Command Palette
Search for a command to run...
ワンクリックで 10k Star オープンソース データ処理ツールを起動してください! 176 の言語認識をサポート。初の高層落下物検出データセットはオンラインで、18 シーンの約 2,000 個のビデオが含まれています。

人工知能の分野では、マルチモーダルなデータ処理は常に困難な問題です。複数の形式の複雑な PDF、Web ページ、電子書籍に直面すると、重要な情報を効果的に抽出するのは簡単ではありません。
上海人工知能研究所と OpenDataLab チームは、オープンソースのインテリジェントなデータ抽出ツール MinerU を発表しました。このツールは、画像、数式、表、その他の要素を含むマルチモーダル PDF ドキュメントを分析しやすい Markdown 形式に変換し、データをサポートします。 Web ページや電子ドキュメントからコンテンツを抽出することで、複雑なドキュメントから高品質のデータを自動的に抽出する必要性が解決されます。
「MinerU ワンストップ データ抽出ツール デモ」は、hyper.ai 公式 Web サイトで公開中です。記事を下にスクロールしてリンクを取得してください~
8 月 26 日から 8 月 30 日までの hyper.ai 公式 Web サイトの更新の概要:
* 高品質なチュートリアルのセレクション: 3
* 高品質の公開データセット: 10
* コミュニティ記事の選択: 3 記事
* 人気のある百科事典のエントリ: 5
※9月締切:7日
公式ウェブサイトにアクセスしてください:ハイパーアイ
選択された公開チュートリアル
MinerU は、PDF を機械可読形式 (マークダウン、json など) に変換するツールで、任意の形式に簡単に抽出でき、176 言語の正確な識別をサポートし、正確な言語タイプの識別を実行します。モデルと環境がデプロイされているので、チュートリアルのガイドラインに従って推論生成に大規模なモデルを使用できます。
直接使用します:https://go.hyper.ai/MIitP
2. ワンクリックで LongWriter-glm4-9b をデプロイします
LongWriter は、清華大学によって開発されたオープンソース プロジェクトで、ロングコンテキストのラージ言語モデル (LLM) を使用して非常に長いテキスト (10,000 ワード以上) を生成します。このチュートリアルでは、モデルのワンクリック デモ デプロイメントを提供します。コンテナーを複製して起動し、生成された API アドレスを直接コピーするだけで、モデルの推論を体験できます。
直接使用します:https://go.hyper.ai/Xvktt
3. オンラインチュートリアル | 青島の兄弟、ジャオ・エンジュンの魂は黒い神話上の悟空を貫くことができる? MuseV + MuseTalk で高品質なデジタル人材を創出
従来のデジタル ヒューマン トレーニング ソリューションを使用して高品質のデジタル ヒューマンを生成するには、多くの場合、多くの時間とコンピューティング リソースが必要であり、トレーニング教材にも高い要件が必要です。 MuseV と MuseTalk の登場は、デジタル ヒューマンの分野に新たな進歩をもたらしました。MuseV を使用してデジタル ヒューマン ビデオを生成し、その後 MuseTalk を使用して唇の形状と音声を同期させると、わずか数分で完全なデジタル ヒューマンの制作が完了します。すべては hyper.ai の公開チュートリアル モジュールとして起動されており、ワンクリックでクローンを作成してオンラインで実行できます。
MuseV チュートリアル:https://go.hyper.ai/9fExW
MuseTalk チュートリアル:https://go.hyper.ai/wiw8g
公開データセットの選択
FADE データセットには、18 のシーン、落下物の 8 つの異なるカテゴリ、4 つの異なる気象条件、および 4 つのビデオ解像度をカバーする 1,881 のビデオが含まれています。 FADE データセットの多様性と専門性により、建物周囲の落下物検出を研究するための貴重なリソースになります。
直接使用します:https://go.hyper.ai/8u8Sr
2. ChiPBench Al チップ レイアウト アルゴリズム データ セット
ChiPBench は、最終設計の PPA メトリックを改善する際の既存の AI ベースのチップ レイアウト アルゴリズムの有効性を評価するために設計された包括的なベンチマークです。研究チームはCPU、GPU、マイクロコントローラーなどさまざまな分野から20個の回路を集めた。これらの設計により、最終設計 PPA に対するレイアウト アルゴリズムの影響を評価できます。
直接使用します:https://go.hyper.ai/LN4Ab
このデータセットには約 9.6k の顔画像が含まれており、そのうち 5k は実際の顔画像、4.63k は AI によって生成された顔画像です。
直接使用します:https://go.hyper.ai/N5nVT
4. TableBench テーブルの質問と回答のベンチマーク データ セット
データセットには 18 のドメインにわたる 886 のサンプルが含まれており、事実確認、数値推論、データ分析、視覚化タスクを容易にするように設計されています。
直接使用します:https://go.hyper.ai/Qcs2F
データセットには、28 人の俳優が 16 の異なるシーンで演技する 363 以上のオリジナル クリップが含まれています。これらの高品質ビデオは、現実世界のコンテンツでモデルをトレーニングするための強固な基盤を提供します。このデータセットには、生データに加えて、DeepFakes 手法を使用して生成された 3,000 を超える処理済みビデオも含まれています。
直接使用します:https://go.hyper.ai/Jw59B
このデータセットは車両分類タスク用に特別に設計されており、7 つのカテゴリに分類された合計 5.6k の画像が含まれています。各カテゴリは異なるタイプの乗り物 (オートリキシャ、自転車、自動車、オートバイ、飛行機、船、電車) を表しており、すべての画像は .jpg 拡張子の付いた JPEG 形式です。異なるタイプの車両を区別するための画像分類モデルの構築とテストに最適です。
直接使用します:https://go.hyper.ai/e9LNg
このデータセットには、解像度 1,080 × 1,080 の線路上の人間の行動を表す 3,766 枚の画像が含まれています。各画像には、人間の存在と線路上の行動を示す境界ボックスの注釈が付けられています。
直接使用します:https://go.hyper.ai/dsr49
8. Ref-AVS オーディオビジュアルシーンセグメンテーションデータセット
Ref-AVS データセットは、オーディオビジュアル シーンにおけるオブジェクト セグメンテーション タスクのベンチマークです。このデータセットには、特に楽器 20 個、動物 8 個、機械 15 個、人間 5 個に分類された 48 個の可聴オブジェクトのビデオが含まれています。
直接使用します:https://go.hyper.ai/pGHwm
9. COSMOS 1050K 医用画像セグメンテーション データセット
このデータセットには、研究チームが編集した53の医療公開データセットが含まれており、18のモダリティ、84のオブジェクト、105万の2D画像、6033のマスクをカバーしています。
直接使用します:https://go.hyper.ai/nHETv
10. 画像数14万枚収録! HUST-OBC Oracle データセットは、チームが ACL 最優秀論文を獲得するのに役立ちます
このデータセットは、華中科技大学のBai Xiang教授の研究チームのWang Pengjieらによって提案された高品質のHUST-OBCデータセットであり、書籍、Webサイト、既存のデータを含む3つの異なるソースから収集されています。セット。データセットには、オリジナルの甲骨碑文を擦って加工スキャンして得た甲骨碑文画像と、オリジナルの甲骨碑文に基づく手書きの甲骨碑文画像の 2 種類の甲骨碑文サンプル画像が含まれています。 、これはさらに、ラビング トレースに基づく画像とグリフ ベースの手書き画像に細分化されます。
直接使用します:https://go.hyper.ai/46AiA
その他の公開データセットについては、以下をご覧ください。
注目のコミュニティ記事
1. SAM 2 最新アプリケーションがリリースされました!オックスフォード大学チームが Medical SAM 2 をリリースし、医療画像セグメンテーションの SOTA リストを更新
オックスフォード大学チームは、Medical SAM 2 と呼ばれる医療画像セグメンテーション モデルを開発しました。このモデルは、SAM 2 フレームワークに基づいて設計されており、医療画像をビデオとして扱います。これは、3D 医療画像セグメンテーション タスクを適切に実行するだけでなく、新しい機能を解放します。単一のプロンプトを分割する機能。この記事は研究論文の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/04VFX
2. AI for Genomics | 空間トランスクリプトームデータ表現アルゴリズム SPACE、ゲノミクスにおける人工知能アプリケーション
生放送の「Meet AI4S」シリーズの第 2 回エピソードでは、清華大学生命科学部の Zhang Qiangfeng 研究室の博士研究員である Li Yuzhe 氏が、「ゲノミクスにおける AI アプリケーションの探索: 」というタイトルでチームの結果を共有しました。空間トランスクリプトーム データ表現アルゴリズム SPACE を例に』 最新の研究結果、この記事は彼の講演のエッセンスであり、有益な情報が満載です。
レポート全体を表示します。https://go.hyper.ai/eRQeT
3. 上海交通大学のホン・リャン教授: AI が本当に工学分野を突破したいのであれば、既存の人間の専門家が不可能な工学的成果を達成する必要があります。
AI for Bioengineering サマースクールイベントでは、上海交通大学のホン・リャン教授が「AI の生命と科学への参入」をテーマに、科学研究分野、特にタンパク質設計分野における AI の応用について共有しました。 、科学のための AI についての彼の考え、および将来の開発の見通し。この記事は、ホン・リャン教授の講演の要旨です。
レポート全体を表示します。https://go.hyper.ai/TWBIk
人気のある百科事典の項目を厳選
1.ダルイー
2. 和集合比 IoU の交差
3. マスクされた言語モデリング MLM
4. 神経放射線場 NeRF
5. 相互ソーティング融合 RRF
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
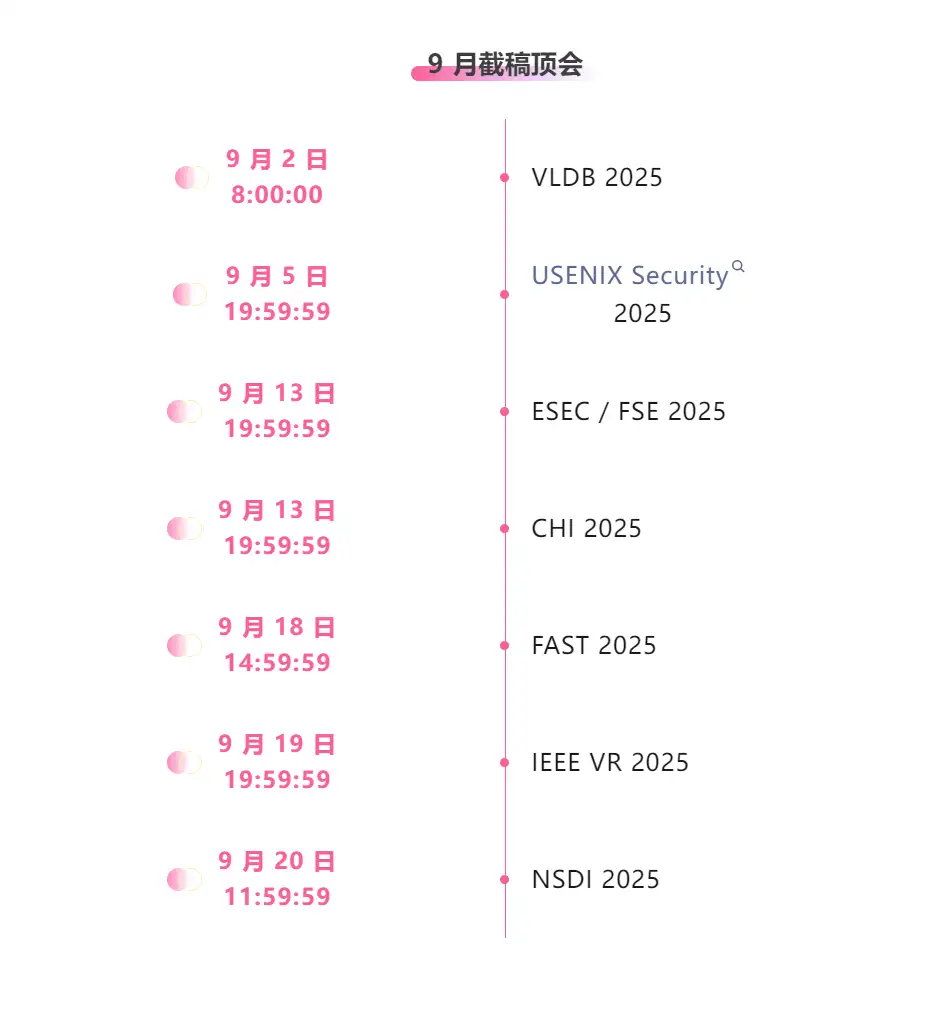
主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
* 1,300 を超える公開データセットに対して国内の高速ダウンロード ノードを提供
* 400 以上の古典的で人気のあるオンライン チュートリアルが含まれています
* 100 以上の AI4Science 論文ケースを解釈
* 500 以上の関連用語クエリをサポート
*Apache TVM の最初の完全な中国語ドキュメントを中国でホストします
学習の旅を始めるには、公式 Web サイトにアクセスしてください。








