Command Palette
Search for a command to run...
ユニバーサルロボットのマイルストーン! MITは、異種データソースの問題を解決し、マルチタスクロボットの柔軟な実行を実現するために、ポリシー結合フレームワークPoCoを提案しました。

18台の人型ロボットが「挨拶」を務め、来場者に一斉に手を振る様子は、今年のロボットの急速な発展を直感的に感じさせる、2024年世界人工知能会議での衝撃的な光景だった。

1954 年に、世界初のプログラム可能なロボット「Unimet」がゼネラル モーターズの組立ラインで正式に稼働し、半世紀以上にわたり、ロボットは扱いにくい産業の巨人から、よりスマートで柔軟な人間のアシスタントへと徐々に成長してきました。中でも、人工知能技術、特に自然言語処理とコンピュータービジョンの画期的な進歩は、巨大な計算能力と大量のデータを使用してロボット開発の高速化の道を切り開きました。動作クローン作成などの単純なアルゴリズムを通じて一般的なロボット戦略をトレーニングします。私たちは、未来のロボットの無限の可能性を徐々に解き放っています。

ただし、現在のロボット学習パイプラインのほとんどは、特定のタスク用にトレーニングされています。そのため、新しい状況や異なるタスクを実行するときに無能になります。さらに、ロボット トレーニング データは主にシミュレーション、人体のデモンストレーション、ロボットの遠隔操作シナリオから得られます。さまざまなデータ ソース間には大きな異質性があります。機械学習モデルが非常に多くのソースからのデータを統合することも難しく、ロボットの一般的な戦略をトレーニングすることは常に大きな問題となっています。
これに対して、MITの研究者らは、ロボットの政策構成フレームワークPoCo(Policy Composition)を提案した。このフレームワークは、拡散モデルの確率的合成を使用して、さまざまな分野やモダリティからのデータを組み合わせ、ロボットの問題を解決できる複雑なロボット戦略の組み合わせを構築するためのタスクレベル、行動レベル、およびドメインレベルの戦略合成手法を開発します。ツールを使用するタスクでのデータの使用。異質性とタスクの多様性の問題。関連する研究は、「PoCo: 異種ロボット学習からの、および異種ロボット学習のためのポリシー構成」というタイトルで arXiv に公開されています。
研究のハイライト:
* 再トレーニングの必要がなく、PoCo フレームワークはさまざまな分野のデータ トレーニング戦略を柔軟に組み合わせることができます
* PoCo は、シミュレーションと実際のツール使用タスクの両方で優れたパフォーマンスを実現します。単一ドメインでトレーニングされたメソッドと比較して、PoCo はさまざまな環境でのタスクに対して高度な汎化能力を示します。

用紙のアドレス:
https://arxiv.org/abs/2402.02511
オープンソース プロジェクト「awesome-ai4s」は、100 を超える AI4S 論文の解釈をまとめ、大規模なデータ セットとツールを提供します。
https://github.com/hyperai/awesome-ai4s
人間と機械のデータ、実際のデータとシミュレートされたデータ、その他の分野をカバーする 3 つの主要なデータセット ソース
この研究に関係するデータセットは主に人間のデモンストレーションビデオデータ、実際のロボットデータ、シミュレーションデータから得られます。
人体デモンストレーションビデオデータセット
人間によるデモンストレーションのビデオは、現場の未調整のカメラから収集でき、合計で最大 200 の軌跡が収集されます。

リアルロボットデータセット
設置されたリスト カメラとオーバーヘッド カメラを通じてシーンのローカルおよびグローバル ビューが取得され、GelSight Svelte Hand を使用してツールと物体が 50 ~ 100 度の軌道で接触しているときのツールの姿勢、ツールの形状、および触覚情報が収集されます。タスクごとにデモンストレーションが収集されます。
シミュレーション シミュレーション データセット
シミュレーション データ セットは Fleet-Tools に従っており、キーポイント軌道の最適化を通じて専門家のデモンストレーションが生成され、合計約 50,000 のシミュレーション データ ポイントが収集されます。その後のトレーニング プロセス中に、研究者は点群データとアクション データの両方でデータ拡張を実行し、テスト用に固定シミュレーション シナリオを保存しました。
さらに、研究者らは、モデルの堅牢性を向上させるために、深度画像とマスクから 512 個のツールと 512 個のオブジェクト点群に点ごとのノイズやランダム ドロップなどを追加しました。
確率分布の積形式による戦略の組み合わせ
戦略の組み合わせでは、研究者には 2 つの確率分布でエンコードされた軌跡情報 pDM(⋅∣c,T) と pD'M'(⋅∣c',T') が与えられ、これらを積分布のサンプリングと直接組み合わせます。 2 つの確率分布からの情報を推論します。
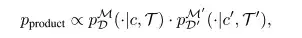
で、製品 両方の確率分布を満たすすべての軌跡で高い尤度を示します。両方のディストリビューションからの情報を効率的にエンコードできます。
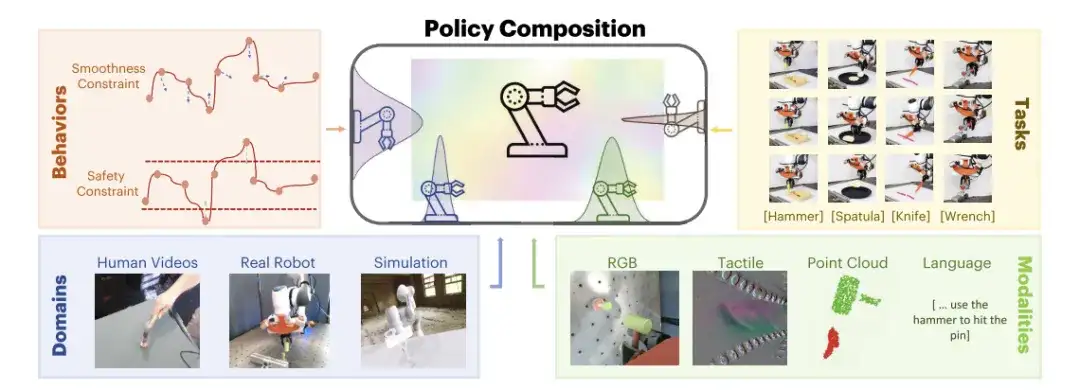
研究者らが提唱したPoCo、行動、タスク、チャネル、ドメインにわたる情報を統合し、再トレーニングを必要とせず、予測を行う際に情報がモジュール式に組み合わされるため、複数のドメインからの情報を活用してツールを使用するタスクを一般化できます。
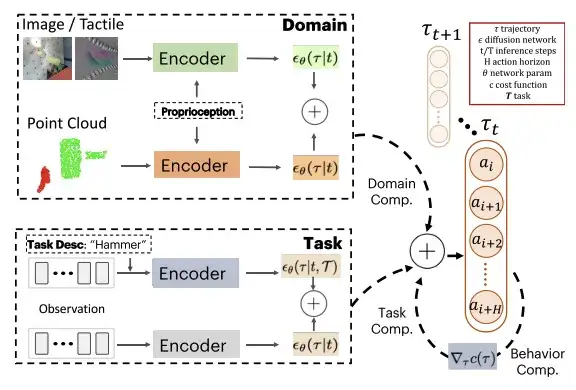
各モデルの拡散出力は同じ空間にある、つまりアクションの次元とアクションの時間領域が同じであると仮定されます。テスト時には、PoCo が勾配予測と組み合わされます。この方法は、画像、点群、触覚画像などの異なるモーダル データを使用して学習された戦略を組み合わせるなど、さまざまな領域での戦略の組み合わせに適用できます。また、さまざまなタスクの戦略を組み合わせたり、動作の組み合わせを通じて目的の動作に対する追加のコスト関数を提供したりするために使用することもできます。
この点に関して、研究者らは、タスクレベルの構成、行動レベルの構成、およびドメインレベルの構成の 3 つの例を提供し、PoCo がどのようにポリシーのパフォーマンスを向上させるかを説明しました。
タスクレベルの構成 タスクレベルの構成
タスクレベルの組み合わせにより、タスク T を完了する軌道に追加の重みが追加されます。これにより、合成された軌道の最終的な品質が向上し、タスクごとに個別のトレーニングを行う必要がなくなります。むしろ、複数のタスクの目標を達成できる一般的なポリシーをトレーニングします。
行動レベルの構成 行動レベルの構成
この組み合わせにより、タスクの分散とコスト目標に関する情報を組み合わせることができます。合成された軌道がミッションを完了し、指定されたコスト目標を最適化することを確認します。
ドメインレベルの構成 ドメインレベルの構成
この組み合わせにより、さまざまなセンサー モダリティやドメインから取得した情報を活用できます。別々の分野で収集されたデータを補完するのに非常に役立ちます。たとえば、実際のロボットのデータ収集コストは高いが精度が高く、シミュレーション デモンストレーション データの収集コストは低いが精度が低い場合、同じフィールド内の異なるモードのデータに対して特徴量連結を実行して処理を簡素化できます。 。
3 つの主要な戦略の組み合わせを評価するためのビジュアル ツールの使用タスク

研究者らは、トレーニング中に時間的 U-Net 構造とノイズ除去拡散確率モデル (DDPM) を使用して 100 ステップのトレーニングを実行し、テスト中にはノイズ除去拡散暗黙的モデル (DDIM) を使用して 32 ステップのテストを実行しました。異なるドメイン D とタスク T の間で異なる拡散モデルを組み合わせるために、研究者らはすべてのモデルに同じアクション空間を使用し、ロボットのアクション境界で固定正規化を実行しました。
研究者らは、ロボットによる一般的なツール(レンチ、ハンマー、シャベル、レンチ)の使用を通じて、提案された PoCo を評価しました。たとえば、ピンが打ち込まれたとき、ハンマーで叩くタスクなど、特定のしきい値に達したときにタスクが成功したと判断されました。成功したとみなされました。
行動レベルの組み合わせにより、望ましい行動目標を向上させることができます
研究者らはテスト時の推論を使用して、滑らかさやワークスペースの制約などの動作を組み合わせ、合成の重みは γc=0.1 に固定されました。
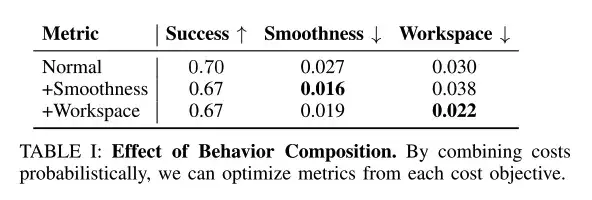
上の表に示すように、テスト時の動作レベルの組み合わせにより、滑らかさやワークスペースの制約など、望ましい動作目標を向上させることができます。
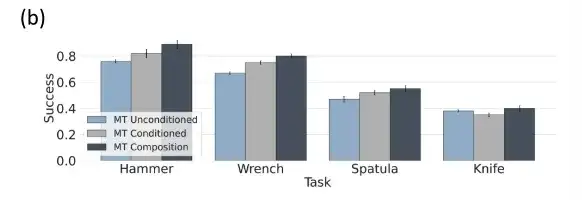
マルチタスクのポリシー評価ではタスクレベルの組み合わせが最適です
タスクの重み α=0 の場合、タスク レベルの組み合わせポリシーは、無条件のマルチタスク ポリシー (無条件のマルチタスク ポリシー) にマッピングされます。 α=1 の場合、0 < α < 1 の場合、標準のタスク条件付きポリシー (タスク条件付きポリシー) にマッピングされます。 、研究者はタスク条件とタスク無条件ポリシーの間を補間します。 α > 1 の場合、よりタスクの状況に応じた軌跡が得られます。
上の図によると、無条件およびタスク固有の条件付きマルチタスク ツール使用普及戦略と比較して、条件付きおよび無条件マルチタスク ツール使用戦略を組み合わせたタスクの方が優れています。
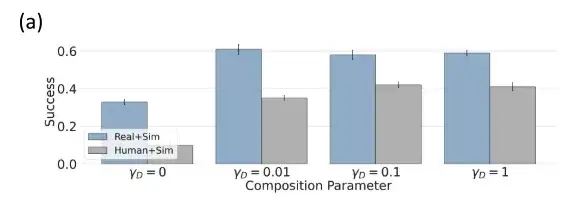
人間 + シミュレートされたデータ、ドメインレベルの組み合わせのパフォーマンスが向上
研究者らは、シミュレートされたデータセット θsim、人間のデータセット θhuman、およびロボットのデータセット θrobot を使用して個々のポリシー モデルをトレーニングし、シミュレートされたシミュレーション設定でドメインレベルの組み合わせを評価しました。
θsim にはトレーニング/テスト領域のギャップがないため、パフォーマンスが良く、成功率は 92% に達します。人間データなどの分野では、研究者は、よりパフォーマンスの高いポリシー θsim と組み合わせることにより、パフォーマンスを大幅に向上させました。
戦略の組み合わせのパフォーマンスは個々のコンポーネントのパフォーマンスを上回り、より汎用性が高くなります。
研究者は、ロボット ツールの使用タスクに PoCo を使用して、さまざまな分野やタスクからのデータを結合し、一般化機能を向上させます。 4 つのタスクは次のとおりです。レンチを使用してネジを回し、ハンマーを使用して釘を打ち、ヘラを使用してパンケーキを型から持ち上げ、ナイフを使用して粘土を切ります。

シミュレートされたデータ、人間のデータ、および現実世界のデータでトレーニングされたポリシーを組み合わせることで、複数のディストラクター (行 1)、さまざまなオブジェクトとツールのポーズ (行 2)、および新しいオブジェクトとツールのインスタンス (行 3) にわたってパフォーマンスを達成できます。間
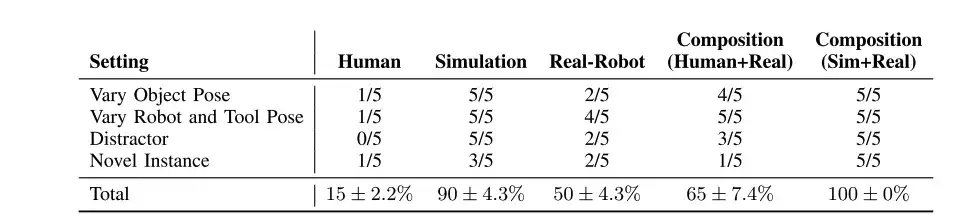
上の表に示すように、人間のデータによって訓練された戦略と実際のロボット (Real-Robot) によって訓練された戦略は、さまざまなシナリオで (シミュレーションと比較して) パフォーマンスが低くなりますが、しかし、それらの組み合わせ (人間 + 現実) は、個々のコンポーネントを超える可能性があります。
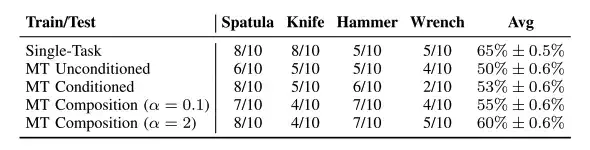
研究者らは現実世界を通じて、4 つの異なるツール使用タスクにおけるロボットの戦略的パフォーマンスを評価し、ツール使用タスクでは次のことが判明しました。タスク組み合わせ戦略のパフォーマンスがさらに向上しました。上の表に示すように、マルチタスク戦略は、Tspatula と Thammer によって条件付けされた特定のタスクとほぼ同じパフォーマンスを示し、いずれも細かいアクションで一定の安定性を示します。さらに、組み合わせたハイパーパラメータは、効果的かつ安定した範囲内に維持する必要があります。
普遍性の最良の条件、人型ロボットの台頭
汎用ロボットは過去 2 年間で精力的に開発されてきましたが、興味深い現象として、業界は人型の汎用ロボットの開発促進にさらに力を入れているようです。なぜ万能ロボットは人型でなければならないのでしょうか?Wuyuan Capital の常務取締役、Chen Zhe 氏は、「人間の生活環境におけるさまざまなインタラクション シナリオに適応できるのは人間型ロボットだけだからです。」ロボットは人間の作業を支援し、その人間型の外観を利用して人間の学習を模倣したいと考えているため、これは明らかに問題です。最高。
テスラは業界のベンチマークとして、早ければ2022年9月にも万能人型ロボット「オプティマス」をリリースした。当初は安定して歩くことすらできなかったものの、人間ができる器用さを満たす完全な人型ロボットのプロトタイプを完成させた。この研究では、テスラのソフトウェアとハードウェア技術を継続的に反復することにより、オプティマスにはさらに多くの期待される機能が搭載されることになり、実際にその通りであることが判明しました。

2024 年の世界人工知能会議で、テスラは人型ロボット オプティマスの最新の研究の進歩を皆に披露しました。直立歩行速度が 30% 増加し、その 10 本の指は知覚と触覚も進化しました。壊れやすい卵を簡単につかむことができます。重い箱もスムーズに移動できます。オプティマスはテスラ工場でビジュアルニューラルネットワークとFSDチップを使用してバッテリー仕分け訓練のために人間の操作を模倣するなどの実用化を試みていることがわかっており、来年には1,000台以上の人型ロボットがテスラ工場で人間を助けることが期待されている。 . 生産タスク。
同様に、2015年に設立された業界大手の総合ロボット企業、上海フーリエ智能科技有限公司も人型ロボットGR-1を会場に持ち込んだ。 GR-1は2023年の発売以来、量産・納入をリードし、環境認識、シミュレーションモデル、モーション制御の最適化において高度なアップグレードを実現してきました。
さらに、今年 3 月、NVIDIA は年次 GTC 開発者カンファレンスで GR00T と呼ばれるヒューマノイド ロボット プロジェクトを立ち上げました。人間の行動を観察して自然言語を理解し、動作を模倣することで、ロボットは調整、柔軟性、その他のナビゲーション スキルを迅速に学習できます。適応し、現実世界と対話します。
科学技術の絶え間ない進歩に伴い、人型ロボットが人間と機械、現実と未来を繋ぎ、よりスマートでより良い社会へと私たちを導く架け橋となる可能性があると私たちは信じています。
参考文献:
https://m.163.com/dy/article/J69LAFDR0512MLBG.html
https://36kr.com/p/1987021834257154
https://hub.baai.ac.cn/view/211








