Command Palette
Search for a command to run...
Natureサブマガジンに掲載されました!論文の筆頭著者は、ウェット実験データの不足の問題を解決するためのタンパク質言語モデルの小サンプル学習方法を詳細に説明しています

生放送「Meet AI4S」シリーズの第 3 回エピソードでは、幸運なことに、上海交通大学自然科学アカデミーおよび上海国立応用数学センターの博士研究員、Zhou Ziyi 氏をお招きします。ホン・リャン氏が勤務する上海交通大学の研究グループの研究方向は、主に AI タンパク質と薬剤の設計、および分子生物物理学です。この研究グループは多大な研究成果を上げており、これまでに合計77本の研究論文を発表しており、その多くはNature誌に掲載されています。
この共有の中で、Zhou Ziyi 博士は「タンパク質言語モデルの小規模サンプル学習法」というタイトルでチームの最新の研究結果を共有し、AI 支援による指向性進化の新しいアイデアについて議論しました。
タンパク質言語モデル(PLM)の研究背景
タンパク質とタンパク質工学
タンパク質は生物学的機能の主な担体であり、生命活動の実行者です。天然アミノ酸であるアンモニアは、脱水縮合反応によりタンパク質の残基配列(Residue Sequence)を形成し、その後折り畳まれて三次構造を形成します。タンパク質のアミノ酸の種類を変更すると、その構造と機能に影響します。
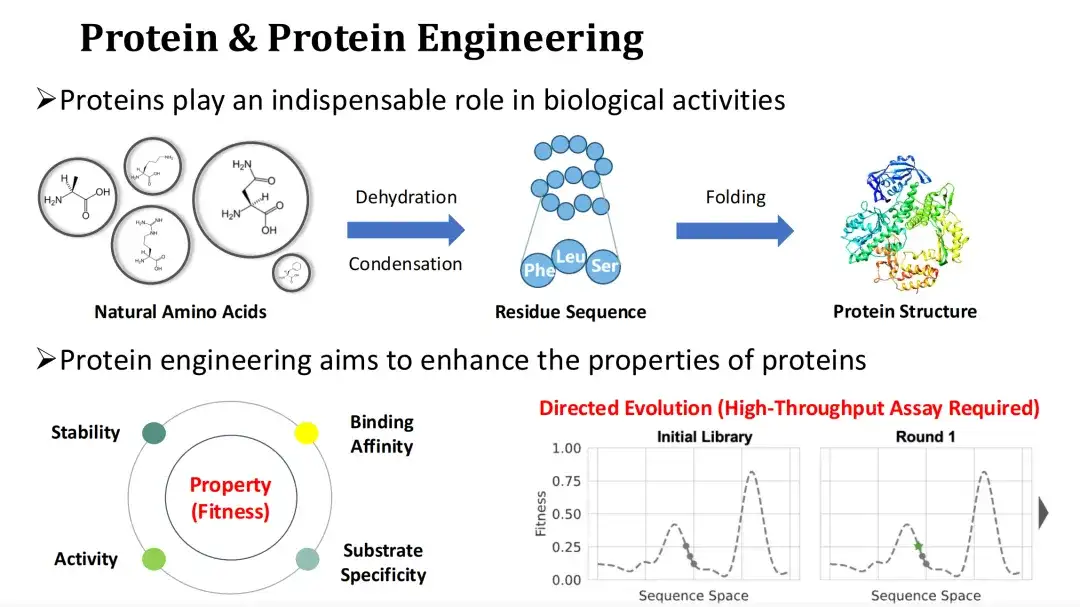
天然のタンパク質は産業や医療のニーズを満たすことが難しいことが多いため、タンパク質工学では、タンパク質を変異させることによって、触媒活性、安定性、結合能力などのタンパク質の機能的特性を改善することが期待されています。
私たちは通常、タンパク質の機能特性の定量化をフィットネスと呼びます。指向性進化は現在主流のタンパク質工学手法です。適応度の高い変異体を見つけるにはランダム変異とハイスループット実験に依存していますが、実験コストは高くなります。これを考慮して、今日私が共有するトピックは、AI 手法を使用して適応度を予測し、それによって実験コストを削減する方法です。
PLM アーキテクチャ
ChatGPT で表される言語モデルは非常に強力で、高品質のテキストの理解と生成が可能であることがわかっています。大量のテキストで事前トレーニングすることにより、これらの言語モデルはテキストの統計的パターンを学習し、基本的な文法と文脈内の単語の意味論を習得できます。では、タンパク質言語モデルは、大量のタンパク質配列に対して同様にトレーニングできるのでしょうか?答えは「はい」です。

タンパク質言語モデルPLMには主に3種類の機能があります。まず、PLM はタンパク質配列の共進化情報をモデル化し、残基間の相互依存性と進化的制約を学習できます。自然言語と同じように、LM はテキストの文法を学習できます。 PLM はこの機能を使用して、どの変異が有害であるか有益であるかを推定し、それによって変異の適合性を予測できます。
次に、フィットネス予測に加えて、PLM はタンパク質のベクトル表現も計算できます。これらの表現は構造予測やタンパク質マイニングに使用でき、微調整後は機能予測にもつながります。
最後に、PLM は ChatGPT のような条件付きタンパク質生成を実行して、de novo タンパク質設計を実現できます。
PLM のアーキテクチャは自然言語 LM のアーキテクチャに似ており、自己回帰モデルとマスク モデルに分かれています。両方のモデルのネットワーク構造は、セルフアテンション メカニズム (セルフ アテンション) と完全に接続された層で構成される Transformer を使用します。主な違いは、事前トレーニング ターゲットにあります。
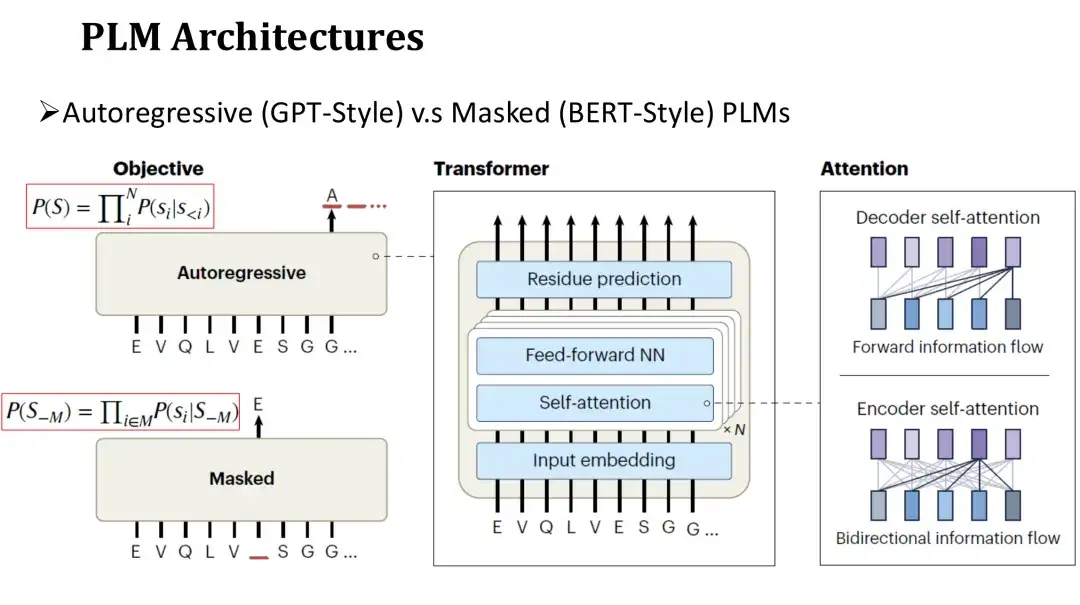
自己回帰モデルのトレーニング前の目標は、左から右の順序で次のアミノ酸を生成することです。マスキング モデルの目的は、クローゼ充填と同様に、ランダムにマスクされたアミノ酸を復元することです。自己回帰モデルは各アミノ酸を予測するときに左側に生成された配列のみに依存できるため、その注目は一方向です。マスキング モデルは、予測時にマスクされた位置の両側のアミノ酸を確認できます。したがって、その注意は双方向に向けられます。
PLM における 2 つの注目の研究方向性
現在、PLM の研究ホットスポットは主に 2 つの方向に分かれています。 1 つ目は検索拡張 PLM です。このタイプのモデルは、現在のタンパク質の多重配列アラインメント (MSA) をトレーニングまたは予測中の追加入力として使用し、情報を取得することで予測パフォーマンスを向上させます。たとえば、MSA Transformer や Tranception などがその代表的なモデルです。
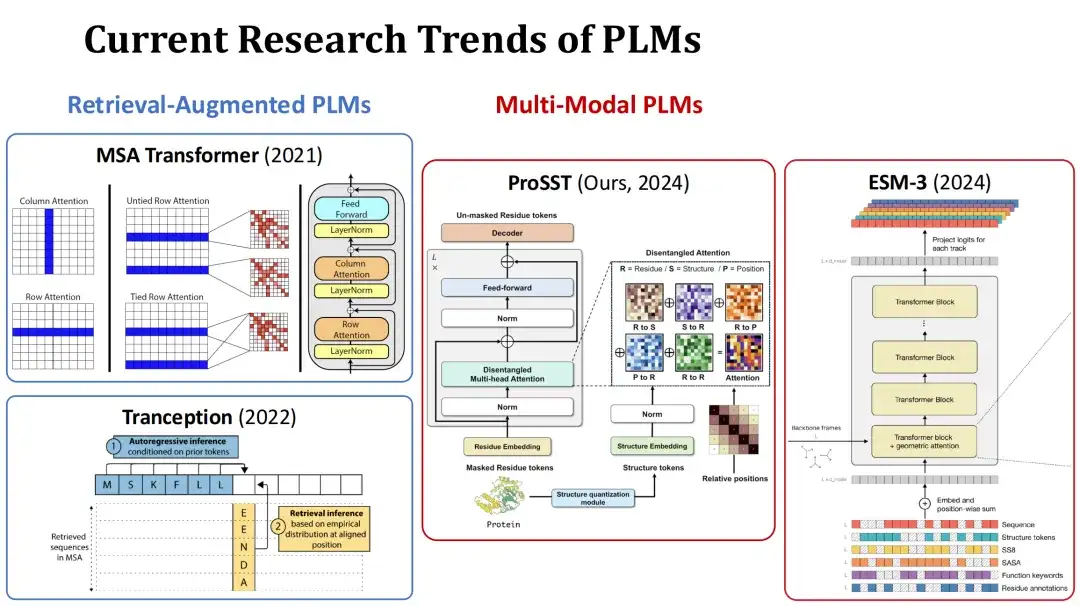
続いてマルチモーダルPLM、このタイプのモデルでは、タンパク質配列に加えて、タンパク質の構造やその他の情報も追加入力として使用して、モデルの表現能力を強化します。例えば、私たちの研究グループが今年提出したProSSTモデルは、タンパク質の構造を構造トークン配列として定量化し、それをアミノ酸配列とともにTransformerモデルに入力し、分離したアテンション機構によって2種類の情報を融合させます。もう 1 つの例は、同時期のモデル ESM-3 です。これは、アミノ酸の種類、完全な三次構造、三次構造トークン、二次構造、溶媒接触表面積 (SASA)、タンパク質および残基の機能の説明など、より豊富な情報を考慮しています。入力は全部で7つあります。
教師なしおよび教師ありのフィットネス予測
次に、フィットネス予測の問題について引き続き説明します。PLM はタンパク質配列の確率分布をモデル化できるため、データにラベルを付けることなく突然変異の適合性を予測するために直接使用できます。この方法はゼロショット予測または教師なし予測と呼ばれます。

具体的には、PLM は、変異体と野生型の間の対数尤度比を計算することによって変異をスコアリングします。自己回帰モデルの場合、配列の確率 P は各アミノ酸の生成確率の積です。突然変異のスコアは、突然変異体の logP から野生型の logP を引くことによって取得できます。直感的に言えば、野生型と比較して突然変異の発生確率を比較し、突然変異の影響を評価するという経験的な評価方法です。
マスキングモデルの場合、配列全体の確率を直接計算することはできませんが、最初に特定の点をマスクし、その点でのアミノ酸の確率分布を推定することができます。したがって、各変異位置について、マスキング後の変異アミノ酸の予測 logP から野生型アミノ酸の logP を減算し、すべての位置での差を加算して変異体のスコアを得ることができます。
さらに、PLM はタンパク質配列のベクトル表現を提供するため、十分な実験データがある場合、それらを微調整して教師あり適応度予測を達成することもできます。
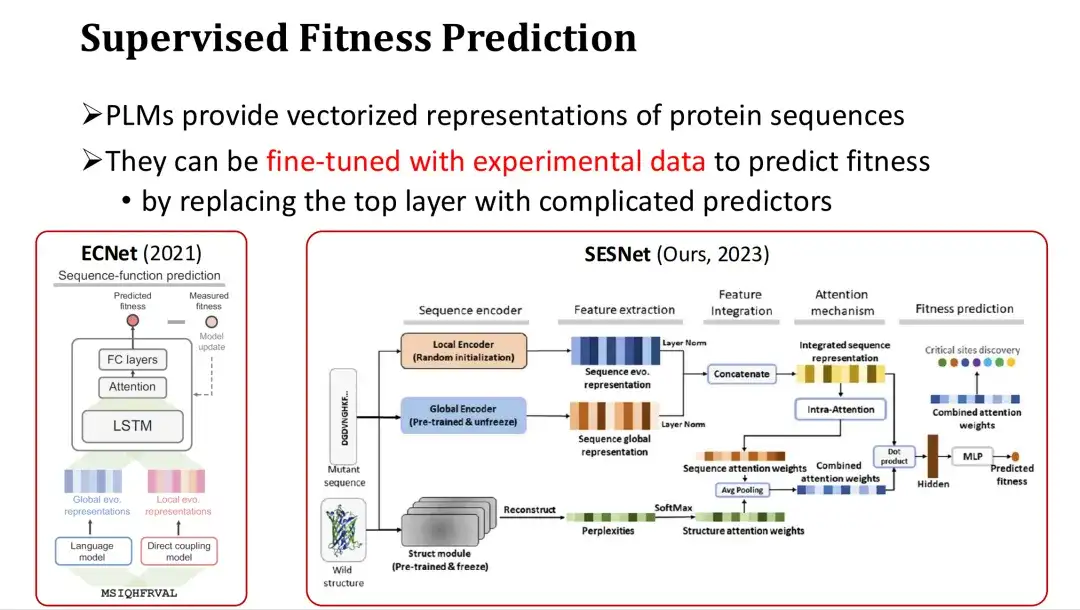
具体的な方法は、PLM の機能の最後の層の後にフィットネスを予測するための出力層 (アテンション メカニズムや多層パーセプトロン MLP など) を追加し、完全または部分的なトレーニングにフィットネス ラベルを使用することです。たとえば、ECNet は大規模モデルの特徴に MSA 特徴を追加し、LSTM を通じてそれらを融合し、教師ありトレーニングを実行します。私たちの研究グループが昨年開発したSESNetモデルは、ESM-1bの配列特徴、ESM-IFの構造特徴、MSA特徴を組み合わせて教師あり適応度予測を行います。
FSFP メソッドの紹介: PLM のための小規模サンプル学習メソッド
フィットネス予測における小規模サンプル学習の重要性
FSFP 手法を導入する前に、適応度予測における小サンプル学習の重要性を明確にする必要があります。教師なし手法ではトレーニングにラベル付きデータは必要ありませんが、ゼロショット スコアリングの精度は低くなります。さらに、対数尤度比に基づくスコアはタンパク質の自然法則の一部しか反映できないため、タンパク質の不自然な特性を効果的に予測することも困難です。

一方、教師あり学習手法は正確ではありますが、PLM パラメータが膨大であるため、パフォーマンスを大幅に向上させるためにはトレーニングに大規模な実験データが必要になります。教師あり学習モデルの評価には通常、既存の高スループット データ セットを 8:2 に分割する必要があり、80% のトレーニング セットにはすでに数万のデータが含まれている可能性があり、実際に取得するには非常にコストがかかります。
この問題を解決するために、我々は PLM に適した小サンプル学習手法である FSFP 手法を提案します。この方法では、少数のトレーニング サンプル (数十) を利用することで、PLM の適応度予測パフォーマンスを大幅に向上させることができます。同時に、FSFP 方式は高い柔軟性を備えており、さまざまな PLM に適用できます。
FSFP メソッド: フィットネスのためのランキング学習
これまでの教師あり学習手法では、適合度予測を回帰問題として扱い、モデルの出力と適合度ラベルの間の平均二乗誤差 (MSE) を計算することでモデルを最適化していました。ただし、サンプルが小さい条件下では、回帰モデルは非常に簡単に過学習し、トレーニング損失は非常に急速に低下します。そこで考え方を変え、回帰は行わず、正確な値の当てはめにはこだわらず、正確なランキングのみを求めてランキング学習を行いました。
このアプローチには 2 つの大きな利点があります。第一に、配列決定自体はタンパク質工学の基本的なニーズを満たしており、単に突然変異の相対的な有効性を測定するだけです。第 2 に、ランキング タスクは絶対値を予測するよりも簡単です。
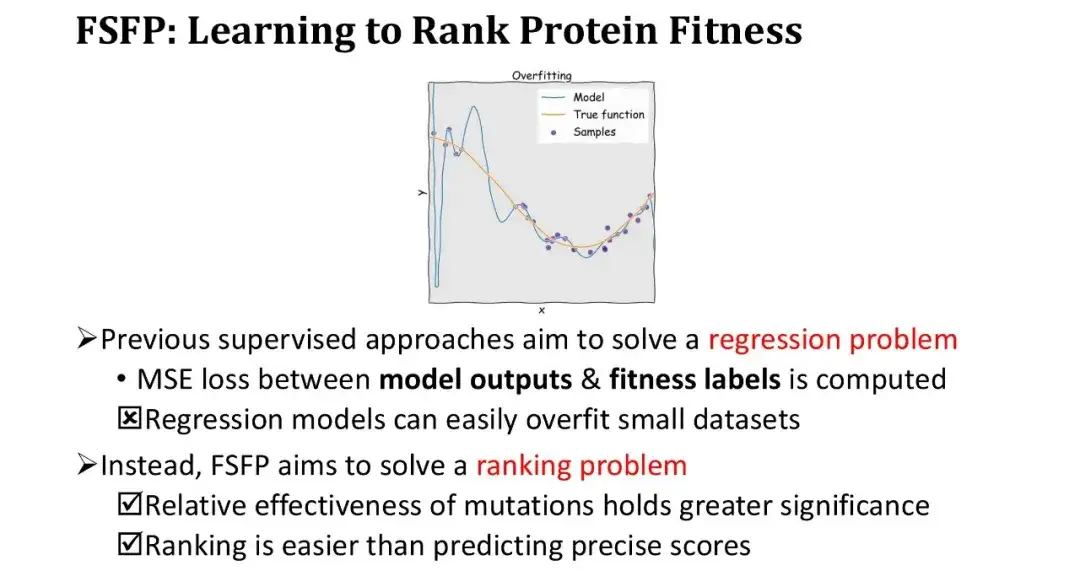
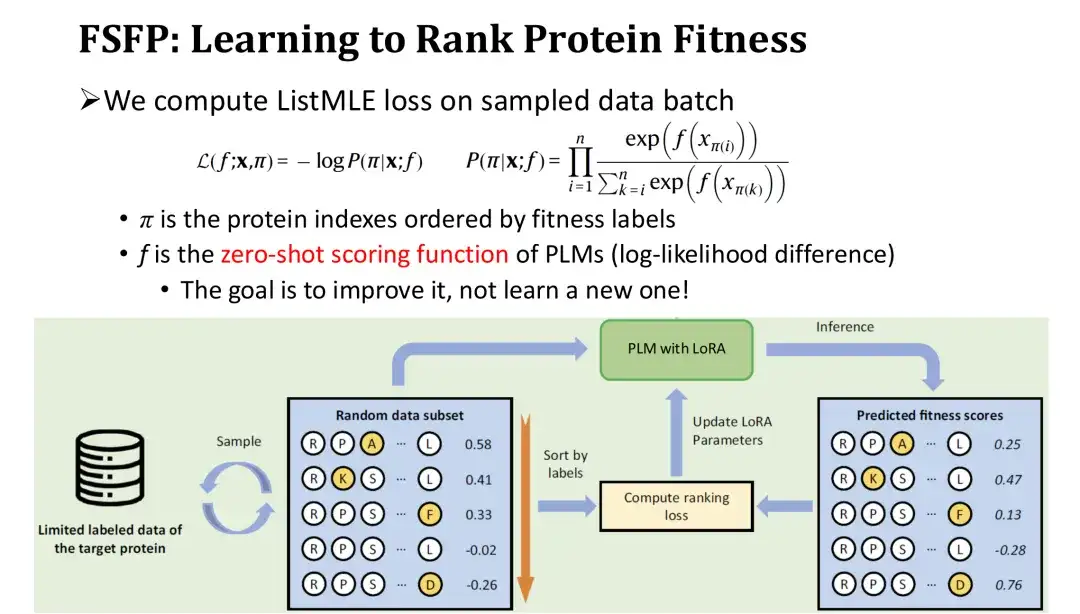
トレーニングの反復では、サンプリングされた突然変異体のセットをラベルごとに逆順に並べ替え、これらの突然変異体のモデルの予測値に基づいてランキング損失 - ListMLE - を計算します。モデル予測のランキングが真のランキングに近ければ近いほど、損失は小さくなります。このうち、突然変異に対するモデルのスコアリング関数 f として、対数尤度比に基づくゼロショット スコアリング関数を使用します。この目的は、ゼロショット スコアを開始点として使用し、トレーニング データで徐々に変更して、モジュールを再初期化することなくパフォーマンスを向上させ、それによってトレーニングの難易度を軽減することです。
FSFP メソッド: パラメータ効率の高い PLM の微調整
通常、PLM のパラメーターの数は数億に達するため、非常に少ないデータで完全な微調整を行うと、必然的にオーバーフィッティングが発生します。そこで、モデルのトレーニング可能なパラメーターの数を制限するために、2 番目のテクノロジー LoRA を導入しました。
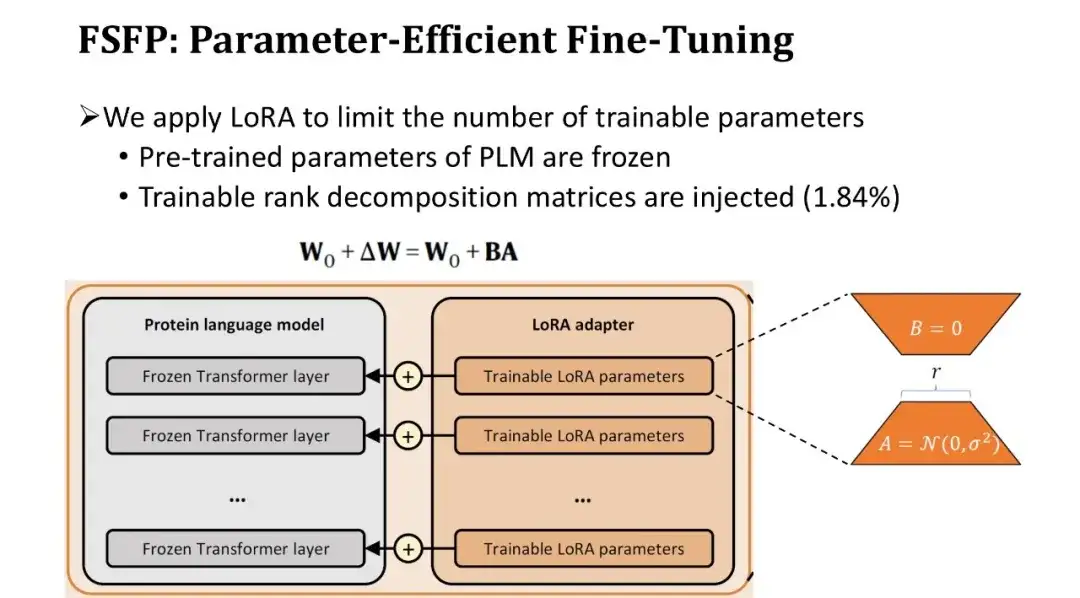
LoRA は、トレーニング前のパラメーターを変更せずに、Transformer の各ブロックの完全に接続された層にトレーニング可能なランク分解行列のペアを挿入します。ランク分解行列が小さいため、学習可能なパラメータの数を元の 1.84% まで減らすことができます。トレーニング可能なパラメータの数は減りますが、Transformer の各層が微調整されているため、モデルの学習能力は保証されています。
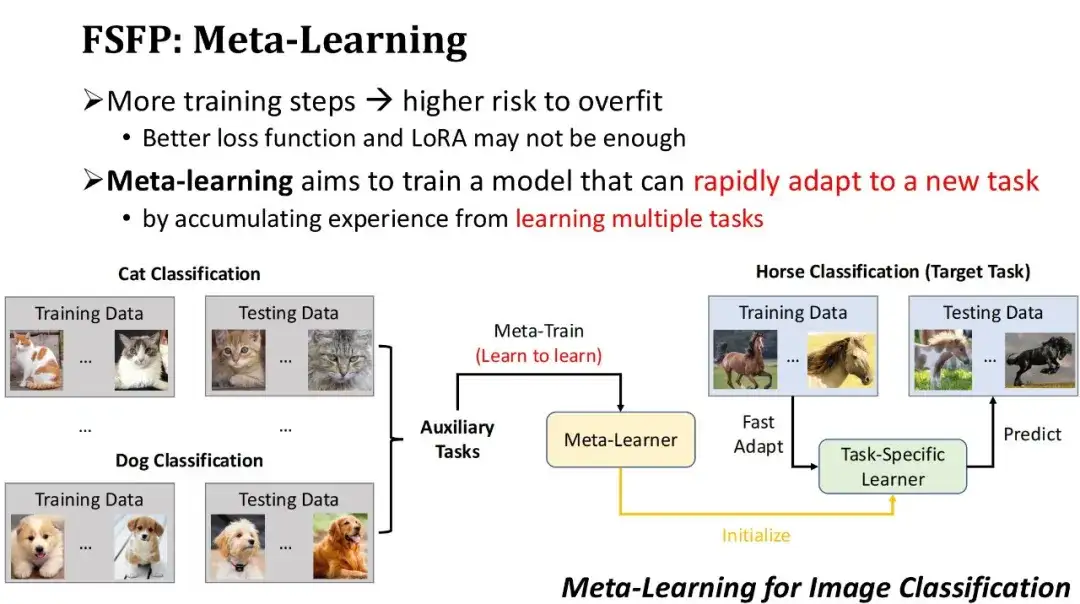
FSFP メソッド: メタ学習をフィットネス予測に適用する
過学習を避けるために、より優れた損失関数を使用するだけでなく、LoRA テクノロジーを通じてトレーニング可能なパラメーターの数も制限します。ただし、それでも、小さなサンプルのトレーニング データに対するトレーニングの反復が多すぎる場合は、依然として過学習のリスクが存在します。したがって、トレーニングの反復回数を減らしてモデルのパフォーマンスを迅速に改善したいと考えています。このニーズに基づいて、私たちは 3 番目のテクノロジーであるメタラーニングを採用しました。メタ学習の基本的な考え方は、まずモデルに特定の補助タスクの経験を蓄積させ、初期モデルを取得し、次にこの初期モデルを使用して新しいタスクに迅速に適応させることです。
以下の図に示すように、これはメタ学習に基づく画像分類の例です。ターゲット タスクが馬を分類するモデルをトレーニングすることであるが、馬についてラベル付けされたデータが比較的少ないとします。したがって、まず、猫の分類、犬の分類など、大量のデータを含むいくつかの補助タスクを見つけ、メタ学習アルゴリズムを使用してこれらの補助タスクをトレーニングし、新しいタスクを学習してメタデータを取得する方法を学習します。学習者。次に、このメタ学習器を初期モデルとして使用し、少量の馬の注釈データでいくつかのステップをトレーニングすると、馬の分類器を迅速に取得できます。明らかに、メタ学習が効果的であるための前提は、使用される補助タスクがターゲット タスクに十分に近い必要があることです。
メタ学習をフィットネス予測シナリオに適用するにはどうすればよいですか?まず、ターゲット タスクはターゲット タンパク質の変異を適合度によってランク付けすることであり、トレーニングされるモデルは LoRA テクノロジーを使用した PLM です。
補助タスクを構築するために 2 つの戦略を採用しました。 1 つ目は、標的タンパク質との類似性に基づいて既存の DMS データベースから類似タンパク質の変異実験データ セットを検索し、最初の 2 つのデータ セットをそれぞれ 2 つの補助タスクとして選択します。その出発点は、同様のタンパク質のフィットネスランドスケープも近いと考えることです。
2 番目の戦略は、MSA モデルを使用して標的タンパク質の候補変異をスコア化し、3 番目の補助タスクとして擬似ラベル データ セットを形成することです。MSA モデルを選択した理由は、通常、MSA モデルの突然変異予測効果が PLM と比べて劣らないため、PLM の表現能力を最大限に発揮するために MSA をデータ拡張に使用したいと考えているためです。
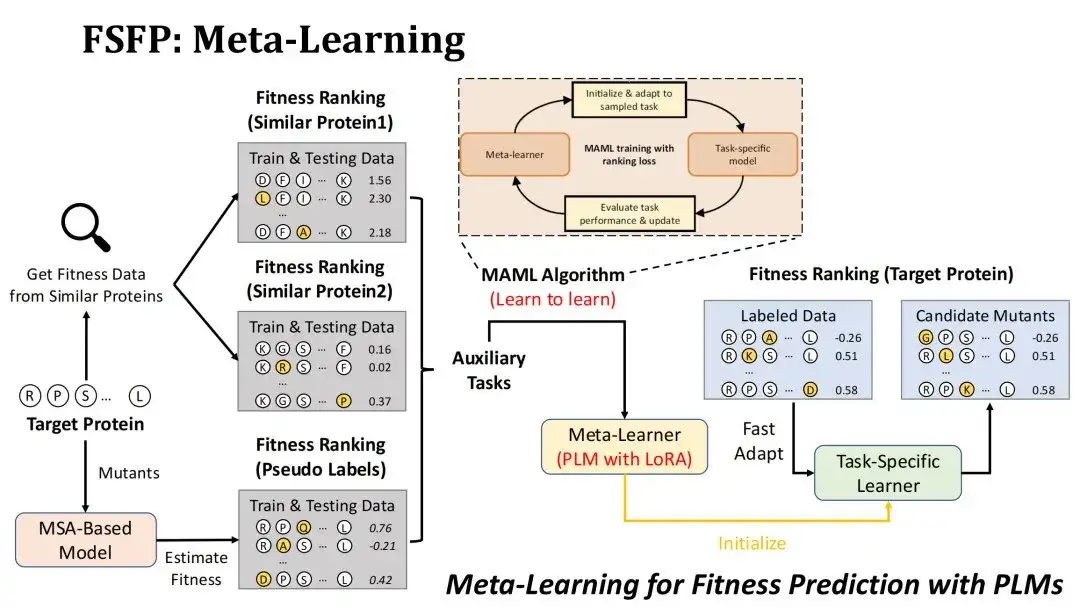
私たちが使用するメタ学習アルゴリズムは MAML です。そのトレーニングの目標は、補助タスクのトレーニング データを使用してメタ学習を微調整する k ステップ後のテスト損失を可能な限り小さくし、その後で大まかに収束できるようにすることです。ターゲットタスクを k ステップで微調整します。
タンパク質フィットネス予測におけるFSFP法の性能評価
ベンチマークの設定
ベンチマーク データは ProteinGym から取得したもので、当初は 87 個の DMS データ セットが含まれていましたが、現在は 217 個に更新されています。87 種類の DMS に対応するタンパク質は、真核生物、原核生物、ヒト、ウイルスの 4 つのカテゴリに大別され、合計約 1,500 万個の変異と対応する適応度をカバーしています。
各データセットについて、小規模サンプルのトレーニング セットとして 20、40、60、80、および 100 個の単一点変異をランダムに選択し、残りの変異をテスト セットとして使用しました。早期停止を行うために追加の検証セットを使用しませんでしたが、トレーニング セットの相互検証を通じてトレーニング ステップ数を推定したことに注意してください。

前述したように、メタ学習には 3 つの補助タスクが必要で、そのうち 2 つはターゲットタンパク質との類似性に基づいて DMS データベースから取得されます。特定のデータセットでトレーニングする場合、それがデータベースであると想定して、ProteinGym の残りのデータセットからそのデータセットを取得します。
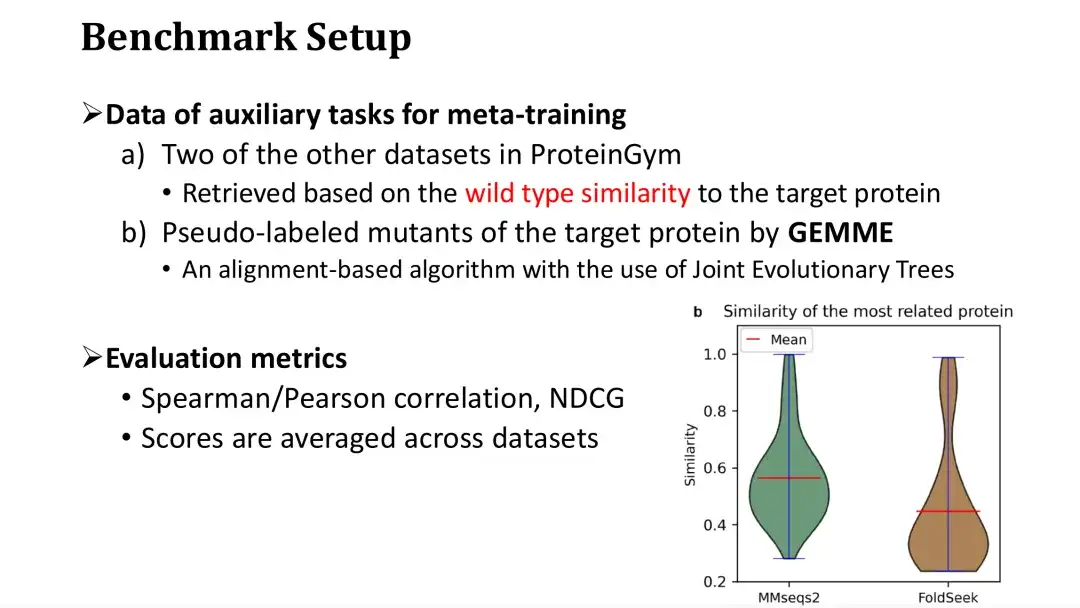
以下の右図に示すように、ProteinGym の各タンパク質をクエリとして使用し、最も類似したタンパク質の類似度分布を MMseqs2 と FoldSeek を通じてそれぞれ取得します。最も類似したタンパク質の平均配列または構造類似性は約 0.5 であることがわかります。 3 番目の補助タスクには、MSA モデルを使用した突然変異のスコアリングが含まれます。私たちは、MSA に基づいて進化ツリーを構築し、進化ツリー上の各点の保存性を計算して突然変異をスコアリングする GEMME モデルを選択しました。
評価指標には、適応度予測タスクで一般的な評価基準であるスピアマン/ピアソン係数とNDCGを使用します。最終的な評価スコアは、87 個のデータセットの平均スコアです。
ESM-2でのFSFPアブレーション実験
以下の図に示すように、左図の x 軸はトレーニング セットのサイズを表し、y 軸はスピアマン係数を表し、各線は異なるモデル構成に対応します。上の行は FSFP モデルの完全版を表し、2 番目の行は、MSA を使用せずに、メタ学習の 3 番目の補助タスクを同様のタンパク質の DMS データに置き換えたものを表しています。MSA を削除した後、モデルのパフォーマンスが低下していることがわかります。 ; 3 行目は、メタ学習が使用されず、ランキング学習と LoRA のみに依存することを示しており、スピアマン係数はさらに減少します。
緑色の線は、NBT で以前に公開されたリッジ回帰モデルを表します。これは、現在、小規模なサンプル シナリオに適した数少ないベースライン モデルの 1 つです。灰色の点線は、ESM-2 の使用を表します。従来の回帰のメソッドトレーニング ESM-2 の結果。
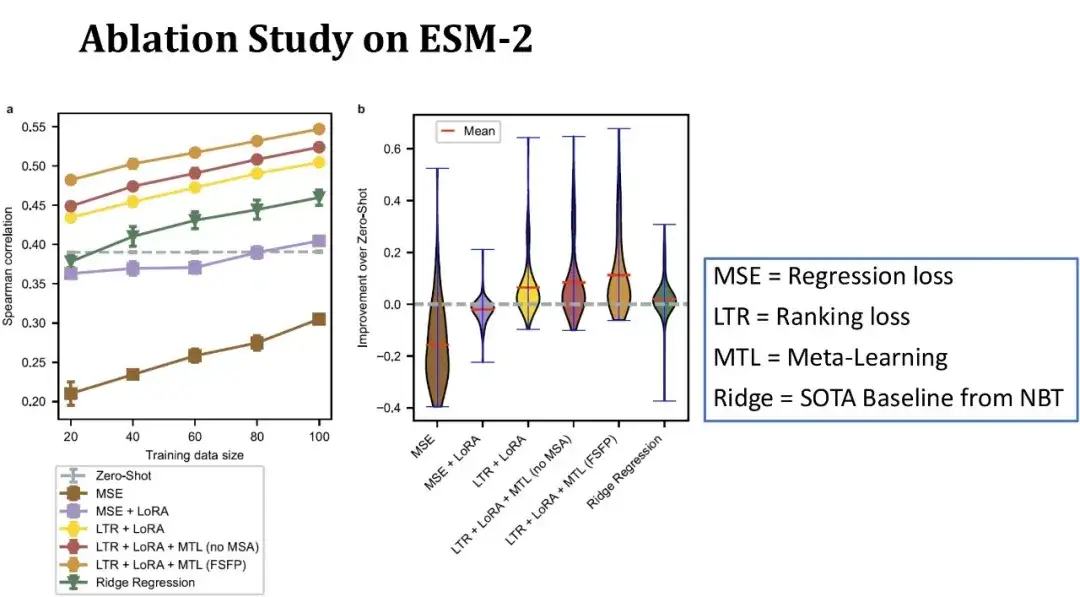
全体として、トレーニング サンプルが 20 個しかない場合、私たちの方法はゼロショットと比較して Spearman を 10 ポイント改善し、各モジュールはモデルのパフォーマンスにプラスの役割を果たします。右の図は、トレーニング セット サイズが 40 サンプルで、87 データ セットのゼロショットと比較したパフォーマンス向上の分布を示しています。私たちの方法はほとんどのデータ セットでモデルのパフォーマンスを向上させることができ、一部のデータ セットでは改善が 40 ポイントを超え、ベースラインよりも安定していることがわかります。
メタ学習の有効性
メタ学習の目的は、PLM が少ない反復回数でターゲット タスクに迅速に収束できるようにすることです。ここでいくつかの例を示します。
次の 3 つのグラフは、3 つのデータセットで 40 個のトレーニング サンプルを使用して微調整されたトレーニング曲線を示しています。 X 軸はトレーニング ステップの数を表し、Y 軸はテスト セットのスピアマン係数を表します。上部のオレンジと赤の線は両方ともメタ学習でトレーニングされたモデルです。前者は補助タスクを構築するために MSA を使用しますが、後者は使用しません。黄色の線は、メタ学習を行わずにランキング学習と LoRA のみを使用したモデルを表します。
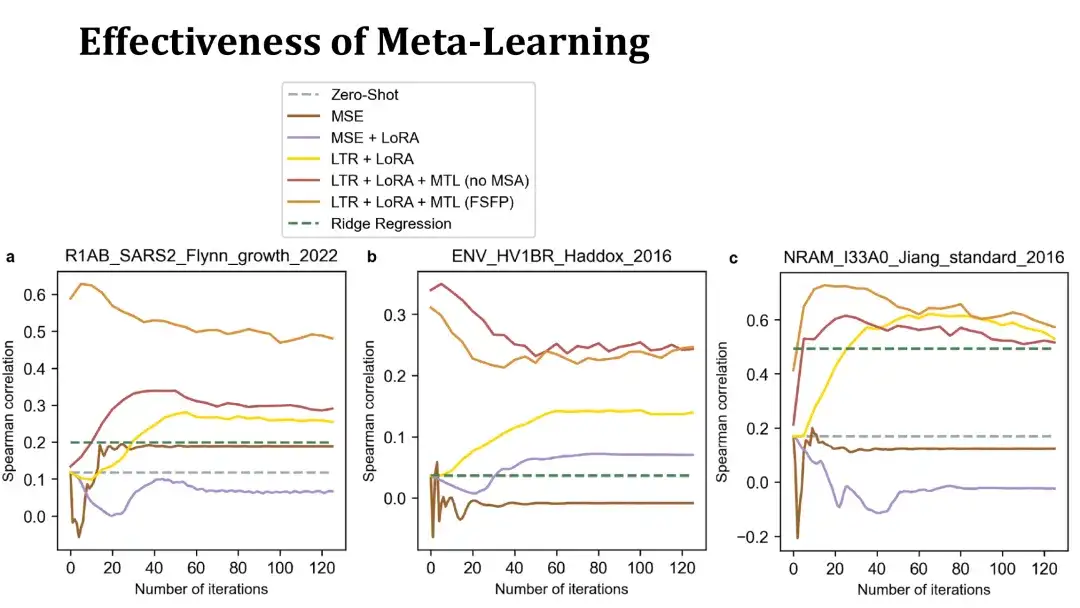
ご覧のように、メタ学習によってトレーニングされたモデルは、ターゲットタンパク質のパフォーマンスをより迅速に向上させることができ、場合によっては微調整を行わない初期モデルのパフォーマンスが向上することもあります。これは、メタ学習により効果的な初期モデルが得られたことを示しています。以下の MSE ベースのモデルはパフォーマンスが悪く、すぐにオーバーフィットしてしまうため、ゼロショット法を超えるのは困難です。
FSFP をさまざまな PLM に適用した結果
ESM-1v、ESM-2、SaProt という 3 つの代表的な PLM を選択しました。最初の 2 つのモデルはタンパク質の配列情報のみを使用しますが、SaProt はタンパク質の三次構造トークンを組み合わせます。
左側の折れ線グラフは、異なるトレーニング セット サイズでの単一点突然変異の効果を予測するためのスピアマン スコアを示しています。同じ色は同じモデルを表し、異なる形状の点は異なるトレーニング方法を表します。上の点は FSFP 法を表し、下の逆三角形はリッジ回帰を表し、点線はモデルのゼロショット性能を表します。紫色の線は GEMME モデルを表します。これは PLM ではありませんが、リッジ回帰法を組み合わせることができます。FSFP 手法は各 PLM のパフォーマンスを着実に向上させることができ、リッジ回帰および対応するモデルのゼロショットよりもはるかに優れていることがわかります。
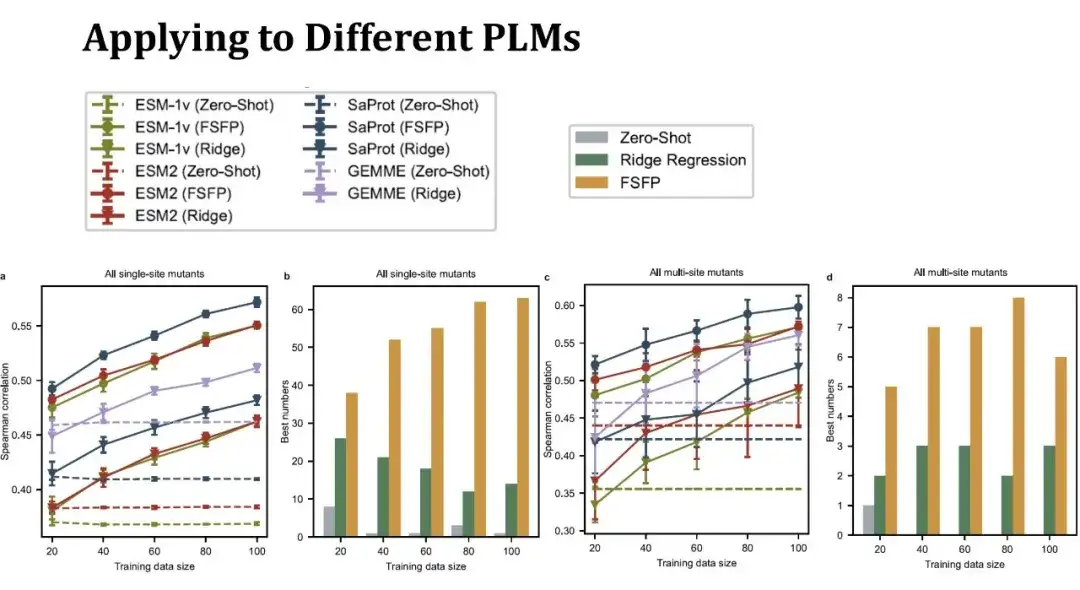
2 番目のヒストグラムは、さまざまなデータセットに対して 3 つの戦略 (ゼロショット、リッジ回帰、FSFP) を使用して取得された最高スコアの数を示します。 FSFP は、ほとんどのデータセットで最高のパフォーマンスを発揮します。右側の 2 つの図は、多点突然変異の予測パフォーマンスを示しています。11 個の多点突然変異データ セットが含まれており、得られた結論は単一点突然変異と同様です。ただし、リッジ回帰モデルの分散はここでより大きく、データ セグメンテーションの影響をより受けやすいことを示しています。
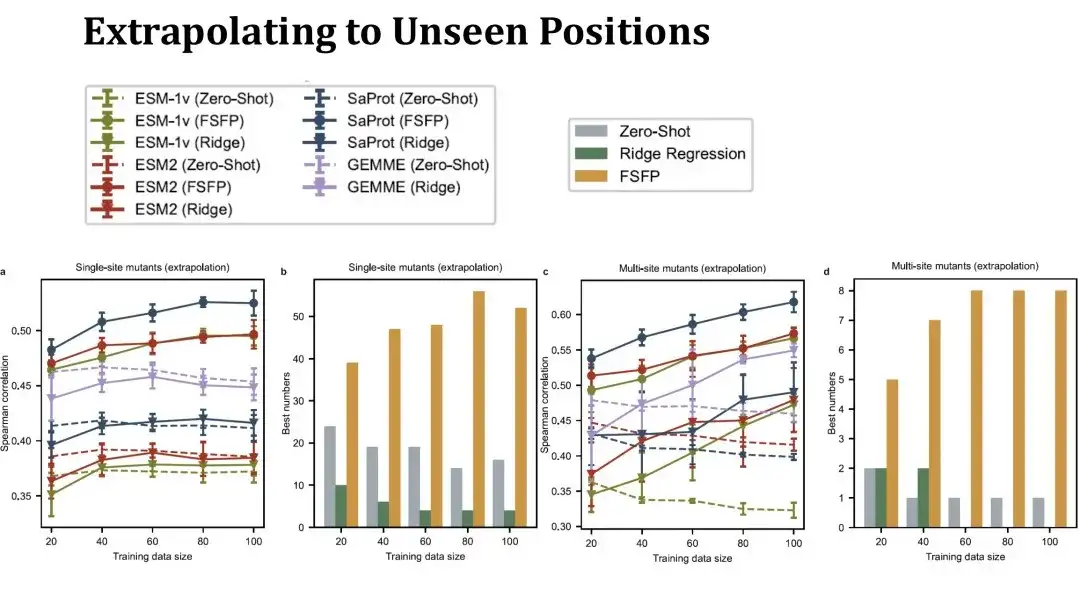
続いて、FSFP の外挿パフォーマンス、つまりトレーニング セットには見られない突然変異点での予測パフォーマンスを具体的に評価しました。。この場合、テスト セットは元のセットよりもはるかに小さく、トレーニング セットが大きくなるにつれてテスト セットは大幅に変化するため、表内のゼロショット パフォーマンスは直線ではなくなります。この設定はより困難です。左側の単一点変異リッジ回帰のパフォーマンスはゼロショットをほとんど超えることができませんが、FSFP は依然としてパフォーマンスを着実に向上させることができます。右側の多点突然変異のテスト結果も、私たちのトレーニング方法が優れた汎化能力を持っていることを示しています。
FSFP で Phi29 を変更する
さらに、FSFP を使用してタンパク質修飾の事例も作成しました。標的タンパク質は DNA ポリメラーゼである Phi29 であり、単一点突然変異によってその Tm を向上させることが期待されています。
実験プロセスは次のとおりです。まず、ESM-1v を使用して飽和単一点変異をゼロショットスコア付けし、スコア付けされた上位 20 個の変異を選択し、ウェット実験を実行して Tm を測定します。次に、これらの 20 個の実験データをトレーニング セットとして使用します。 FSFP を使用して ESM-1v を評価し、トレーニング済みのモデルを使用して飽和単一点変異を再度スコアリングし、最初の 20 個の変異がテスト用に再選択されます。
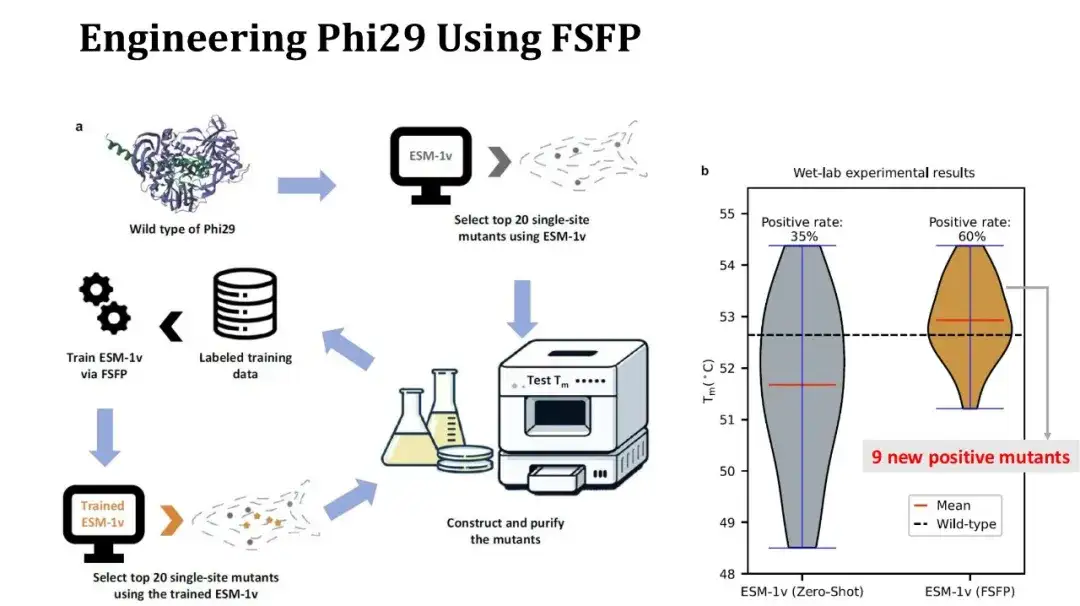
右の写真は、2 回の実験の前後の Tm 分布の比較を示しています。第 1 ラウンドでは 20 個の変異のうち 7 個が陽性でしたが、第 2 ラウンドでは 12 個に増加し、平均 Tm は 1 度上昇しました。このうち、第2ラウンドで見つかった陽性変異のうち9つは新規のものだった。陽性率と平均 Tm は改善しましたが、残念ながら、2 ラウンド目で得られた最高 Tm の変異が 1 ラウンド目の結果にまだ存在しているため、最高 Tm は改善されていません。ただし、より多くの陽性の単一点変異が得られているため、これらの点を組み合わせて高点変異実験を実施し、Tm をさらに上昇させることができます。
FSFP法の概要と今後の研究の展望
FSFP は、PLM 用の小サンプル学習戦略であり、少数 (数十) のラベル付きトレーニング サンプルを使用して、突然変異効果予測における PLM のパフォーマンスを大幅に向上させることができ、さまざまな異なる PLM に柔軟に適用できます。実験により、FSFP の設計が合理的であることが示されています。
* ランキング学習は、タンパク質工学における突然変異ランキングの基本的なニーズを満たし、トレーニングの難易度を軽減します。
* LoRA は、PLM のトレーニング可能なパラメーターの量を制御することにより、過剰適合のリスクを軽減します。
* メタ学習はモデルに適切な初期パラメータを提供し、モデルをターゲット タスクに迅速に移行できるようにします。

最後に、AI 支援による指向進化の将来の方向性について説明します。 AI 支援による指向進化の一般的なプロセスは、一連の初期突然変異から開始し、ウェット実験を通じてそのフィットネス ラベルを取得し、実験からフィードバックされた注釈付きデータを使用して機械学習モデルをトレーニングし、その後、目的の突然変異を選択します。モデルの予測に基づいて次のラウンドでテストされます。何度も繰り返します。
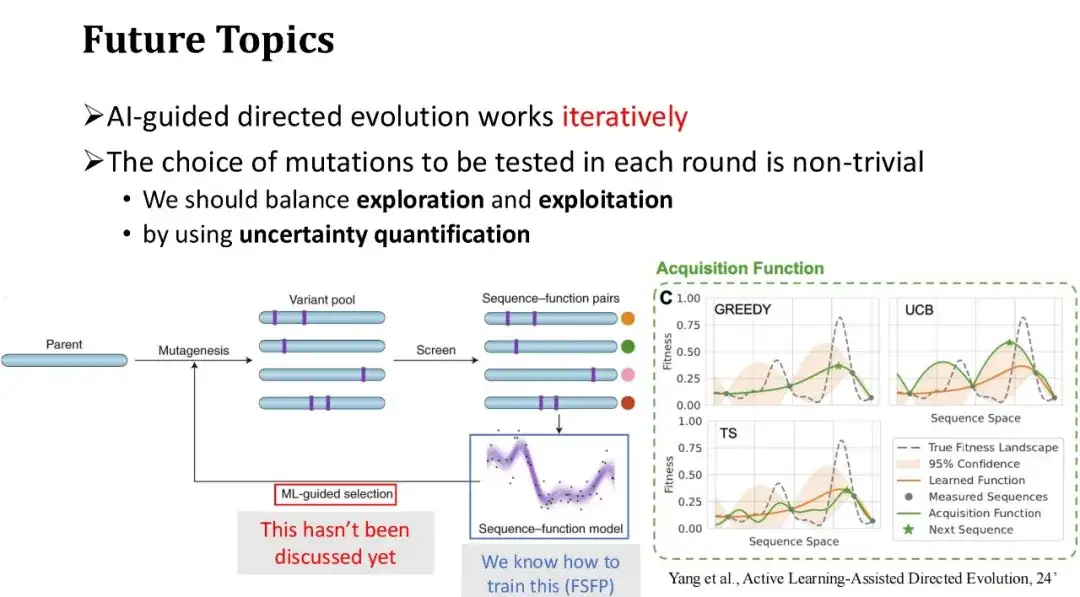
FSFP は主に、実験反復の各ラウンドにおけるモデルの小さなサンプルのトレーニングの問題を解決し、モデルの予測精度を向上させます。ただし、次のラウンドでテストする突然変異、つまり次のラウンドで追加する新しいトレーニング サンプルを効果的に選択する方法については議論していません。 Phi29 タンパク質修飾の前述の例では、モデル スコアが最も高い上位 20 個の変異を直接選択しましたが、複数ラウンドの反復シナリオでは、貪欲な選択戦略が必ずしも最良の方法であるとは限らず、陥りやすいです。局所的な最適性。したがって、探索と活用の間のバランスを見つける必要があります。
実際、ラベルを付けるテストサンプルを繰り返し選択し、トレーニングデータを徐々に拡張するプロセスはアクティブラーニングの問題であり、タンパク質工学の分野で一定の研究を進歩させてきました。たとえば、指向進化の分野で権威ある科学者であるフランシス H. アーノルドは、「アクティブ ラーニング支援指向進化」という記事で関連する問題について議論しています。
用紙のアドレス:
https://www.biorxiv.org/content/10.1101/2024.07.27.605457v1.full.pdf
不確実性の定量化手法を使用して、各変異体のモデルのスコアの不確実性を評価できます。これらの不確実性に基づいて、テストサンプルの選択戦略はより多様になります。。一般的に使用される戦略は UCB 法です。これは、次のアノテーション ラウンドでモデル予測の不確実性が最も高い変異サンプルを選択します。つまり、予測分散が最大のサンプルを優先します。これは人間の学習プロセスと似ています。特定の知識ポイントを十分に把握していない場合、または不確かな場合は、学習を強化することに重点を置きます。








