Command Palette
Search for a command to run...
独占中国語字幕! LeCun の学生 Alfredo の春期 AI コースが開始されました。CVPR'24 リモート センシング データ セットのダウンロードが開始されました。

最近、ニューヨーク大学のコンピューターサイエンス助教授でヤン・ルカンの学生でもあるアルフレド・カンツィアーニ氏は、離散確率と単純ベイズ、パーセプトロンとロジスティック回帰、最適化、統計、ニューラル自然言語などのトピックをカバーする春の「AIコース」を発表した。処理、ニューラル ネットワーク分類、リカレント ニューラル ネットワーク、畳み込みニューラル ネットワークなど。
今週、HyperAI はステーション B でコースを 24 時間年中無休でライブ放送します。一緒に学びましょう~
閲覧アドレス:
http://live.bilibili.com/26483094
6 月 24 日から 6 月 28 日までの hyper.ai 公式 Web サイト更新の概要:
- 高品質の公開データセット: 10
- 高品質なチュートリアル セレクション: 3
- コミュニティ記事の選択: 4 件の記事
- 人気のある百科事典のエントリ: 5
- 7月締切:4日
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. GeoChat 命令リモートセンシングマルチモーダル命令追跡データセット
このデータセットには約 318,000 の命令が含まれており、マルチモーダル命令の適応をリモート センシングの分野に拡張して、マルチタスクの会話アシスタントを訓練することを目的としています。関連する論文結果が CVPR 2024 に受理されました。
直接使用します:https://go.hyper.ai/CXu0K
2. RRSIS-D 大規模リモートセンシング画像セグメンテーションデータセット
このデータセットには、さまざまな空間解像度とオブジェクトの方向をカバーする 17,402 個の画像記述マスクのトリプルが含まれています。関連する論文結果が CVPR 2024 に受理されました。
直接使用します:https://go.hyper.ai/1VRQG
3. Earth Parser Dataset リモートセンシングマッピングデータセット
このデータセットは、照合されていない大規模な航空 LiDAR スキャンに関する分析手法をトレーニングおよび評価するために使用されます。データセットには、7.7 平方キロメートル以上のエリアをカバーする 7 つのシーンが含まれており、合計 9,800 万の 3D ポイントが含まれています。関連する論文結果が CVPR 2024 に受理されました。
直接使用します:https://go.hyper.ai/3pFjm
4. Harvard-GF3300 網膜神経疾患 (緑内障) データセット
このデータセットは、2D および 3D 画像データを含む 3,300 人の被験者の網膜神経疾患 (緑内障) データセットです。このデータセットには、3 つの主要な人種グループ (白人、黒人、アジア人) からの同数の被験者が含まれており、混乱を招く可能性のあるデータの不均衡の問題が回避されます。公平な学習の問題。
直接使用します:https://go.hyper.ai/vIhu6
このデータセットには、さまざまな歯科矯正用断層撮影 (OPG) X 線画像、70 個の高品質サンプルが含まれています。注釈を提供することにより、このデータセットを使用して、歯の種類の分類、異常検出などの歯科画像分析タスク用の機械学習モデルをトレーニングおよびテストできます。
直接使用します:https://go.hyper.ai/vK9zz
このデータセットには、下肢、上肢、腰椎、股関節、膝などを含むすべての解剖学的身体領域をカバーする骨折および非骨折の X 線画像が含まれています。データセットはトレーニング、テスト、検証のフォルダーに分割されており、合計 10,580 個の放射線画像 (X 線) データが含まれています。
直接使用します:https://go.hyper.ai/Yk1bA
データセットには 10 種類の果物と 26 種類の野菜の画像が含まれており、各カテゴリはトレーニング、テスト、検証セットに分割されており、画像認識タスクに多様なセットを提供します。
直接使用します:https://go.hyper.ai/FdfRK
このデータセットには、さまざまなメディア タイプやジャンルの 15,939 人の人気キャラクターに関する情報が含まれています。各エントリには、キャラクター、メディア ソース、キャラクターが関与するユニークなシーンに関する詳細情報が含まれています。
直接使用します:https://go.hyper.ai/wf1q1
RepLiQA は、17 のトピックまたはドキュメント カテゴリをカバーする「コンテキスト-質問-回答」トリプルを含む評価データセットで、提供されたドキュメント内のコンテキスト情報を検索して使用する大規模言語モデル (LLM) の機能をテストするように設計されています。
直接使用します:https://go.hyper.ai/ZkSYD
10. CS-Eval 大型モデルネットワークセキュリティ評価データセット
このデータ セットは、ネットワーク セキュリティの 11 の主要カテゴリ、42 のサブカテゴリ、および 4,369 の多肢選択式質問、正誤質問、知識抽出質問をカバーしており、知識ベースの実践的な包括的な評価タスクを提供し、ユーザー独自の評価をサポートします。は大規模なモデルであり、実際のネットワーク セキュリティに関する参照とインスピレーションを提供します。
直接使用します:https://go.hyper.ai/ziacf
その他の公開データセットについては、以下をご覧ください。
選択された公開チュートリアル
このチュートリアル デモでは、指定された生物学的画像を科、属、種などによって分類できます。これは、CVPR2024 の最優秀学生論文「BioCLIP: A Vision Foundation Model for the Tree of Life」のモデルの Gradio バージョンです。
オンラインで実行:https://go.hyper.ai/OEWk1
2. 一貫したスタイルの InstantStyle 画像ジェネレーター
InstantStyle は、Xiaohongshu の InstantX チームによって開発されたテキストから画像への生成フレームワークで、コンテンツのテキストによる制御性を維持しながらスタイルの転送を実現します。このチュートリアルでは、すべての人に関連する環境がセットアップされており、ワンクリックでその環境を複製して体験することができます。
オンラインで実行:https://go.hyper.ai/E6GuW
3. 5 秒で高品質の記事を生成し、ワンクリックで Llama 3-中国語-チャット デモを開始します。
このモデルは、Meta-Llama-3-8b-Instruct モデルに基づいて中国語向けに特に微調整された中国語チャット モデルです。オリジナルの Meta-Llama-3-8b-Instruct モデルと比較して、「中国語の質問に対する英語の返答」や中国語と英語の混合問題が大幅に減少しました。コンテナを複製して起動し、生成された API アドレスを直接コピーするだけで、モデル上で推論を実行できます。
オンラインで実行:https://go.hyper.ai/BLHcM
注目のコミュニティ記事
1. 最強の鉄系超電導マグネット誕生!科学者が機械学習に基づいた新たな研究システムを設計、磁場強度が従来の記録を2.7倍上回る
英国と日本の科学者は、機械学習技術を使用して、研究者主導の方法とデータ主導の方法を組み合わせた研究システムを設計し、既知の世界最強の鉄系超電導磁石の作成に成功しました。この記事は、研究の詳細な解釈と共有です。
イベントの詳細を表示:https://go.hyper.ai/RxV9x
2. 北京大学病院副院長 Li Jianping 氏: AI を使用して臨床心筋虚血予測の困難さ、行き詰まり、問題点を解決
北京志源カンファレンスで、北京大学第一病院副院長で心臓血管研究所所長の李建平教授は、冠状動脈性心疾患の診断と臨床におけるAIによる「臨床的心筋虚血の予測方法と困難さ」というテーマについて共有した。心筋虚血の予測およびその他の側面における新たな探求と実践。これは、冠状動脈性心疾患患者の診断と治療に新しいアイデアを提供し、心臓から腎臓まで焦点を広げ、臨床医学においてAIがより大きな価値を発揮できるようになると期待されています。この記事はスピーチの詳細な要約です。
インタビュー全文を見る:https://go.hyper.ai/5X9jM
3. 1億個のパラメータを持つ大規模セルモデルが登場! Nature サブジャーナルに掲載、清華大学チームが scFoundation: 20,000 個の遺伝子の同時モデリングを発表
清華大学の研究チームは、sc-Foundationと呼ばれる大細胞モデルを提案しました。このモデルは、5,000万個の細胞の遺伝子発現データに基づいて学習され、1億個のパラメータを持ち、約2万個の遺伝子を同時に処理できます。基本モデルとして、細胞配列決定の深さの強化、細胞薬物応答予測、細胞摂動予測など、さまざまな生物医学の下流タスクで優れたパフォーマンスの向上が示されています。この記事は、研究の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/v5i5K
4. AI 実践者はどのように科学を行っていますか?清華大学 AIR 周昊: テキスト生成からタンパク質設計までの国境を越えた探索
最近、清華大学知能産業研究所の周昊教授は、コンピューター実務家として、タンパク質設計においてAIが直面する複数の課題を全員と共有し、データ構造、生成アルゴリズム、タンパク質の3つの側面から現状を説明しました。プロテインに関する最新の最先端研究。この記事では、Zhou Hao 教授の詳細な情報をレポートします。
レポート全体を表示します。https://go.hyper.ai/PTyAp
人気のある百科事典の項目を厳選
1. スケーリング定理 スケーリングの法則
2. 相互ランキング融合 RRF
3. 神経放射線場 NeRF
4. 大規模マルチタスク言語理解MMLU
5. コルモゴロフ・アーノルド表現定理
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
ステーションBのライブブロードキャストプレビュー
AIfredo Canziani は、ニューヨーク大学のコンピューター サイエンスの助教授であり、Yann LeCun の学生です。最近、彼は春の「AI コース」ビデオをリリースしました。各章で教えられる知識の内容には、離散確率と単純ベイズ、統計とニューラル ニューラル言語処理などが含まれます。今週、スーパー ニューロ TV がこのコースを 24 時間年中無休で生放送します。
次の表は、編集者が全員に向けて選択したコンテンツのプレビューです↓↓↓
| 日付 | 時間 | コンテンツ |
|---|---|---|
| 7月1日月曜日 | 18:00 | パート 1 ナイーブ ベイズの概要 |
| 7月2日火曜日 | 18:00 | パート 2 単純ベイズ分類 |
| 7月3日水曜日 | 18:00 | パート 3 単純ベイズ パラメーター推定とラプラシアン平滑化 |
| 7月4日(木) | 18:00 | パート 4 バイナリ分類器の評価 |
| 7月5日金曜日 | 18:00 | パート 5 マルチクラス パーセプトロン バイナリおよびマルチクラス ロジスティック回帰 |
| 7月6日土曜日 | 18:00 | パート 6 最適化と勾配上昇 |
| 7月7日日曜日 | 18:00 | アルフレド・カンツィアーニ氏がエネルギーベースの自己教師あり学習について講義 |
スーパー ニューラル TV ステーションは、7 時間 24 日中断のない生放送を放送しており、ワンクリックで AI 分野の「電子マスタード」を収穫できます。
http://live.bilibili.com/26483094
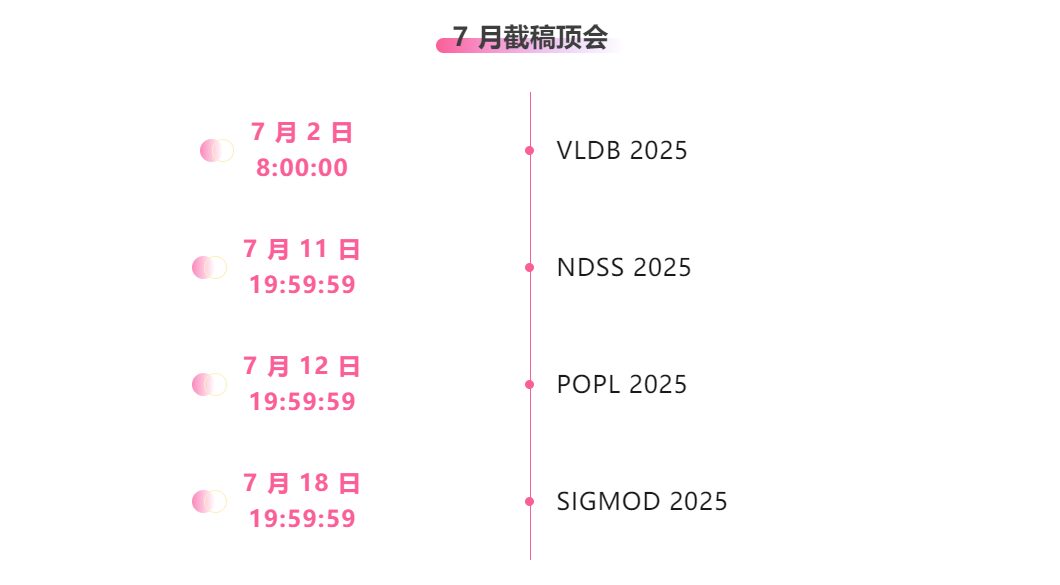
主要な人工知能学会をワンストップで追跡:https://hyper.ai/events
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。 国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
- 1,300 を超える公開データセットに対して国内の高速ダウンロード ノードを提供
- 400 以上の古典的で人気のあるオンライン チュートリアルが含まれています
- 100 件を超える AI4Science 論文のケースを解釈する
- 500 以上の関連用語クエリをサポート
- Apache TVM の初の完全な中国語ドキュメントを中国でホスト
学習の旅を始めるには、公式 Web サイトにアクセスしてください。








