Command Palette
Search for a command to run...
20 の実験データが AI タンパク質のマイルストーンを作成します。上海交通大学と上海AIラボはタンパク質の事前トレーニングモデルを効果的に最適化するFSFPをリリース

タンパク質は、小さくても強力な生体分子であり、生命活動の基礎であり、生物の中でさまざまな役割を果たしています。ただし、特定の産業または医療のニーズに合わせてタンパク質の機能を正確に調整して最適化することは、非常に困難な作業です。従来、科学者はタンパク質の謎を探求するために湿式実験室法に頼ってきましたが、このアプローチは時間と費用がかかります。
幸いなことに、人工知能の急速な発展に伴い、事前トレーニングされたタンパク質言語モデル (PLM) という新しいツールが、前例のない方法でタンパク質の動作を理解し、予測するのに役立っています。 PLM は、何百万ものタンパク質のアミノ酸配列の分布特性を教師なしで学習し、タンパク質配列とその機能の間の暗黙の関係を明らかにする上で大きな可能性を示し、広い設計空間を効率的に探索するのに役立ちます。今、事前トレーニング済み PLM は、実験データがないにもかかわらず大幅な進歩を遂げてきましたが、その精度と解釈可能性はまだ改善する必要があります。さらに、従来の教師あり学習モデルでは大量のラベル付きトレーニング サンプルが必要ですが、これも実際のアプリケーションでは乗り越えられない障害となっています。
上記の問題を解決するために、上海交通大学自然科学研究所/物理天文学院/張江高等研究院/薬学部のホン・リャン教授と、上海人工知能研究所の若手研究者タン・パン氏の研究グループは、メタ転移学習 (MTL)、ランク付け学習 (LTR)、パラメーター効率の良い微調整 (PEFT) を包括的に使用し、データが極度に不足している場合にタンパク質言語モデルを効果的に最適化できるトレーニング戦略 FSFP を開発しました。これは、タンパク質の適合性の小規模サンプル学習に使用でき、非常に少ないウェット実験データを使用して突然変異特性を予測する従来のタンパク質事前トレーニング大規模モデルの効果を大幅に改善し、実用的なアプリケーションでも大きな可能性を示します。
関連する研究のタイトルは「少数ショット学習による最小限のウェットラボデータによるタンパク質言語モデルの効率の向上」で、Nature のサブジャーナルである Nature Communications に掲載されました。

用紙のアドレス:
https://doi.org/10.1038/s41467-024-49798-6
ProteinGym タンパク質変異データセットのダウンロード アドレス:
オープンソース プロジェクト「awesome-ai4s」は、100 を超える AI4S 論文の解釈をまとめ、大規模なデータ セットとツールを提供します。
https://github.com/hyperai/awesome-ai4s
データ不足の問題に対処し、FSFP はタンパク質言語モデルを最適化します。
FSFP アプローチは 3 つのフェーズで構成されます。メタトレーニング用の補助タスクを構築し、補助タスクで PLM をトレーニングし、LTR 経由で PLM をターゲット タスクに転送します。
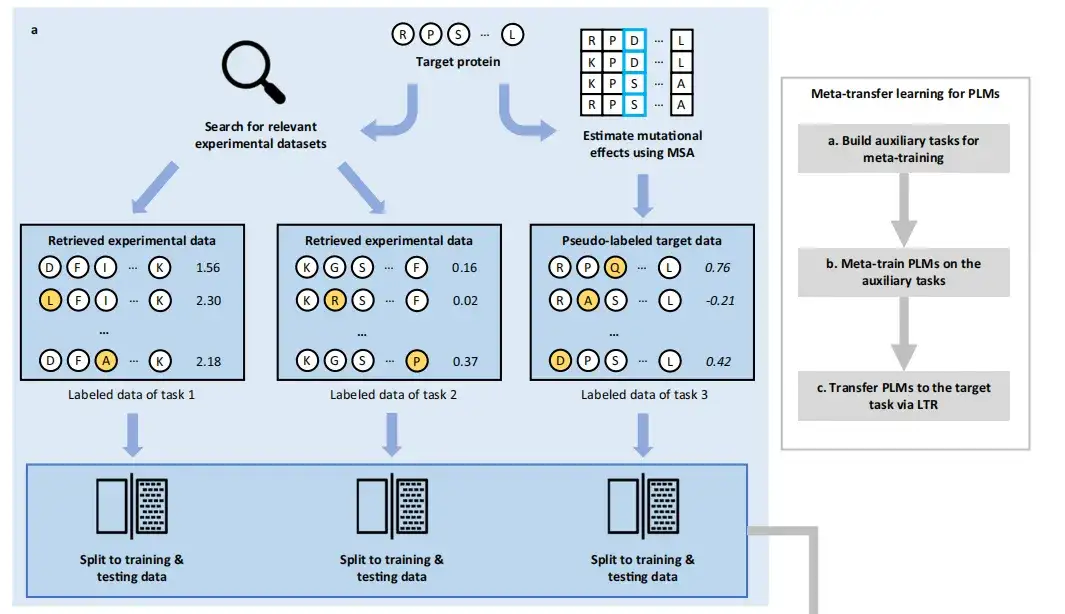
で、メタ学習は、複数の学習タスクからの経験を蓄積し、わずかなトレーニング例と反復のみを使用して、新しいタスクに迅速に適応できるモデルをトレーニングすることを目的としています。。したがって、この研究では、最初に PLM を使用して、標的タンパク質 (ターゲットタンパク質) の野生型配列または構造、およびデータベース内の配列または構造を埋め込みベクターにコード化しました。
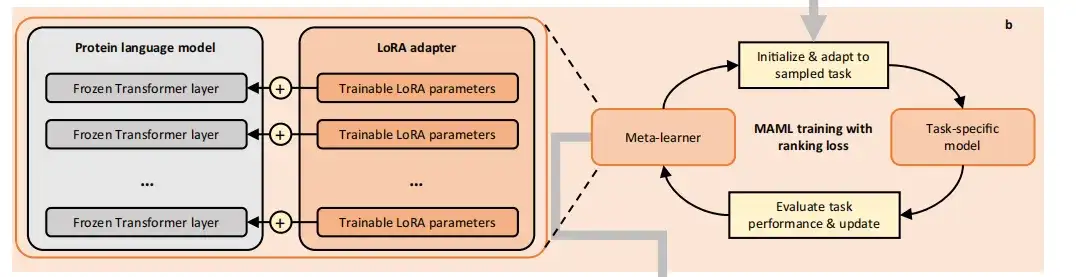
また、この研究では、モデルに依存しないメタ学習 (MAML) と呼ばれる勾配ベースのメタ学習手法が使用されました。構築されたタスクに関して PLM をメタトレーニングします。 MAML は最適な初期モデル パラメーターを見つけることができ、それらに対する小さな変更でもターゲット タスクに大幅な改善をもたらすことができます。各反復サイクルで、メタトレーニング プロセスには 2 つのレベルの最適化が含まれ、最終的に PLM を初期化されたメタ学習器に変換します。
内部最適化では、研究では現在のメタ学習器の初期化を使用して一時的な基本学習器を形成し、その後タスクのトレーニング データをサンプリングすることでタスク固有のモデルに更新されます。外部最適化では、この研究では、タスク固有のモデルのテスト損失をそのタスクで使用して、メタ学習者を最適化します。
トレーニング データが少なすぎることによる致命的な過剰適合を避けるために、FSFP は、低ランク適応 (LoRA) を使用して、トレーニング可能なランク分解行列を PLM に注入します。ここでは、元の事前トレーニング済みパラメーターが凍結され、すべてのモデルの更新が少数のトレーニング可能なパラメーターに制限されます。
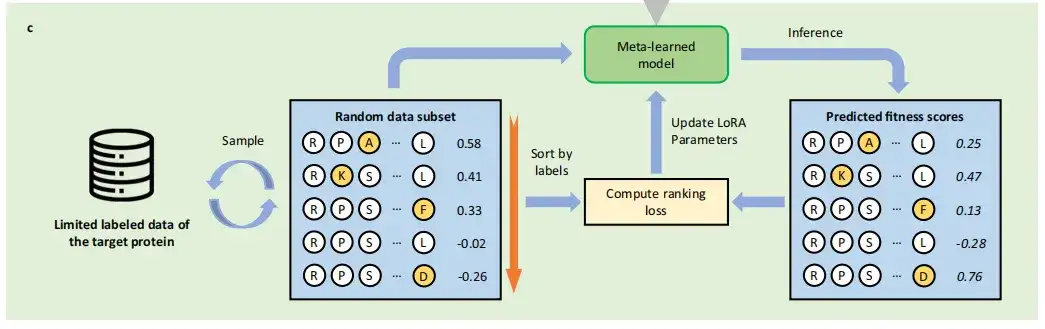
メタトレーニング後、この研究では LoRA パラメーターに基づいて初期化を取得し、最終的にメタトレーニングされた PLM をターゲットの小さなサンプル学習タスクに転送します。つまり、限られたラベル付きデータを使用して、ターゲットタンパク質の変異の影響を予測する方法を学習します。タンパク質の変異予測のための従来の教師あり学習手法とは異なり、FSFP はこれをシーケンス問題として扱い、LTR テクノロジーを利用します。
具体的には、FSFP は ListMLE 損失を計算することによって、突然変異の適合性をランク付けすることを学習します。各反復において、調査では、サンプリングされたデータの 1 つ以上のサブセットの予測がグランド トゥルースの配置に近づくようにモデルをトレーニングします。これらのトレーニング スキームは、ターゲット トレーニング データを使用した転移学習フェーズと補助タスク トレーニング データを使用したメタトレーニング フェーズの両方の内部最適化に適用されます。
87 個のハイスループット変異データセットに基づく ProteinGym のベンチマーク テスト
メタ学習に必要な学習タスクを構築するには、この方法では、まず既存のラベル付き変異データセットを取得し、現在最大の公開 DMS データセットである ProteinGym からターゲットタンパク質に最も近いタンパク質の最初の 2 つの変異データセットを取得し、MSA ベースの GEMME を使用して変異情報をスコア付けします。ターゲットタンパク質のデータを取得して、3 番目のタスクのデータセットを構築します。これらのデータセットは、標的タンパク質に対する変異の影響を予測するのに役立つ可能性があります。これらのタスクのラベル付きデータは、トレーニング データとテスト データにランダムに分割されます。
モデルのパフォーマンスを評価するには、この研究では、ベンチマーク データ セットとしてタンパク質変異データ セット (ProteinGym) を選択しました。データセットには、87 回の DMS シーケンス実験から得られた合計約 150 万個のミスセンス バリアントが含まれています。 ESM-1v の最大入力長は 1,024 であるため、この研究では 1,024 アミノ酸を超えるタンパク質を切り詰め、対応するデータセット内のそれらの変異のほとんどが世代間隔内に発生することを確認しました。
その直後、研究では最初のトレーニング セットとして 20 個の単一点変異をランダムに選択し、次に 20 個の単一点変異を追加してトレーニング セットのサイズを 40 に拡張し、以下同様に 60、80、および 100 のトレーニング セットを構築しました。 5回のランダムなデータ分割プロセスの後、この調査では、特定のトレーニング スケールのさまざまなパーティションでモデルのパフォーマンスを平均化できます。
FSFP は 3 つの基本モデルに適用されており、小規模なサンプルの学習タスクにおいて大きな利点があります。
理論的には、FSFP は勾配降下最適化に基づいたあらゆるタンパク質言語モデルに適用できます。その普遍性を確かめるために、この研究では、トレーニング用の基本モデルとして 3 つの代表的な PLM (ESM-1v、ESM-2、SaPro-t) を選択し、評価にはすべて 650M バージョンを選択しました。
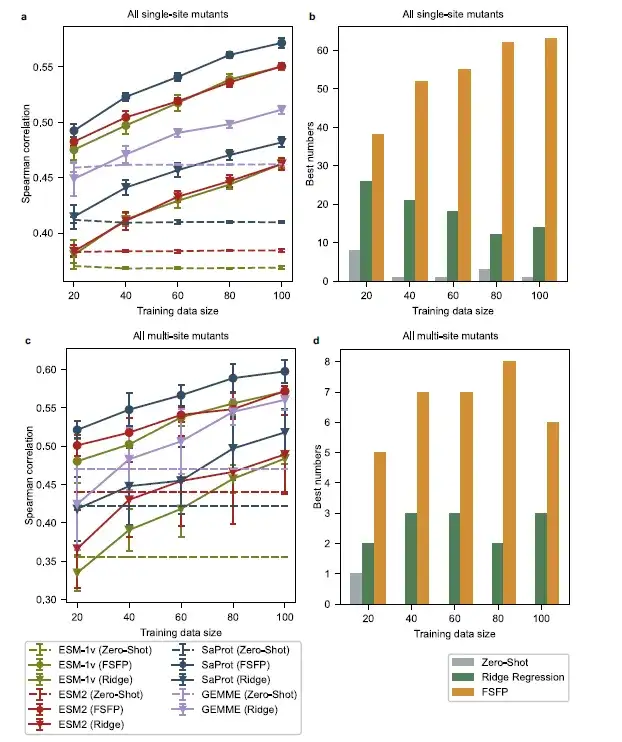
平均的なパフォーマンスで言えば、FSFP によってトレーニングされた PLM は、すべてのトレーニング データ スケールで他のベースラインよりも一貫して優れたパフォーマンスを発揮します。その中で、SaProt (FSFP) が最も優れたパフォーマンスを示しましたが、ESM-1v (FSFP) と ESM-2 (FSFP) も同様に優れたパフォーマンスを示しました。さらに、FSFP でトレーニングされた PLM は、ProteinGym のほとんどのデータセットで最高のスピアマン相関を達成しました。ゼロショット予測と比較して、FSFP は、わずか 20 個のトレーニング例を使用して単一変異体に対するスピアマン相関を改善することにより、単一変異体に対する PLM のパフォーマンスを 0.1 近く向上させます。また、複数変異になると、この差はさらに大きくなります。これらの改善はトレーニング データセットが増加するにつれて増加しており、これはこの研究のアブレーション実験の結果と一致しています。
すべてのトレーニング サンプルにおいて、FSFP を使用したモデルは、GEMME およびその強化版のリッジ回帰よりも大幅な改善を達成しました。これは、FSFP が GEMME の複数の配列アライメントの知識を PLM に伝えるだけでなく、マルチタスク学習を通じてターゲットのトレーニング データからの教師付き情報とうまく組み合わせることができることを示しています。これにより、小規模な学習タスクにおける FSFP の利点が改めて確認されました。
外挿パフォーマンス評価、FSFP トレーニング PLM のスピアマン相関評価の方が優れています
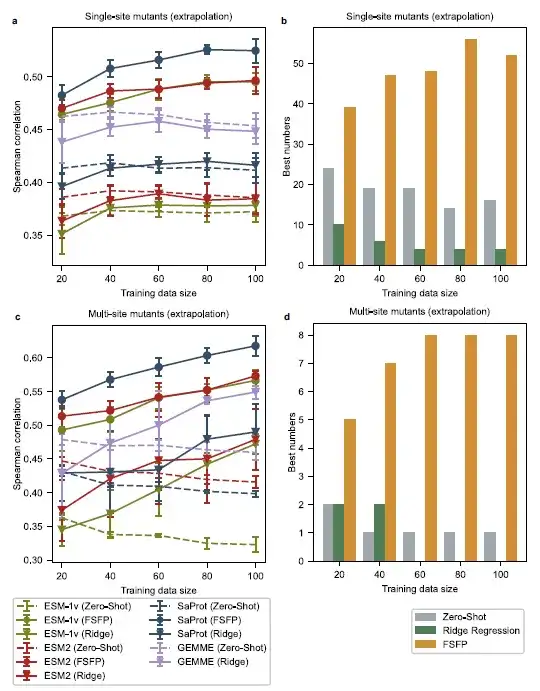
研究者は、変異部位がトレーニング例とは異なる単一点変異体を各元のテスト セットからすべて選択し、その結果、トレーニング例とは異なる単一点変異体のテスト セットが得られます。次に研究者らは、個々の突然変異がトレーニング データ内の突然変異と重複しない多点突然変異体を選択したため、別の困難なテスト セットが得られました。この設定では、ベース モデルのゼロショット パフォーマンスがトレーニング セットのサイズによって大きく異なることがわかりました。
異なる位置での単一点突然変異の場合、リッジ回帰によって強化されたモデルは、100 個のトレーニング例があっても基本モデルよりも優れたパフォーマンスを発揮しません。多点突然変異の場合、トレーニング サイズが 60 未満の場合、リッジ回帰法は GEMME および ESM-2 のパフォーマンスを効果的に向上させることができません。対照的に、FSFP を使用してトレーニングされた PLM は、すべてのトレーニング スケールですべての基本モデルと比較して、スピアマン相関スコアが高くなります。また、ほとんどのデータセットで最高のパフォーマンスを発揮するモデルは、FSFP でトレーニングされたモデルです。
4 つのタンパク質の包括的な比較、FSFP は小規模なデータセットのトレーニングで大きな利点をもたらします
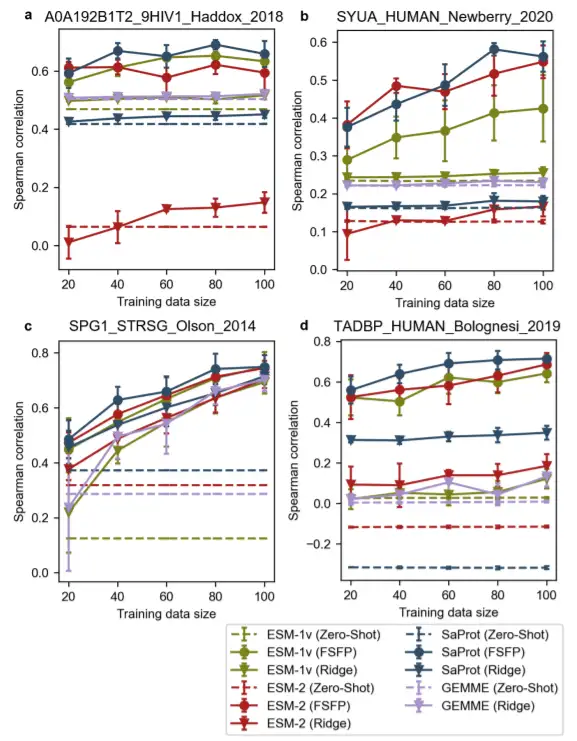
FSFP の適用性と一般化をさらに証明するために、この研究では、HIV 由来のエンベロープタンパク質 Env、ヒト α-シヌクレイン、プロテイン G (GB1)、ヒト TAR DNA 結合タンパク質 43 (TDP-43) の 4 つのタンパク質の異なる方法間の比較結果も示しています。これらの少数のケースでは、1 つ以上の教師なしモデルのパフォーマンスが低下しました。
TDP-43 の場合、すべてのゼロサンプル予測のスピアマン相関がゼロに近いことは注目に値します。 GB1 を除いて、リッジ回帰によって強化されたほとんどのモデルも、大規模なトレーニング データ セットではパフォーマンスが大幅に向上しません。対照的に、事前トレーニングされたモデルは、FSFP を使用して小さなデータセットでトレーニングすると、かなりの利益を達成できます。
FSFP を使用して Phi29 DNA ポリメラーゼを設計すると、陽性率が増加しました 25%
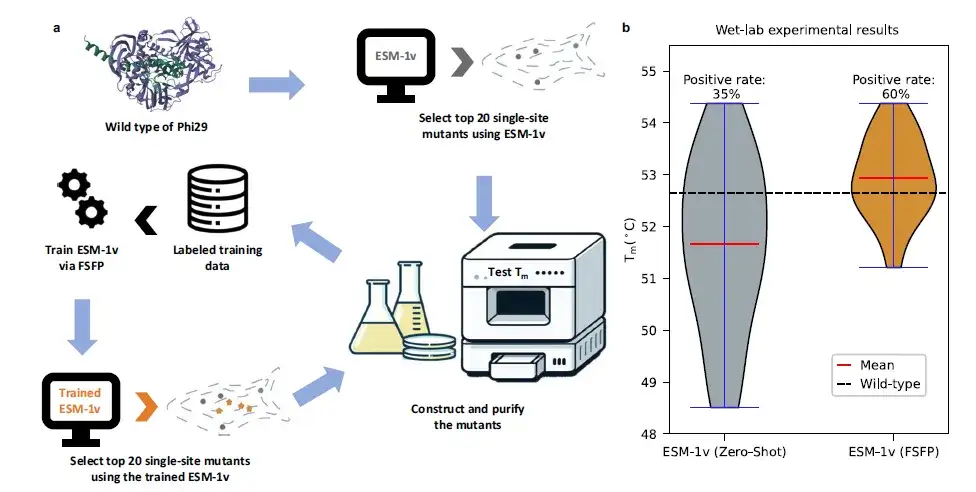
この研究では、タンパク質 Phi29 の修飾の特定のケースも調査しました。湿式実験検証を実施した。この研究では、限られたウェット実験データに基づいて、FSFP を使用して ESM-1v をトレーニングし、それを使用して新しい単一点変異体を見つけ、実験的検証を実施しました。 ESM-1vの最初の20件の予測結果をFSFPトレーニング前後で比較すると、平均Tm値が1℃以上増加し、陽性率は25%増加しました。
具体的には、ESM-1v (FSFP) によって発見された最良の変異体 (つまり、最も高い Tm 値を持つ変異体) も ESM-1v (ゼロショット) によって推奨されます。ただし、ESM-1v (FSFP) によって予測された陽性変異体のうち 9 つはトレーニング データには現れず、FSFP により PLM がより多くのタンパク質変異体を識別できることが示されました。これらの結果は、タンパク質工学設計とテストの反復サイクルを加速する FSFP の可能性を裏付けています。それにより、機能的特徴が強化されたタンパク質の開発に役立ちます。
AI for Bioengineeringの代表格、強力なアライアンスが時代の最前線に立つ
AI と科学研究が緊密に統合されている今日、私たちは歴史的なチャンスの前に立っています。ホン・リャン教授は、中国のバイオ医薬品産業は強い力を持っているが、国際産業チェーンにおける利益の割合にはまだ改善の余地があると考えている。 AI を通じて、私たちは「車線変更と追い越し」の機会を手に入れ、人工知能の力を直接利用して産業の発展を促進します。このコンセプトに基づいて、Hong Liang 教授は研究者の Tan Pan 氏と協力して、バイオエンジニアリングのための AI 分野での終わりのない探求を開始しました。
Tan Pan 博士は、分子生物物理学、人工知能機能タンパク質設計、薬物分子設計に重点を置いています。Nature Communications、PRL、Journal of Cheminformatics、PCCP およびその他のジャーナルに 15 件の SCI 論文を発表。人工知能を利用したさまざまなタンパク質の設計および変更アルゴリズムが開発されています。ホン・リャン教授の専門技術とタン・パン博士のAIアルゴリズムを統合し、両者の共同研究は繰り返しの成果を上げてきた。
長年にわたり、両当事者はタンパク質工学の分野における汎用人工知能に関する革新的な研究に焦点を当て、タンパク質工学用汎用人工知能のプロシリーズの開発に成功してきました。 ChatGPT が人間の言語を理解する方法と同様に、プロ シリーズは大規模なモデルを通じて天然タンパク質のアミノ酸配列を理解し、優れたパフォーマンスを備えたタンパク質製品を設計します。その中には、産業用途におけるマイルストーンとなる製品も 2 つあります。
* 極めて耐アルカリ性の高い単一ドメイン抗体:Kinsey Pharmaceuticals と共同開発した世界初の大型モデル設計のタンパク質製品は、5,000 リットルの工業生産を達成し、生体高分子の精製のための新しいソリューションを提供します。
※糖転移酵素:漢海新酵素と協力して、膵炎スクリーニングの核心物質であるeps-g7製造用酵素を開発し、長期にわたる海外独占を打ち破り、コストを大幅に削減しました。
これら 2 つの事例は、大規模なモデル設計とスケールアップ生産の成功により、工業化段階に入った世界で最初と 2 番目のタンパク質製品を示しています。ホン・リャン教授は、AIタンパク質設計の分野での深い蓄積に基づいて、2021年にShanghai Tianyu Technology Co., Ltd.を設立しました。わずか3年で、同社は複数のタンパク質設計プロジェクトを完了しただけでなく、Yaotu CapitalやJinshajiang Capitalなどの著名な機関からPre-Aラウンドで数千万元の資金調達も受けた。
現在、同社のサービスは革新的な医薬品、体外診断薬、合成生物学などの分野をカバーしており、より多くの科学研究機関や企業との協力を積極的に模索しており、この分野で国内、さらには世界的なベンチマークを設定することに尽力している。タンパク質工学。
競争の激しいタンパク質工学分野において、Hong Liang 教授のビジョンは明確です。私たちは国のリーダーになるだけでなく、世界のリーダーにならなければなりません。今後の科学研究の旅において、ホン・リャン教授と彼のチームは、世界の科学研究機関や企業との緊密な協力を拡大し、タンパク質設計の無限の可能性を常に探求し、この分野での技術的ブレークスルーと応用革新の達成に努めることに尽力する。国内でのベンチマークを設定し、国際的に卓越性を実証しています。
最後に、興味のある友人は QR コードをスキャンして参加できる、オンラインの学術共有アクティビティをお勧めします。









