Command Palette
Search for a command to run...
上海交通大学のホン・リャン教授:AIが本当に工学分野を突破したいのであれば、既存の人間の専門家ができない工学的成果を達成しなければなりません。

最近、上海交通大学 AI for Bioengineering サマースクールが成功裏に終了しました。企業、研究機関、大学からの 100 名以上の業界専門家、ビジネス代表者、優れた若手学者が集まり、AI の応用について熱心に考えました。生物工学衝突の分野で。
で、上海交通大学の自然科学研究、物理天文学部、薬学部の特別教授であるホン・リャン氏は、「AI の生命と科学への参入」というテーマについて共有し、特に科学研究分野における AI の応用について共有しました。タンパク質設計の分野における彼の理解だけでなく、科学用 AI の将来の開発の見通しについても理解しています。
重要なポイントの抜粋:
* 本当に科学向け AI を構築して実装するには、まず科学的問題を定義し、次に人工知能ソリューションを提案する必要があります。
* AI は、良好な活性と高い陽性率を維持しながら、数百のアミノ酸配列を変換できます。この種の配列生成タスクでは、AI はすでに人間の専門家よりもはるかに強力です。 * タンパク質工学の分野では、最もネガティブなデータとポジティブなデータを組み合わせることができ、プロの酵素エンジニアの合理的な設計の範囲を超えて、AI が従来の物理計算に取って代わりました。 * 人工知能が工学分野に突破口を開きたいのであれば、単に科学者のアシスタントを作成したり、文書収集などの基本的な作業を実行したりするだけではなく、人間の専門家にはできないことを実行する必要があります。 ※今後3年間で、タンパク質設計、創薬研究開発、疾患診断、新たな標的発見、化学合成ルート設計、材料設計などの分野において、専門分野における汎用人工知能が明確なパラダイム変化をもたらし、人工知能に取って代わる。過去の人間の脳への依存は散発的でした。試行錯誤の科学的発見モデルは、大規模な AI モデル用の自動化された標準設計モデルに変換されます。
HyperAI Super Neural は、Hong Liang 教授の素晴らしい共有内容を、当初の意図に反することなく編集し、要約しました。以下はスピーチの要点です。

AI文系学生 vs. AI理系学生
ホン・リャン教授は、AI文系学生とAIサイエンス学生の視点から、AIの生活への応用(AI for Life)と科学研究(AI for Science)を紹介しました。
AI文系学生:生活のパーソナルアシスタント
AI 文系学生、つまり AI for Life について、ホン・リャン教授は、現在の AI は公共生活におけるパーソナルアシスタントとなり、人々が反復的で創造的で非科学的な仕事の負担を軽減できると考えています。特徴としては、学習に利用できるデータの規模がすでに大きく、生成される結果に高い精度が要求されないため、クロスドメインの汎化機能が強く、一般的な分野で大規模なモデルを構築することが可能です。
その後、現在普及している大型モデルと組み合わせた、AI テキスト生成、AI 画像生成、AI ビデオ生成などの具体的な事例を通じて、生活における AI の応用について生き生きと説明しました。
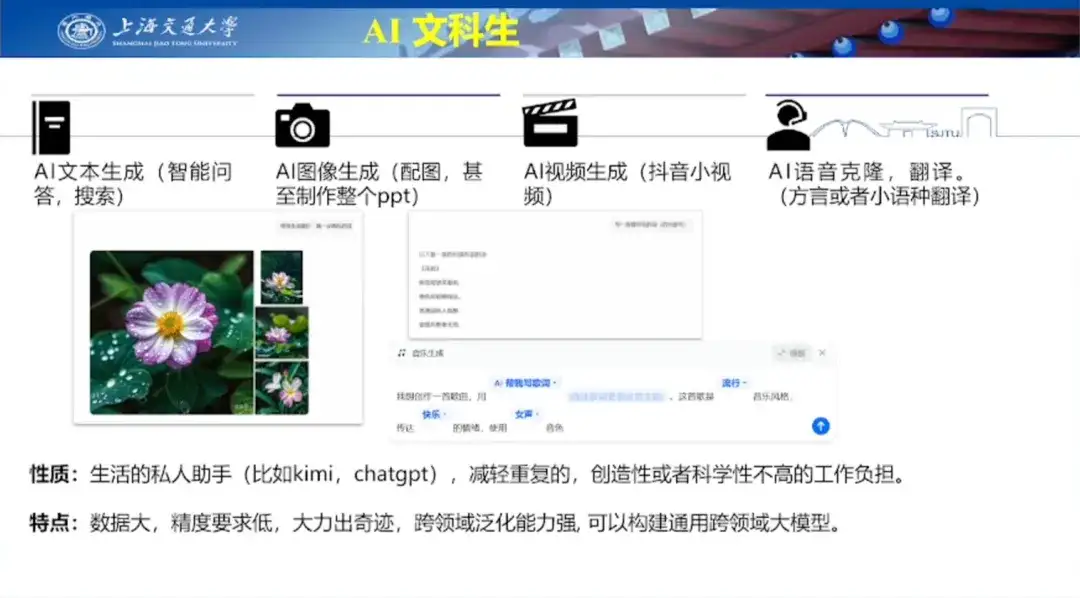
AI テキスト生成に関して、Hong Liang 教授は、バレンタインデーに妻のために詩を書くという例を用いて、ChatGPT の詩作成機能を実証しました。同時に、小学生の息子に自評を書くのを手伝うためにウェンシンイーヤンを利用した例も紹介し、ウェンシンイーヤンの文章作成能力を実証した。
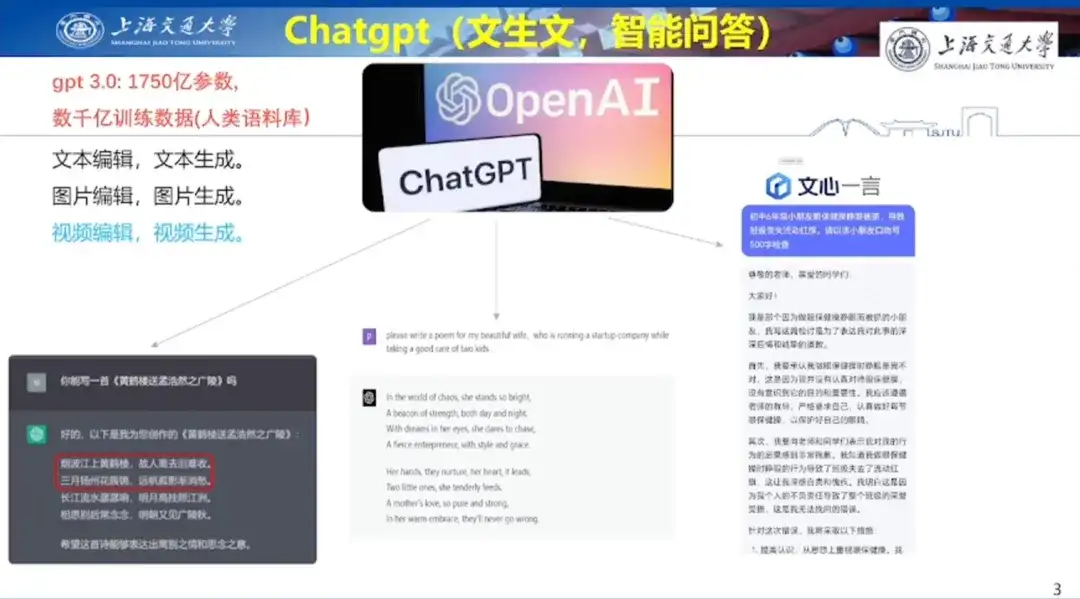
AI 画像生成に関して、Hong Liang 教授は、以下の図に示すように、Baidu Wenxinyiyan、Adobe firefly、Midjourney が同じプロンプト ワードに基づいて生成するさまざまな効果を実証しました。

AI ビデオ生成に関して、Hong Liang 教授は、ビデオ生成における人気の Sora の強力な機能を実証しました。彼は、Sora が生成した東京の街を歩くおしゃれな女性のビデオを例に挙げ、そのビデオに表示されるキャラクターの顔の毛穴のワンショット技術と詳細な処理を賞賛しました。
同時に同氏は、「Sora はデータ駆動型の物理エンジンである」という業界関係者による評価にも同意し、Vincent Video が Douyin などのプラットフォームのコンテンツ作成者にとって大きな助けになっていると信じていました。

AI 科学の学生: ある種の科学的問題を解決する科学者
AI 科学の学生、つまり科学のための AI またはエンジニアリングのための AI について、Hong Liang 教授は次のように考えています。 「それは、ある種の科学的問題を解決する科学者です。本質的には、生物医学、材料化学、核物理学などのさまざまな分野の科学者を生み出すことです。」最大の難点は、精度要件が非常に高く、トレーニングに使用できる機能データが比較的少なく、独自の AI モデルしか構築できないことです。

AI の科学への応用を誰もがより深く理解できるように、Hong Liang 教授は、生物学/医学用 AI、材料/化学用 AI、制御可能な核融合用 AI などの具体的な事例に基づいて詳細な分析を実施しました。
1つ目は、生物学分野におけるAIの事例です。ホン・リャン教授は、「タンパク質の三次元構造予測は科学用AIの最も重要な出発点である」と述べた。同氏は、タンパク質の構造予測は50年近く科学者を悩ませてきたと述べ、「ディープマインドがAlphaFoldモデルをリリースする前、科学者は一般に、タンパク質の構造を予測するためにAIを使用することは単なるゲームだと信じていた」と述べた。
AlphaFold 1 から AlphaFold 3 まで、AI はタンパク質の三次元構造の予測において才能を発揮しており、特に AlphaFold 3 の精度は、タンパク質とリガンドの相互作用、タンパク質と核酸の相互作用など、これまでの多くの特殊なツールと比較して優れています。抗体抗原予測が大幅に向上します。
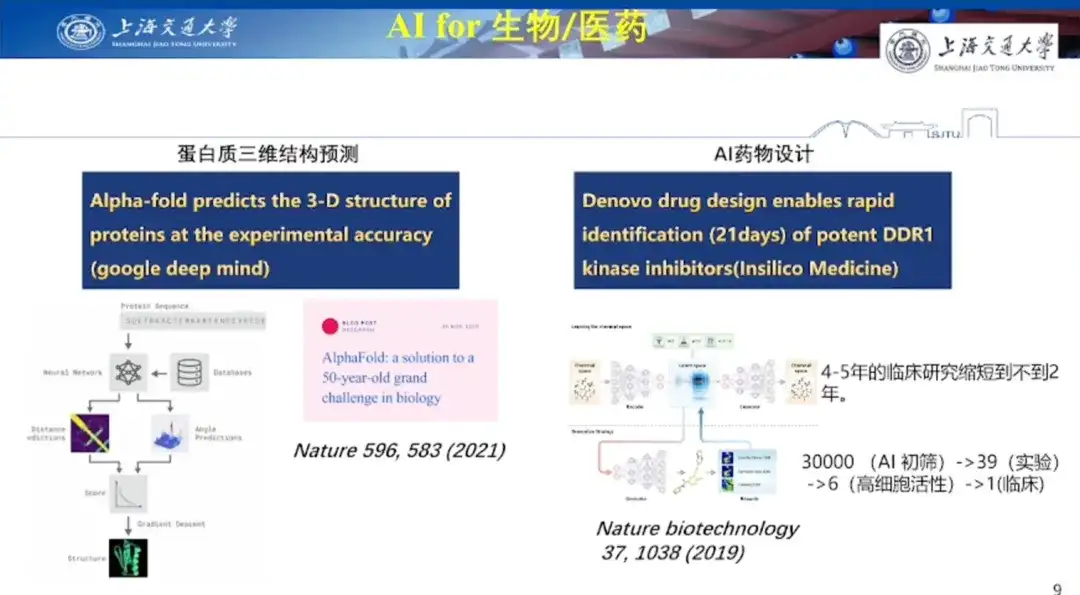
次にAI創薬の事例です。ホン・リャン教授は、AI医薬品の設計は分子レベルで問題を解決する必要があるだけでなく、その後の臨床試験の課題にも直面するため、比較的難しいと述べた。ハイスループットスクリーニングなどの従来の創薬方法では、数千の低分子をテストし、少数のリード化合物しか取得できず、そのうち臨床試験に合格できるのはわずか10分の1以下です。
2019 年に Nature Biotechnology に掲載された研究結果は、医薬品設計における AI の大きな可能性を明らかにしました。研究者らは、強化学習(GENTRL)を使用して、線維性疾患に関連するキナーゼ標的であるディスコイドドメイン受容体 1(DDR1)の強力な阻害剤を 21 日間で発見しました。研究者らはAI技術を利用して最初に3万個の分子をスクリーニングし、その後さまざまなスクリーニング方法で39の細胞実験を実施し、細胞活性の高い6つを発見し、最終的に1つを臨床試験に進めた。
さらに、Hong Liang教授は材料・化学におけるAIの事例も挙げた。彼はこう思います、「材料、特に化学材料の AI は実装が難しいものです。」ただし、自然言語、人間の言語、DNA 配列とは異なり、マテリアルは本質的に 3 次元構造の問題であるため、大規模なモデルを構築する場合は、DFT 計算、自動実験、および AI 再帰を組み合わせる必要があります。特定の無機化合物の合成の進歩。たとえば、DeepMind マテリアル チームは、2023 年に深層学習ベースのマテリアル探索用グラフ ネットワーク (GNoME) を立ち上げました。A-Lab ラボは、テスト タスク中に 17 日間で 58 の予測マテリアルのうち 41 の合成に成功しました。これは、過去10年ではもっと時間がかかるでしょう。
クリックして原文を表示: 人類より800年先? DeepMind が GNoME をリリース、深層学習を使用して 220 万個の新しい結晶を予測

最後に、Hong Liang教授は、制御可能な核融合のためのAIの例を挙げ、この方向での進歩は非常に喜ばしいことであると述べた。同氏は、現在の核融合の主な問題は、プラズマが容易に「引き裂かれ」、プラズマを抑制するために使用される強い磁場から逃げてしまい、核融合反応が中断されてしまうことだと指摘した。プリンストン大学のチームは、プラズマ ティアリングの潜在的なリスクを 300 ミリ秒前に予測し、適切なタイミングで介入できる AI コントローラーを開発しました。
クリックして原文を表示: プラズマティアリングのリスクを 300 ミリ秒前に予測、プリンストン大学が AI コントローラーをリリース
以下の図に示すように、研究者は従来の物理ベースの手法と高度な AI テクノロジーを統合して、プラズマ挙動の制御と理解を向上させています。以下の図 a、b、c は、核融合炉内のプラズマの状態を示しています。
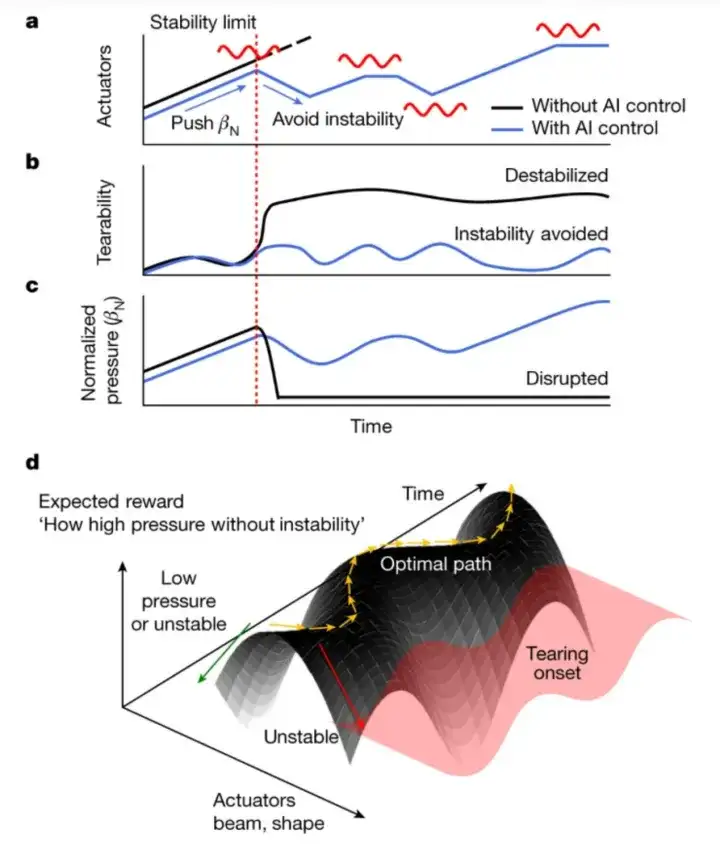
図 a の黒い線は、外部温度の上昇 (中性粒子ビームなど) に伴ってプラズマ圧力が増加すると、最終的に安定限界に達することを示しています。この制限を超えると、引裂きの不安定性が引き起こされます。引き裂き不安定性が一度励起されると、プラズマは急速に破壊され、図 b および c に示すように、実際の操作では重大な結果をもたらします。
研究者らは、ディープニューラルネットワークと強化学習に基づいて、プラズマ状態の変化にリアルタイムで応答し、プラズマの将来の状態を予測し、それに応じて制御動作を調整できるインテリジェントな制御システムを開発した。これにより、トカマク運転は理想的な経路をたどり、引き裂きの不安定性を回避しながら、高い圧力を維持します。
最後に、ホン・リャン教授はこう強調した。「科学のための AI を真に実装し実装するには、まず科学的問題を定義し、次に人工知能ソリューションを提案する必要があります。」
バイオエンジニアリング向け AI: エンジニアリングの問題を解決し、マルチシナリオの製品実装を実現
続いて、Hong Liang教授は、伝統的なタンパク質工学の定義と課題、タンパク質工学分野におけるAIの応用、チームの研究開発成果とその実装、チームの核となる利点について説明し、AIの価値をさらに明らかにしました。バイオエンジニアリング用。
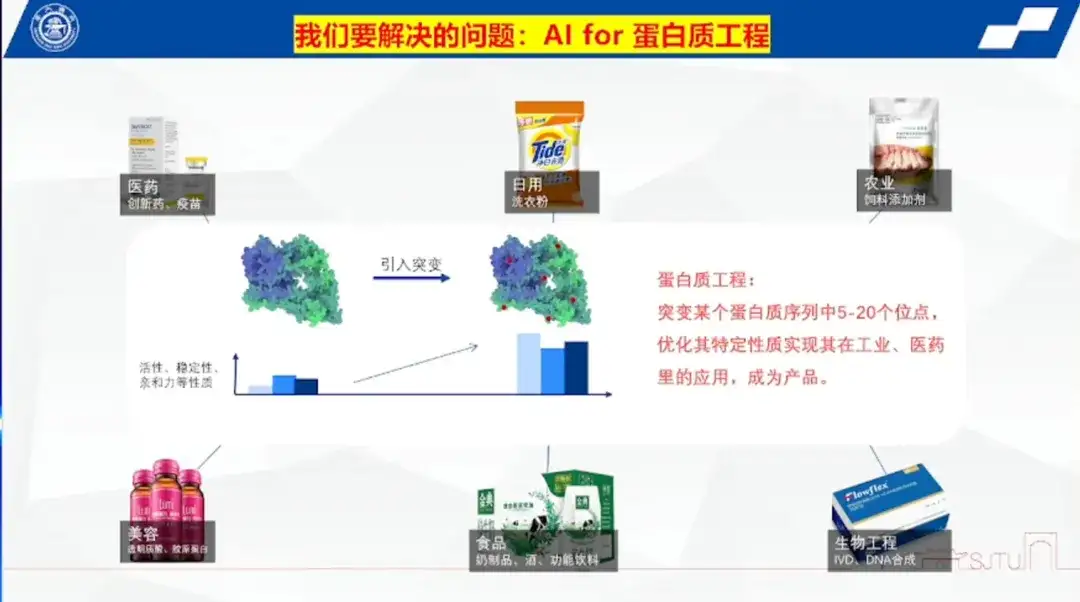
タンパク質工学: 製品アプリケーションの要件を満たすためにタンパク質配列部位を変異させます。
ホン・リャン教授は、タンパク質工学とは、特定のタンパク質配列の5~20箇所を変異させ、その特定の特性を最適化し、産業や医療への応用を実現し、製品化することを指すと指摘した。
同氏は、タンパク質は生物の重要な構成要素であり、人々の日常生活に不可欠な製品であると説明しました。酵素はタンパク質分子として産業シナリオで広く使用されており、触媒効果があります。たとえば、革新的な医薬品の分野における抗体 ADC 部位特異的カップリング酵素、洗剤中の酵素、動物の代謝を助ける飼料中の酵素添加物、美容、食品、バイオエンジニアリングにおけるさまざまな酵素などです。
その後、Hong Liang 教授はタンパク質工学の最も主流な 2 つの方法を紹介しました。
1つ目は合理的設計・準合理的設計です。一般に、タンパク質の構造と触媒機構を明確に研究し、その機構に応じてタンパク質を改変する必要があります。しかし、合理的設計の欠点は、時間がかかること、修正が必要な部位が主にアクティブポケット周辺に集中していること、設計範囲が相対的に限定され、思考範囲も比較的限定されていることです。
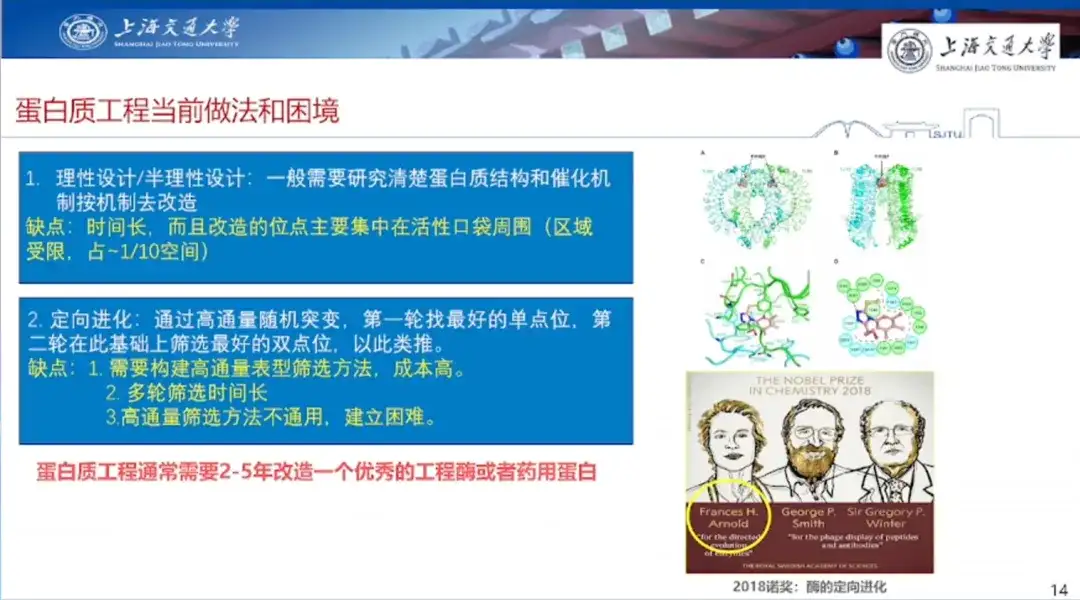
2番目のタイプは指向性進化です。つまり、人間の思考パラダイムを打ち破るため、ハイスループットのスクリーニングを通じて、ハイスループットの単一点ランダム変異が野生ベースで実行され、最初のラウンドで最良の単一点変異体が検索されます。 、最適な二重点変異体がこの位置に基づいてスクリーニングされます。利点は過去の経験に依存せず、「資金さえあれば実施できる」ことだが、欠点はハイスループットな表現型スクリーニング法の構築が必要であり、コストが高く、複数ラウンドに時間がかかることである。さらに、ハイスループットスクリーニング方法は普遍的ではなく、難易度を確立することが困難です。
ホン・リャン教授は、2016年にNatureに掲載された研究論文を例に、緑色蛍光タンパク質の実験を紹介した。同氏は、この実験では、ハイスループットスクリーニングにより陽性部位を選択することができ、研究者が部位変異を個別に実行するとタンパク質の特性を改善できるが、複数の変異部位が組み合わされるとタンパク質の合成が失われると指摘しました。活動。
この点に関して、彼はこう言いました。「広大な位相空間で優れた変異点を見つけ、それらを組み合わせて優れた多部位変異体を作り、その応用価値を実現する方法は、現在のタンパク質工学が直面している課題です。」

タンパク質工学のための汎用人工知能技術 - エンドツーエンドで機能的に設計された配列
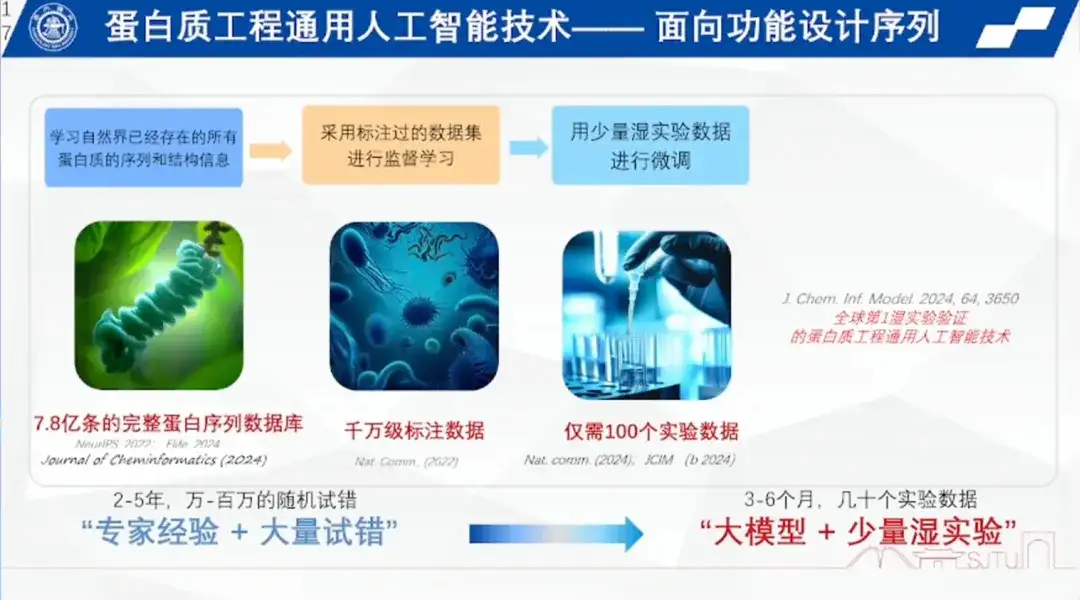
「人工知能が工学分野に突破口を開きたいのであれば、単に科学者のアシスタントを作成したり、文書収集などの基本的な作業を実行したりするだけではなく、人間の専門家にはできないことを実行しなければなりません。」これに基づいて、Hong Liang教授のチームは2021年にタンパク質工学の分野で独自のモデルの探索を開始し、機能の配列をエンドツーエンドで設計しました。
研究チームは、自然界のすべての既知のタンパク質に基づいて数億の完全なタンパク質配列のデータベースを構築し、このデータベースに基づいてアミノ酸の配置と規則を学習するタンパク質工学用の汎用人工知能を構築しました。
ホン・リャン教授は、上海科技大学のリウ・ジア教授と協力してクリスパーcas12aの熱安定性を向上させ、キンゼイ・ファーマシューティカルズと協力して単一ドメイン抗体のアルカリ耐性を向上させ、漢海新酵素と協力して酵素イノベーションを立ち上げた。 5 つの実際の応用事例では、タンパク質工学における一般的な人工知能技術の応用シナリオが詳しく説明されています。
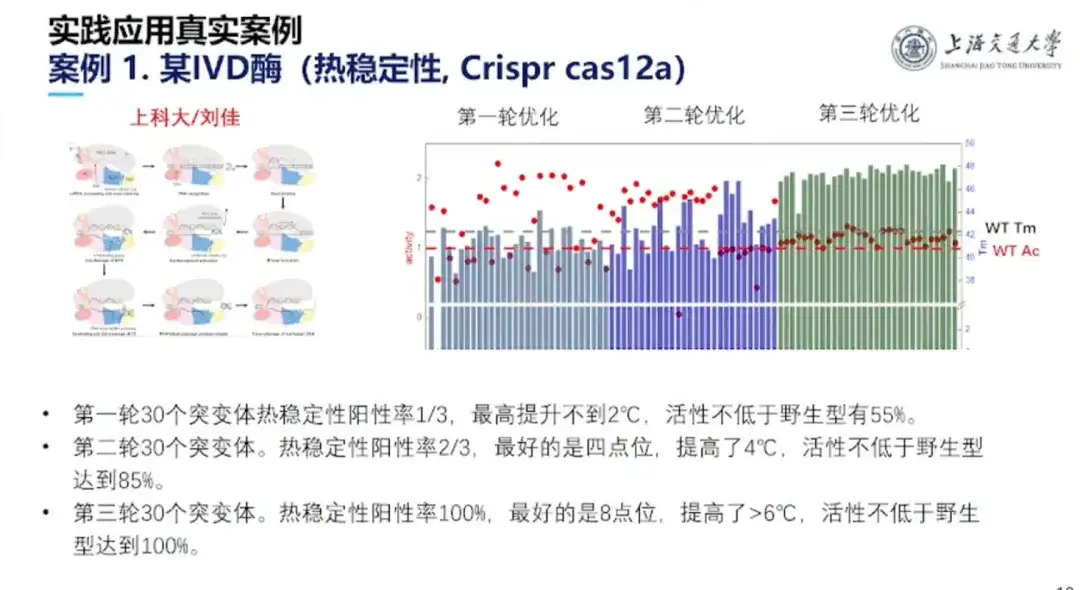
ケース 1: Crisper cas12a の熱安定性の向上
このプロジェクトは上海理工大学のHong Liang教授とLiu Jia教授のチームによって完成されました。Crisper cas12aは1,300個のアミノ酸で構成されており、野生型の活性は非常に優れていますが、体外診断キットとしては安定性が良くありません。 、室温では使用できず、冷蔵コストが高くなります。これを受けて研究チームは3回の実験を実施した。最終的に、変異体の安定性は継続的に増加する状態に達し、タンパク質活性は野生型の活性よりも低くならず、100%に達しました。
ホン・リャン教授はこう紹介した。「タンパク質工学の分野は最もネガティブなデータを持っています。AIはネガティブなサイトとポジティブなサイトを組み合わせることができ、タンパク質工学の想像力を広げます。これはプロの酵素エンジニアの合理的な設計の範囲を超えています。AIは基本的に物理計算を置き換えました。古い道。」
同氏はさらに、AI がタンパク質のネガティブな変異データとポジティブな変異データをどのように組み合わせるかの基本的なロジックを 3 つのステップに分けて紹介しました。
最初のステップは、タンパク質言語の語彙を構築することです。彼は、タンパク質配列情報を事前にトレーニングするプロセスをクローズ問題に例えました。つまり、モデルを使用して、数億の完全なタンパク質配列データベース内の任意の配列を連続的または離散的にブロックすると、モデルはブロックされた領域をカバーできるようになります。それを戻します。この操作は複数ラウンドにわたって繰り返され、タンパク質言語の語彙を構築するために数億のタンパク質配列でモデルを事前トレーニングできることが保証されます。
2 番目のステップはラベルを付けることです。温度、圧力、PHなど、研究チームは合計数千万のラベルを付けました。
3 番目のステップは、小規模サンプルの学習です。つまり、少量のウェット実験データを使用して微調整を行って強化学習を完了することで、生物工学におけるサンプル数が少ない問題を解決します。

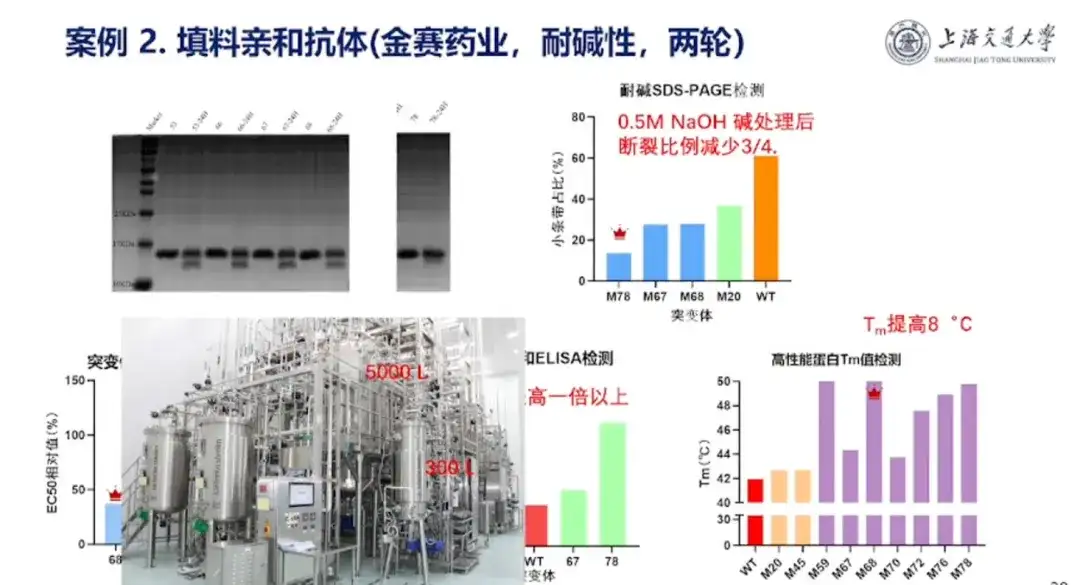
事例 2: Kinsey Pharmaceuticals と協力して、極めて耐アルカリ性の高い単一ドメイン抗体を開発
ホン・リャン教授は、キンゼイ・ファーマシューティカル社は、アルパカ単一ドメイン抗体ライブラリーから単一ドメイン抗体をスクリーニングし、水素カラムに置くことによって成長ホルモンを精製することが多いと指摘した。ただし、精製プロセス中に、水素とカラムは不可避的に何らかの不純物によって汚染されるため、次の精製実験に使用する前に強アルカリで洗浄する必要があります。しかし、生体は強アルカリに弱く、腐食する恐れがあります。したがって、Kinsey Pharmaceuticals は、単一ドメイン抗体のアルカリ耐性を改善したいと考えています。
この点について、研究チームは、Proシリーズ大型モデルで設計した単一ドメイン抗体を0.5M NaOHで24時間処理することで、アルカリ耐性を向上させることに成功した。本プロジェクトで設計した耐アルカリ性タンパク質は5,000Lの量産を達成しました。これは、現在大型モデルを使用して製造されている初の工業化されたタンパク質製品です。
事例3:酵素革新による糖転移酵素の選択性、活性、生産性の向上
急性膵炎および唾液腺炎のスクリーニングの中心となる物質はマルトヘプタグリコシドであり、非常に複雑な構造を持ち、化学生産コストが高く、中国での価格は 1 キログラムあたり数十万元に達します。これに応えて、Hong Liang教授のチームとHanhai New Enzymeは、グリコシルトランスフェラーゼを使用してマルトヘプタグリコシドを生成する酵素イノベーションを共同で立ち上げた。研究チームは、糖転移反応の強化、反応特異性の強化、加水分解活性の低下、収量の増加という4つの指標を改善する必要がある。
2ラウンドの形質転換実験を通じて、研究者らは80個の変異体のBUGインデックスを改善し、総グリコシル転移活性を8倍に高め、標的生成物の純度を80から95に高め、加水分解活性インデックスを10に下げ、P3を2倍にした。生産 。この製品は湖北省宜昌市の1,000kgの生産ラインに導入され、生産コストが大幅に下がりました。
ケース 4: 単一盲検試験における少量のサンプル学習に基づく抗体親和性試験
「AI for Science はサンプル数が少ないという問題を解決する必要があります。単に論文を発表するだけでは実用性はほとんどありません。」 ホン・リアン教授は、抗体製薬会社と協力して完成させたデモを通じて、これについて詳しく説明しました。
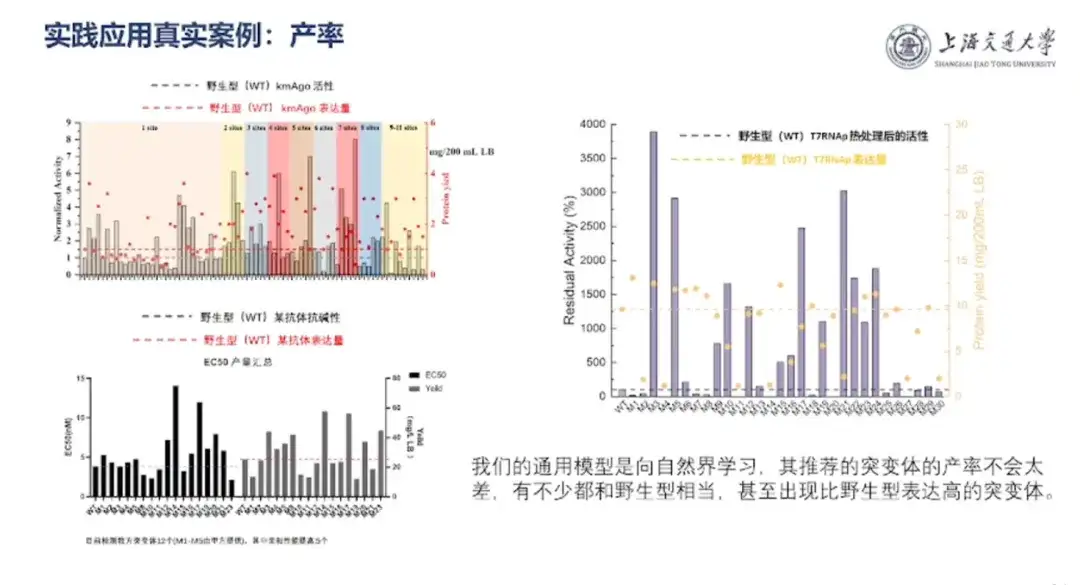
ホン・リャン教授は、これは全長245アミノ酸のScFv抗体で、21の変異部位が含まれており、考えられる変異配列は1,000万を超えていると紹介した。しかし、共同研究者らは、33 個の既知の変異体に関する親和性データと、予測が不明であった 14 個の新しい配列親和性データのみを提供しました。少数のサンプル学習に基づいて、チームは単一盲検テストで 0.65 の相関係数を達成しました。
「生物医学であろうと合成生物学であろうと、最終的な実装には依然としてコストの問題を解決する必要があります。つまり、収量が高くなければなりません。」ホン・リャン教授は、「チームのAIタンパク質設計モデルは自然からの学習に基づいており、推奨する変異体の収量はそれほど悪くない。それらの多くは野生型と同等であり、より高い変異体もある」と述べた。野生型の体よりも表情が豊かです。
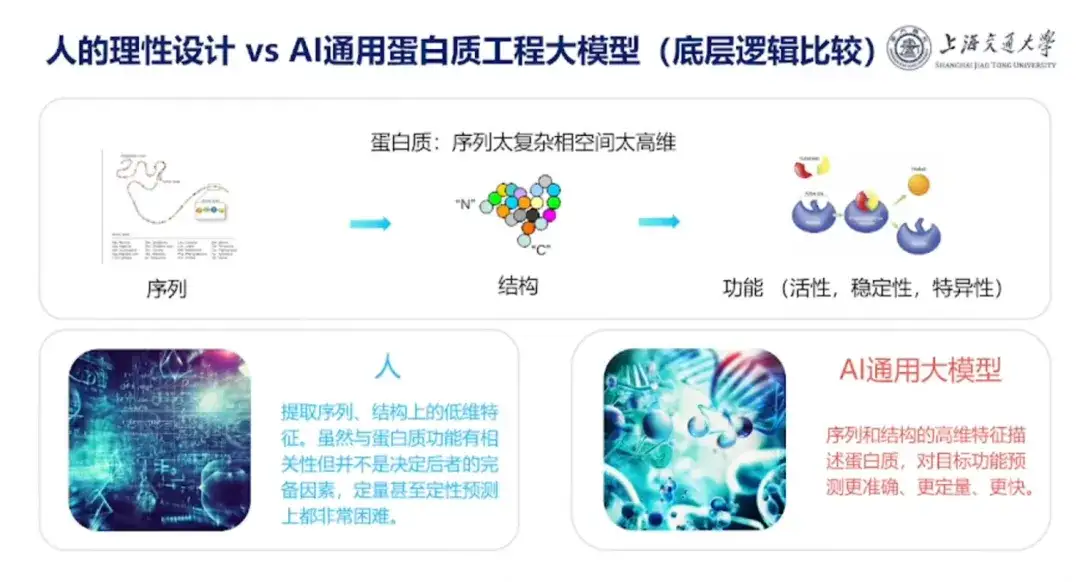
人間の脳のタンパク質設計と大規模な AI タンパク質設計モデルの違いについて、Hong Liang 教授は、主な違いは、人間は経験を要約することを好むが、人間の経験は一般にタンパク質の抽出シーケンスやタンパク質の抽出シーケンスなどの低次元であることであると指摘しました。構造内の低次元の特徴。これらの特性はタンパク質の機能に関連していますが、タンパク質の機能を決定する完全な要素ではないため、定量的および定性的に予測することが困難です。AI タンパク質設計大規模モデルは、高次元の特徴を使用してタンパク質の配列と構造を記述し、標的の機能をより正確、定量的、より迅速に予測できます。
ケース 5: タンパク質配列を最初から設計する (de novo)
この問題をさらに説明するために、Hong Liang 教授は彼の研究グループ Cell Discovery の結果を共有しました。同氏によると、これは、6つの構造ドメインと700以上のアミノ酸を持つ遺伝子編集酵素であるde novoデザインを通じて得られた、報告されたタンパク質配列としては最大のものであるという。
自然界に知られている編集酵素アルゴは 600 種類以上しかなく、研究チームはこれをテンプレートとして使用して 27 の新しい配列を生成しました。自然界と比較すると、配列類似性はすべて65%より低く、最も低いのは49%である。言い換えれば、研究チームは700以上のアミノ酸配列のうち300以上を改変しており、そのうち2/3にあたる23が活性である。野生型より活性が高く、最高の野生型は8.6倍に達した。
ホン・リャン教授は、「AIタンパク質設計の大型モデルは、300のアミノ酸配列の変換を達成でき、良好な活性と高い陽性率も維持している。この種の配列生成では、AIはすでに人間の専門家よりもはるかに強力である」と述べた。タスク。"
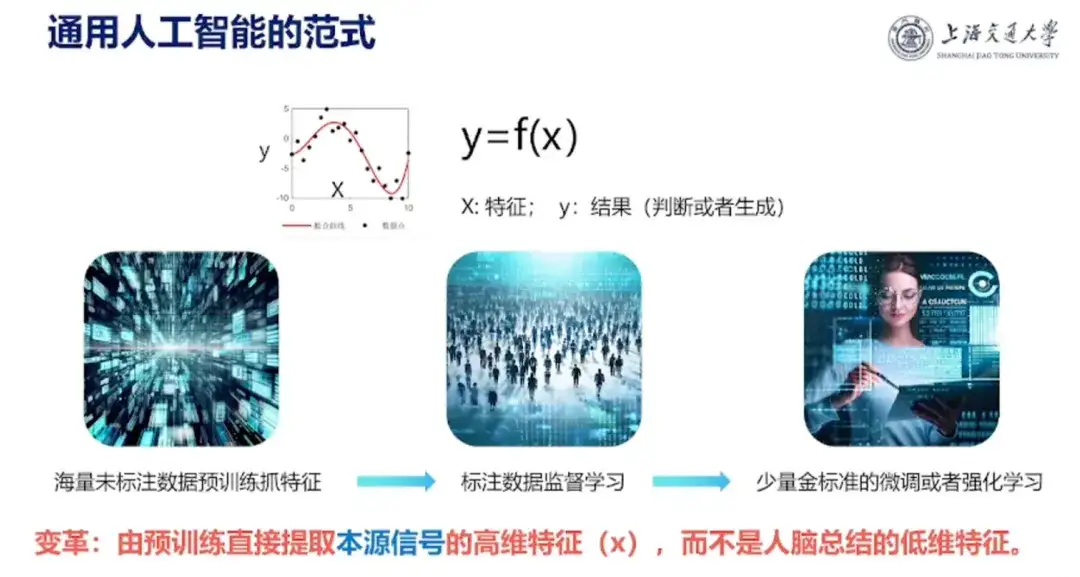
さらに、Hong Liang 教授は人工知能についての理解を次のように共有しました。「人工知能は y から x へのマッピングです。x は入力特徴、y はタンパク質の安定性や活性など、生成したい結果です。現在、人工知能は高次元のフィッティングを行っています。」
AIタンパク質設計の大型モデルで大幅な生産性向上を実現
ホン・リャン教授は、チームが構築した大規模なAIタンパク質設計モデルを示し、「研究者が内部ソフトウェアに配列を入力すると、プラットフォームは実験のために自然法則に適合する30または50の配列を選択し、その配列を入力します」と述べた。小さなサンプルの学習プロセス、つまり研究者が必要とする指標に合わせて AI モデルを微調整し、最終的に優勢な変異体が生成されます。」
現在、彼のチームにはタンパク質設計に焦点を当てている研究者は 2 人だけで、1 人は生物医学の分野、もう 1 人は合成生物学の分野にいますが、チームは 40 以上のプロジェクトを同時に実行していることは注目に値します。時間。これはまた、ホン教授が言ったことを裏付けるものでもあります。「AI が基礎となるエンジニアリングを突破する能力を獲得すれば、爆発的に大きな生産性を発揮するでしょう。」
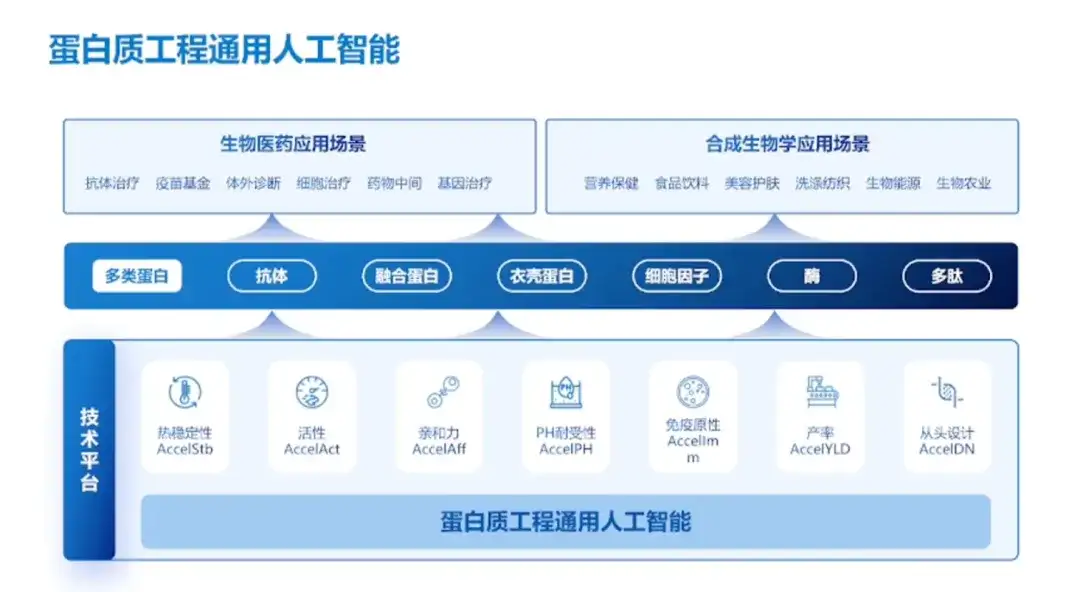
私たちは多くの大学や企業と緊密な協力関係を築いており、次の 3 つの主要な利点があります。
さらに、Hong Liang教授はチームの成果と核となる利点を全員に示しました。
成果に関しては、チームは清華大学や上海科技大学免疫化学研究所などの大学・研究機関や、キンゼイ・ファーマシューティカルズ、ハンハイ・ニュー・エンザイムズ、アルファマブなどの企業と緊密な協力を行ってきた。 。過去 1 年間で、20 種類のタンパク質の変換に成功し、実りある結果が得られました。
チームの利点について、Hong Liang教授は次のように述べています。このチームは「新しいデータ、独立したモデル、そして最初の製品の発売という 3 つの側面で核となる利点を持っています。」まず第一に、チームは公開データセットよりも大幅に大きい完全なタンパク質配列データを持っています。第二に、チームは独立したモデル、自己構築したタンパク質語彙、少数のサンプル学習方法、および配列 + 構造の事前トレーニング方法を持っています。実験の精度と研究速度は世界の最前線に達し、最終的にチームは複数のタンパク質製品の世界的な応用を実現することを主導しました。

AI for Science の展望: 今後 3 年間で、AI 大規模モデル自動化の標準設計モデルが実現される
ホン・リャン教授は、「今後 3 年間で、タンパク質設計、医薬品研究開発、疾患診断、新しい標的発見、化学合成ルート設計、材料設計などの分野において、専門分野における一般的な人工知能が明確な成果をもたらすだろう」と考えています。パラダイムが変化し、これまでの依存関係が置き換わります。散発的な試行錯誤による人間の脳の科学的発見モデルは、AI による大型モデルの自動化された標準設計モデルに変わりました。」

具体的な変更には、ゼロサンプルまたは小規模サンプルの学習方法の構築と、事前トレーニング技術モデルの構築が含まれます。データがない場合は、物理シミュレーターを使用して精度が若干低い偽データを大量に生成して事前学習し、実際の貴重なデータを使用して微調整して強化学習を完成させます。ホン教授は、「フェイクデータとは、現実世界ではないが、AIによって生成されたデータや、最終的には実際の湿式実験によって強化されたデータを指します。データは最も貴重であり、モデルの最終的な微調整に使用できます。」
この共有の最後に、Hong Liang 教授は、AI 文系学生と AI 科学系学生の比較をもう一度まとめました。 AI リベラルアーツの学生は本質的に人間の生活と仕事のパーソナルアシスタントです、Kimi、ChatGPT などは、人々が反復的な創造的な作業やあまり科学的ではない作業を減らすのに役立ちます。これは、大規模なデータ、低い精度要件、奇跡を生み出す能力、および強力なクロスドメイン汎用化機能を特徴としています。ただし、これは大規模な工場に属している必要があり、そうではありません。大学の研究機関に最適です。
そして AI 科学の学生が解決する必要があるのは、一種の科学または工学の問題です。企業や科学アカデミーの科学者の研究開発頭脳の代わりに、彼らは非常に創造的なことを行い、コストを大幅に削減して効率を高め、さらにはこれまでの科学的経験では達成できない製品を開発することができます。大学や科学研究機関のチームを組み合わせることができます。現場で関連する AI ソリューションを探索するには、彼ら独自の専門的な障壁があります。

ホン・リャン教授について
ホン・リャン教授は、学部では中国科学技術大学の物理学科で学び、大学院では香港中文大学でナノマテリアルの合成と特性評価を研究しました。米国のアクロン大学で博士号を取得しており、主な研究方向はポリマー/タンパク質の物理的および化学的特性と相転移です。

2010年、ホン・リアン教授は、米国のオークリッジ国立研究所に博士研究員として加わり、計算生物学の分野でタンパク質の構造、ダイナミクス、機能に焦点を当てています。 2015年、ホン・リャン教授は、分子生物物理学の研究に従事するため、独立したPIとして上海交通大学に加わりました。 2020年、ホン・リャン教授は、AI、コンピューティング、湿式実験を組み合わせてタンパク質設計研究を行っています。それは物理学から化学へ、次に化学から生物学へ、そして最後に湿式実験からコンピューティングと人工知能へと移りました。これは典型的な学際的な研究背景です。
3年を経て、ホン・リャン教授のチームは「配列から機能まで」AIタンパク質汎用人工知能プロシリーズを独自に開発: 大規模モデルの事前トレーニングから、基礎となる語彙の探索、そして教師あり学習方法に至るまで、タンパク質の物理的および化学的特性ラベルのデータベースを作成し、これに基づいて少量のサンプルの微調整方法を開発しました。ついに、機能的に設計されたタンパク質配列計画のための人工知能ソリューションが開かれました。
関連する結果については、彼の研究グループのホームページをご覧ください。
https://ins.sjtu.edu.cn/people/lhong/papers.html
これまで、Hong Liang教授が率いる研究チームは、学界および産業界のパートナーとの豊かで深い交流と協力を行ってきました。これには、生物医学、体外診断学、医薬品中間体、栄養とヘルスケア、食品と飲料、美容とスキンケア、洗濯と繊維、バイオエネルギー、生物農業、環境工学などの多くの分野が含まれます。科学研究の成果が狂気とも言えるほど多くなった時代においても、彼らは「実用化できる研究をする」という初志を貫き、地道に研鑽を積み、科学研究の成果を世界にもたらしています。研究室から生産ラインまで次々と運ばれます。
ホン・リャン教授について詳しくは、以下をご覧ください。
https://ins.sjtu.edu.cn/people/








