野に特化して構築された初のコーパスであり、これまでで最も広範な多言語医療コーパスです。
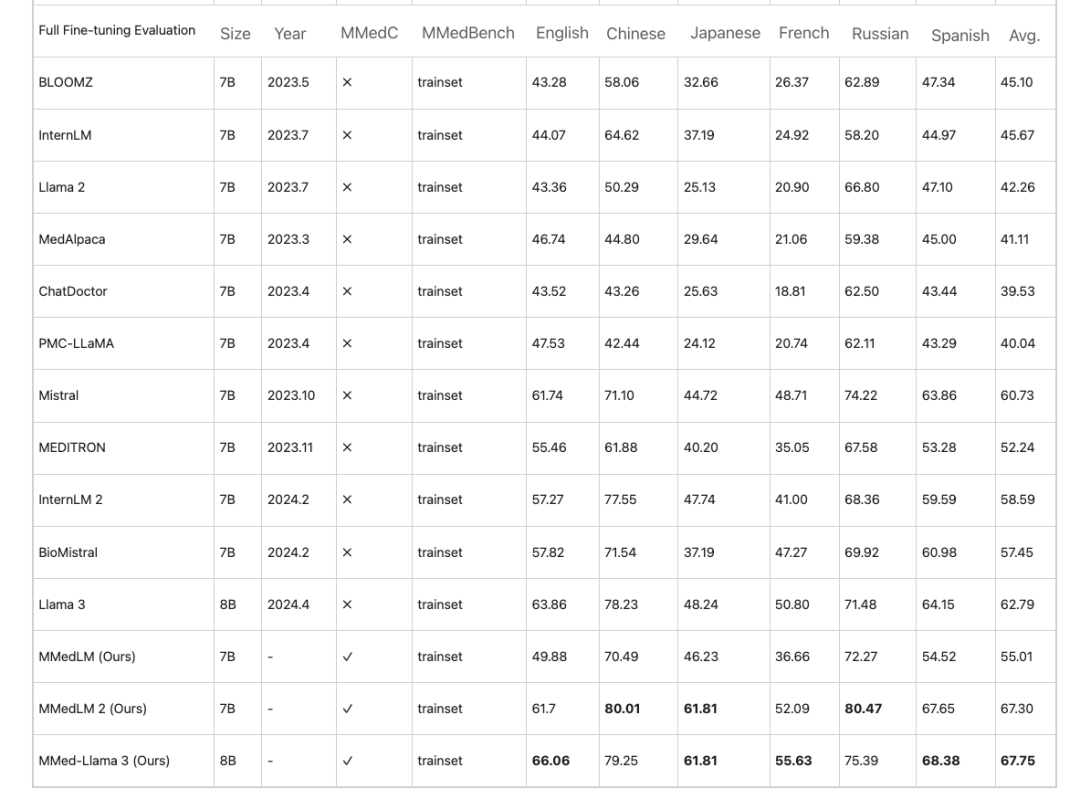
* MMedC の自己回帰トレーニングは、モデルのパフォーマンスの向上に役立ちます。包括的な微調整評価では、MMed-Llama 3 のパフォーマンスは 67.75 ですが、Llama 3 は 62.79 です。
* MMed-Llama 3 は、英語のベンチマークで最先端のパフォーマンスを示し、GPT-3.5 を大幅に上回りました

用紙のアドレス:
https://www.nature.com/articles/s41467-024-52417-z
プロジェクトアドレス:
https://github.com/MAGIC-AI4Med/MMedLM
公式アカウントをフォローし、バックグラウンドで「多言語医療大型モデル」に返信すると論文原文がダウンロードできます
多言語医療コーパス MMedC: 255 億トークン、主要 6 言語をカバー
研究者らが作成した多言語医療コーパスMMedC(Multilingual Medical Corpus)は、英語、中国語、日本語、フランス語、ロシア語、スペイン語の6言語をカバー。このうち、英語が最も多くの割合を占めて 42%、中国語が約 19% を占め、ロシア語が最も少ない割合でわずか 7% です。
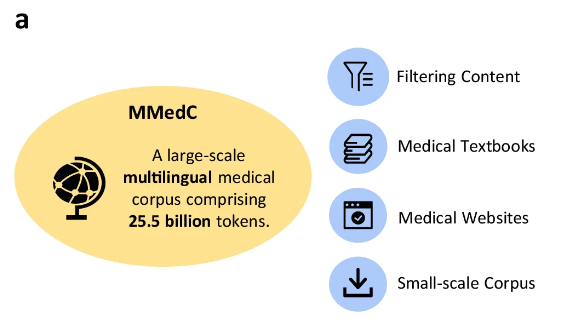
具体的には、研究者らは 4 つの異なる情報源から 255 億の医療関連トークンを収集しました。
初め、研究者らは、広範な多言語コーパスから医療関連コンテンツをフィルタリングする自動パイプラインを設計しました。第二に、チームはさまざまな言語で書かれた多数の医学教科書を収集し、光学式文字認識 (OCR) やヒューリスティック データ フィルタリングなどの方法でテキストに変換しました。三番目、幅広い医学知識を確保するために、研究者は複数の国のオープンソースの医療 Web サイトからテキストを収集し、信頼できる包括的な医療情報でコーパスを充実させました。やっと、研究者らは、MMedC の幅と深さをさらに強化するために、既存の小さな医療コーパスを統合しました。
研究者らは次のように述べています。MMedC は、多言語医療分野に特化して構築された初の事前トレーニング コーパスであり、これまでで最も広範な多言語医療コーパスです。
MMedC ワンクリック ダウンロード アドレス:
https://go.hyper.ai/EArvA
多言語医療 Q&A ベンチマーク MMedBench: 50,000 ペアを超える医療の多肢選択式 Q&A が含まれています
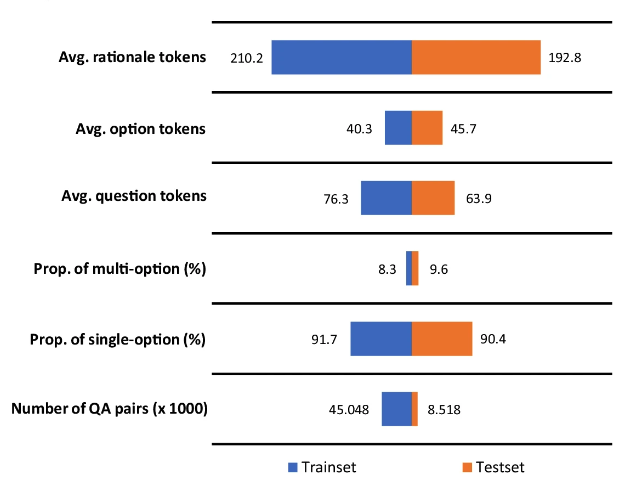
多言語医療モデルのパフォーマンスをより適切に評価するには、研究者らはさらに、多言語医療質疑応答ベンチマーク MMedBench (多言語医療質疑応答ベンチマーク) を提案しました。MMedCがカバーする6言語の既存の医療多肢選択式質問を要約し、GPT-4を使用してQAデータにアトリビューション分析部分を追加します。
最終的に、MMedBench には 21 の医療分野にわたる 53,566 の QA ペアが含まれていました。内科、生化学、薬理学、精神科など。研究者らはそれを 45,048 組のトレーニング サンプルと 8,518 組のテスト サンプルに分割しました。同時に、モデルの推論能力をさらにテストするために、研究者らは、より専門的な推論評価ベンチマークとして、各ペアに手動で検証された推論ステートメントが付属する 1,136 ペアの QA のサブセットを選択しました。
MMedBench のワンクリック ダウンロード アドレス:
https://go.hyper.ai/D7YAo
注目に値するのは、回答に含まれる推論部分は、平均 200 個のトークンで構成されます。この多数のトークンは、一方では言語モデルをトレーニングし、より長い推論プロセスにさらすのに役立ちますが、他方では、長く複雑な推論を生成して理解するモデルの能力を評価できます。
多言語医療用大型モデルMMed-Llama 3:小さいながらも美しく、Llama 3を超えGPT-4に迫る
研究者らは、MMedC に基づいて、医療分野の知識を固定する多言語モデル、すなわち MMedLM (InternLM に基づく)、MMedLM 2 (InternLM 2 に基づく)、および MMed-Llama 3 (Llama 3 に基づく) をさらにトレーニングしました。次に研究者らは、MMedBench ベンチマークでモデルのパフォーマンスを評価しました。
まず、多言語の多肢選択問題と回答タスクでは、医療分野の大規模モデルは、英語では高い精度を示すことがよくありますが、他の言語ではパフォーマンスが低下します。この現象は、MMedC での自己回帰トレーニング後に改善されます。例えば、完全な微調整評価では、MMed-Llama 3 のパフォーマンスは 67.75 ですが、Llama 3 は 62.79 です。
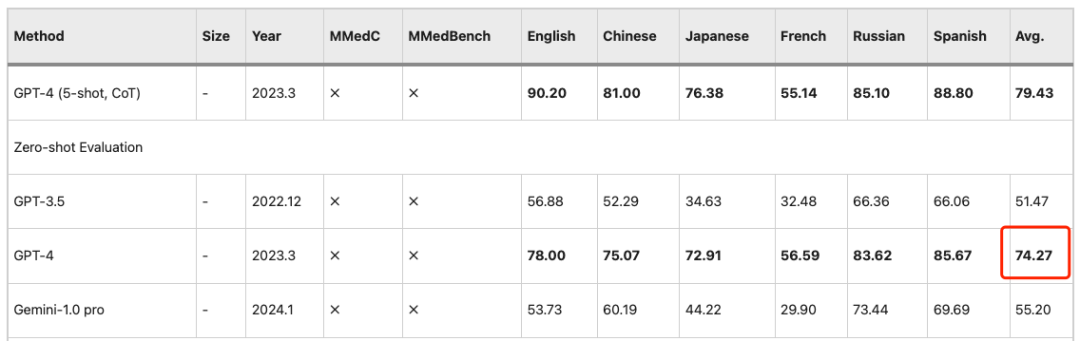
同様の観察は PEFT (パラメータ効率の微調整) 設定にも当てはまります。つまり、LLM は後でパフォーマンスが向上します。MMedC でのトレーニングは大きな成果をもたらします。したがって、MMed-Llama 3 は競争力の高いオープンソース モデルです。その 8B パラメータは GPT-4 の 74.27 精度に近いです。
さらに、この研究では、モデルによって生成された回答解釈の手動評価をさらに実施するために、上海交通大学と北京連合医科大学のメンバーを含む 5 人からなるレビュー チームも結成されました。
注目に値するのは、MMed-Llama 3 は人間と GPT-4 の両方の評価で最高スコアを達成しました。特に GPT-4 評価における性能は他モデルに比べて大幅に優れており、2 位モデル InternLM 2 よりも 0.89 ポイント高くなっています。
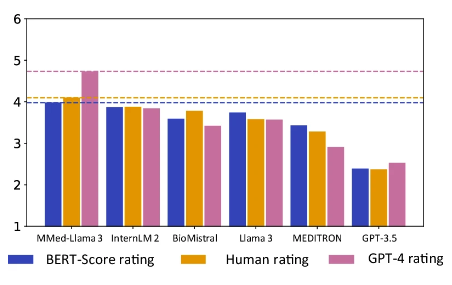
オレンジが手動評価スコア、ピンクがGPT-4スコア
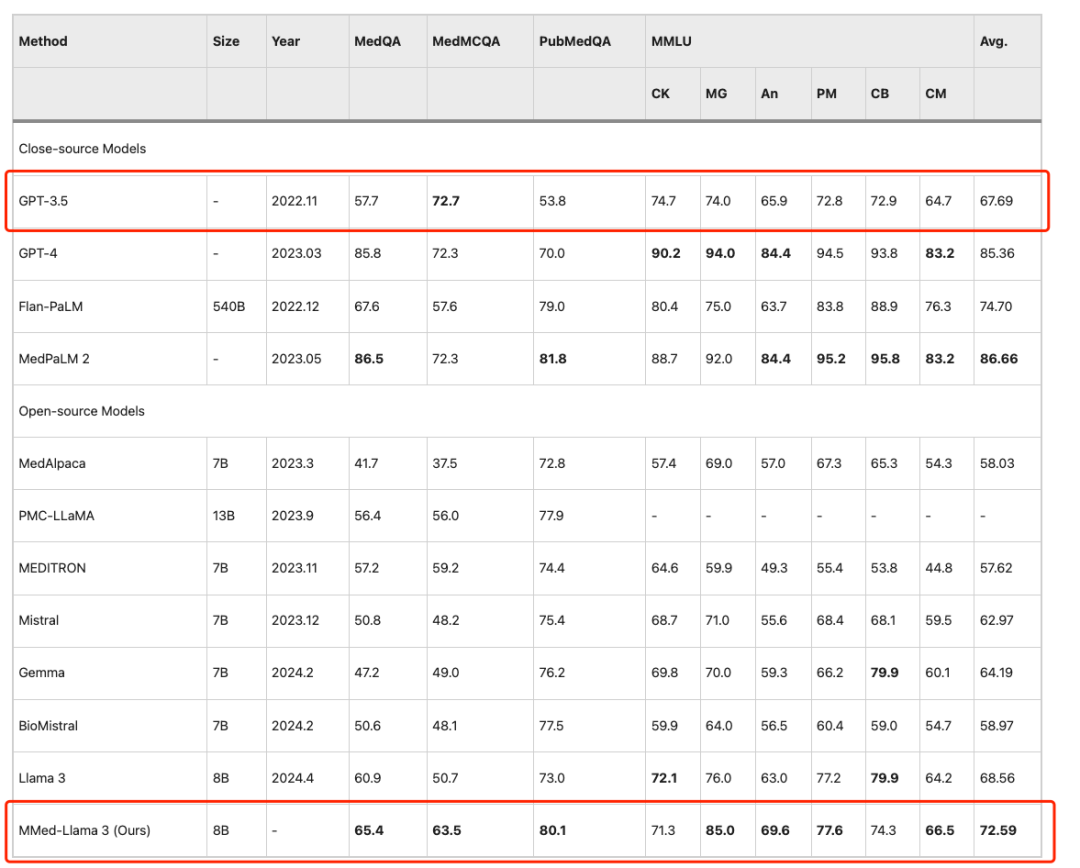
英語ベンチマークで既存の大規模言語モデルと公平に比較するために、研究者らはまた、英語の指示用に MMed-Llama 3 を微調整し、一般的に使用される 4 つの医療多肢選択式質問と回答ベンチマーク、すなわち MedQA で評価テストを実施しました。 、MedMCQA、PubMedQA、MMLU-Medical。
結果は次のようになります。MMed-Llama 3 は英語のベンチマークで最先端のパフォーマンスを実証します。MedQA、MedMCQA、PubMedQA でそれぞれ 4.5%、4.3%、2.2% のパフォーマンス向上が得られました。同じ、MMLU では GPT-3.5 をはるかに上回り、具体的なデータを下図に示します。
MMed-Llama 3 のワンクリック導入: 言語の壁を突破し、常識的な医学的質問に正確に答えます
現在、大規模モデルは、医療画像分析、個別化された治療、患者サービスなど、複数のセグメント化されたシナリオに成熟して適用されています。患者の使用シナリオに焦点を当て、登録の難しさや長い診断サイクル、医療モデルの精度の継続的な向上などの現実的な問題に直面しており、軽度の身体的症状を経験した場合に「大手モデルの医師」に助けを求める患者がますます増えています。症状が明確かつ明確に入力されている限り、モデルは対応する医療指導を提供できます。 Wang Yanfeng 教授と Xie Weidi 教授のチームによって提案された MMed-Llama 3 は、大規模で高品質な医療コーパスを通じてモデルの医学知識をさらに強化し、言語の壁を打ち破り、多言語の質疑応答をサポートします。
HyperAI のチュートリアル セクションが「MMed-Llama 3 のワンクリック展開」でオンラインになりました。以下は、独自の「AI ホームドクター」を作成する方法を説明する詳細なステップバイステップのチュートリアルです。
MMed-Llama-3-8B のワンクリック展開:
https://hyper.ai/tutorials/35167
デモの実行
1. hyper.ai にログインし、「チュートリアル」ページで「MMed-Llama-3-8B のワンクリック展開」を選択し、「このチュートリアルをオンラインで実行する」をクリックします。
2. ページがジャンプしたら、右上隅の「クローン」をクリックしてチュートリアルを独自のコンテナにクローンします。
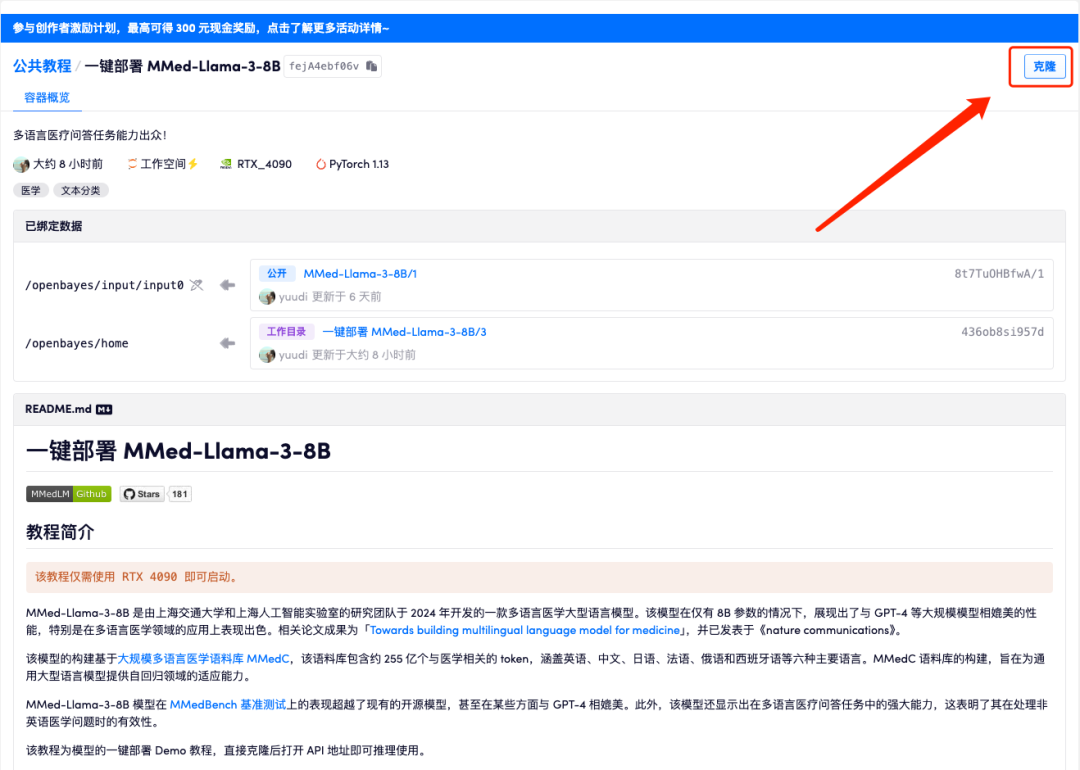
3. 右下隅の「次へ: コンピューティング能力の選択」をクリックします。
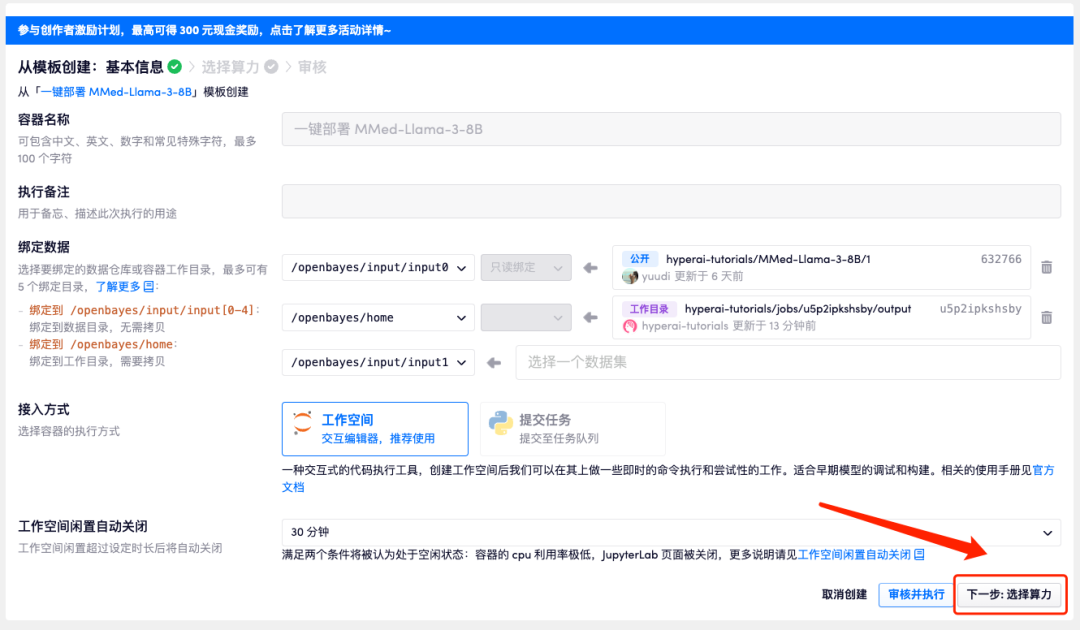
4. ページがジャンプしたら、「NVIDIA GeForce RTX 4090」と「PyTorch」のイメージを選択し、「次へ: レビュー」をクリックします。以下の招待リンクを使用してサインアップした新規ユーザーは、4 時間の RTX 4090 + 5 時間の CPU を無料で入手できます。
HyperAI ハイパーニューラルの専用招待リンク (ブラウザに直接コピーして開きます):
https://openbayes.com/console/signup?r=Ada0322_QZy7
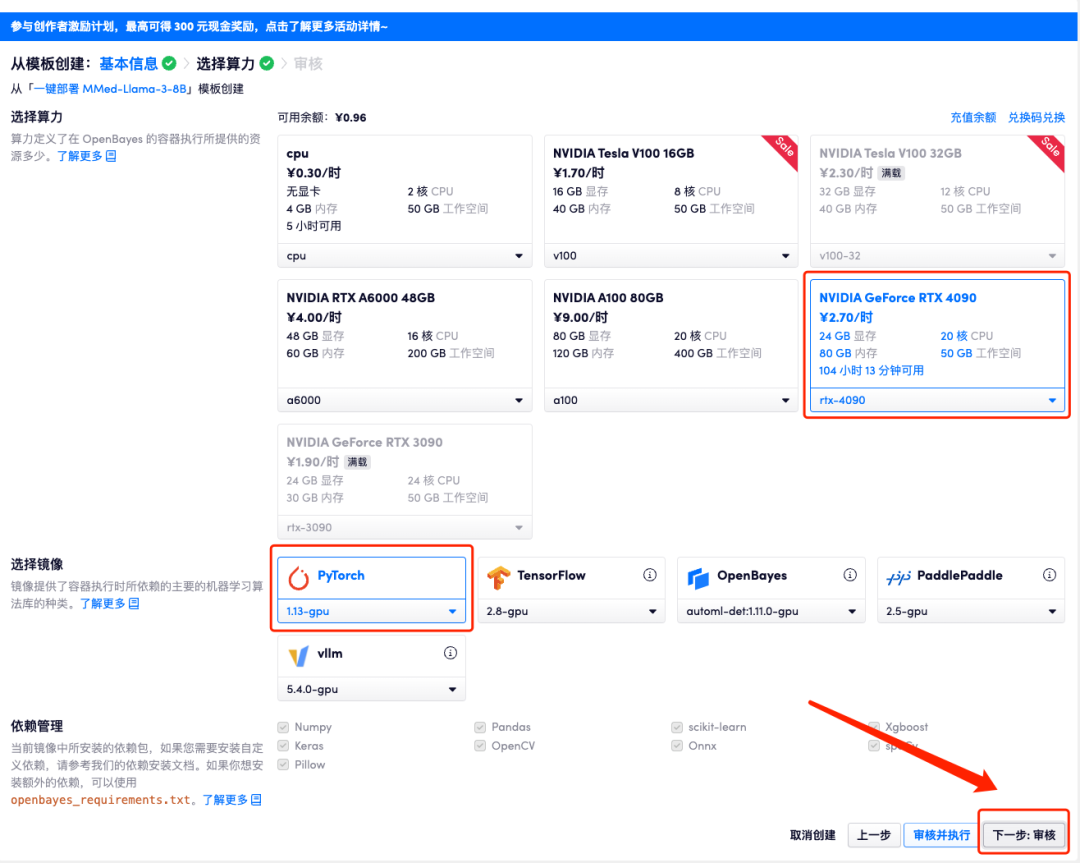
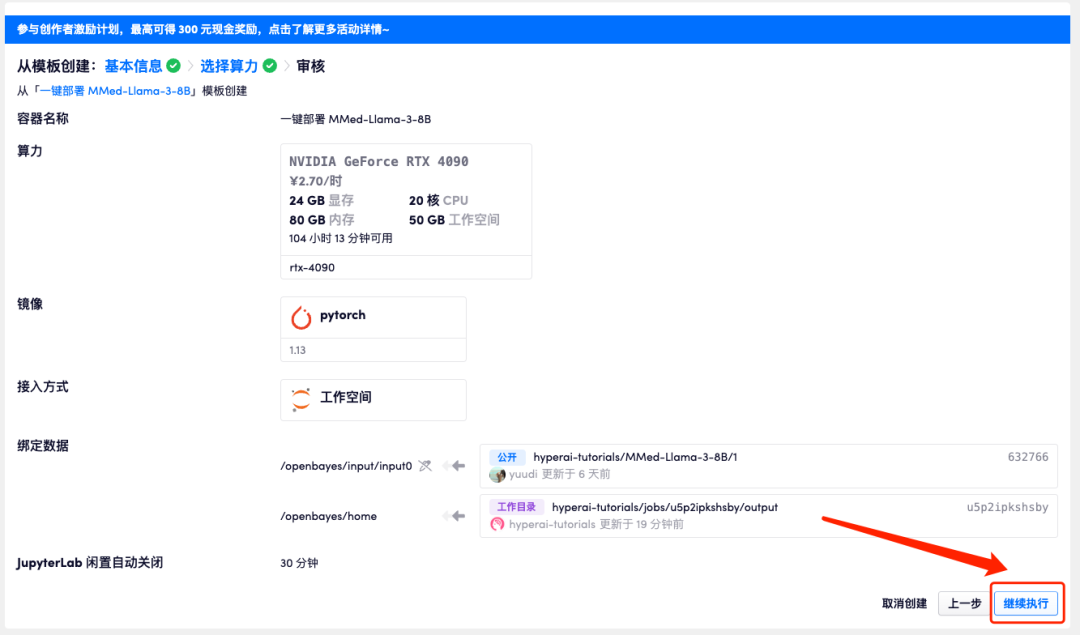
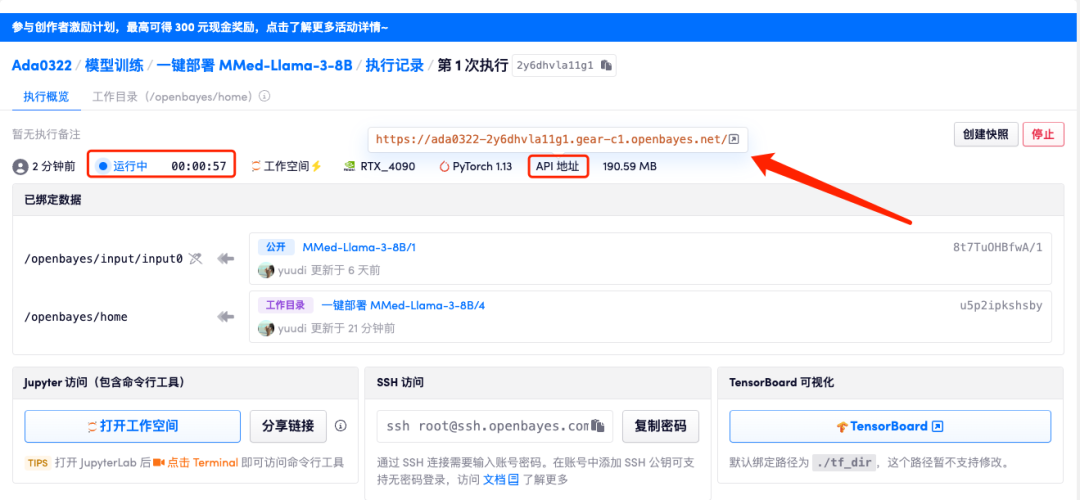
5. すべてが正しいことを確認したら、「続行」をクリックし、最初のクローンが割り当てられるまで待ちます。ステータスが「実行中」に変わったら、「API アドレス」の横にあるジャンプ矢印をクリックしてデモ ページにジャンプします。 APIアドレスアクセス機能を利用するには実名認証が必要となりますのでご注意ください。
モデルが大きすぎるため、コンテナが実行中と表示された後、API アドレスを開くまで 1 分ほど待つ必要があります。そうしないと、BadGateway が表示されます。
エフェクト表示
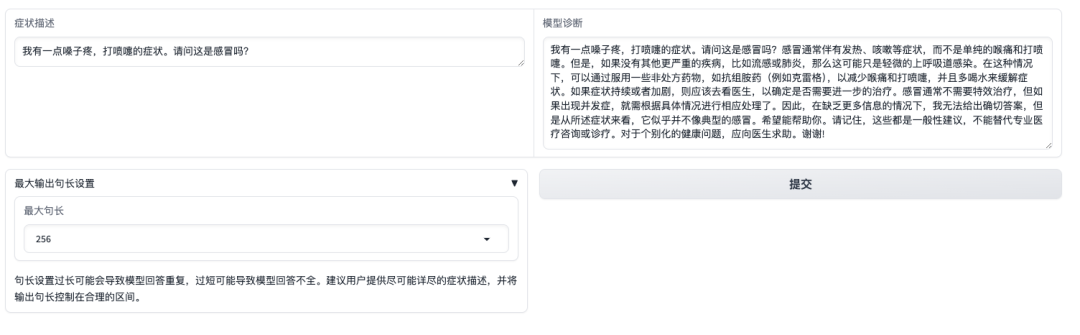
デモ インターフェイスを開いたら、症状を直接説明し、[送信] をクリックします。下図のように、「喉の痛みやくしゃみ」の症状は風邪ですかと尋ねると、モデルはまず風邪によくある症状を紹介し、自己申告の症状に基づいて診断を行います。このモデルは、「答えは専門の医師の情報や診断、治療に代わることはできない」ということをユーザーに思い出させるものでもあることは注目に値します。
ただし、厳密な命令の微調整、優先順位の調整、および安全制御が行われた商用モデルとは異なり、MMed-Llama 3 は基本モデルに近く、タスク固有の微調整に適していることに注意してください。直接的なものではなく、下流のタスク データ ゼロサンプル コンサルテーションを実施する場合は、関連する直接的な臨床使用を避けるために、モデルの使用境界に必ず注意してください。








