Command Palette
Search for a command to run...
スタンフォード/Apple を含む 23 機関が DCLM ベンチマーク テストをリリースしました。高品質のデータセットはスケーリングの法則を揺るがすことができますか?基本モデルは Llama3 8B と同等のパフォーマンスを発揮します

AI モデルに対する人々の注目はますます高まっており、スケーリング則に関する議論もますます白熱しています。
OpenAI は、2020 年に論文「ニューラル言語モデルのスケーリング則」で初めてスケーリング則を提案しました。これは、大規模言語モデルのムーアの法則とみなされます。その意味は次のように簡単に要約できます。モデルのパフォーマンスは、モデルのサイズ、データセットのサイズ、および浮動小数点計算 (トレーニングに使用される) の数が増加するにつれて向上します。
スケーリングの法則の影響で、多くの支持者は依然として「大きい」ことがモデルのパフォーマンスを向上させるための第一原則であると常に信じています。特に、「豊富な資金」を持つ大企業は、大規模で多様なコーパス データ セットにさらに依存しています。
この点に関して、清華大学コンピュータサイエンス学部の博士であるQin Yujia氏は次のように指摘した。この側面は、長期的にはベースモデルがより優れていることを誰にでも伝えますが、一方で、スケーリングの法則の限界効果を考慮すると、私たちは次世代を観察し続けたいと考えています。モデルを GPT3 から GPT4 に改善するには、少なくとも 10 桁多くのデータ (150T など) が必要になる可能性があります。」

言語モデルのトレーニングに必要なデータ量の継続的な増加とデータ品質の問題に対応して、ワシントン大学、スタンフォード大学、Apple を含む 23 機関が協力して、実験的テスト プラットフォーム DataComp for Language Models (DCLM) を提案しました。そのコアは Common Crawl から派生しています。 240T の新しい候補語彙ライブラリは、トレーニング コードを修正することで、研究者がイノベーションのための新しいトレーニング セットを提案することを奨励します。これは、言語モデルのトレーニング セットの改善にとって非常に重要です。
関連する研究は、「DataComp-LM: 言語モデルの次世代トレーニング セットを求めて」というタイトルで学術プラットフォームに公開されています。 http://arXiv.org 優れた。
研究のハイライト
* DCLM ベンチマークの参加者は、412M から 7B パラメーターのモデル スケールでデータ管理戦略を実験できます。
* モデルベースのフィルタリングは、高品質のトレーニング セットを構築するための鍵です。生成されたデータ セット DCLM-BASELINE は、2.6T トレーニング トークンを使用した MMLU での 7B パラメーター言語モデルのゼロからのトレーニングをサポートし、5 ショット精度に達します。
* DCLM の基本モデルは、MMLU 上の Mistral-7B-v0.3 および Llama3 8B と同等のパフォーマンスを発揮します

用紙のアドレス:
https://arxiv.org/pdf/2406.11794v3
オープンソース プロジェクト「awesome-ai4s」は、100 を超える AI4S 論文の解釈をまとめ、大規模なデータ セットとツールを提供します。
https://github.com/hyperai/awesome-ai4s
DCLM ベンチマーク: さまざまなコンピューティング スケール要件を達成するための 400M から 7B までのマルチスケール設計
DCLM は、言語モデルを改善するためのデータセット実験プラットフォームであり、言語モデル トレーニング データ管理の最初のベンチマークです。
以下の図に示すように、DCLM ワークフローは主に、スケールの選択、データセットの構築、モデルのトレーニング、53 の下流タスクに基づくモデルの評価の 4 つのステップで構成されます。
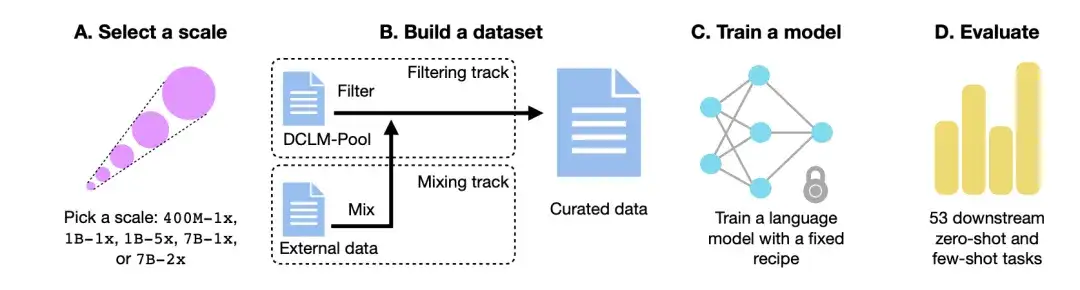
計算スケールを選択してください
まず、計算規模の点で、研究者らは 3 桁の計算規模にわたる 5 つの異なる競争レベルを作成しました。各レベル (つまり、400M-1x、1B-1x、1B-5x、7B-1x、および 7B-2x) は、モデル パラメーターの量 (たとえば、7B) およびチンチラ乗数 (たとえば、1x) を指定します。スケールあたりのトレーニング トークンの数は、パラメーターの数とチンチラ乗数の 20 倍です。
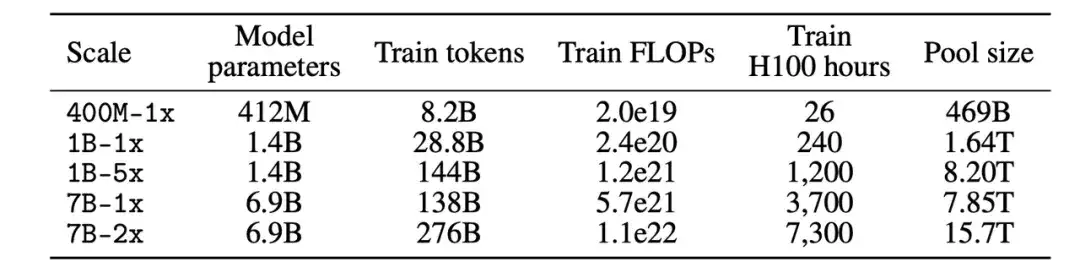
データセットを作成する
第二に、パラメータスケールを決定した後、データセットを確立するプロセス中に、参加者はデータをフィルタリング(Filter)または混合(Mix)することによってデータセットを作成できます。
フィルタリングトラックでは、研究者らは、フィルタリングされていないクローラー Web サイト Common Crawl から 240T トークンの標準化されたコーパスを抽出し、DCLM プールを構築し、計算規模に基づいて 5 つのデータ プールに分割しました。参加者はアルゴリズムを提案し、データプールからトレーニングデータを選択します。
ミックストラックでは、参加者は複数のソースからのデータを自由に組み合わせることができます。たとえば、DCLM プール、カスタム クロール データ、スタック オーバーフロー、Wikipedia からのデータ ドキュメントを合成します。
トレーニングモデル
OpenLM は、分散トレーニング用の FSDP モジュールに焦点を当てた、PyTorch に基づくコード ベースです。データセットの干渉の影響を排除するために、研究者らは各データ スケールでのモデル トレーニングに固定の方法を使用しました。
モデル アーキテクチャとトレーニングに関する以前のアブレーション研究に基づいて、研究者は GPT-2 や Llama などのデコーダのみの Transformer アーキテクチャを採用し、最終的に OpenLM でモデル トレーニングを実行しました。
モデルの評価
やっと、研究者らは、LLM-Foundry ワークフローを通じて、基本的なモデル評価に適した 53 の下流タスクに基づいてモデル評価を実施しました。これらの下流タスクには、質疑応答、自由形式の生成形式が含まれ、コーディング、教科書の知識、常識的推論などのさまざまな分野がカバーされます。
データ並べ替えアルゴリズムを評価するために、研究者らは主に、MMLU 5 ショット精度、CORE 中心精度、および EXTENDED 中心精度という 3 つのパフォーマンス指標に焦点を当てました。
データセット: DCLM を使用して高品質のトレーニング データセットを構築する
DCLM はどのようにして高品質のデータ セット DCLM-BASELINE を構築し、データ管理方法の効果を定量化するのですか?
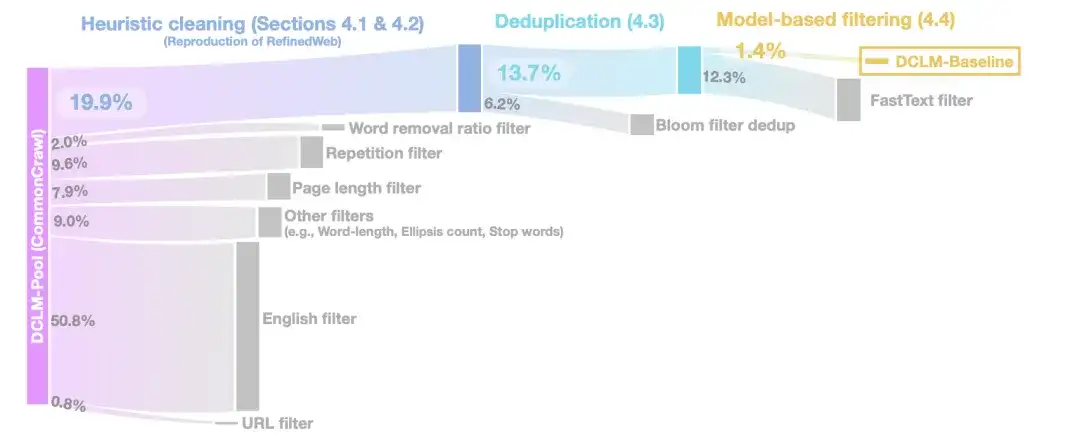
ヒューリスティック クリーニング ステージでは、研究者らは、RefinedWeb メソッドを使用してデータをクリーンアップしました。具体的な操作には、URL フィルター (URL フィルター)、英語フィルター (英語フィルター)、ページ長フィルター (ページ長フィルター)、重複コンテンツ フィルター (繰り返しフィルター) などが含まれます。
重複排除の段階では、研究者らは、ブルーム フィルターを使用して抽出されたテキスト データの重複を排除し、修正されたブルーム フィルターの方が 10 TB のデータ セットに拡張しやすいことも発見しました。
データの品質をさらに向上させるために、モデルベースのフィルタリング段階では、研究者らは 7 つのモデルベースのフィルタリング手法を比較しました。フィルタリング、セマンティック重複排除 (SemDedup)、fastText バイナリ分類子などに PageRank スコアを使用することを含め、fastText ベースのフィルタリングが他のすべての方法よりも優れていることがわかります。
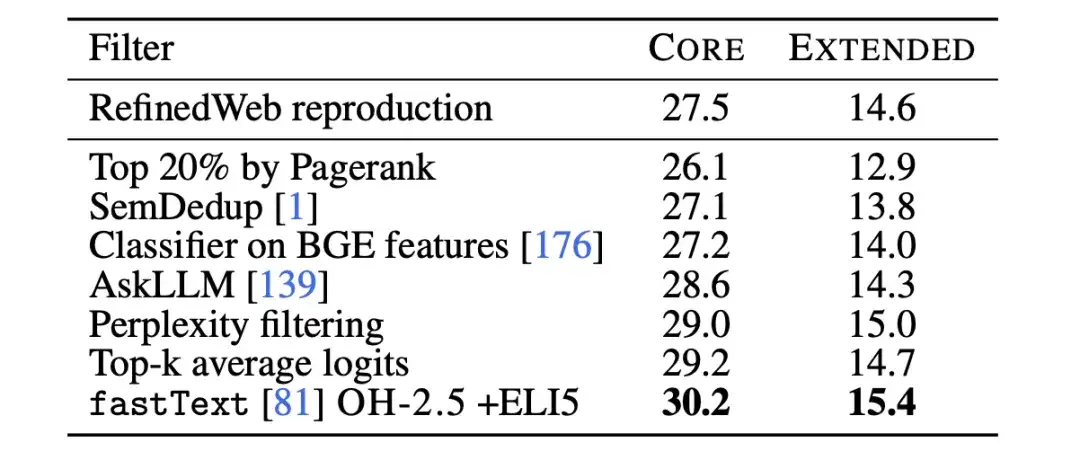
その後、研究者らはテキスト分類器アブレーション実験を使用して、fastText に基づくデータ フィルタリングの限界をさらに研究しました。研究者らは、以下の図に示すように、参照データ、特徴空間、フィルタリングしきい値のさまざまな選択肢を調査しながら、いくつかの異なるバリアントをトレーニングしました。研究者らは参照データとして、一般的に使用されている Wikipedia、OpenWebText2、および RedPajama-books を選択しました。これらはすべて GPT-3 で使用される参照データです。
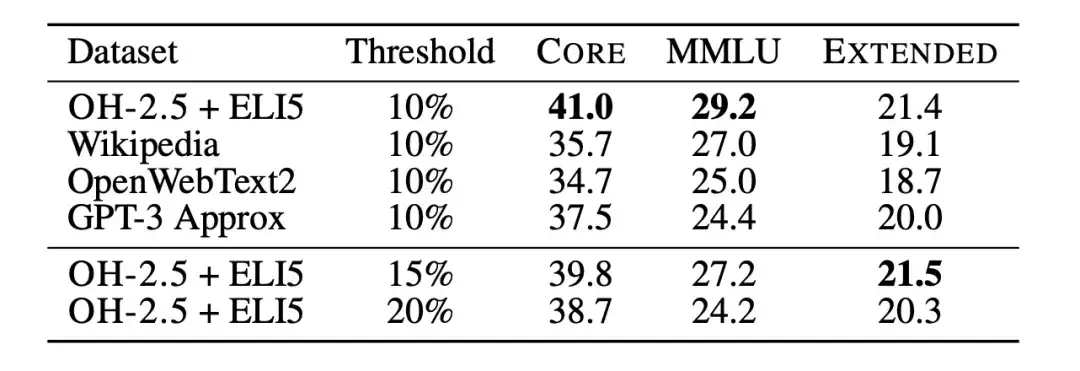
同時に、研究者らはまた、OpenHermes 2.5 (OH-2.5) および r/ExplainLikeImFive (ELI5) サブレディットの高スコア投稿から例を抽出し、命令形式のデータを革新的に利用しました。結果は、一般的に使用される参照データと比較して、OH-2.5 + ELI5 メソッドが CORE を 3.5% 改善することを示しています。
さらに、研究者らは、厳密なしきい値 (つまり、しきい値 10%) により、より優れたパフォーマンスを達成できることを発見しました。それで、研究者らは、fastText OH-2.5 + ELI5 分類子スコアを使用してデータをフィルタリングし、上位 10% ドキュメントを保持して DCLM-BASELINE を取得しました。
調査結果: 高品質のデータセットの生成、モデルベースのフィルタリングが鍵
まず、研究者らは、未評価のトレーニング前データの汚染が研究結果に影響を与えるかどうかを分析しました。
MMLU は、大規模な言語モデルのパフォーマンスを測定するベンチマーク テストとして、さまざまな言語を理解するモデルの能力をより包括的に検査することを目的としています。したがって、研究者は MMLU を評価セットとして使用し、MMLU から DCLM-BASELINE の問題を検出して削除します。その後、研究者らは、検出された MMLU のオーバーラップを使用せずに、DCLM-BASELINE に基づいて 7B-2x モデルをトレーニングしました。
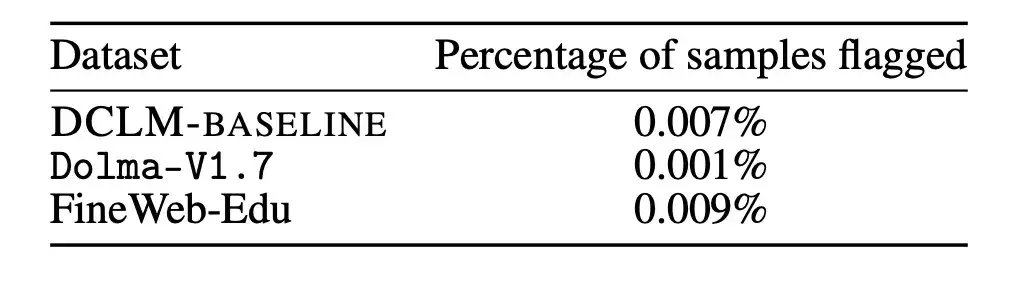
結果は、以下の図に示すように、汚染されたサンプルの除去によってモデルのパフォーマンスが低下しないことを示しています。このことからわかることは、MMLU テスト ベンチマークにおける DCLM-BASELINE のパフォーマンスの向上は、そのデータ セットに MMLU 内のデータが含まれているという事実によるものではありません。

これに加えて、研究者らは上記の除去戦略を Dolma-V1.7 と FineWeb-Edu にも適用して、DCLM-BASELINE とこれらのデータセットの間の汚染の違いを測定しました。 DLCM-BASELINE の汚染統計は、他の高性能データセットとほぼ同様であることがわかりました。
次に、研究者らは、トレーニングされた新しいモデルを 7B ~ 8B パラメーター スケールの下で他のモデルと比較しました。結果は、DCLM-BASELINE データセットに基づいて生成されたモデルが、オープン ソース データセットでトレーニングされたモデルよりも優れたパフォーマンスを示し、クローズド ソース データセットでトレーニングされたモデルと競合できることを示しています。
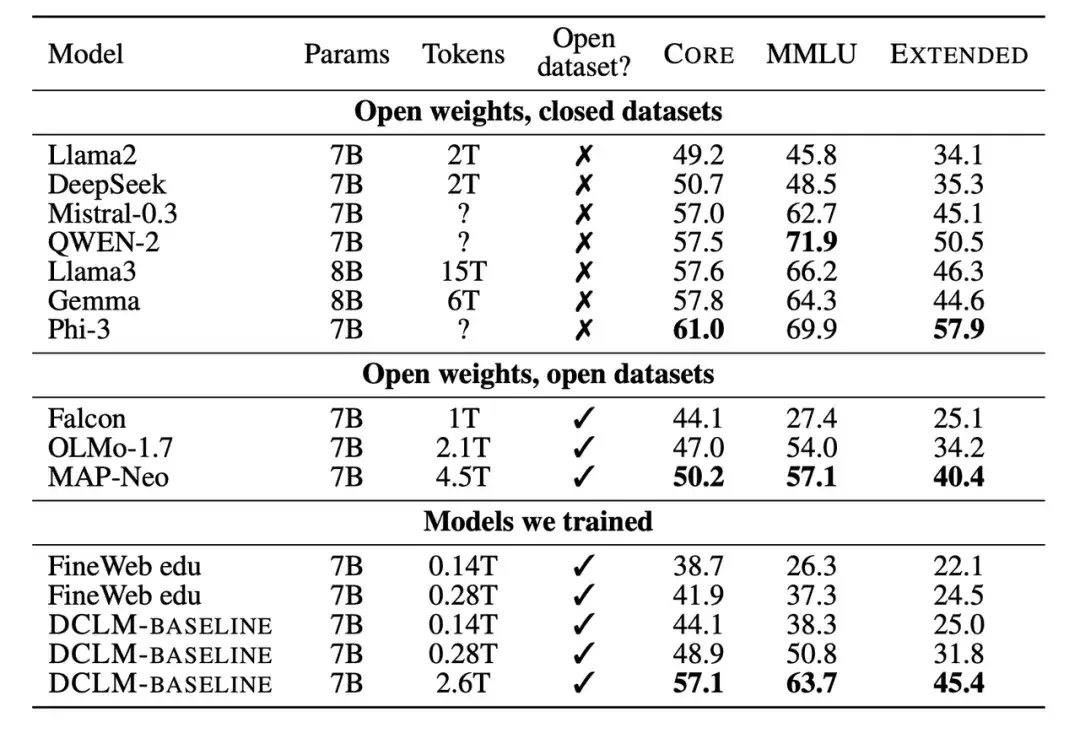
多くの実験結果が示しています。モデルベースのフィルタリングは高品質のデータセットを形成するための鍵であり、データセットの設計は言語モデルのトレーニングにとって非常に重要です。生成されたデータセット DCLM-BASELINE は、2.6T トレーニング トークンを使用して MMLU 上で 7B パラメーター言語モデルを最初からトレーニングすることをサポートし、64% の 5 ショット精度を達成します。
従来の最先端オープンデータ言語モデルMAP-Neoと比較して、生成されたデータセット DCLM-BASELINE は、MMLU を 6.6 % 改善し、トレーニングに必要な計算量を 40% 削減します。
DCLM の基本モデルは、MMLU 上の Mistral-7B-v0.3 および Llama3 8B (63% および 66%) に匹敵し、53 の自然言語理解タスクで同様に実行しますが、トレーニングに必要な計算量は Llama3 8B の 6.6 分の 1 です。
スケーリング則 スケーリング則の将来の方向性は不透明で、言語モデルの次世代トレーニング セットを探しています
要約すると、DCLM の中核は、研究者がモデルベースのフィルタリングを通じて高品質のトレーニング セットを構築することを奨励し、それによってモデルのパフォーマンスを向上させることです。そしてこれは、「美しさとして大きなものを取る」というモデルトレーニングのトレンドの下で、新しい問題解決のアイデアも提供します。
清華大学コンピューターサイエンス学部の博士課程の Qin Yujia 氏は、「データを縮小する時期が来ています」と述べています。複数の論文を分析して要約することで、彼は「クリーンなデータ + クリーニング後の小さなモデルは、ダーティなデータ + 大規模なモデルの効果をより正確に近似できる」ことを発見しました。
7 月初旬、ビル・ゲイツ氏は最新の Next Big Idea ポッドキャストで AI テクノロジーのパラダイム変化について言及し、スケーリングの法則は終わりに近づいていると考えていました。コンピューターインタラクションにおける AI の革命はまだ到来していませんが、その本当の進歩は、単にモデルのサイズを大きくすることではなく、より人間に近いメタ認知能力を実現することにあります。

これに先立ち、多くの国内業界関係者が2024年の北京知源会議でスケーリング法の将来の方向性について徹底的な議論を行った。
Lingyiwuwu の CEO である Li Kaifu 氏は、スケーリングの法則は効果的であることが証明されており、まだピークに達していないと述べています。しかし、スケーリングの法則を使用するだけでは、モデルの効果を向上させるために単に盲目的に GPU をスタックすることはできません。勝つために十分な GPU を備えた企業や国に。
清華大学インテリジェント産業研究所所長のZhang Yaqin氏は、スケーリング法の導入は主に大量のデータの利用とコンピューティング能力の大幅な向上から恩恵を受けると述べた。それは今後 5 年間の産業発展の主な方向性であり続けるでしょう。

Dark Side of the Moon の CEO、Yang Zhilin 氏は、より多くのコンピューティング能力、データ、そしてモデルのパラメータが大きくなる限り、モデルはより多くのインテリジェンスを生成し続けることができると考えています。彼は、スケーリング則は進化し続けると信じていますが、その過程でスケーリング則の手法は大きく変わる可能性があります。
Baichuan Intelligence の CEO、Wang Xiaochuan 氏は、スケーリング法に加えて、単に知識の圧縮に移行するのではなく、コンピューティング能力、アルゴリズム、データ、その他のパラダイムにおける新たな変革を模索する必要があると考えています。このシステムから抜け出すことによってのみチャンスを得ることができます。 AGIに向けて進みます。
大規模モデルの成功は、スケーリング則の存在によるところが大きく、スケーリング則は、モデルの開発、リソースの割り当て、適切なトレーニング データの選択にある程度の貴重な指針を提供します。 「スケーリング則の終焉」はまだ分からないかもしれませんが、DCLM ベンチマークは、モデルのパフォーマンスを向上させるための新しい思考パラダイムと可能性を提供します。
参考文献:
https://arxiv.org/pdf/2406.11794v3
https://arxiv.org/abs/2001.08361








