Command Palette
Search for a command to run...
ワンクリックで Meta の最大のビデオ セグメンテーション データ セットをダウンロードします。 47 か国をカバーする 50.9K の現実世界のビデオが含まれています

2023 年 4 月、Meta は「あらゆるものをセグメント化できる」と主張し、従来のコンピューター ビジョン (CV) タスクを覆す革新的な成果として、業界で広範な議論を引き起こし、すぐに医療画像のセグメンテーションに適用されました。他の垂直分野の研究。最近、SAM が再びアップグレードされました。メタ オープンソースの Segment Anything Model 2 (SAM 2) は、コンピューター ビジョンの分野におけるもう 1 つの画期的なマイルストーンとなります。
画像セグメンテーションからビデオセグメンテーションまで、SAM 2 は、リアルタイム プロンプト セグメンテーションで優れたパフォーマンスを発揮します。このモデルは、画像とビデオのセグメンテーションおよび追跡機能を統合モデルに導入し、ビデオ フレームにプロンプト (クリック、ボックス、またはマスク) を入力するだけで、画像またはビデオ内のオブジェクトを正確に識別してセグメント化します。サンプル学習能力により、SAM 2 は非常に高い汎用性を備えています。医療、リモートセンシング、自動運転、ロボット工学、迷彩物体検出などの分野で大きな応用可能性を示しています。 Meta はこれに自信を持っています。「私たちのデータ、モデル、洞察は、ビデオ セグメンテーションと関連する認識タスクの重要なマイルストーンになると信じています。」
実際、SAM 2 フロントフットがオンラインになったとき、誰もがそれを使用するのを待ちきれませんでした。そして、その効果は信じられないほど優れていました。

SAM 2 がオープンソースになってから半月も経たないうちに、トロント大学の研究者が SAM 2 を医療画像やビデオに使用し、論文を発表しました。

原紙:
https://arxiv.org/abs/2408.03322
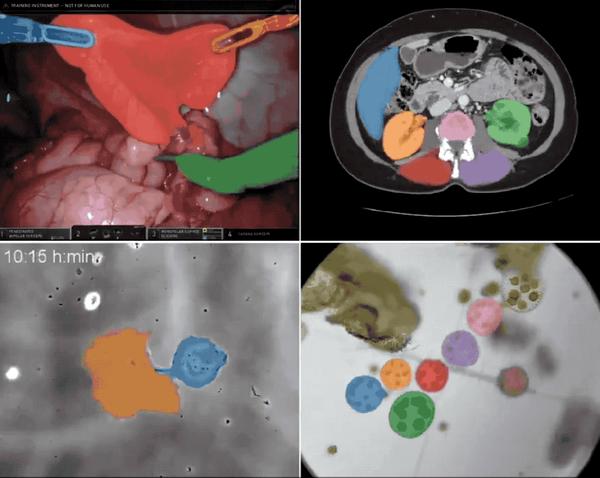
モデルにはトレーニング用のデータが必要ですが、SAM 2 も例外ではありません。 同時に、Meta は SAM 2 のトレーニングに使用される大規模データセット SA-V もオープンソース化しました。このデータセットは、一般的なオブジェクト セグメンテーション モデル (汎用オブジェクト セグメンテーション モデル) のトレーニング、テスト、評価に使用できることが報告されています。HyperAI Super Neural は、ワンクリックでダウンロードできる「SA-V: 最大のビデオ セグメンテーション データ セットを構築するためのメタ」を公式 Web サイトで開始しました。
SA-V ビデオ セグメンテーション データ セットは直接ダウンロードされます。
https://go.hyper.ai/e1Tth
さらに高品質のデータセットをダウンロードします。
https://go.hyper.ai/P5Mtc
既存のビデオ セグメンテーション データセットを超えてください。 SA-V は複数のトピックとシナリオをカバーします
メタ研究者は、以下の表に示すように、データ エンジンを使用して大規模で多様なビデオ セグメンテーション データセット SA-V を収集しました。このデータ セットには、50.9K のビデオと 642.6K のマスクレット (SAM 2 によって手動で注釈が付けられた 191K、および SAM 2 によって自動生成された 452K) が含まれています。他の一般的なビデオ オブジェクト セグメンテーション (VOS) データセットと比較して、SA-V ではビデオ、マスクレット、およびマスクの数が大幅に向上しています。ラベル付きマスクの数は、既存の VOS データセットの 53 倍です。将来のコンピューター ビジョン作業に豊富なデータ リソースを提供します。
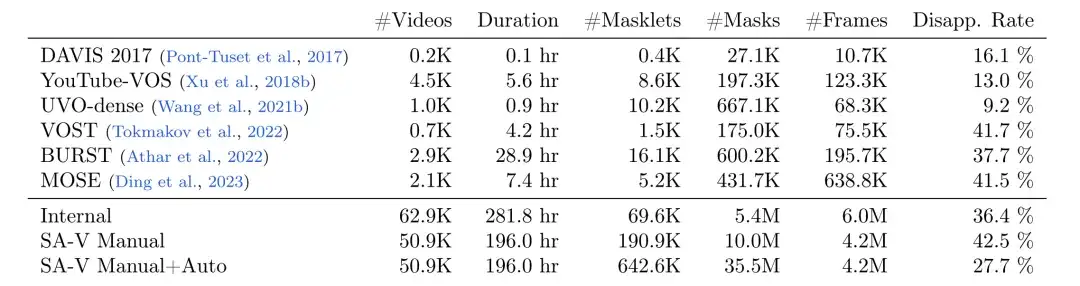
マスクセグメント数、マスク数、フレーム数、消失率の比較
*SA-V マニュアルには手動で注釈が付けられたラベルのみが含まれています
* SA-V Manual+Auto は、手動で注釈を付けたラベルと自動生成されたマスク セグメントを結合します。
SA-V には既存の VOS データ セットよりも多くのビデオが含まれており、平均ビデオ解像度は 1401 × 1037 ピクセルであることがわかります。集められた映像は日常のさまざまなシーンを網羅し、54% の屋内シーンのビデオと 46% の屋外シーンのビデオを含めると、平均再生時間は 14 秒です。また、動画のテーマも多岐にわたりますが、場所、オブジェクト、シーンなどを含むマスクは、建物のような大きなオブジェクトから室内装飾のような細かい部分まで多岐にわたります。
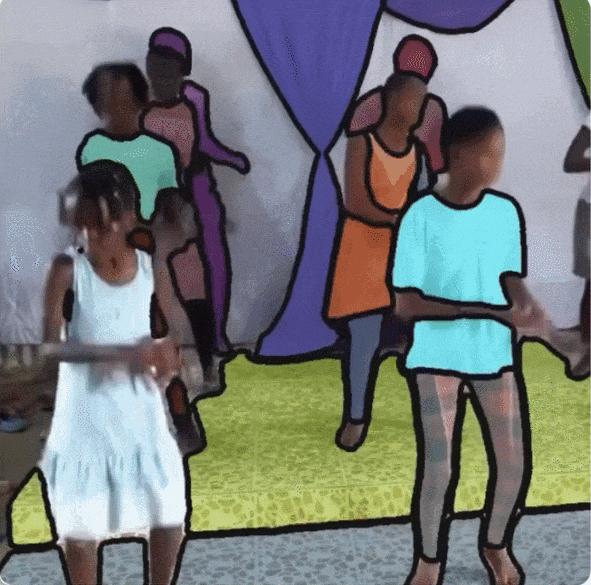
以下の図に示すように、SA-V のビデオは 47 か国をカバーしており、また、さまざまな参加者が撮影した図 a は、DAVIS、MOSE、および YouTubeVOS のマスク サイズ分布と比較して、SA-V が 0.1 未満の正規化されたマスク面積が 88% を超えていることを示しています。
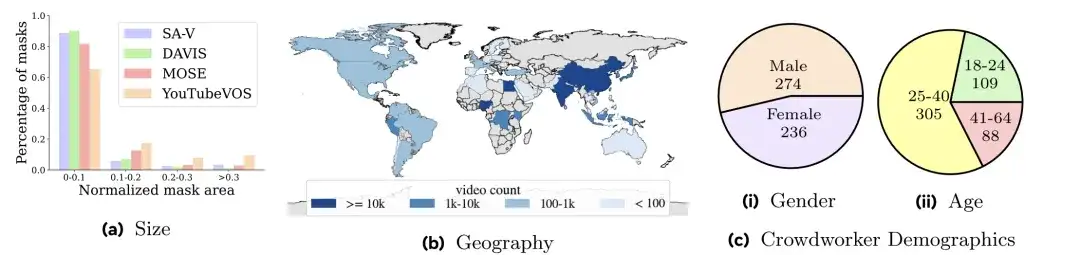
研究者らは、ビデオの作者とその地理的位置に従って SA-V データセットを分割しました。データ内の類似したオブジェクトの重複が最小限に抑えられるようにします。SA-V 検証セットと SA-V テスト セットを作成するために、研究者らはビデオを選択する際に困難なシーンに焦点を当て、アノテーターが素早く移動するターゲット、他のオブジェクトによって遮蔽されるターゲット、および消失/再出現パターンを持つターゲットを識別することを要求しました。最後に、SA-V 検証セットには 293 個のマスクレットと 155 個のビデオがあり、SA-V テスト セットには 278 個のマスクレットと 150 個のビデオがあります。さらに、研究者らは社内で利用可能なライセンス付きビデオ データを使用してトレーニング セットをさらに強化しました。
SA-V ビデオ セグメンテーション データ セットは直接ダウンロードされます。
https://go.hyper.ai/e1Tth
上記は、この号で HyperAI が推奨するデータ セットです。高品質のデータ セット リソースを見つけた場合は、メッセージを残すか、投稿してお知らせください。
さらに高品質のデータセットをダウンロードします。
https://go.hyper.ai/P5Mtc








