Command Palette
Search for a command to run...
Llama 3.1 中国語微調整データセットはオンラインであり、ワンクリックで超大規模モデルを展開できます

7月のAIサークルは本当に小さなモデルから大きなモデルまでいっぱいで、ワクワクが止まりませんでした!ほとんどの学生は GPT-4o や Mistral-Nemo などの小型モデルを体験できますが、Llama-3.1-405B や Mistral-Large-2 などの非常に大きなモデルは多くの学生にとって困難です。
心配しないで!hyper.ai 公式 Web サイトでは、これら 2 つの非常に大きなモデルを 2 つの方法で起動する方法に関するチュートリアルが提供されています。「Open WebUI」を使用する方法と「OpenAI 互換 API サービス」を使用する方法のチュートリアル セクションです。さらに、中国語の微調整されたデータセット DPO-zh-en-emoji もリリースされました。記事をプルダウンしてリンクを取得してください。
8 月 5 日から 8 月 9 日までの hyper.ai 公式 Web サイト更新の概要:
* 高品質なチュートリアルのセレクション: 5
* 高品質の公開データセット: 10
* コミュニティ記事の選択: 3 記事
* 人気のある百科事典のエントリ: 5
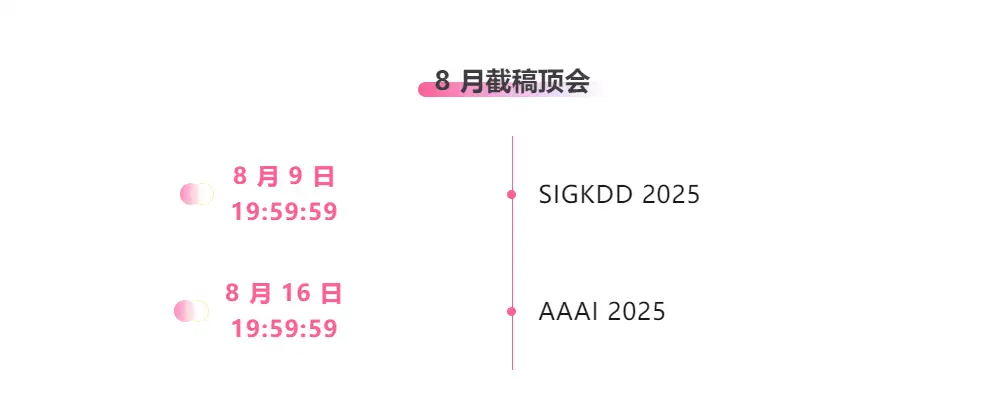
※8月提出締切:2
公式ウェブサイトにアクセスしてください:ハイパーアイ
選択された公開チュートリアル
1. Open WebUI を使用して、ワンクリックで Mistral Large 2 / Llama 3.1 405B を展開します
このチュートリアルでは、OpenWebUI を使用して、ワンクリックで Mistral Large 2 / Llama 3.1 405B をデプロイします。推論エクスペリエンスのためにコンテナを複製して起動するだけで済みます。
* Mistral Large 2 モデルの展開をオンラインで実行します。
* Llama 3.1 405B モデルの展開をオンラインで実行します。
2.Mistral Large 2 / Llama 3.1 405Bモデル OpenAI対応APIサービスのワンクリック導入
このチュートリアルでは、OpenAI 互換 API を使用して Mistral-Large-Instruct-2407-AWQ をデプロイします。 「OpenAI 互換 API」とは、サードパーティ開発者が OpenAI と同じリクエストおよび応答形式を使用して、同様の機能を独自のアプリケーションに統合できることを意味します。このチュートリアルを開始すると、OpenAI 互換の SDK でモデルに接続できます。前のチュートリアルよりも複雑で、プログラミングの基礎がある人に適しています。
* Mistral Large 2 モデルの展開をオンラインで実行します。
* Llama 3.1 405B モデルの展開をオンラインで実行します。
3. ギブス拡散を使用してブラインド画像ノイズを低減します。
Gibbs-Diffusion の正式名である GDiff は、信号およびノイズ パラメータの事後サンプリングの問題を解決するベイジアン ブラインドノイズ除去法です。このチュートリアルは、論文「Listening to the Noise: Blind Denoising with Gibbs Diffusion」に組み込まれたテスト方法に基づいています。チュートリアルの手順に従って研究結果を体験してください。
オンラインで実行:https://go.hyper.ai/y2wIU
公開データセットの選択
1. DPO-zh-en-emoji 絵文字の質問と回答のデータ セット
このデータ セットは、大規模な言語モデルを微調整するために特別に設計されたデータ セットであり、各質問には中国語版と英語版の両方の回答が含まれており、その回答には次のような興味深い要素が組み込まれています。絵文字(絵文字)の使用。 shareAI チームは、これを使用して Llama 3.1 8B モデルを微調整しました。
直接使用します:https://go.hyper.ai/Y90pZ
2. UrbanSARFloods v1 洪水マッピング ベンチマーク データセット
UrbanSARFloods は、都市およびオープンエリアの洪水マッピング専用のデータセットで、807,500 平方キロメートルをカバーし、18 の洪水イベントをカバーする 8,879 個の 512 × 512 の画像パッチが含まれています。これにより、既存の大規模な SAR に基づく洪水マッピング研究では都市洪水への注意が不十分であるという問題が解決されます。
直接使用します:https://go.hyper.ai/yOXx7
3. VRSBench 大規模で高品質なリモートセンシングビジュアル言語ベンチマークデータセット
このデータセットは、リモート センシング画像理解用に設計された多目的の視覚言語ベンチマーク データセットで、手動で検証された 29,614 個の詳細なキャプション画像、52,472 個のオブジェクト参照、および 123,221 個の質問と回答のペアが含まれており、汎用の大規模な開発を促進することを目的としています。リモートセンシング画像の視覚言語モデル。
直接使用します:https://go.hyper.ai/O7DtC
4.ATLAS高解像度3Dキャラクターテクスチャデータセット
データセットの正式名は ArTicuLated humAn textureS (略して ATLAS) で、最大の高解像度 (1,024 × 1,024) 3D ヒューマン テクスチャ データセットで、テキスト説明付きの 50,000 個の高忠実度テクスチャが含まれています。関連する論文結果が ECCV 2024 に選ばれました。
直接使用します:https://go.hyper.ai/Zx1nj
MIND には、約 160,000 件の英語ニュース記事と、100 万人のユーザーによって生成された 1,500 万件を超えるインプレッション ログが含まれており、これらは Microsoft News Web サイト上の匿名の行動ログから収集されました。これは、ニュース推奨のベンチマーク データ セットとして機能し、ニュース推奨および推奨システムの分野での研究を促進することを目的としています。
直接使用します:https://go.hyper.ai/lVOyX
BoWFire データセットは、火災検出の精度を向上させ、誤報を減らすことを目的として、火炎検出用に特別に設計された画像データセットです。このデータセットには、建物火災、産業火災、自動車事故、暴動など、さまざまな緊急事態の火災画像が含まれています。
直接使用します:https://go.hyper.ai/73AYY
このデータセットには、CNN とデイリー メールのジャーナリストが執筆した 300,000 件を超えるニュース記事が含まれており、長い段落のテキストを 1 つまたは 2 つの文に要約できるモデルの開発を支援するように設計されています。
直接使用します:https://go.hyper.ai/AbidL
データセットには、340 の落書きカテゴリをカバーする 100 万枚以上の画像が含まれており、機械学習タスク用に処理されます。
直接使用します:https://go.hyper.ai/Ns4M4
Yoga-16 データセットは、ヨガのポーズ認識モデルの分類精度を向上させることを目的としています。これはトレーニング、テスト、検証の 3 つのメイン ディレクトリに分かれており、各ディレクトリには 16 の異なるヨガの姿勢に対応する 16 のサブディレクトリが含まれています。
直接使用します:https://go.hyper.ai/iMe0Z
10. 人体画像データセット 男性と女性の人体画像データセット
このデータセットには、男性と女性の 2 つの人物カテゴリの画像フォルダーが含まれています。画像には顔、上半身、全身が含まれます。性別認識、人物識別、画像分類などのさまざまなプロジェクトで使用できます。
直接使用します:https://go.hyper.ai/6UJb7
その他の公開データセットについては、以下をご覧ください。
https://hyper.ai/datasets
注目のコミュニティ記事
1. 学術の共有丨清華大学博士研究員 Li Yuzhe 氏が Cell/Nature サブジャーナル論文を詳細に説明し、ゲノミクスにおける AI 応用を探求
生放送「Meet AI4S」シリーズの第 2 回エピソードでは、清華大学の張強峰研究室の博士研究員である李雨哲氏が招待されました。 8月21日、Li Yuzhe博士はオンラインライブブロードキャストの形で、空間トランスクリプトミクスと単細胞オミクス研究におけるAI手法をさらに共有します。
イベントの詳細を表示:https://go.hyper.ai/GIzpo
2.世界初!清華大学と上海交通大学などが共同で糖尿病の診断と治療のためのビジュアルラージ言語モデルを構築、Natureサブジャーナルに掲載
Google Research は MIT と提携して、IJCAI 2024 Best Paper Award を受賞しました。公式アカウントのバックエンドからIJCAI 2024に返信すると、IJCAI 2024最優秀論文賞、優秀論文賞、AIJ古典論文賞、優秀論文賞コレクションを獲得できます。
レポート全体を表示します。https://go.hyper.ai/ZGzI2
3. 初めて! GPT-2 は無線通信の物理層を強化し、北京大学チームは事前トレーニングされた LLM に基づくチャネル予測ソリューションを提案します
清華大学副院長兼医学部長のHuang Tianyin教授のチーム、上海交通大学電気工学部コンピュータサイエンス学科のSheng Bin教授のチーム/中国の人工知能重点研究室教育省、上海交通大学医学部付属第六人民病院のJia Weiping教授とLi Huating教授のチーム、シンガポール国立大学とシンガポール国立眼科センターのQin Yuzong教授のチームが協力しました。共同して、糖尿病の診断と治療のための世界初の視覚-大規模言語モデル統合システム DeepDR-LLM の構築に成功しました。この記事は、研究の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/qnzSp
人気のある百科事典の項目を厳選
1. 和集合比 IoU の交差
2. 相互ソーティング融合 RRF
3. 対照学習
4. 大規模マルチタスク言語理解MMLU
5. 長期記憶と短期記憶 長短期記憶
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
* 1,300 を超える公開データセットに対して国内の高速ダウンロード ノードを提供
* 400 以上の古典的で人気のあるオンライン チュートリアルが含まれています
* 100 以上の AI4Science 論文ケースを解釈
* 500 以上の関連用語クエリをサポート
*Apache TVM の最初の完全な中国語ドキュメントを中国でホストします
学習の旅を始めるには、公式 Web サイトにアクセスしてください。








