Command Palette
Search for a command to run...
主よ、時代はまた変わりました! SD の中心メンバーが独自のビジネスを立ち上げ、最初のモデル FLUX.1 が SD 3 と Midjourney に強化されました

多様な芸術スタイルを備えた Midjourney から、OpenAI を利用した DALL-E、オープンソースの Stable Diffusion (SD) に至るまで、長い間、Vincent ダイアグラム モデル生成の品質と速度は継続的にアップグレードされ、迅速な理解と詳細な処理が行われてきました。も改良され、主要モデルの採用に向けた新たな方向性が生まれました。
2024 年に入ってからは、「二人の英雄」段階にある Midjourney と Stable Diffusion が相次いで取り組み、まず SD 3 がリリースされ、その後 Midjourney V6.1 もアップデートが繰り返されました。しかし、人々がまだ SD 3 と Midjourney の比較に夢中になっているとき、新世代の「魔王」が静かに誕生した――FLUXが誕生した。
FLUX がキャラクター、特に実際のキャラクターのシーンを生成すると、その効果は実際のショットに非常に近く、キャラクターの表情、肌の光沢、髪型、髪の色などの細部が非常にリアルになります。かつては Stable Diffusion の後継としても知られていました。興味深いことに、この 2 つは実際に密接な関係があります。
FLUX の背後にあるチームである Black Forest Labs の創設者である Robin Rombach は、Stable Diffusion の共同開発者の 1 人です。 ロビンは、Stability AI を辞めた後、Black Forest Labs を設立しました。FLUX.1モデルを発売しました。
現在、FLUX.1 には Pro、Dev、および Schnell の 3 つのバージョンが提供されています。 Pro バージョンは、API を通じて提供されるクローズド ソース バージョンで、ビジネスに使用でき、最も強力なバージョンでもあります。Dev バージョンは、Pro バージョンから直接「抽出」された、非商用ライセンス付きのオープン ソース バージョンです。 Schnell バージョンは最速です。合理化されたバージョンは最大 10 倍高速に実行されると言われており、オープン ソースであり、Apache 2 ライセンスに基づいてライセンスされており、ローカル開発および個人使用に適しています。
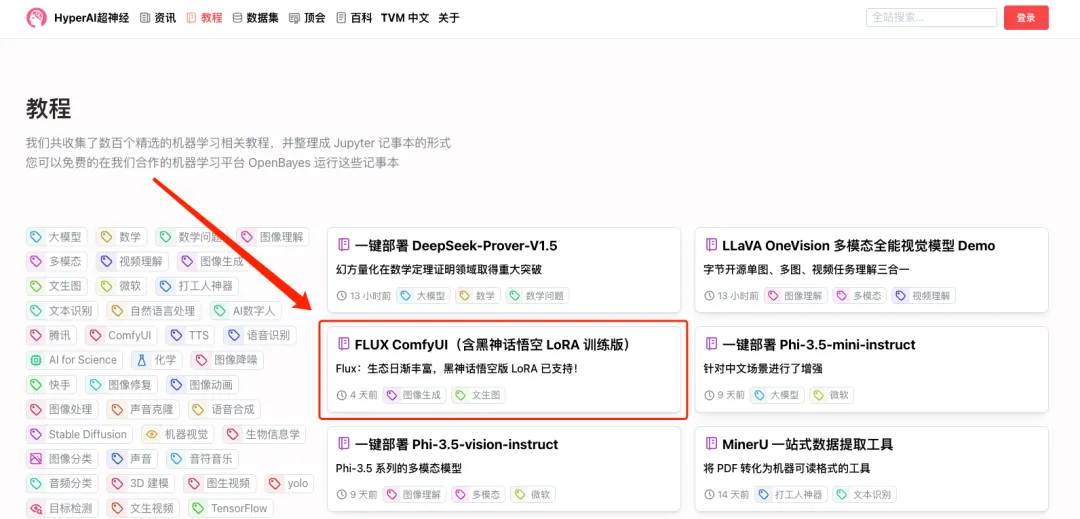
多くの友人がこの新世代の一流の文生図を実際に体験したいと思っていると思います。HyperAI 公式 Web サイト (hyper.ai) のチュートリアル セクションでは、FLUX [dev] の ComfyUI バージョンであり、LoRA トレーニングにも対応した「FLUX ComfyUI (Black Myth Wukong LoRA training version を含む)」を公開しました。
興味のある方は今すぐ体験しに来てください!編集者がみんなで試してみましたが、効果はSD3やMidjourneyと比べても遜色ありません↓

同じプロンプト、3 つのモデルがそれぞれ生成する効果
* プロンプト: 女の子が「私は AI です」と書かれた看板を持っています。
さらに、ステーション B の人気 Up ホストである Jack-Cui も、誰もが段階的に学べる詳細な操作チュートリアルを作成しました。
チュートリアルのアドレス:
操作ビデオ:
https://www.bilibili.com/video/BV1xSpKeVEeM
デモの実行
FLUX ComfyUI の実行
1. hyper.ai にログインし、[チュートリアル] ページで [このチュートリアルをオンラインで実行する] をクリックします。 「FLUX ComfyUI (Black Myth Wukong LoRA トレーニング バージョンを含む)」で、「このチュートリアルをオンラインで実行する」をクリックします。
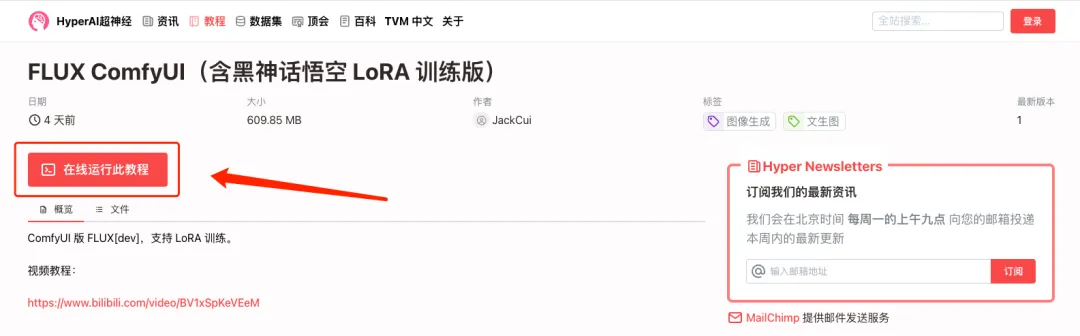
2. ページがジャンプしたら、右上隅の「クローン」をクリックしてチュートリアルを独自のコンテナにクローンします。
3. 右下隅の「次へ: コンピューティング能力の選択」をクリックします。
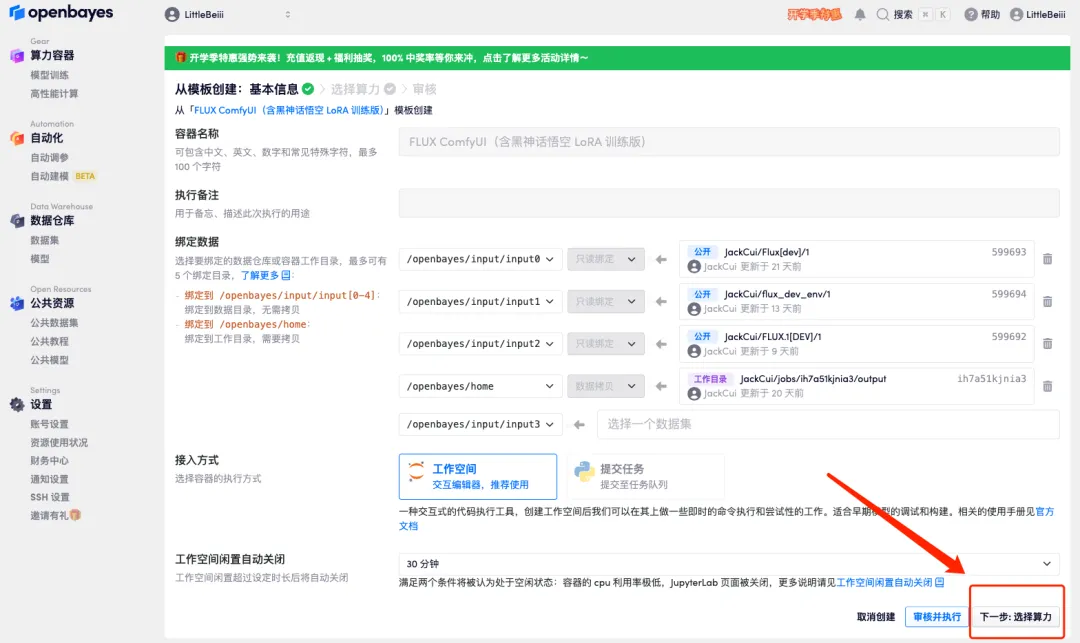
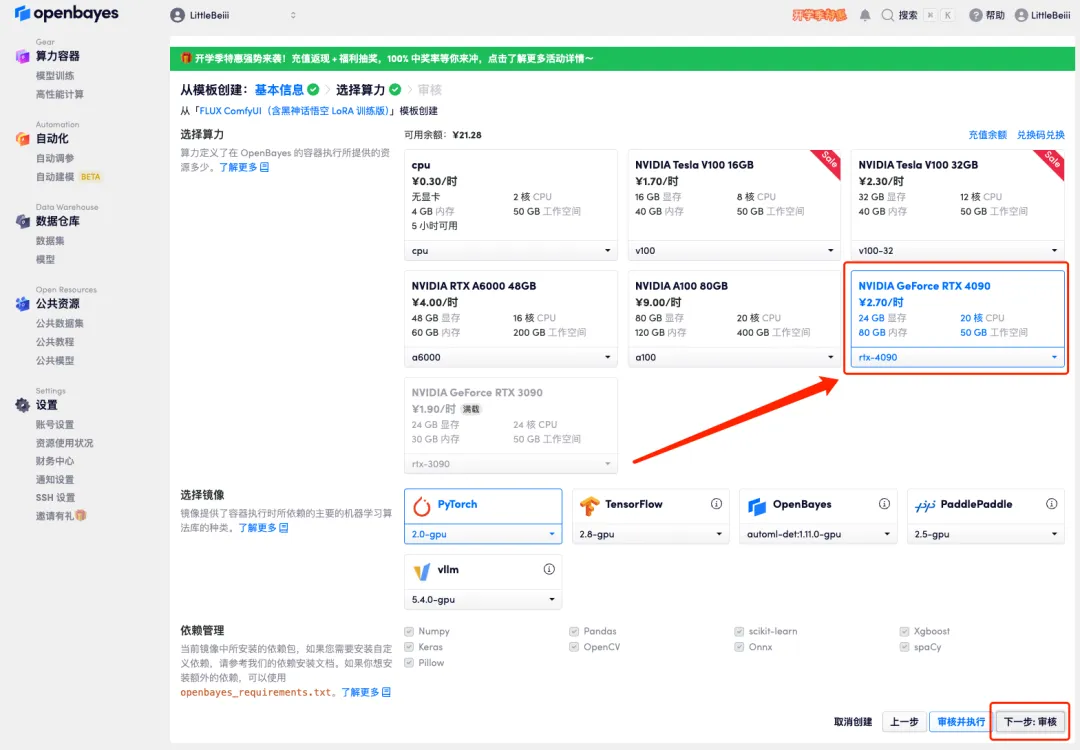
4. ページがジャンプしたら、「NVIDIA RTX 4090」と「PyTorch」のイメージを選択し、「次へ: レビュー」をクリックします。以下の招待リンクを使用してサインアップした新規ユーザーは、4 時間の RTX 4090 + 5 時間の CPU を無料で入手できます。
HyperAI ハイパーニューラルの専用招待リンク (ブラウザに直接コピーして開きます):
https://openbayes.com/console/signup?r=6bJ0ljLFsFh_Vvej
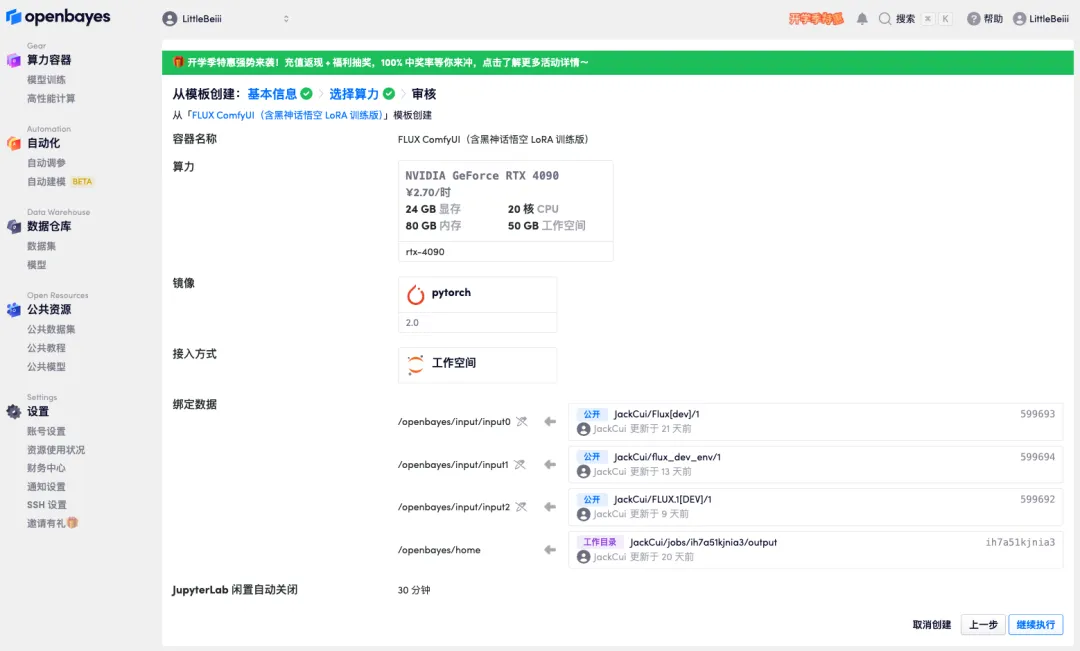
5. すべてが正しいことを確認したら、「続行」をクリックし、最初のクローンが割り当てられるまで待ちます。ステータスが「実行中」に変わったら、「API アドレス」の横にあるジャンプ矢印をクリックしてデモ ページにジャンプします。APIアドレスアクセス機能を利用するには実名認証が必要となりますのでご注意ください。
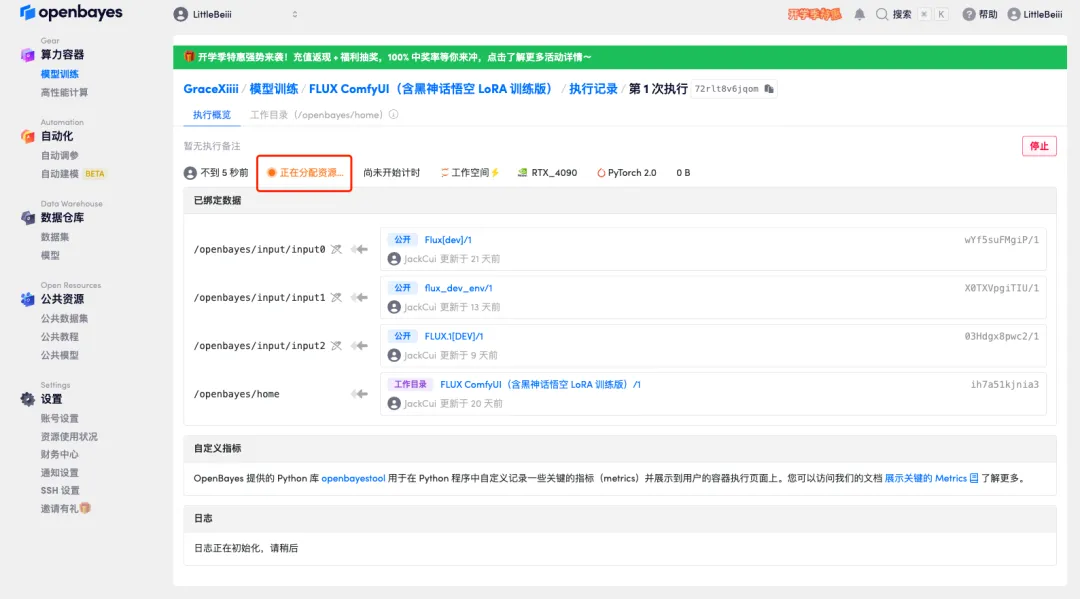
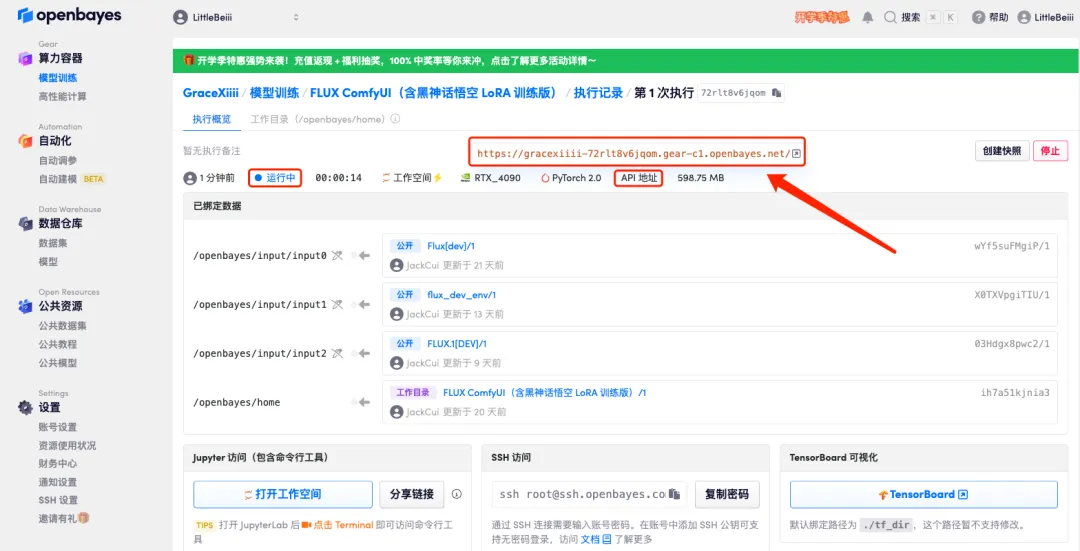
6. デモを開いた後、「ロケールの切り替え」をクリックして言語を中国語に切り替えます。
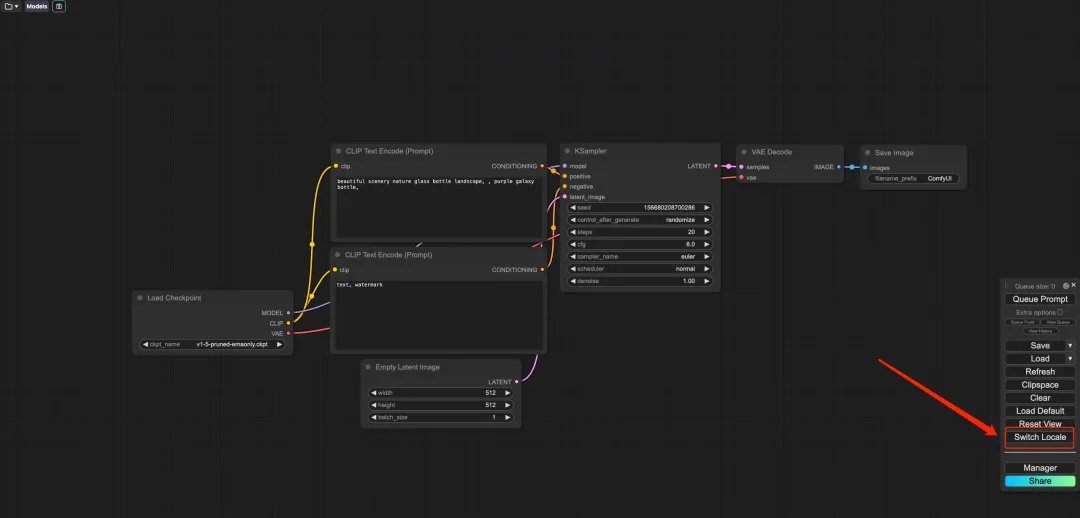
7. 言語を切り替えた後、左上隅のフォルダー アイコンをクリックして、目的のワークフローを選択します。
* wukong: Black Myth Wukong イメージデモ
* TED: TED ライブスピーチデモ
* 3mm4w: 写真にテキストを書き込むデモ
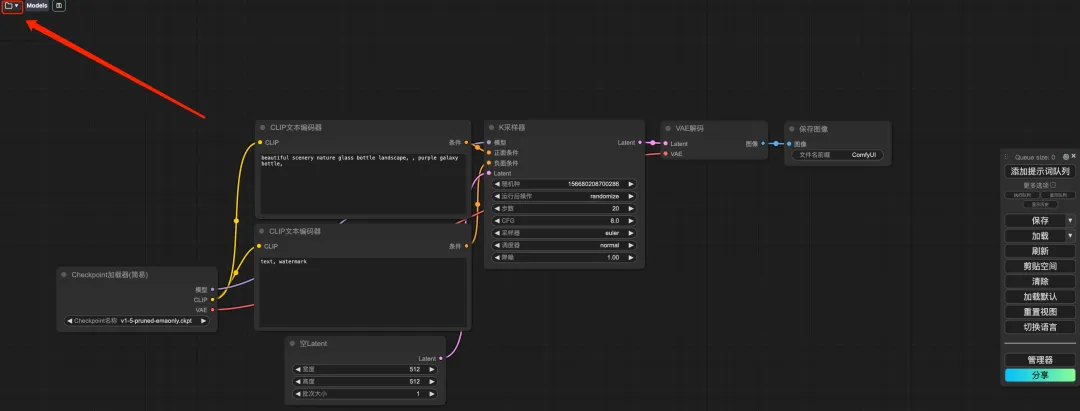
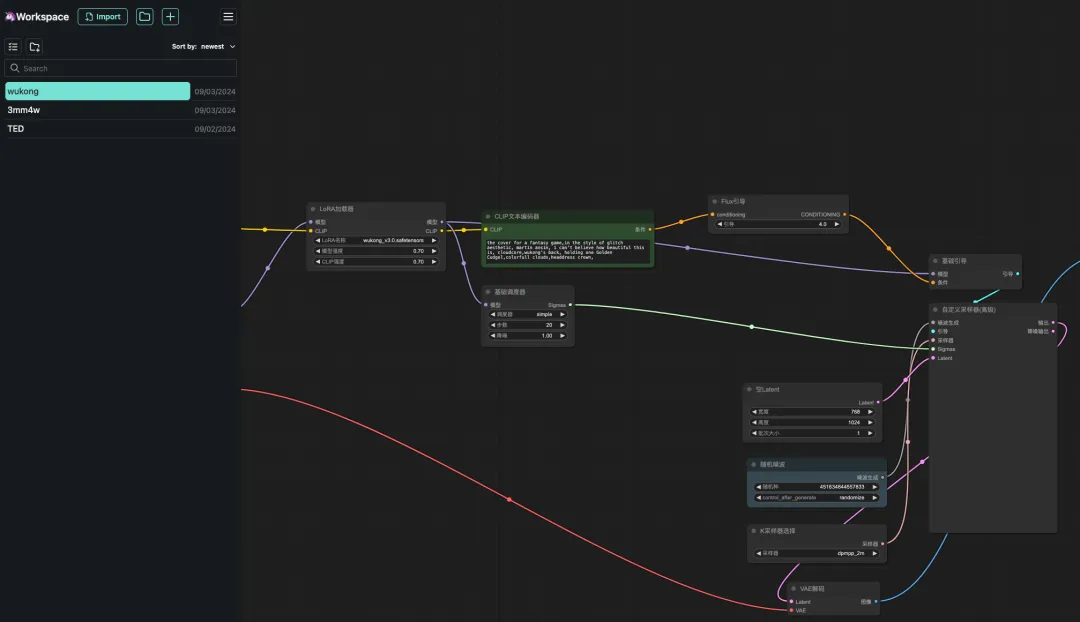
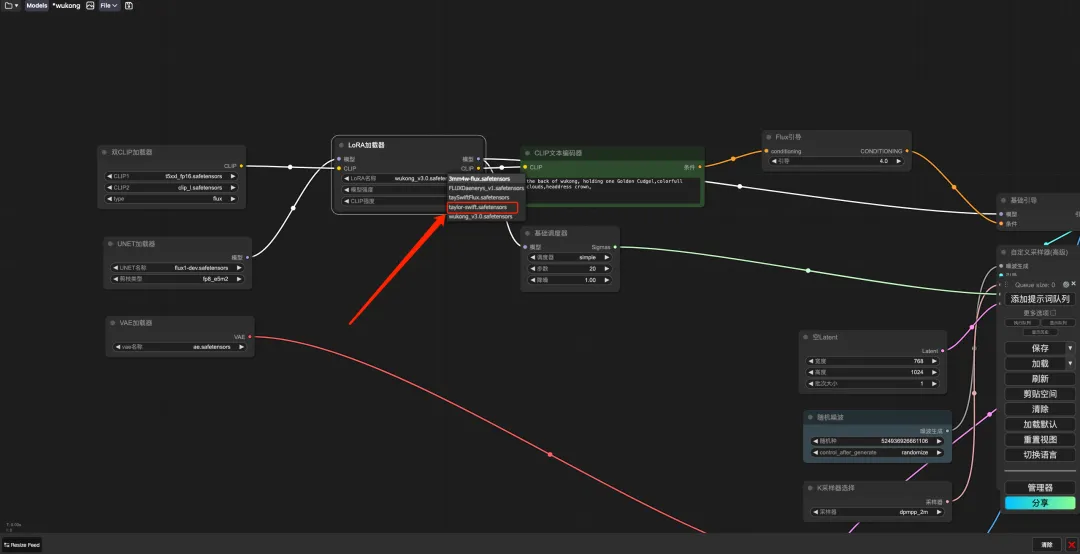
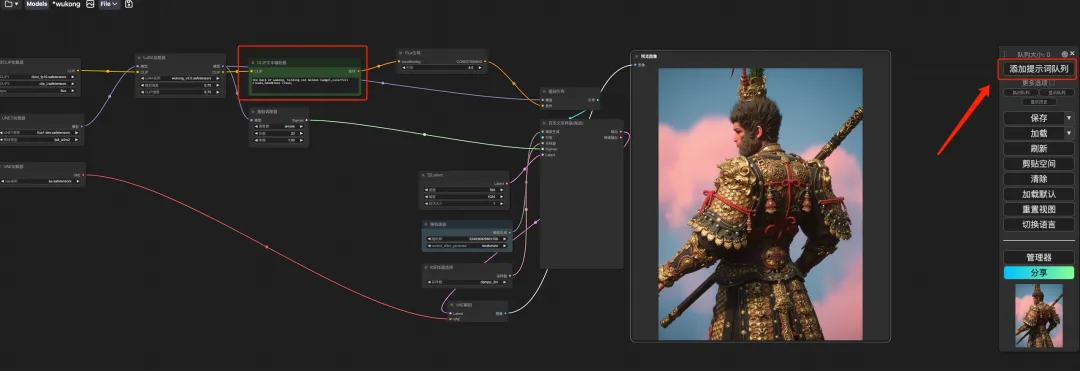
8. 「悟空」ワークフローを選択し、CLIP テキスト ジェネレーターに「プロンプト」と入力し (例: 悟空の背中、金のこん棒を 1 つ持つ、カラフルな雲、頭飾りの王冠)、「画像を生成するためのプロンプト ワード キューを追加」をクリックすると、次のことができます。生成された写真は非常に美しいです。

FLUX LoRA トレーニング
1. ワークフローをカスタマイズするには、まず LoRA モデルをトレーニングし、先ほどのコンテナー インターフェイスに戻り、[ワークスペースを開く] をクリックして、新しいターミナルを作成する必要があります。
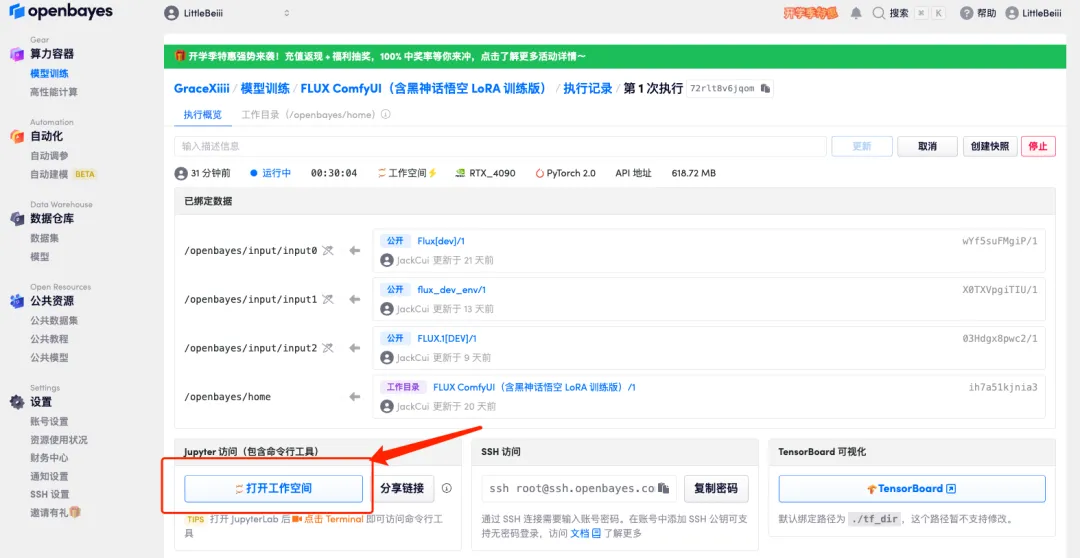
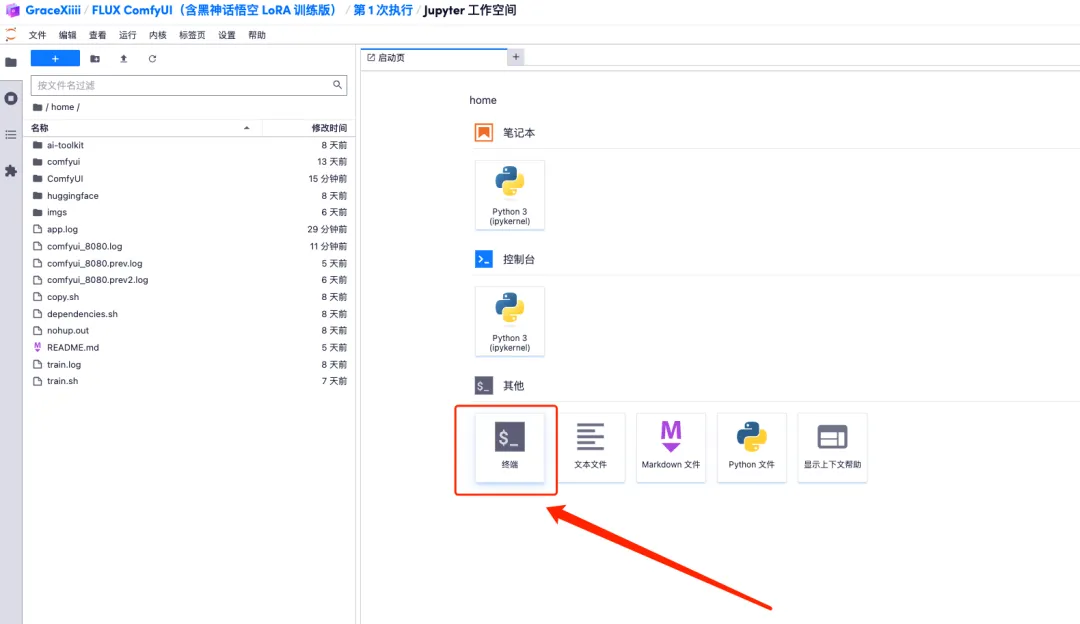
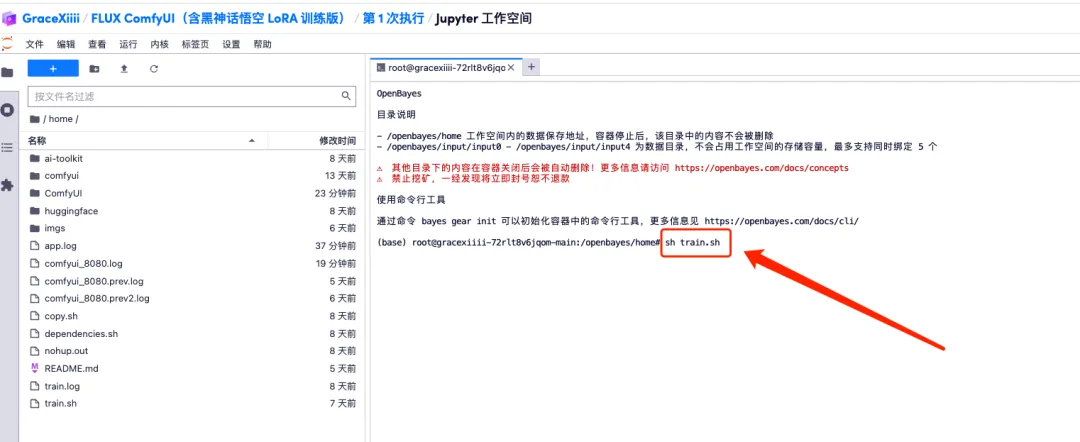
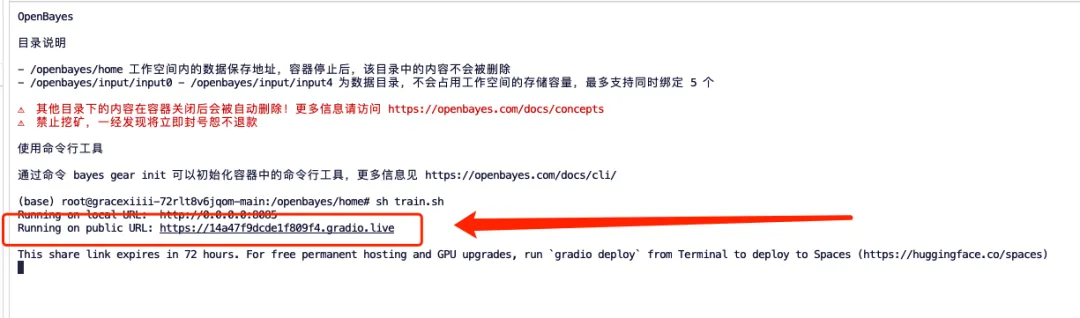
2. ターミナルに「sh train.sh」と入力し、Enter キーを押して実行し、「パブリック URL で実行中」と表示されたら、リンクをクリックします。
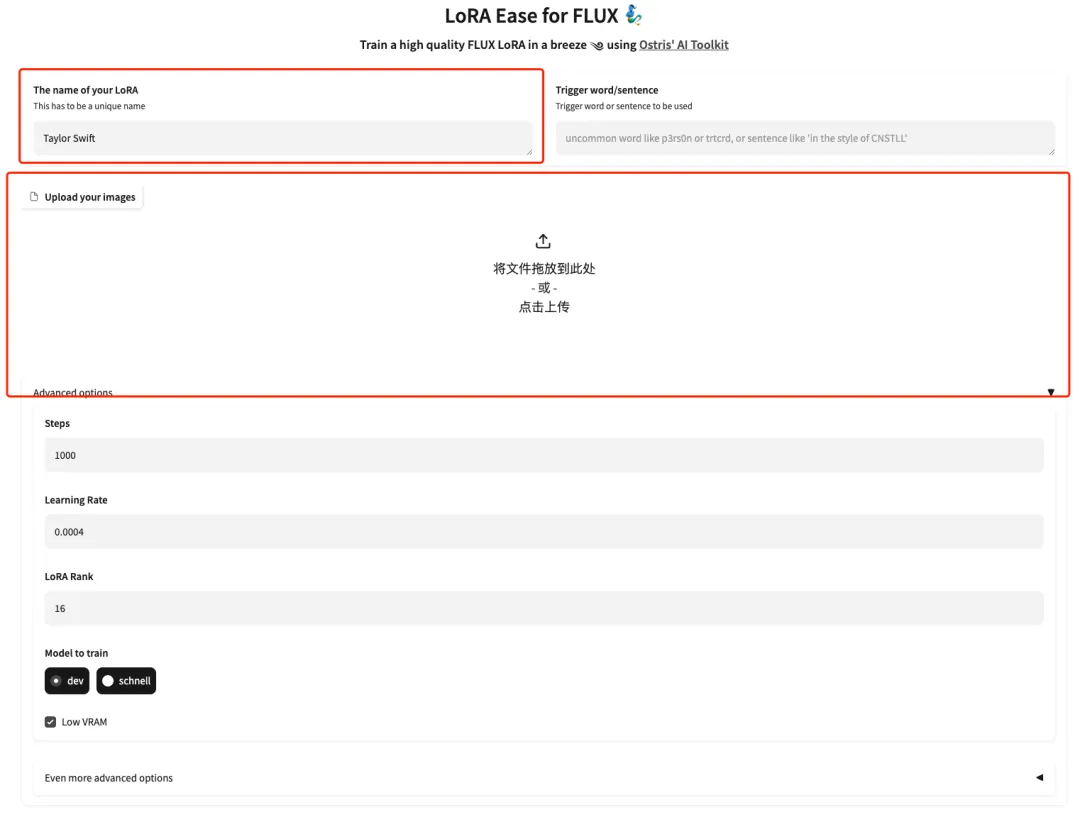
3. ページが飛んだので、モデルのモデルを入力し、ここにテイラー・スウィフトの写真を 5 枚アップロードします。画像は顔の割合が大きい高解像度の正面写真である必要があることに注意してください。画像の品質が高いほど、トレーニング効果は高くなります。
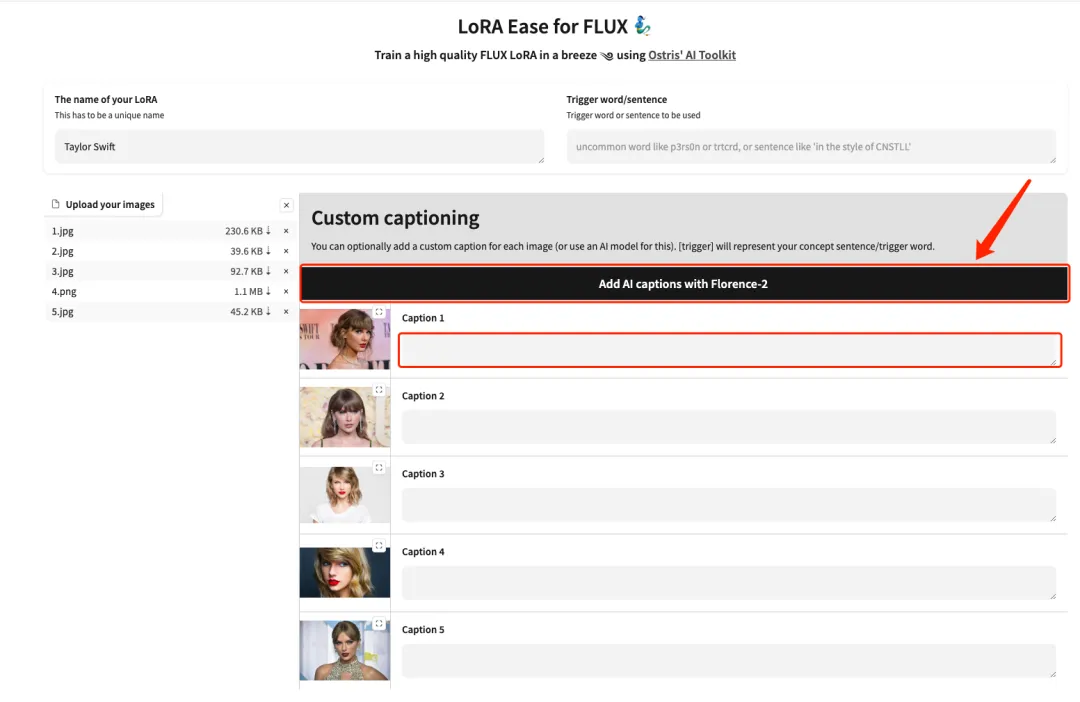
4. アップロードが成功したら、各画像の後ろに英語のテキスト説明を手動で追加するか、[Florence-2 で AI キャプションを追加] をクリックしてテキスト説明を自動的に生成します。
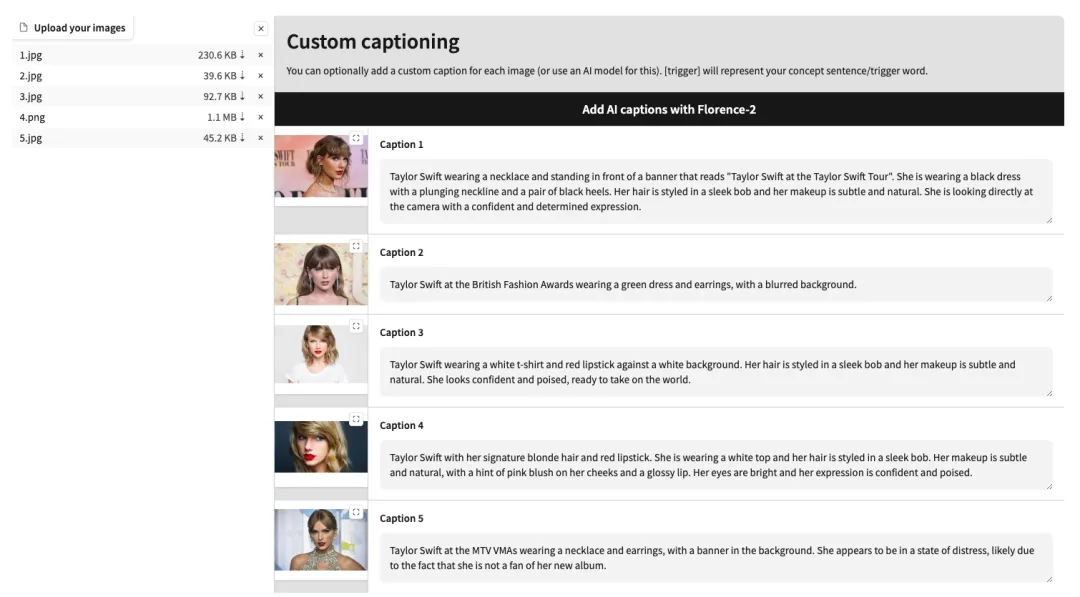
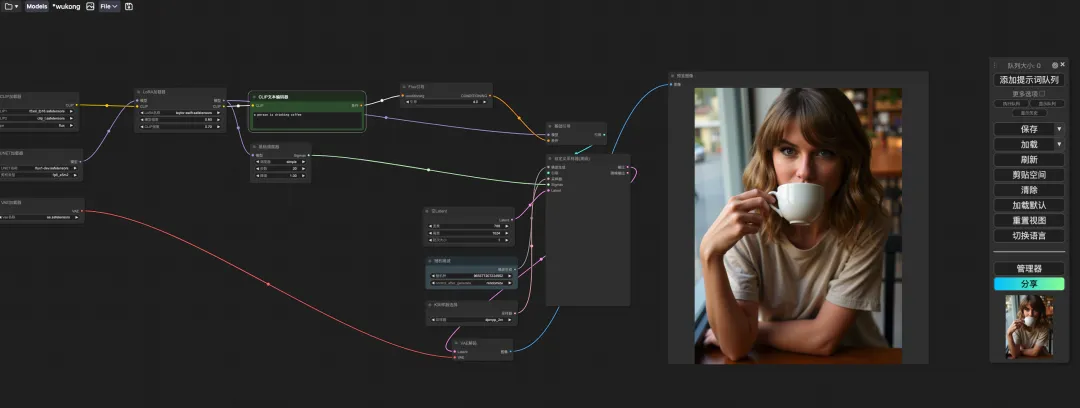
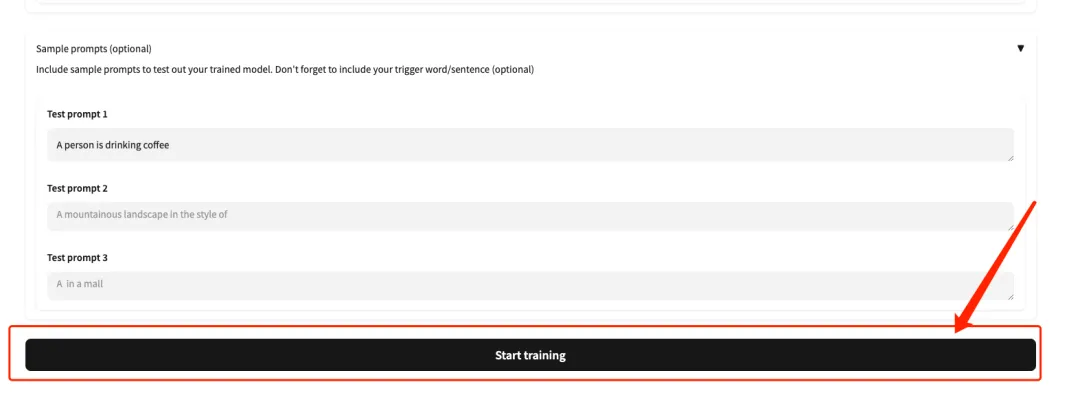
5. ページの一番下までスクロールし、テスト プロンプト (例: 人はコーヒーを飲んでいます) を入力し、[トレーニングの開始] をクリックします。
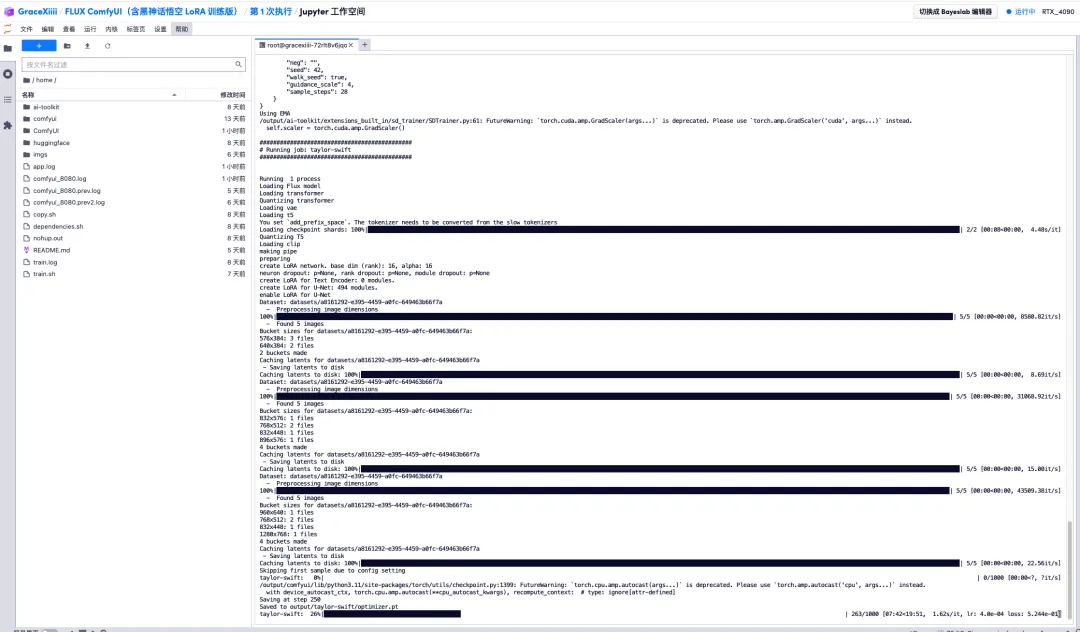
6. 数分間待った後、先ほどのターミナル インターフェイスに戻り、トレーニングの進行状況バーが表示されます。トレーニングは約 40 分で完了します。 「output/taylor-swift/optimizer.ptに保存されました」と表示されたらトレーニングは完了です。
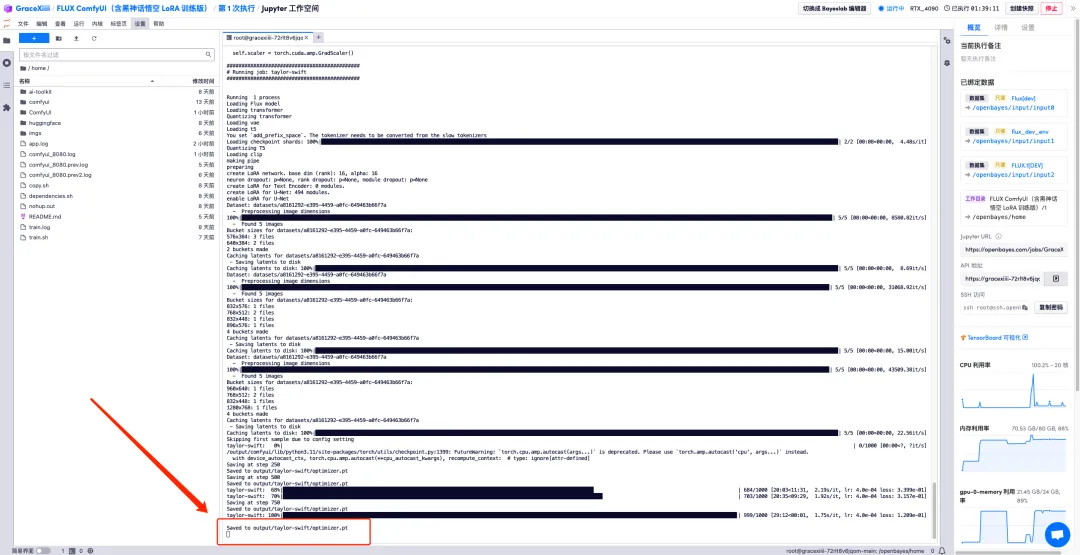
7. 左側の「ai-toolkit」-「output」-「taylor swift」-「sample」ファイルで、先ほどのテスト プロンプトの効果を確認できます。効果が良好であれば、モデルが適切であることが証明されます。はトレーニングに成功しました。
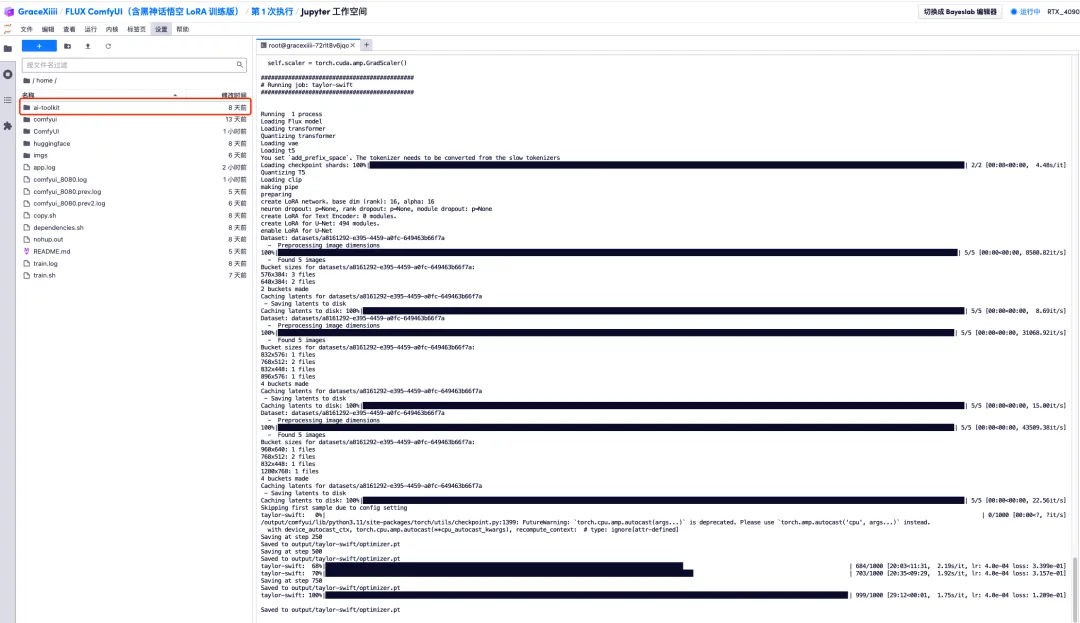
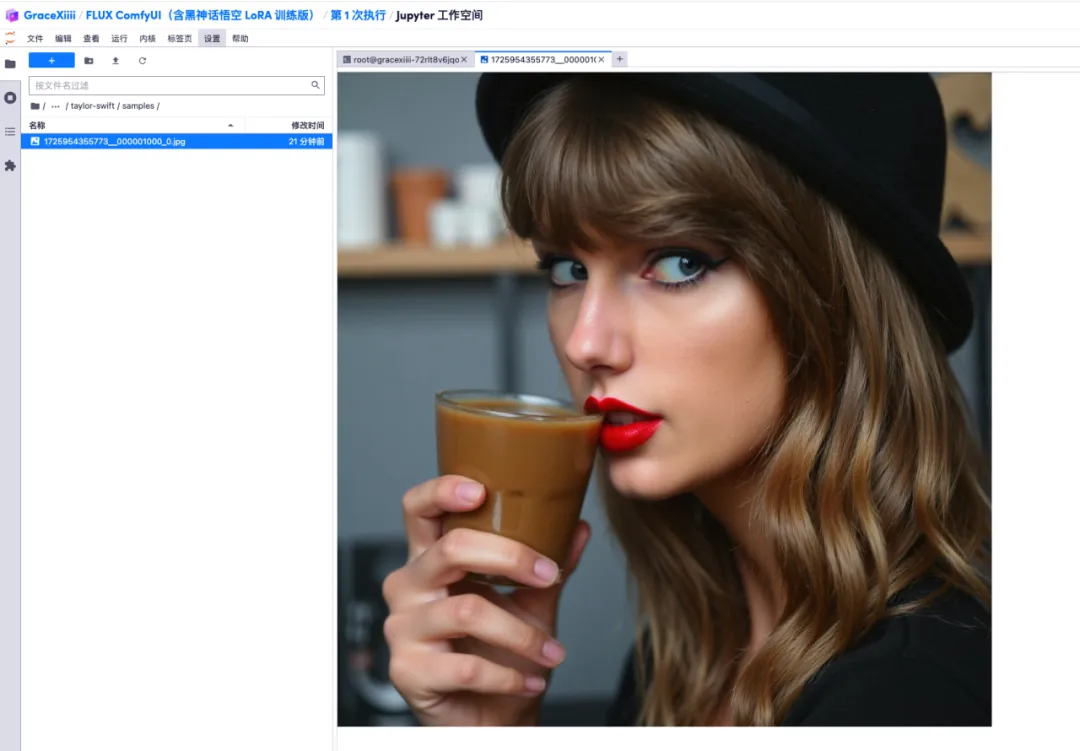
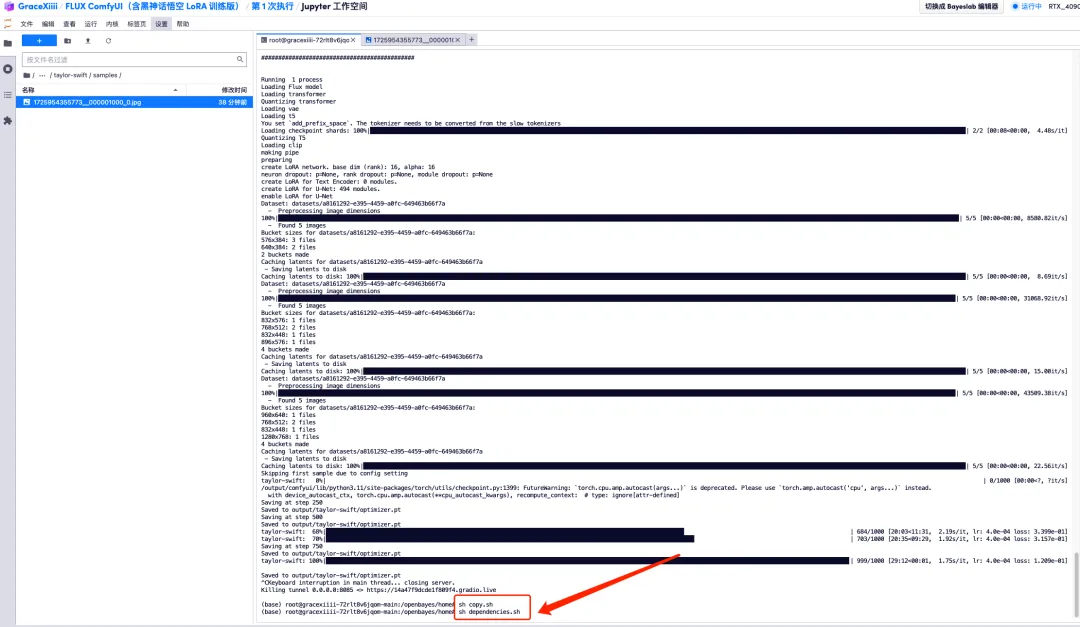
8. モデルがトレーニングされた後、トレーニング サービスをオフにし、GPU リソースを解放し、先ほどのキー インターフェイスに戻り、「Ctrl+C」を押してトレーニングを終了する必要があります。
9. 「sh copy.sh」を実行し、次に「sh dependency.sh」を実行して ComfyUI を起動します。2 分間待った後、右側の API アドレスを開きます。
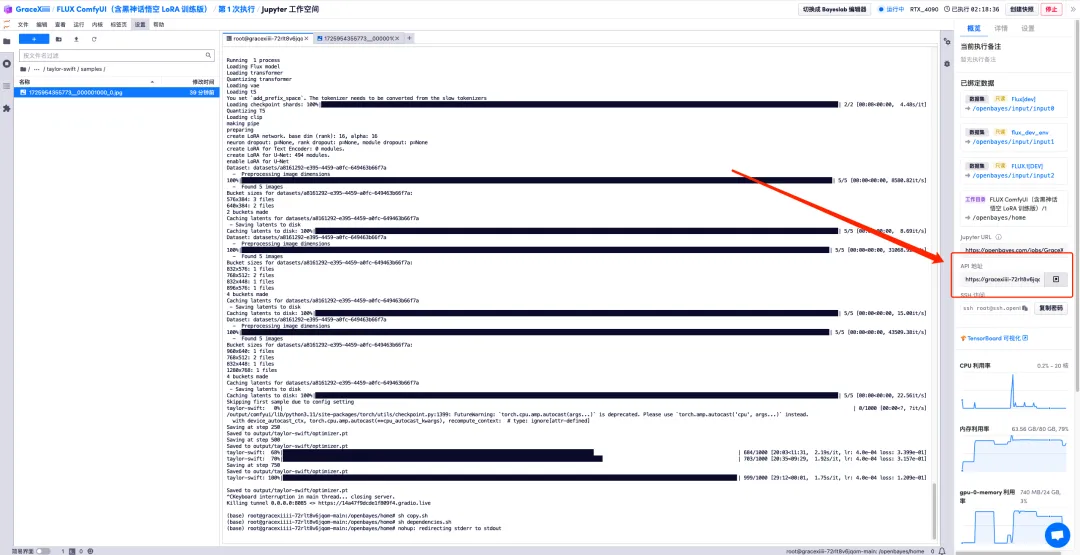
10. ページがジャンプしたら、「LoRA Loader」でトレーニングしたばかりのモデルを選択し、「CLIP」にプロンプト(例:コーヒーを飲んでいる人)と入力し、「プロンプトワードキューを追加」をクリックして画像を生成します。