Command Palette
Search for a command to run...
オンライン チュートリアル | 10,000 ワードのサスペンス小説を 1 分で生成、LongWriter-glm4-9b が長いテキスト出力のボトルネックを突破

近年、大規模言語モデル (LLM) は、複雑なテキストを理解して生成する強力な機能を実証しており、最大 100,000 トークンの入力を処理できますが、2,000 ワードを超える一貫した出力を生成する場合には、しばしば困難に遭遇します。
主な理由の 1 つは、SFT (教師あり微調整) データセット内の長い出力サンプルが不足しているためです。研究によると、モデルの最大出力長は、SFT 段階でモデルがさらされるサンプルの長さと有意な正の相関関係があることがわかっています。言い換えれば、モデルは長いテキストを理解して処理する方法を学習しましたが、同じ長さのテキストを生成する方法を十分に学習していません。
この問題を解決するために、清華大学と Zhipu AI は、AgentWrite テクノロジーに基づいて LongWriter-6k と呼ばれるデータ セットを構築しました。これには、6,000 の SFT データ サンプルと 2k ~ 32k ワードの範囲の出力長が含まれています。データ セットは現在、HyperAI 公式 Web サイトのデータ セット セクションにオンラインであり、ワンクリック入力をサポートしています。
データセットアドレス:
その後、研究チームは LongWriter-6k を使用して GLM-4-9B に基づいてトレーニングし、10,000 ワードを超える一貫したテキストを生成できるモデル LongWriter-glm4-9b を取得しました。これにより、大規模なデータの出力可能性が大幅に拡張されました。言語モデルは、創作やニュース報道などの実際の応用において優れた多用途性を示しています。
現在、HyperAI スーパーニューラル チュートリアル セクションで「LongWriter-glm4-9b のワンクリック展開」を開始しました。ワンクリックでクローンを作成して会話を開始します。
チュートリアルのアドレス:
デモの実行
1. hyper.ai にログインし、「チュートリアル」ページで「LongWriter-glm4-9b のワンクリック展開」を検索し、「このチュートリアルをオンラインで実行する」をクリックします。
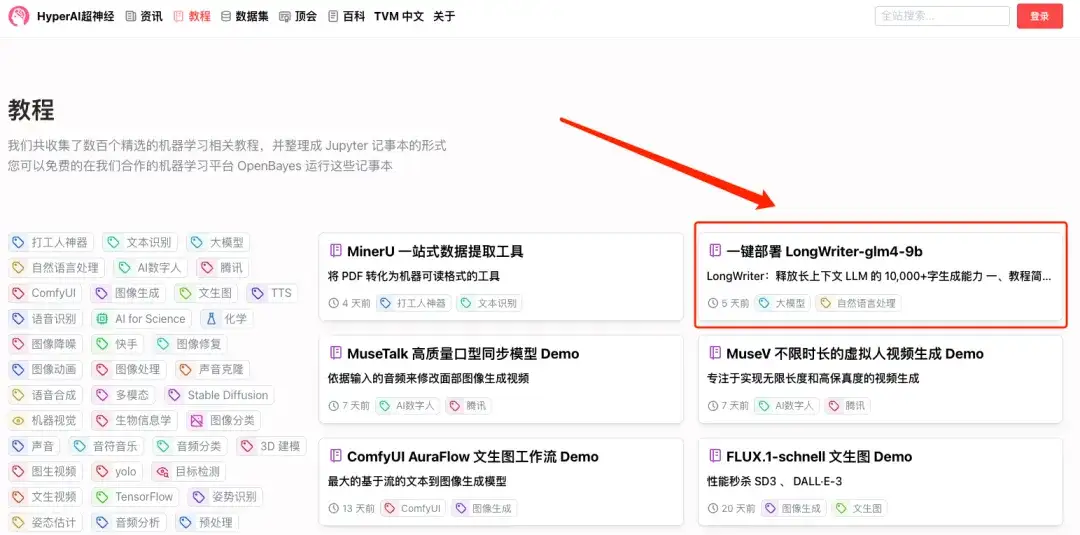
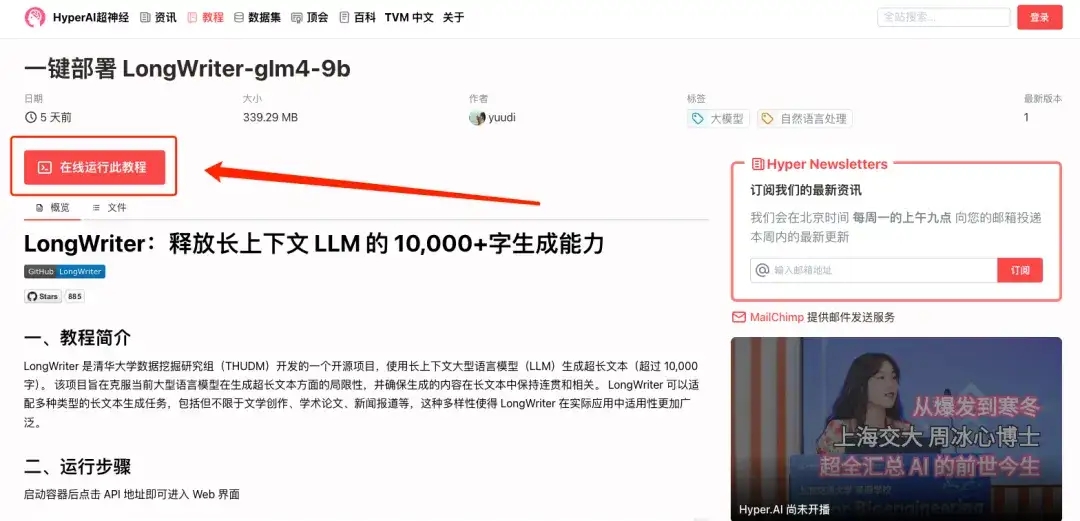
2. ページがジャンプしたら、右上隅の「クローン」をクリックしてチュートリアルを独自のコンテナにクローンします。
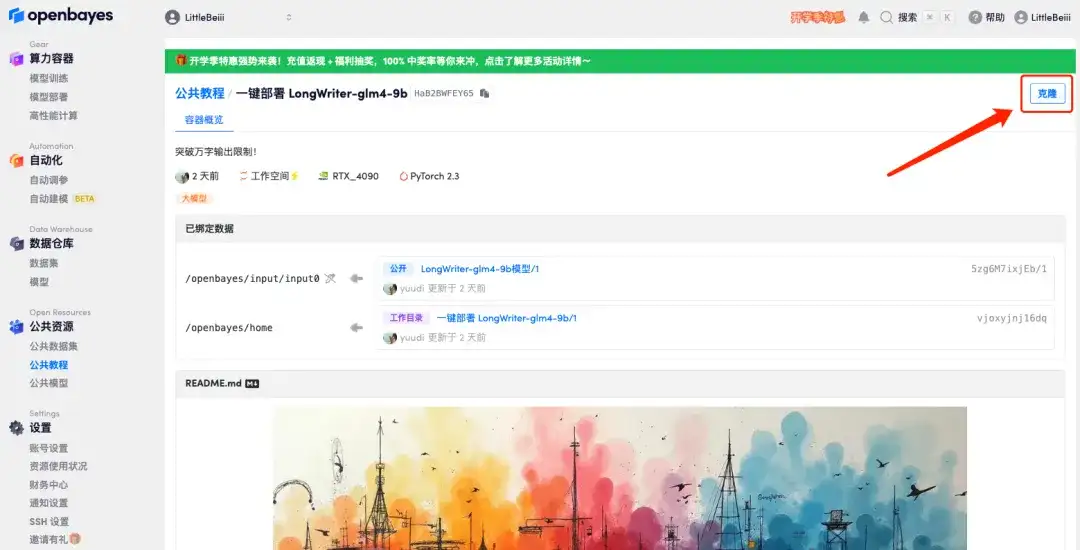
3. 右下隅の「次へ: コンピューティング能力の選択」をクリックします。
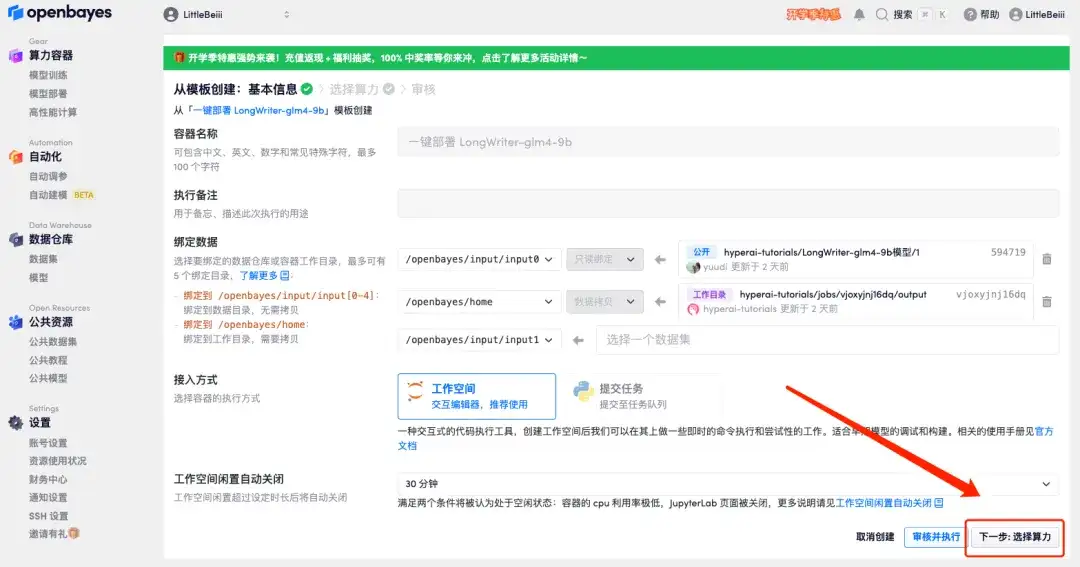
4. ページがジャンプしたら、「NVIDIA RTX 4090」と「PyTorch」のイメージを選択し、「次へ: レビュー」をクリックします。以下の招待リンクを使用してサインアップした新規ユーザーは、4 時間の RTX 4090 + 5 時間の CPU を無料で入手できます。
HyperAI ハイパーニューラルの専用招待リンク (ブラウザに直接コピーして開きます):
https://openbayes.com/console/signup?r=6bJ0ljLFsFh_Vvej
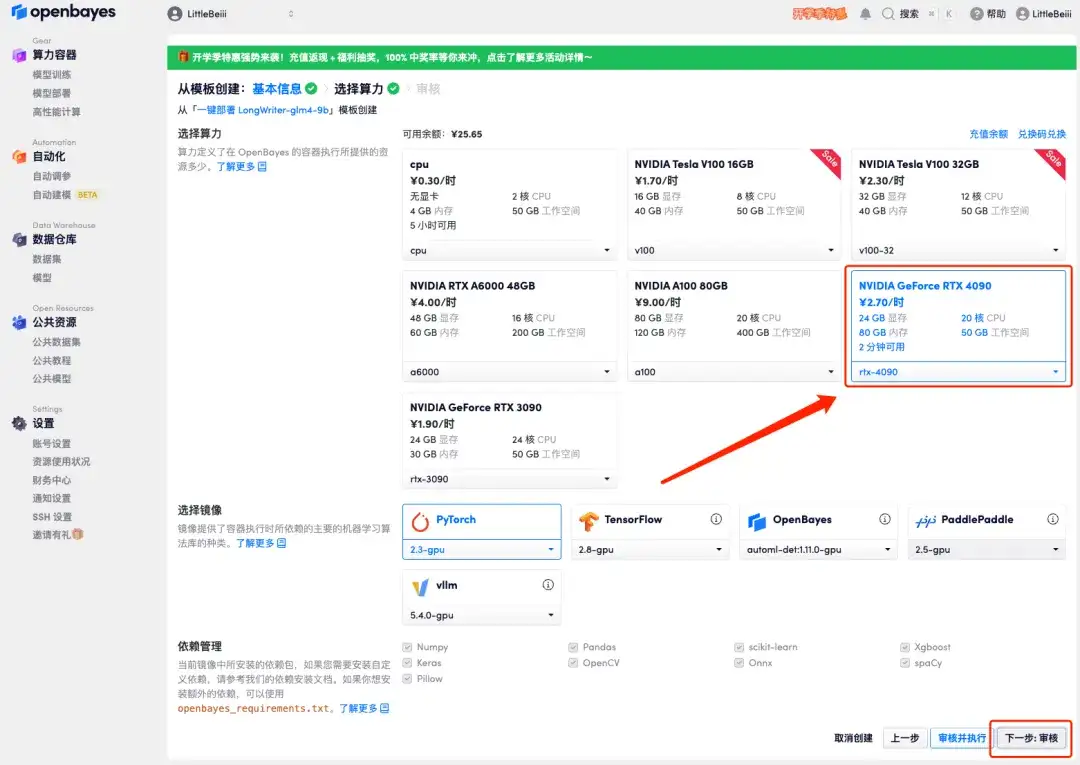
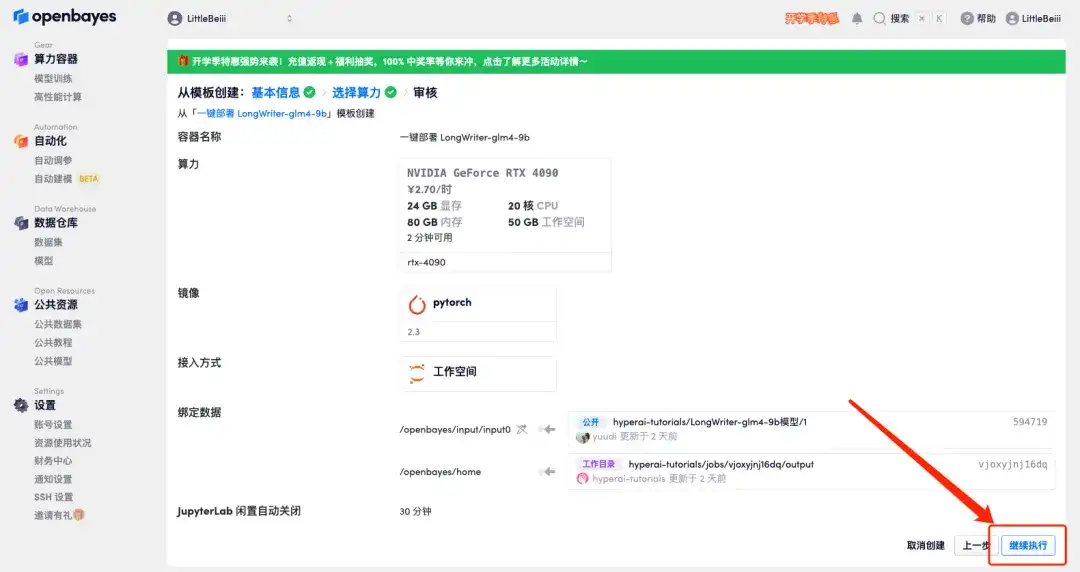
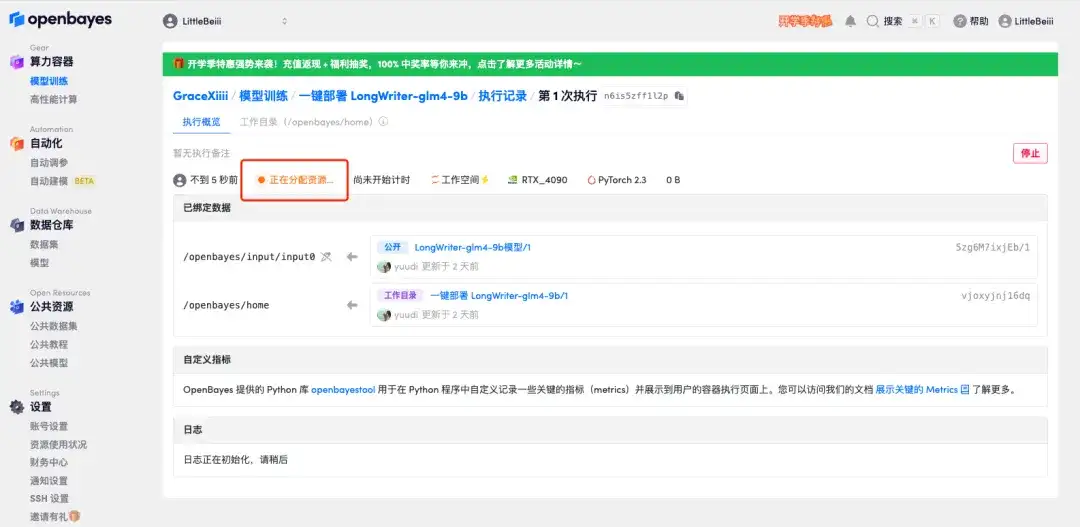
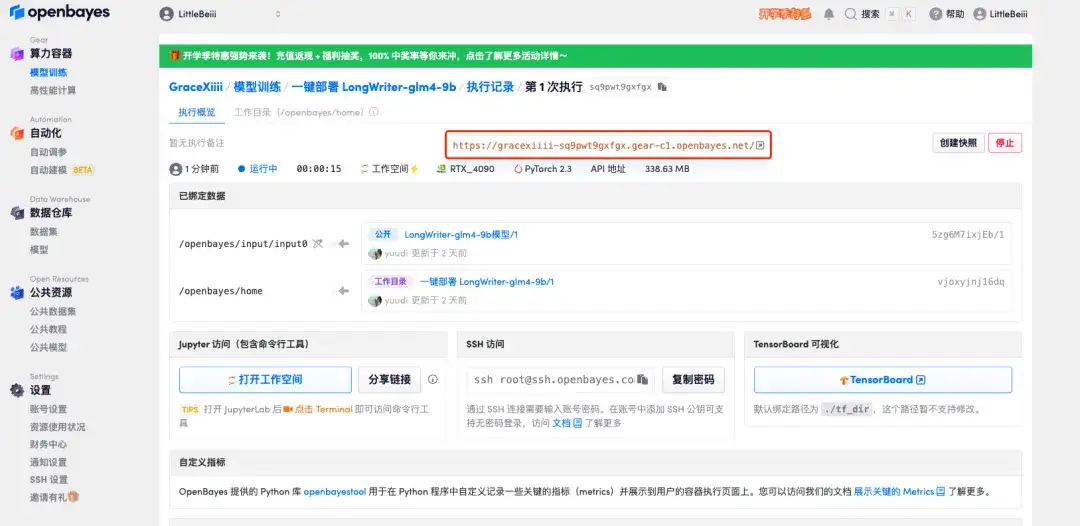
5. すべてが正しいことを確認したら、[続行] をクリックし、最初のクローンが割り当てられるまで待ちます。ステータスが「実行中」に変わったら、「API アドレス」の横にあるジャンプ矢印をクリックしてデモ ページにジャンプします。APIアドレスアクセス機能を利用するには実名認証が必要となりますのでご注意ください。
エフェクトのプレビュー
1. デモ インターフェイスを開いて、10,000 ワードのサスペンス小説を生成してみましょう。
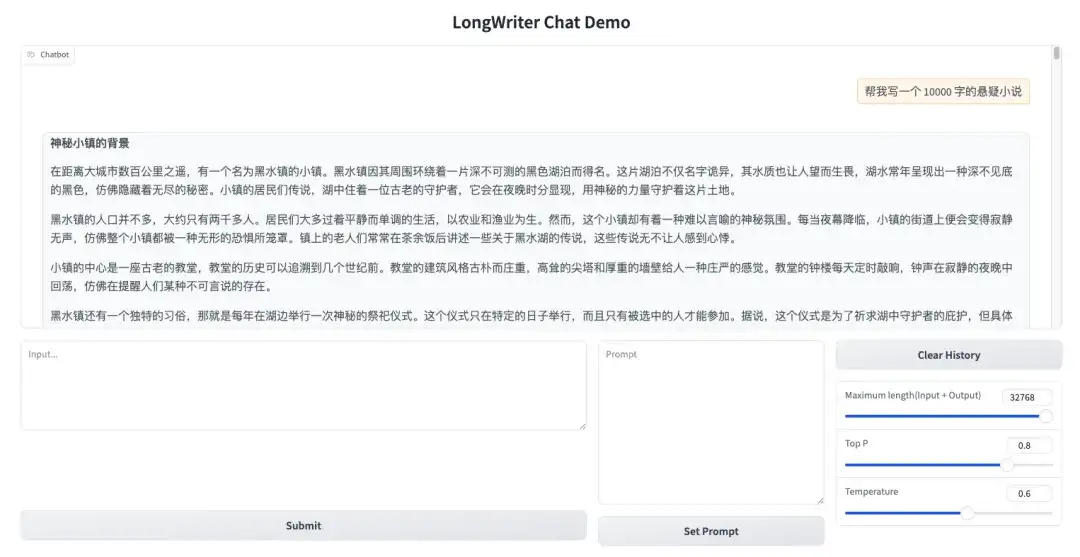
2. 長編サスペンス小説がすぐに出力されることがわかります。








