Command Palette
Search for a command to run...
感度が向上した56%、香港チャイニーズ/復丹/エール大学などが共同で新たなタンパク質ホモログ検出法を提案

タンパク質は生命の物質的基盤であり、生命活動の主な担い手です。ポストゲノム時代では、タンパク質測定技術の発展に伴い、タンパク質配列データベースのサイズが爆発的に増大しました。タンパク質の多様性と機能を深く理解するために、タンパク質を同定することは生物学において特に重要です。
タンパク質同定のプロセスにおいて、タンパク質配列相同性の同定は重要なタスクの 1 つです。これは、科学者がタンパク質の進化の関係、構造的特徴、機能を理解するのに役立ちます。従来のタンパク質配列アラインメント法は多くの場合うまく機能しますが、遠い相同体に直面すると失敗します。これらの遠位ホモログは、配列類似性が低いために従来のアラインメントでは見落とされることが多く、タンパク質の多様性と複雑さについての研究者の包括的な理解を制限しています。
タンパク質の遠隔相同性研究の問題点を解決するために、タンパク質言語モデルと高密度検索技術 (高密度検索) に基づいて、香港中文大学の Li Yu 氏は、Intelligent Complex の若手研究者 Sun Siqi 氏とチームを組みました。復旦大学のシステム研究所と上海人工知能研究所、およびイェール大学のマークは、超高速かつ高感度のホモログ検出フレームワークであるDense Homology Retriever (DHR)を提案しました。
DHR は、デュアルエンコーダー構造とタンパク質言語モデルの強力な機能を通じて、従来の配列アライメントに依存することなく、配列の奥深くに隠されたリモートのホモログを識別することができ、ホモログ同定の速度と感度に前例のない利点をもたらします。この研究は「ディープデンス検索を使用したタンパク質ホモログの高速で高感度な検出」と題され、国際的に有名な学術誌 Nature Biotechnology に掲載されました。
研究のハイライト:
* DHR は、以前の方法と比較して 10% 以上感度が向上し、アライメントベースの方法では同定が難しいサンプルのスーパーファミリー レベルで 56% 以上感度が向上します。
* DHR エンコーディングは、PSI-BLAST や DIAMOND などの従来の方法より 22 倍、HMMER より 28,700 倍高速にシーケンスとデータベースをクエリします。

用紙のアドレス:
https://doi.org/10.1038/s41587-024-02353-6
オープンソース プロジェクト「awesome-ai4s」は、100 を超える AI4S 論文の解釈をまとめ、大規模なデータ セットとツールを提供します。
https://github.com/hyperai/awesome-ai4s
より広範なタンパク質配列レパートリーを探索するために設計された、多次元的に構築されたデータセット
この研究で構築されたトレーニング セットには、UR90 から慎重に選択された 200 万個のクエリ シーケンスが含まれています。この研究では、JackHMMER アルゴリズムを使用して、Uni-Clust30 で候補配列を繰り返し検索し、候補配列をマルチプル シーケンス アラインメント (MSA) に合わせて整列させました。各 MSA には 1,000 の相同体が含まれており、最も関連性の高い配列のみが確実に保持されます。厳格なスクリーニングの後、JackHMMER が再デプロイされて、取得されたさまざまなシーケンスを処理し、公平な比較を容易にするために AF2 (AlphaFold 2) と同じハイパーパラメーター設定を使用しました。
大規模なデータセット研究の観点から、この研究では BFD/MGnify データセットを選択しました。これは、約 3 億個のタンパク質を含む大規模なデータベースであり、より広範囲のタンパク質配列の探索を可能にします。
DHR メソッド: 超高速かつ高感度のタンパク質ホモログ検索パイプライン
DHR 法の中心となるアイデアは、タンパク質配列を高密度の埋め込みベクトルにエンコードして、配列間の類似性を効率的に計算することです。具体的には、この研究では、ESM とアンサンブル対比学習技術を初期化することで配列エンコーダーを効果的にトレーニングし、それによってタンパク質言語モデルの構築のための条件を作成し、相同体を検索するために DHR をより効果的に使用できるようにします。
以下の図 a に示すように、デュアル エンコーダーのトレーニング フェーズが完了すると、この研究では高品質のオフラインタンパク質配列埋め込みを生成できます。この研究では、これらの埋め込みと類似性検索アルゴリズムを使用して、各クエリタンパク質の相同体を取得しました。類似性を検索指標として指定することで、従来の方法よりも効率的に類似タンパク質を見つけ、2 つのタンパク質間の類似性を利用してさらなる分析を行うことができました。最後に、JackHMMER は取得したホモログの MSA を構築し、この研究によりホモログを迅速かつ効果的に発見できる DHR テクノロジーを取得しました。
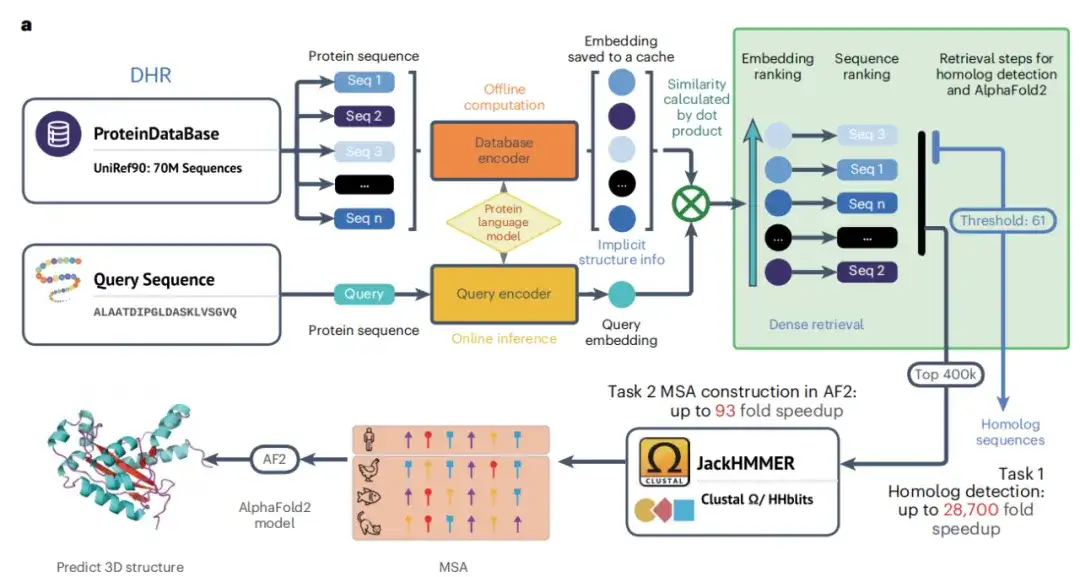
それだけでなく、この研究ではハイブリッド モデル DHR-meta も開発されました。このモデルは、DHR と AF2 デフォルトを組み合わせることにより、CASP13DM (ドメイン シーケンス) および CASP14DM ターゲットで個別のパイプラインよりも優れたパフォーマンスを発揮しました。
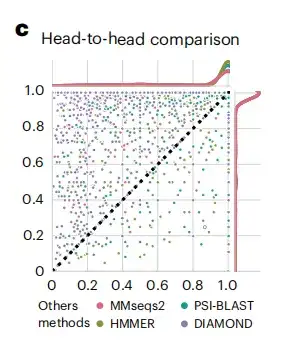
得られたタンパク質包埋物を取得した後、この研究では、標準的な SCOPe (タンパク質の構造分類) データセットの方法と比較することにより、DHR のパフォーマンスを評価します。以下の図 c に示すように、DHR データの感度は他の方法よりも優れています。
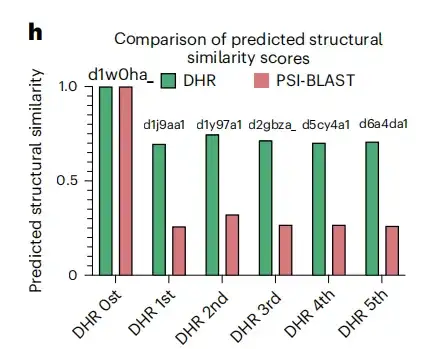
さらに、以下の図 h に示すように、d1w0ha クエリの特定の例では、PSI-BLAST も MMseqs2 も結果に一致しませんでしたが、DHR は 5 つのホモログを取得し、これらも同じファミリーの d1w0ha に割り当てられました。これは、DHR がより多くの構造情報を取得できることを意味します。 PSI-BLAST、MMseqs2、DIAMOND、HMMER などの従来の方法と比較して、DHR は最も多くのホモログを検出します (感度は 93%)。これは、DHR が豊富な構造情報を統合し、多くの場合 100% の感度を達成できることを示しています。
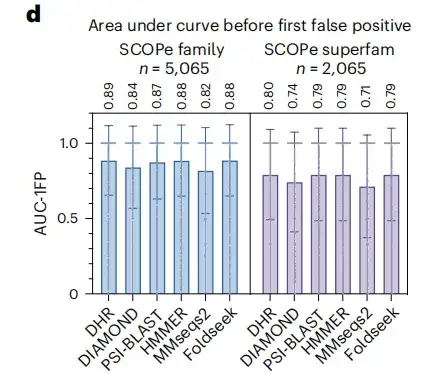
調査結果の信頼性を強化するために、この研究には別の標準指標である最初の FP 前の曲線下面積も含まれています。結果は、以下の図 d に示すように、DHR が 89% のスコアに達していることを示しています。同時に、他のメソッドも DHR と同等のパフォーマンスを示しますが、実行時間は大幅に長くなります。この研究で遠縁ホモログのより困難なスーパーファミリーレベルをさらに分析したところ、すべてのメソッドで大幅なパフォーマンス低下が発生し、全体で約 10% 減少しました。それにもかかわらず、DHR は依然として AUC-1FP スコア 80% という最高のパフォーマンスを維持しています。
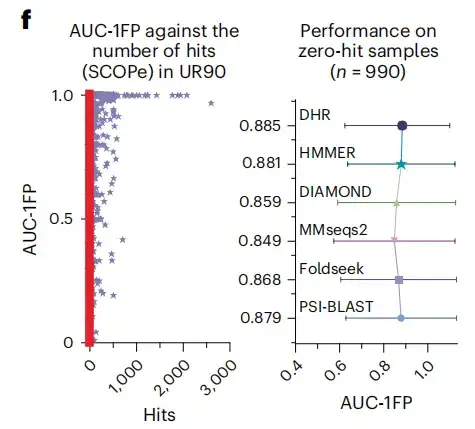
この研究では、BLAST を使用して SCOPe データベースと UniRef90 の比較分析を実行した場合、ほとんどのサンプルで生成された一致が 100 未満であり、約 500 のサンプルでさえ一致が得られなかったことも判明しました。これは、これらのサンプルがトレーニングに「満足していない」ことを示しています。以前見たデータセットの構造。比較として、DHR はこれらの構造に直面した場合でも高品質の予測を達成し、AUC-1FP スコア 89% に達しました。これは、DHR がまったく新しいデータを処理できることを示しています。
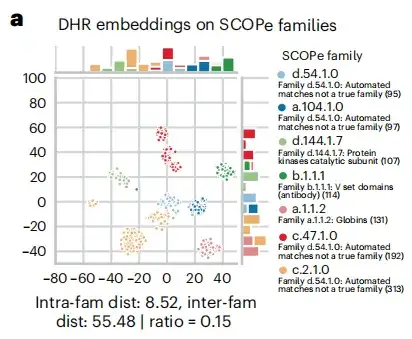
相同性検索プロセスでは、以下の図 a に示すように、DHR 配列の埋め込みには大量の構造情報が含まれており、DHR による相同性検索の精度は構造ベースのアライメント法の精度を上回っていることが判明しました。この結果を踏まえて、この研究はさらに、配列類似性ランキングと DHR の構造類似性の間の相関関係を明らかにしました。
研究結果: DHR は精度と有効性が優れており、大規模なデータセットで高品質の MSA を構築できます。
この研究では、DHR によって提供されたホモログを使用して JackHMMER から MSA を作成し、それを AF2 のデフォルト パイプラインと比較しました。以下の図 a に示すように、DHR + JackHMMER のすべての構成の平均実行速度は、AF2 の通常の JackHMMER の平均実行速度よりも高速です。また、UniRef90上でMSAを構築するとDHRがJackHMMERと80%程度重複しますが、これは、MSA に関連する多くの下流タスクが DHR を使用して実行でき、同様の結果が得られますが、速度ははるかに速いことを示しています。
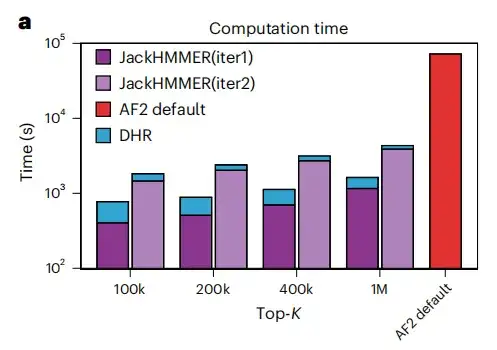
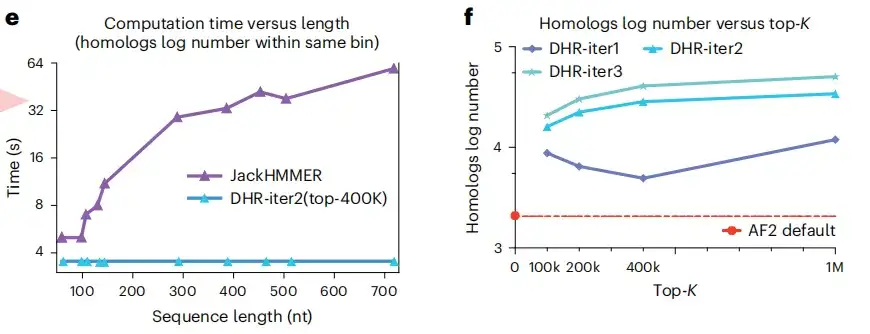
以下の図 e および f に示すように、DHR のもう 1 つの利点は、JackHMMER が線形にスケールするのに対し、一定時間内に異なる長さの同数のホモログを構築できることです。また、AF2 と比較して、DHR はクエリ埋め込み用により多くのホモログと MSA を提供できます。これらの結果は次のことを示していますDHR は、あらゆるクラスの MSA 構築にとって有望なアプローチです。
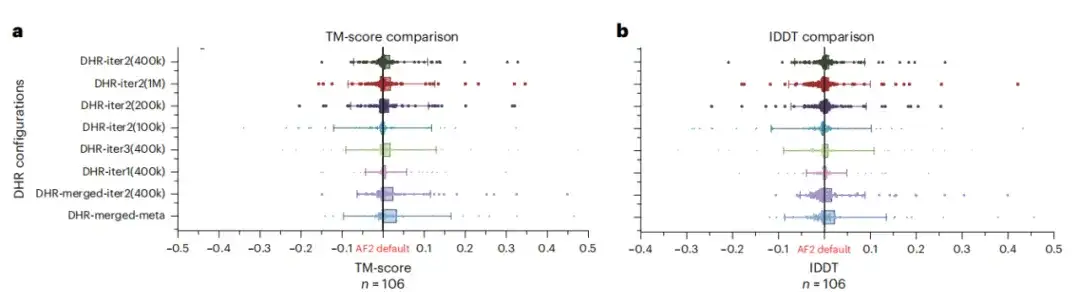
DHR はさまざまな MSA を生成することができますが、この研究では、DHR が AF2 ベースラインに対する MSA 補完として機能するかどうかをさらに分析しました。研究結果では、以下の図 a と b に示すように、異なる DHR 設定ですべての MSA と AF2 をマージすると、最高のパフォーマンスが得られることがわかりました。これは、DHR が AF2 の MSA パイプラインを迅速かつ正確に補充できることを意味します。
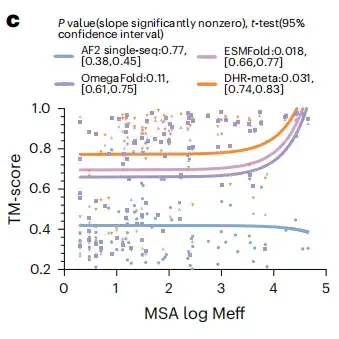
タンパク質構造予測における大規模言語モデルの潜在的な利点を調べるために、この研究では、すべての CASP14DM ターゲットで MSA を大規模言語モデルに置き換えることでより良い結果が得られるかどうかを評価しました。以下の図 c に示すように、多数の MSA が利用できる単純なケースでは、言語モデルは MSA と同じくらい多くの情報を伝えることができます。しかし、シーケンスの長さが増加するにつれて、DHR-meta のパフォーマンスはますます向上し、ほぼすべてのケースで ESMFold を上回ります。これは、言語モデルベースの方法と比較して、MSA ベースのモデルは、予測の精度と有効性を大幅に向上させることができます。
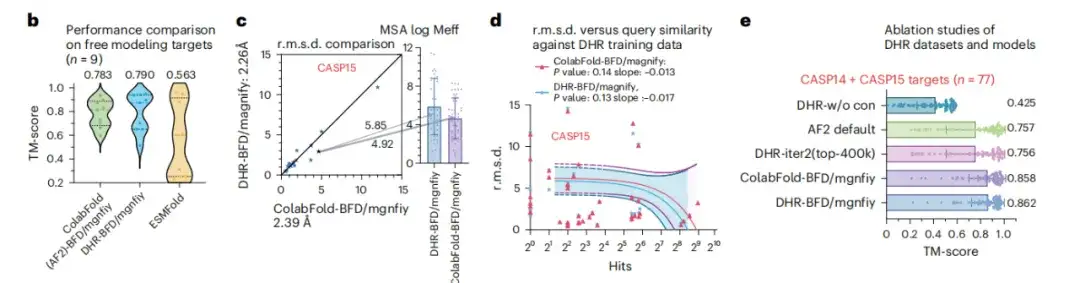
大規模なデータセットにおける DHR のスケーラビリティを研究するために、この研究では BFM/MGnify に基づいて DHR の詳細な分析を実施しました。以下の図 b に示すように、FM ターゲットの構造を予測する複雑なシナリオでは、MMseqs2 を使用して MSA を構築する ColabFold メソッドのパフォーマンスが 0.007 TM スコア高く、DHR はより意味のある MSA を生成することで際立っています。
以下の図 c では、DHR は ColabFold-MMseqs2 と比較してわずかなパフォーマンスの向上を示しています。以下の図 d は、CASP14 と SCOPe で類似性テストを実施した後、DHR がクエリやヒットの結果を単に記憶しているのではなく、すべてのターゲットの包括的な類似性評価を実施していることが判明したことも示しています。これらの結果は次のことを証明していますDHR を使用すると、多様性の高い大規模な検索データセット上で不規則なタンパク質の MSA を構築できます。
タンパク質構造予測分野の若き力
タンパク質構造予測が創薬、抗体設計、その他の応用において重要な役割を果たしていることに疑いの余地はなく、タンパク質構造予測精度が限られているという歴史的問題を解決する鍵となる可能性があります。この重要分野では、国内の科学研究チームが百家争鳴の状況を徐々に形成しており、上述の研究成果を主導した李宇氏や孫思奇氏らの新進気鋭の若手研究者が無視できない勢力となっている。 、最高のものの一つです。

Li Yu は、2015 年に中国科学技術大学の北世章エリート クラスで優秀な成績で生物科学の学士号を取得し、2015 年にサウジアラビアのキング アブドラ科学技術大学 (KAUST) でコンピュータ サイエンスの修士号を取得しました。 2016 年 12 月にコンピュータ サイエンスの修士号を取得し、2020 年にコンピュータ サイエンスの修士号を取得しました。
同年 12 月に彼は中国に戻り、香港中文大学コンピュータ科学工学部に助教授として加わり、ヘルスケアにおける人工知能 (AIH) グループを率いました。機械学習、ヘルスケア、バイオインフォマティクスの交差点であり、生物学とヘルスケアにおける計算問題、特に構造化学習問題を解決するための新しい機械学習手法の開発にチームを導きました。
李裕氏は、自身が深く取り組んでいる生物学と医療の分野について、「私の長期的な目標は、医療制度を改善し、人々の健康と福祉の向上を通じて社会に直接利益をもたらすことだ」と述べた。彼は2022年フォーブス・アジアの「30歳未満の30人」リスト(ヘルスケアとサイエンス)にも選ばれたことは注目に値する。

Sun Siqi 氏は、世界的なタンパク質構造予測コンテストで優秀な成績を収めており、現在は復旦大学知能複雑システム基礎理論・主要技術研究室と上海人工知能研究室の若手研究者です。彼は、モデルの精度と速度の向上、モデルの実装における特定の問題の解決に重点を置き、生命科学や自然言語処理などの学際的な主題における深層学習の応用に取り組んでいます。
タンパク質の予測に関しては、深層学習モデルを通じてタンパク質の構造と配列を予測し、配列のパターンと規則性を特定するモデルをトレーニングしてタンパク質の配列とフォールディング方法を予測し、de novo タンパク質の配列と構造の精度を向上させることに重点を置いています。安全性と効率性を予測し、それによって医薬品設計と疾患治療の新たな可能性を生み出します。
国内のAI4S分野では、若手の活躍が増えています。タンパク質構造予測の分野ではAI技術がより重要な役割を果たすことが予想されるが、その道のりは険しく長い。幸いなことに、国内の科学研究チームは探究と革新に対する粘り強さを示しており、アルゴリズムの最適化とモデルの構築に熱心に取り組むだけでなく、研究結果を確実にするためにデータ処理や実験検証などについても徹底的な研究を行っています。セックスと実用性です。こうした取り組みは徐々に実用化され、医療研究開発やバイオテクノロジーなどの分野に新たな活力と希望をもたらしています。
最後に、学術的な共有活動をお勧めします。
Meet AI4S の 3 回目のライブ ブロードキャストには、上海交通大学自然科学アカデミーおよび上海国立応用数学センターの博士研究員である Zhou Ziyi 氏が招待されました。ライブブロードキャストを視聴するにはクリックして予約してください。
https://hdxu.cn/6Bjom hdxu.cn/6Bjom