Command Palette
Search for a command to run...
GoogleがTPUの秘密兵器を公開、AlphaChipがNatureに登場! AI設計チップの開発史を徹底解説

2020年、Googleは画期的なプレプリント論文「深層強化学習によるチップ配置」を発表し、新しい強化学習手法を使用して設計されたチップレイアウトを世界で初めて披露した。このイノベーションにより、Google は TPU チップ設計に AI を導入し、人間の設計者を超えるチップ レイアウトを実現することができました。
2022 年までに、Google は論文に記載されているアルゴリズム コードをさらにオープンソース化し、世界中の研究者がこのリソースを使用してチップ ブロックを事前トレーニングできるようにします。
現在、この AI 主導の学習方法は、TPU v5e、TPU v5p、Trillium などの複数世代の製品のテストを経て、Google 内で目覚ましい成果を上げています。さらに注目すべきことは、Google DeepMind チームが最近、この手法の付録を Nature 誌に発表し、チップ設計の分野に対するこの手法の広範囲にわたる影響について詳しく説明したことです。同時に、Google はまた、20 個の TPU モジュールの事前トレーニングに基づいたチェックポイントを開き、モデルの重みを共有し、それを AlphaChip と名付けました。
AlphaChip の出現は、AI がチップ設計の分野でより広く使用されるようになるということを予告するだけでなく、「チップベースの設計」という新しい時代に突入していることを示しています。
AlphaChip: Google DeepMind が AI を使用してチップ設計に革命を起こす方法
Google の DeepMind の頂点である AlphaChip は、チップ設計における革新的な進歩により、世界のテクノロジー コミュニティの注目を集めています。
チップ設計は、現代テクノロジーの頂点にある分野であり、その複雑さは、非常に細いワイヤーを介した無数の精密コンポーネントの巧妙な接続にあります。現実世界のエンジニアリング問題を解決するために適用された最初の強化学習技術の 1 つである AlphaChip は、人間と同等かそれ以上のチップ レイアウト設計を、数週間から数か月かかる手作業ではなく、わずか数時間で完了することができます。この画期的な開発は、従来の限界を超えて私たちの想像力への扉を開きました。
では、AlphaChip はどのようにしてこの偉業を達成したのでしょうか?
AlphaChip の秘密は、チップ レイアウト設計をゲームとして扱う強化学習へのアプローチにあります。 AlphaChip は、空のグリッドから始めて、すべてが所定の位置に配置されるまで、各回路コンポーネントを徐々に配置します。その後、レイアウトの品質に基づいて、システムは対応する報酬を与えます。
さらに重要なことは、Google が「エッジベース」のグラフ ニューラル ネットワークを革新的に提案したことです。これにより、AlphaChip はチップコンポーネント間の相互関係を学習し、それをチップ全体の設計に適用することで、あらゆる設計で自己超越性を実現します。 AlphaGo と同様に、AlphaChip は「ゲーム」を通じて学習し、優れたチップ レイアウトを設計する技術を習得できます。
TPU レイアウトを設計する具体的なプロセスでは、AlphaChip はまず、オンチップおよびチップ間ネットワーク モジュール、メモリ コントローラー、データ送信バッファーなど、前世代のチップのさまざまなモジュールに対して事前トレーニングを実施します。この事前トレーニング段階では、AlphaChip に豊富な経験を提供します。その後、Google は AlphaChip を使用して、現在の TPU モジュール用の高品質のレイアウトを生成しました。
従来の方法とは異なり、AlphaChip は、人間の専門家が練習を通じてスキルを向上させ続けるのと同じように、より多くのチップ レイアウト タスクを解決することで継続的に最適化します。 DeepMind の共同創設者兼 CEO の Demis Hassabis 氏は次のように述べています。Google は、AlphaChip を中心とした強力なフィードバック ループを構築しました。
* まず、高度なチップ設計モデル (AlphaChip) をトレーニングします
* 2 番目に、AlphaChip を使用してより優れた AI チップを設計する
* 次に、これらの AI チップを使用して、より良いモデルをトレーニングします
* 最後に、これらのモデルを使用してより良いチップを設計します
モデルと AI チップは繰り返しアップグレードされており、「これが Google TPU スタックのパフォーマンスが非常に優れている理由の 1 つです」と Demis Hassabis 氏は述べています。
AlphaChip は人間の専門家よりも多くのモジュールを配置するだけでなく、配線の長さも大幅に短くなります。新世代の TPU が導入されるたびに、AlphaChip はより優れたチップ レイアウトを設計し、より完全な全体的なフロア プランを提供することで、設計サイクルを短縮し、チップのパフォーマンスを向上させます。
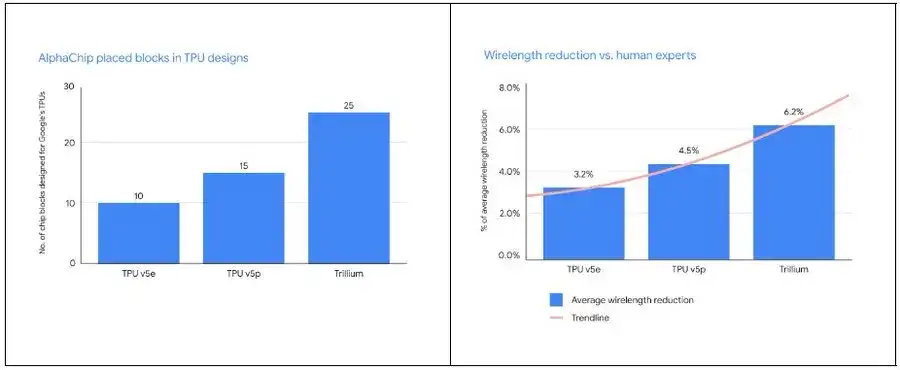
Google TPU の 10 年間の旅: ASIC の固執から AI 設計の革新まで
TPU 分野の探検家および先駆者として、このテクノロジー分野における Google の開発の歴史を見ると、Google はその鋭い洞察力に頼っているだけでなく、並外れた勇気を示しています。
誰もが知っているように、1980年代には、ASIC (特定用途向け集積回路) は、高い費用対効果、強力な処理能力、高速性が特徴です。市場から幅広い支持を得ています。ただし、ASIC の機能はカスタム マスク ツールによって決定されるため、顧客は高額な非経常エンジニアリング (NRE) コストを前払いする必要があります。
現時点では、FPGA (フィールド プログラマブル ゲート アレイ) には、初期費用を削減し、デジタル ロジックをカスタマイズするリスクを軽減できるという利点があります。世間の注目を集めるようになり、性能が完全に優れているわけではありませんが、市場ではユニークです。
当時、業界では一般に、ムーアの法則によって FPGA のパフォーマンスが ASIC のニーズを超えて向上するだろうと予測していました。しかし、FPGA はプログラマブルな「汎用チップ」として、未開発の少量生産製品で優れたパフォーマンスを発揮し、GPU よりも優れた速度、消費電力、またはコスト指標を達成できることがわかっていますが、依然として「汎用性」を取り除くことはできません。最適性を同時に達成することはできません。」 FPGA が特殊なアーキテクチャへの道を開くと、より特殊な ASIC に道を譲ります。
21 世紀に入ってから、機械学習およびディープラーニング アルゴリズムに対する熱意はますます高まっており、高性能、低消費電力の専用 AI コンピューティング チップに対する需要が高まっています。 . 多くの複雑なタスクでは効果がありません。こうした状況を背景に、Google は 2013 年に大胆な決断を下しました。TPU インフラストラクチャを構築し、TensorFlow と JAX を中心に開発するには、ASIC を選択してください。
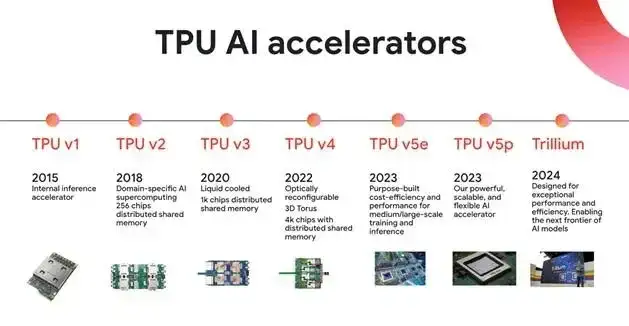
ASIC の独立した研究開発は、長いサイクル、多額の投資、高い敷居と大きなリスクを伴うプロセスであることは注目に値します。一度間違った方向を選択すると、多大な経済的損失を引き起こす可能性があります。しかし、より費用対効果が高く、エネルギーを節約できる機械学習ソリューションを模索するために、Google は 2012 年にディープラーニングによる画像認識で画期的な進歩を遂げた後、2013 年にすぐに TPUv1 の開発を開始し、2015 年に第 1 世代を発表しました。チップ (TPU v1) は内部でオンラインになっており、世界初のAI専用アクセラレーターの誕生です。
幸いなことに、TPU はすぐに注目を集めるデモンストレーションの機会をもたらしました。2016 年 3 月には、AlphaGo Lee が世界囲碁チャンピオンである Lee Sedol に勝利しました。AlphaGo シリーズの第 2 世代バージョンとして、TPU は計算に 50 TPU を消費します。 。
しかし、TPU はすぐには業界で大規模な応用に成功しませんでした。TPU が真に新しい開発段階に入ったのは、AlphaChip チップ レイアウト手法が提案されてからでした。
2020年、Googleはプレプリント論文「深層強化学習によるチップ配置」でAlphaChipの機能を実証した。過去の経験から学習して継続的に改善することができ、さまざまなネットリストとそのレイアウトを正確に予測できる報酬ニューラル アーキテクチャを設計することで、入力ネットリストの豊富な機能埋め込みを生成できます。
AlphaChip は、パフォーマンス最適化の条件をゲームの勝利条件とみなし、強化学習手法を採用し、累積報酬の最大化を目標にエージェントをトレーニングすることでチップ レイアウトの能力を継続的に最適化します。彼らは 10,000 のゲームを開始し、AI が 10,000 個のチップ上でレイアウトとルーティングを練習し、データを収集しながら、継続的に学習と最適化を行えるようにしました。
最終的に、AI は人間のエンジニアと比較して、面積、消費電力、配線の長さの点で手動のレイアウトを上回ったり、同等のパフォーマンスを示し、設計基準を満たすのにかかる時間が大幅に短縮されたことがわかりました。結果は次のことを示していますAlphaChip は、最新のアクセラレータ ネットリストに対する手動作業に匹敵する、またはそれを超えるレイアウトを 6 時間以内に生成できます。同じ条件下では、既存の人間の専門家が同じ作業を完了するのに数週間かかる場合があります。
AlphaChip の助けにより、Google は TPU への依存度を高めています。 2023年12月Google は、マルチモーダルな一般的な大規模モデルである Gemini の 3 つの異なるバージョンをリリースしました。このモデルのトレーニングでは、Cloud TPU v5p チップが広範囲に使用されています。 2024 年 5 月Google は、第 6 世代 TPU チップ Trillium をリリースしました。これは、単一の高帯域幅、低レイテンシーのポッド内で最大 256 個の TPU のクラスターに拡張できます。前世代の製品と比較して、Trillium はモデル トレーニングに適応する強力な機能を備えています。 。
同時に、TPU チップは徐々に Google を超えて市場で広く認知されるようになりました。 2024 年 7 月 30 日Appleは発表した研究論文の中で、Apple Intelligenceエコシステムで人工知能モデルAFMをトレーニングする際に、Googleから2つのテンソルプロセッシングユニット(TPU)クラウドクラスタを選択したと主張した。他のデータによると、60% を超える生成 AI スタートアップ企業と、90% 近くの生成 AI ユニコーン企業が Google Cloud の AI インフラストラクチャと Cloud TPU サービスを使用していることがわかります。
Googleが10年間刀を研ぎ続けた後、TPUが育成期を脱し、その優れたハードウェア性能をAI時代にGoogleにフィードバックし始めたことを示すさまざまな兆候があります。AlphaChip に含まれる「AI 設計 AI チップ」の道も、チップ設計の分野に新たな地平を切り開きます。
AI がチップ設計に革命を起こす: Google AlphaChip からフルプロセス自動化の探求まで
AlphaChip は AI 設計チップの分野ではユニークですが、それだけではありません。 AI テクノロジーの範囲は、チップの検証やテストなどの多くの重要なリンクに広く拡張されています。
チップ設計の中核となるタスクは、チップの消費電力 (Power)、パフォーマンス (Performance)、および面積 (Area) を最適化することです。この課題は、総称して PPA と呼ばれます。従来、このタスクは EDA ツールによって実行されていましたが、最適なパフォーマンスを達成するために、チップ エンジニアは常に手動で調整を行った後、再度最適化するために EDA ツールに引き渡すなどの作業を行う必要がありました。このプロセスは、自宅で家具を配置するのと似ており、常にスペースを最大限に活用し、動線を最適化しようとしますが、各調整は家具を移動して並べ替えることに相当し、非常に時間と労力がかかります。
この問題を解決するには、シノプシスは 2020 年に DSO.ai を立ち上げました。これは、AIとEDAを統合した業界初のチップ設計ソリューションです。 DSO.ai は強化学習テクノロジーを使用し、AI を通じて設計空間を自動的に検索し、手動介入なしで最適なバランス ポイントを見つけます。このツールは多くのチップ大手によって使用されています。
たとえば、Microsoft は DSO.ai を使用した後、同じパフォーマンスを維持しながらチップ モジュールの消費電力を 10% ~ 15% 削減しました。STMicroelectronics は、メモリ チップ大手の SK Hynix によってチップ面積を 3 倍以上増加させました。 5%。シノプシスのデータによると、DSO.ai は 300 件を超える商用テープアウトの支援に成功しており、実際のチップ設計と製造において AI が重要な役割を果たしていることがわかります。
AI支援によるチップ検証に関しては、シノプシスが発表した技術レポートでも、検証プロセスにはチップ開発サイクル全体の最大70%がかかると指摘している。チップのテープアウトにかかるコストは数億ドルにもなり、最新のチップは複雑さが増し続けているため、検証が困難になっています。この目的を達成するために、シノプシスは VSO.ai ツールを立ち上げ、AI を使用して検証スペースを最適化し、カバレッジの収束を加速します。
VSO.ai は、さまざまなカバレッジ タイプを推測し、従来のコード カバレッジを補完し、検証経験から学習してカバレッジ目標を継続的に最適化することもできます。さらに、シノプシスは、チップ開発者がファウンドリによって製造された欠陥のあるチップを選別するのに役立つ TSO.ai ツールも開始しました。
チップ設計の分野における AI の深い関与は、「AI を使用して完全なチップを設計できるか?」という大胆なアイデアを引き起こしました。実際、Nvidia はすでにこの分野に挑戦しています。深層強化学習エージェントを通じて回路を設計し、NVIDIA の H100 のほぼ 13,000 の回路は AI によって設計されました。中国科学院計算技術研究所もAIを活用し、「Qiu Meng No.1」と呼ばれるRISC-Vプロセッサチップを5時間以内に生成した。400 万の論理ゲートを備え、そのパフォーマンスは Intel 80486 に匹敵します。
全体として、完全なチップを設計する AI の能力にはまだ限界がありますが、これは間違いなく将来のチップ開発にとって重要な機会です。テクノロジーの継続的な進歩により、チップ設計分野における AI の可能性は確実にさらに探求され、活用され、最終的にはチップ設計プロセス全体が変化するでしょう。








