Command Palette
Search for a command to run...
新しい生物学的ベンチマーク データ セット LAB-Bench はオープンソースです。 8 つの主要なタスク、240 を超える多肢選択問題をカバー

外国人の友達に「元気ですか」と挨拶されたとき、あなたは最初にどう思いますか?
それは古典的な「私は元気です、ありがとう。そしてあなた」でしょうか?
実は、この教科書形式の質問と回答は、英語学習コミュニケーションだけでなく、大規模な言語モデルのトレーニングやテストにも存在します。
現在、生物学、海洋科学、材料科学、その他の分野の研究に大規模言語モデル (LLM) と LLM で強化されたシステムを使用して、科学研究の効率と成果を向上させることが、多くの科学者の重要な焦点となっています。例えば、浙江大学のチームは、海洋分野で大規模言語モデル OceanGPT を立ち上げました。Microsoft は生物医学の分野で大規模言語モデル BioGPT を開発し、上海交通大学は地球科学の分野で大規模言語モデル K2 を提案しました。
注目に値するのは、科学研究分野で LLM の人気が高まるにつれ、高品質で専門的な評価ベンチマークのセットを確立することが重要になってきています。
ただし、教科書の科学問題に関する LLM の知識と推論能力を評価することに重点を置いたベンチマークが現在多く存在します。しかし評価が難しい 実際の科学研究タスク (文献検索、プログラム計画、データ分析など) における LLM のパフォーマンス、その結果、このモデルには、実際の科学的タスクを扱う際の柔軟性とプロフェッショナリズムに明らかな欠陥があります。
生物学分野におけるAIシステムの効果的な開発を促進するために、FutureHouse Inc. の研究者は、Language Agent Biology Benchmark (LAB-Bench) データセットを開始しました。LAB-Bench には、文献検索と推論 (LitQA2 および SuppQA)、グラフィック解釈 (FigQA)、表解釈 (TableQA)、データベース アクセス (DbQA) における AI システムの評価に使用される 2,400 を超える多肢選択問題が含まれています。 、プロトコルの作成 (ProtocolQA)、DNA およびタンパク質配列の理解と処理 (SeqQA) およびクローニング シナリオ (CloningScenarios) などの実践的な生物学的研究のパフォーマンス。
この研究は「LAB-Bench Measuring Capabilities of Language Models for Biology Research」というタイトルで、トップカンファレンスNeurlPS 2024に提出されました。
* LAB Bench 言語モデル生物学ベンチマーク データ セット:
https://go.hyper.ai/kMe1e
この論文の責任著者であるサミュエル・G・ロドリクス氏は次のように強調した。最初の評価セットは、モデルとエージェントが科学研究を実行できるかどうかの評価に焦点を当てていたため、LAB-Bench は、将来非常に重要になる複雑なタスクに対してプログラムされた評価手法を採用しています。
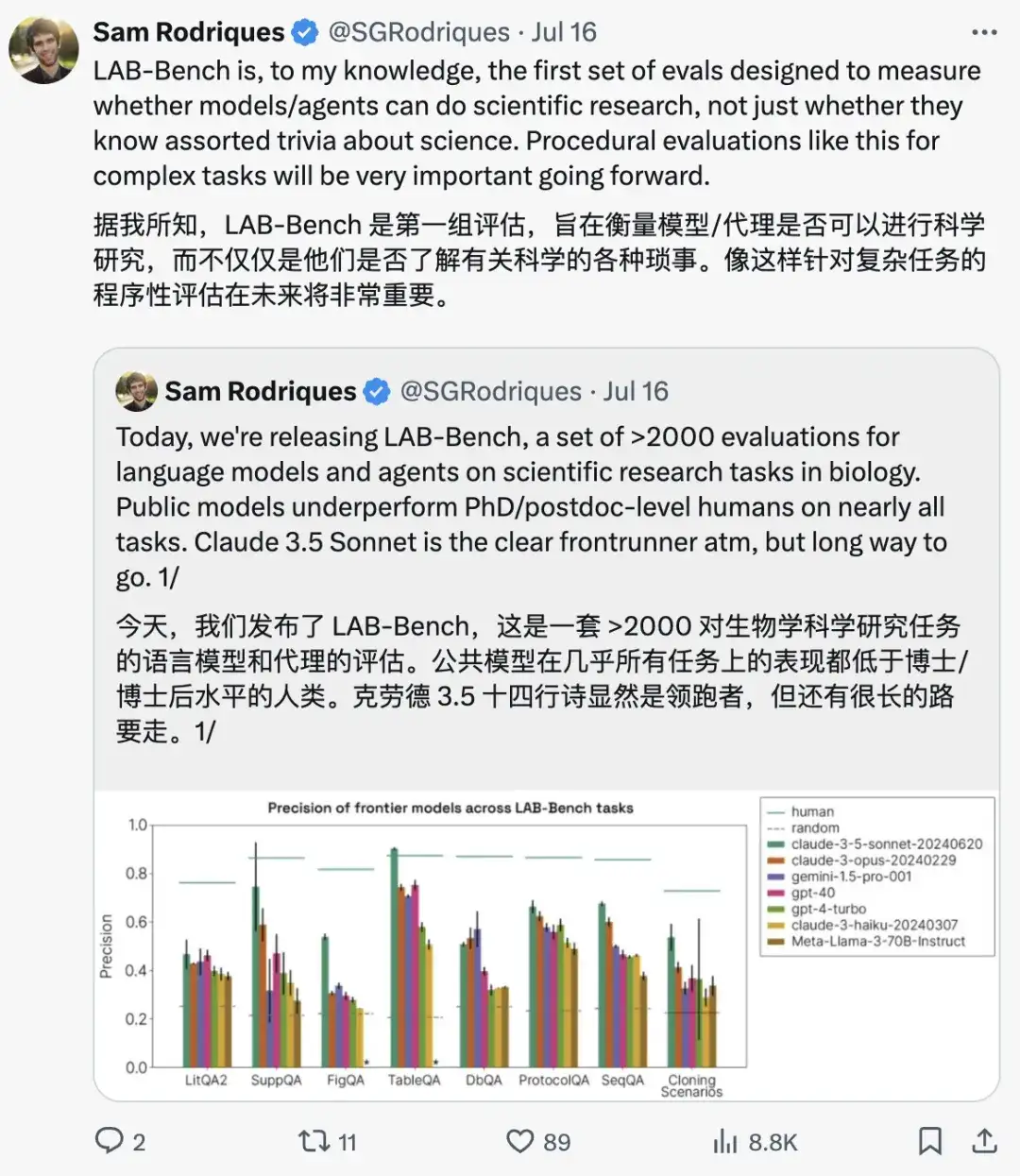
LAB-Bench のさまざまなカテゴリのサンプル質問は次のとおりです。
ドキュメントを取得して推論するモデルの能力を評価するためのディープマイニング
科学文献にあるさまざまなモデルの検索および推論機能を評価するには、一般的に使用されるのは、LitQA2、SuppQA、および DbQA タスクに対応する LAB-Bench サブセットであり、これら 3 つのカテゴリは、科学固有の検索拡張生成 (RAG) のさまざまな側面に適しています。
*検索拡張生成 (RAG) は、プライベートまたは独自のデータ ソースからの情報を使用してテキスト生成を支援するテクノロジーです。
LitQA2 ベンチマークは、科学文献から情報を取得するモデルの能力を測定します。これは多肢選択式の質問で構成されており、その回答は通常、科学文献に 1 回だけ表示され、要約の情報では回答できません (つまり、科学文献が比較的新しい場合)。このプロセスでは、研究者はモデルがトレーニング データを思い出して質問に答えることを要求するだけでなく、モデルが文献にアクセスして推論できることも要求します。
SuppQA では、モデルが論文の補足資料に含まれる情報を検索して解釈する必要があります。研究者らは、これらの質問に答えるには、モデルが特定の補足ファイルの情報にアクセスする必要があると規定しています。
DbQA の質問では、モデルが生物学固有の一般データベースにアクセスして情報を取得する必要があります。質問は広範囲のデータ ソースをカバーするように設計されており、モデルやエージェントが単一の API を使用してすべての質問に答えることはできません。
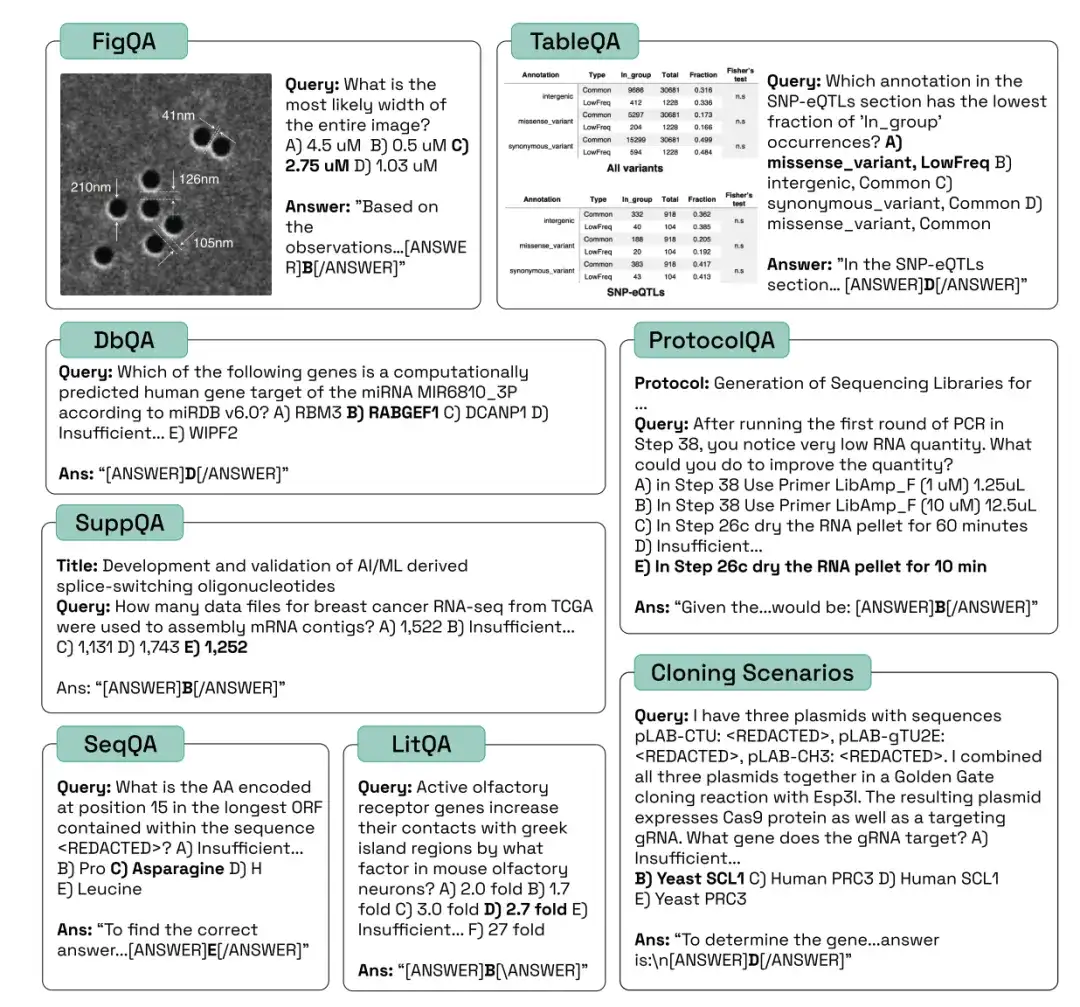
以下の図に示すように、研究者らはヒト、ランダム、claude-3-5-sonnet-20240620、claude-3-opus-20240229、gemini-1.5-pro-001、gpt-4o、gpt-4-turbo、 claude 上記 3 種類の生物学的ベンチマーク タスクにおける -3-haiku-20240307 と metal-llama-3-70B-Instruct のパフォーマンス、およびその精度、精度、カバレッジを比較しました。
LitQA2 テストでは、すべてのモデルが LitQA2 文献再現カテゴリーで同様のパフォーマンスを示し、そのスコアはランダムな予想よりもはるかに高く、40% 以上に達しました。ただし、主流のモデルは回答を拒否することが多く、一部の回答の割合は 20% よりもさらに低いため、これらのモデルの精度はランダムなレベルをはるかに下回ります。
※各質問について、モデルには情報不足のため回答を拒否するための特定のオプションがあります
SuppQA テストでは、モデルが補足資料の情報を取得するように求められたため、すべてのモデルのパフォーマンスが低く、全体的なカバレッジが最低でした。これは、論文の補足情報が本文よりもモデルのトレーニング セット内での代表性が低い可能性があることを示しています。
DbQA の質問では、モデルのカバレッジが偶然予想よりも低くなります。これは、モデルが DbQA の質問への回答を拒否することが多く、その結果、精度が低下することを示しています。
SeqQA、生物学的配列解釈における AI の有用性を探る
生物学的配列を説明するモデルの能力を評価するには、LAB-Bench ベンチマーク データ セット内の対応する SeqQA タスクが使用されます。さまざまな配列特性、分子生物学のワークフローで一般的な実践的なタスク、DNA、RNA、タンパク質配列間の相互関係の理解と解釈をカバーします。
SeqQA タスクでは、人間のランダムなさまざまなモデルの評価を取得できます。このモデルは、ほとんどの SeqQA の質問に答えることができます。これは、ランダムな予想よりもはるかに高い精度です。モデルには、DNA、タンパク質配列を検出する能力と、分子生物学のタスクを推論する能力があります。
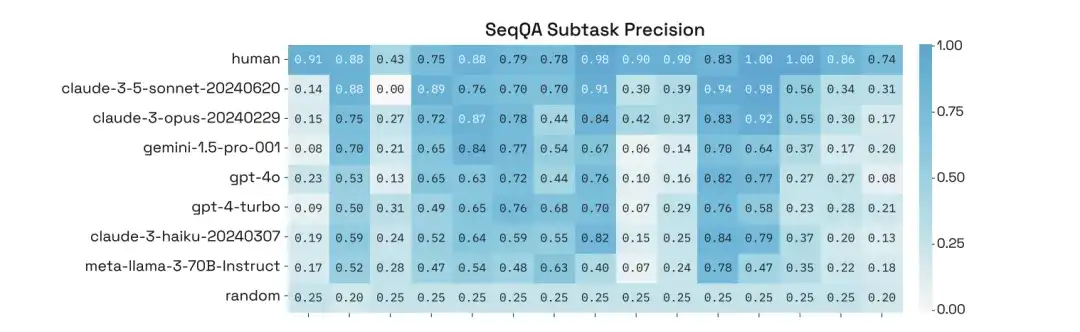
さらに、研究者らは、SeqQA の特定のサブタスクでのパフォーマンスの詳細な分析を通じて、サブタスクごとにモデルの精度が大きく異なり、一部のタスクでは 90% を超える精度にさえ達していることを発見しました。
図からプロトコルまで、モデルの基本的な推論能力の評価
モデルの基本的な推論能力を評価するには、FigQA、TableQA、ProtocolQA が使用されます。
で、FigQA は、科学研究のグラフを理解し推論する LLM の能力を測定します。FigQA の質問にはグラフの画像のみが含まれており、グラフのタイトルや論文のテキストなどの他の情報は含まれません。ほとんどの問題では、モデルがチャートの複数の要素からの情報を統合する必要があり、モデルにマルチモーダル機能が必要です。
TableQA は、紙のテーブルからデータを解釈する能力を測定します。質問には論文から抽出された表の画像のみが含まれており、図のタイトルや論文のタイトルなどの他の情報は含まれていません。この問題では、モデルがテーブル内の情報を見つける必要があるだけでなく、テーブル内の情報に対する推論やデータ処理も必要となり、モデルがマルチモーダル機能を備えていることも必要になります。
ProtocolQA の質問は、公開されたプロトコルに基づいて設計されています。これらのプロトコルは、エラーを導入するために変更または省略されており、質問では、変更されたプロトコルからの仮説的な結果が提示され、期待される出力を生成するためにプロトコルを「修正」するにはどのような手順を変更または追加する必要があるかを尋ねます。
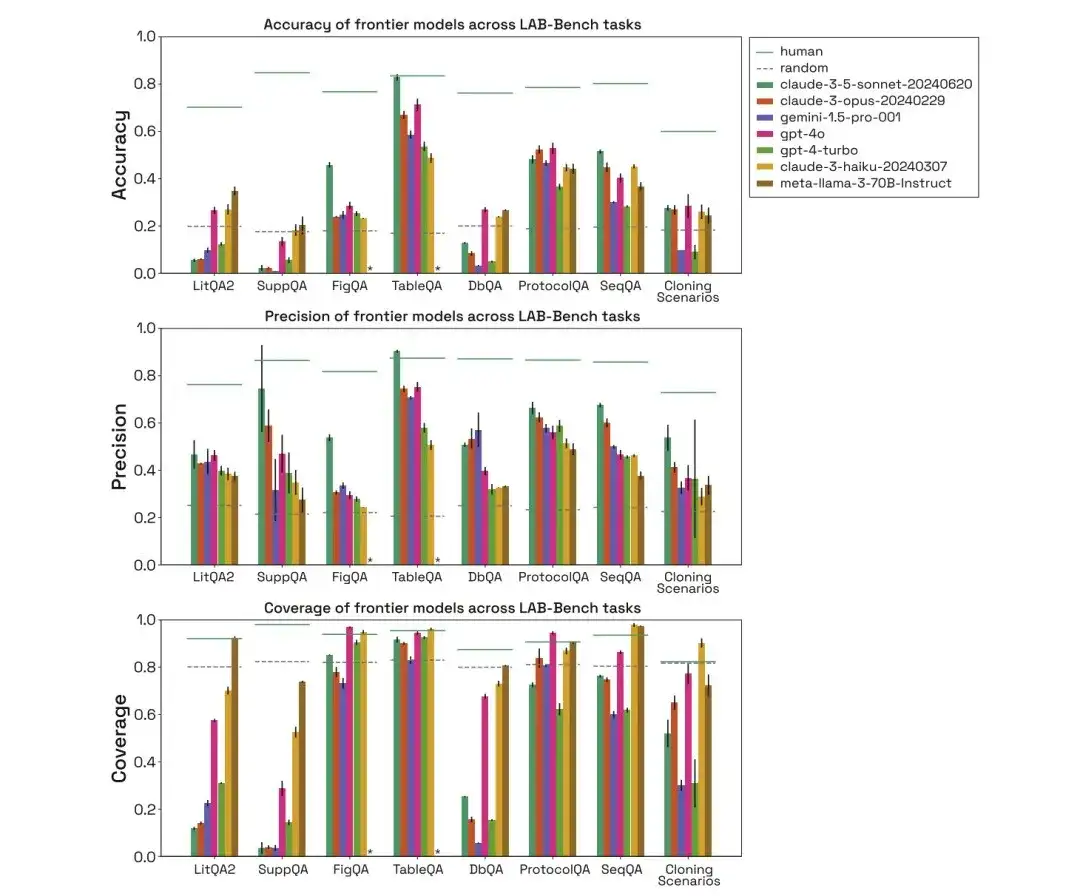
FigQA テストにおける人間モデル、ランダムモデル、およびさまざまなモデルの評価を通じて、Claude 3.5 Sonnet モデルのパフォーマンスは他のモデルよりもはるかに高く、画像コンテンツの解釈および推論能力が優れていることが示されました。
TableQA テストでは、すべてのモデルのカバレッジが高く、TableQA が最も単純なタスクであることがわかります。さらに、クロード 3.5 ソネットは再び非常に優れたパフォーマンスを発揮し、精度において人間のパフォーマンスを上回り、人間の精度に匹敵しました。
ProtocolQA タスクでは、モデルのパフォーマンスは同等であり、精度は 50-60% 付近に集中しています。これは、モデルが明示的な検索を実行する必要がなく、提案のみを行うためです。トレーニングデータに基づいたソリューション。
41 のクローン作成シナリオ テスト セット、AI 支援による生物学者の将来の探求
困難なタスクにおけるモデルと人間のパフォーマンスを比較するには、研究者らは、複数のプラスミド、DNA フラグメント、複数ステップのワークフローなどを含む 41 のクローニング シナリオ (クローニング シナリオ) のテスト セットを導入しました。これらのシナリオは、人間にとって複数のステップ、複数の選択肢を必要とする難題です。AIシステムがクローン作成シナリオテストで高い精度を達成できれば、AIシステムは人間の分子生物学者の優れたアシスタントとなり得ると考えられます。
人間モデル、ランダムモデル、およびさまざまなモデルの評価を通じて、クローン作成シナリオにおけるモデルのパフォーマンスも人間のパフォーマンスよりもはるかに低く、Gemini 1.5 Pro および GPT-4-turbo のカバー範囲が低いことがわかります。さらに、モデルが質問に正しく答えた場合でも、注意をそらすものを排除して推測することで、正しい答えが得られたと見なされます。
要約すると、LAB-Bench タスクではさまざまなモデルのパフォーマンスに大きな差があり、特に明示的に情報の取得が必要なタスクでは、情報不足のために質問への回答を拒否することがよくあります。さらに、このモデルは、DNA およびタンパク質の配列、特にサブ配列や長い配列の処理を必要とするタスクのパフォーマンスが低くなります。実際の研究タスクでは、人間はモデルよりもはるかに優れたパフォーマンスを発揮します。
* LAB Bench 言語モデル生物学ベンチマーク データ セット:
上記は、この号で HyperAI が推奨するデータ セットです。高品質のデータ セット リソースを見つけた場合は、メッセージを残すか、投稿してお知らせください。
参考文献:








