Command Palette
Search for a command to run...
AI 実践者はどのように科学を行っているのでしょうか?清華大学 AIR 周昊: テキスト生成からタンパク質設計までの国境を越えた探索

最近、北京インテリジェントソース会議の「科学のための AI」サブフォーラムで、清華大学知能産業研究所准研究員の周昊氏は、「科学的発見のための生成人工知能」をテーマに講演した。HyperAI Super Neural は、Zhou Hao 教授の詳細な共有を、当初の意図に違反することなく編集し、要約しました。

テキスト生成から分子設計までの国境を越えた探索
この講演で、周昊教授は主に、複雑なシンボルの生成人工知能、顕微鏡サンプル生成が直面する課題、現在の具体的な研究内容の3つの側面について詳しく説明しました。
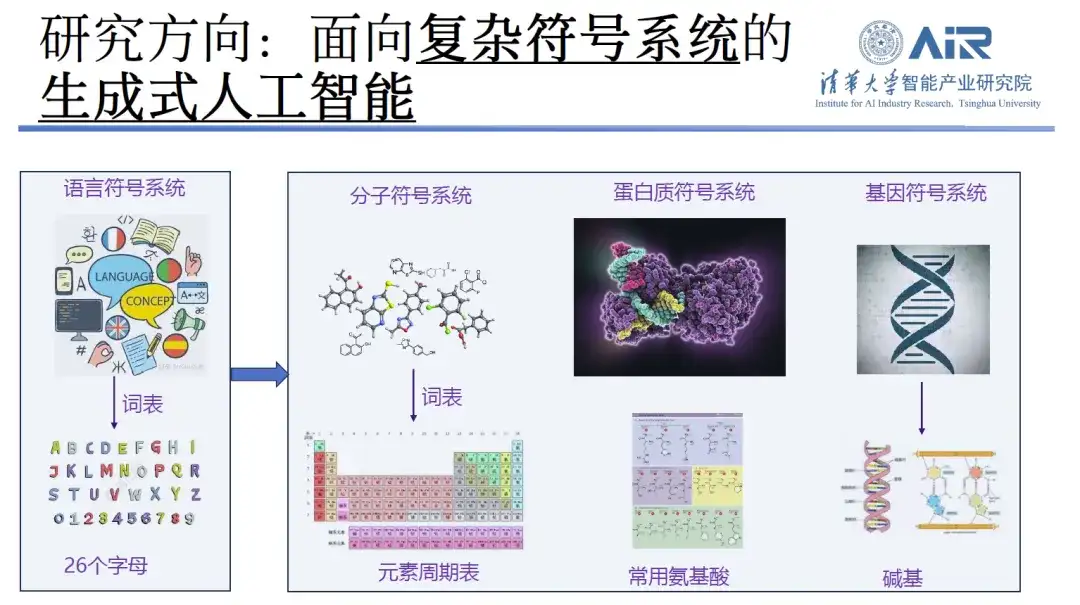
関連する研究の方向性を紹介する際、Zhou Hao 教授は、過去 10 年間、テキスト生成や機械翻訳を含む自然言語処理に焦点を当ててきたと述べました。過去 2 年間で、研究の焦点は、コンテンツ作成から分子生成とタンパク質設計へと徐々に移行してきました。彼の見解では、過去のテキスト処理作業が語彙が 26 文字で構成される複雑な言語記号システムとみなされる場合、現在の作業はこれら 26 文字を元素、アミノ酸、塩基の周期表に拡張することに相当します。その他のより広い領域。これらの技術に関して、彼の研究チームは豊富な経験を蓄積しています。

コンテンツ作成に特化した人工知能から、科学的発見に特化した人工知能まで、両者の間にはどのような関係があるのでしょうか?実際、人工知能はノイズから完全な画像を生成することができ、多くの北米の研究チームがすでに同様の方法をタンパク質設計に使用しています。タンパク質のアミノ酸を空間内にランダムに配置し、0 から 2,000 までの一連の生成設計ステップを経ることで、合理的に見えるアミノ酸配列を設計できます。
この研究に関与するタンパク質の長さには依然として一定の制限がありますが、最近の研究結果はこれらの制限を大幅に拡張し、この技術の大きな可能性を示唆しています。これが、Zhou Hao 教授がこの分野を選択した重要な理由である可能性があります。
AI 実践者が科学研究を行う際に直面する複数の課題
その後、周昊教授は、コンピューターサイエンスやAIの分野の実務家の視点から、科学分野で人工知能(AI for Science)を探求する際に直面する3つの大きな課題を全員に共有しました。
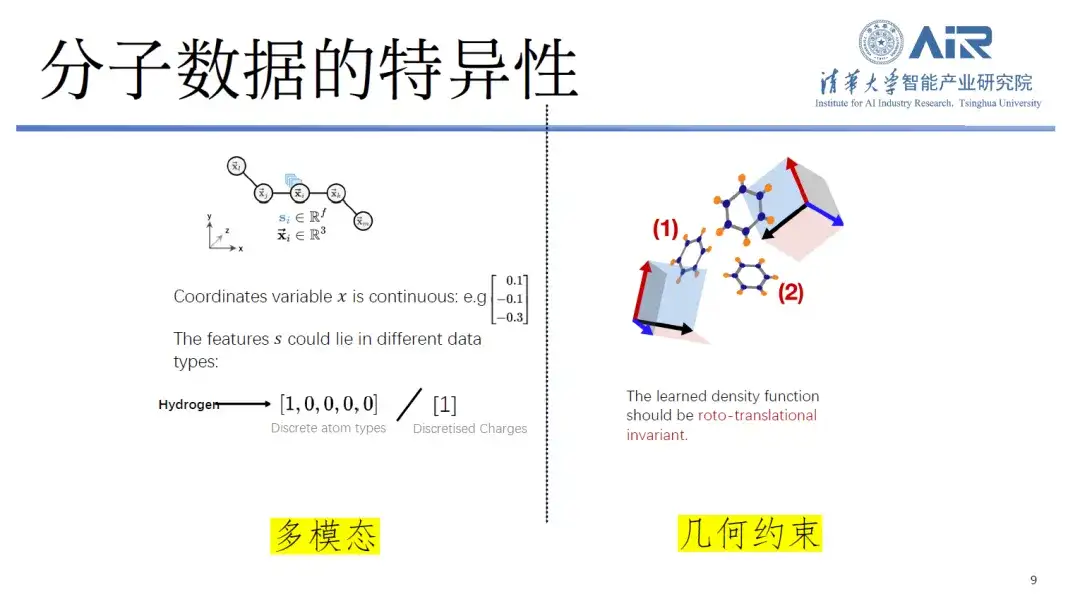
まず、分子データの特異性です。一般に文字や記号は離散的に処理され、画像は0から1までの連続信号となりますが、分子データには離散要素と連続要素の両方が含まれます。
たとえば、分子をコンピュータに保存する場合、研究者は通常、分子を原子座標と原子タイプとして表現しますが、原子座標は連続的であり、原子タイプは離散的であるため、処理がより困難なマルチモーダル データが形成されます。さらに、分子には回転や平行移動の不変性などの幾何学的制約もありますが、これはテキストや画像の処理では一般的ではありません。
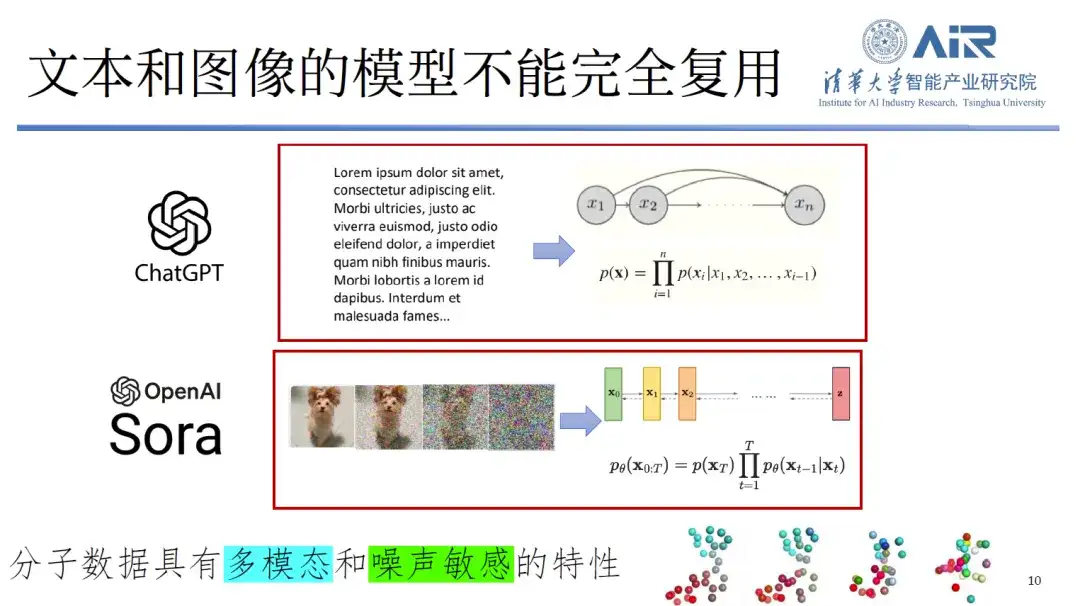
第二に、テキストと画像のモデルはタンパク質分野で完全に再利用することはできません。分子データは本質的に多峰性であるだけでなく、ノイズの影響を非常に受けやすいものです。たとえば、犬の写真にノイズを加えても、人はそれが犬の写真であることを認識できます。しかし、分子データにわずかでもノイズが加わると、人間は分子の正体を特定できなくなり、大量の情報が失われる可能性があります。したがって、従来の処理方法は、この新しいデータ型には完全には適していません。
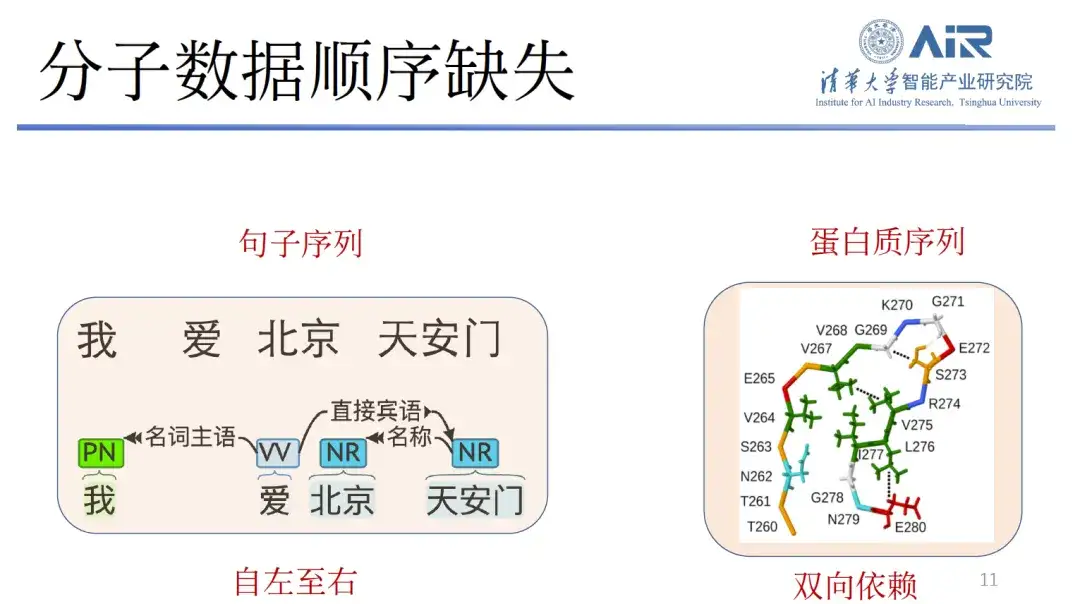
第三に、分子データが逐次欠落している。テキストは左から右への依存性がほとんどないため、GPT を介して左から右へ新しいテキストを生成できます。しかし、タンパク質の双方向依存性は非常に強く、テキストや画像モデルを直接使用して分子構造を生成すると、その前後左右の順序を決定するのが困難になります。
上記の課題を解決するために、Zhou Hao教授のチームは、データ構造、生成アルゴリズム、ベース構築について徹底的な研究を実施しました。
データ構造から始めて、固有のデータ記述空間を見つけます
分子の 3D 構造表現を再構築するために、二面角の自由度のみが保持されます。
「分子やターゲットのデータ構造の固有空間をどのように決定するかは、コンピューター科学者が解決しなければならない問題です。」周昊教授は、分子の三次元構造表現は非常に重要であり、構造は機能であると言えると述べました。これまで、研究者は主に、必要な情報を得るために原子の座標と種類を記録することによって分子モデルを構築していました。しかし、分子の構造は非常に大きく、多くの冗長な情報を含んでいます。これを従来の方法でモデル化すると、コンピュータサイエンスの観点からは、分子の固有空間では観察されません。
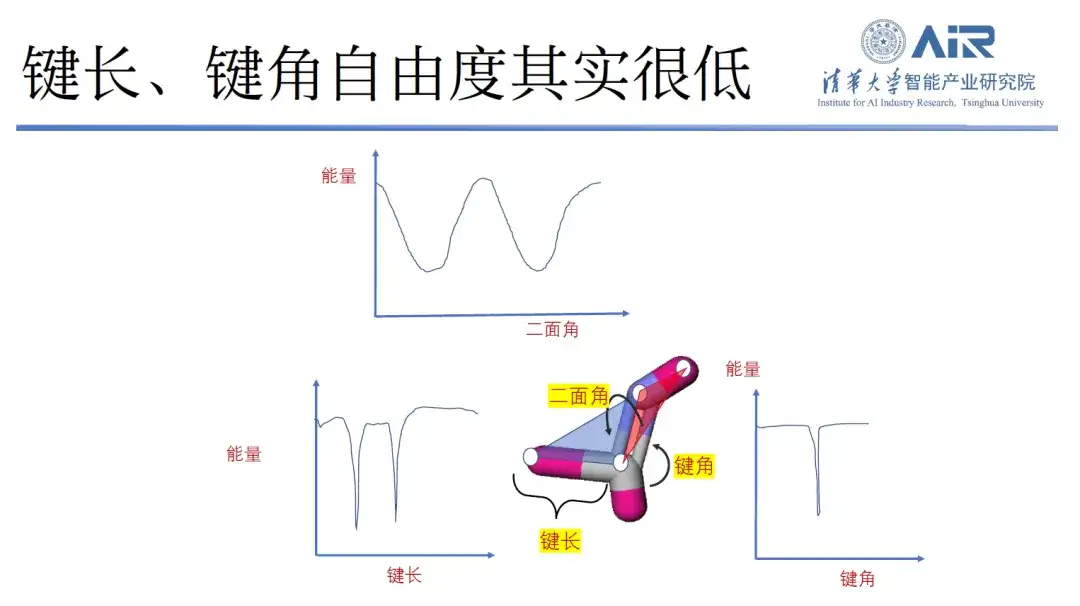
実際、分子の結合長、結合角、二面角を分析すると、分子の結合長と結合角はピークが少なく自由度が限られているのに対し、二面角はより自由度が高いことがわかります。そこで、Zhou Hao教授のチームは新しい方法を考案しました。つまり、二面角の自由度を保持しながら、他の余分な自由度が削除されます。
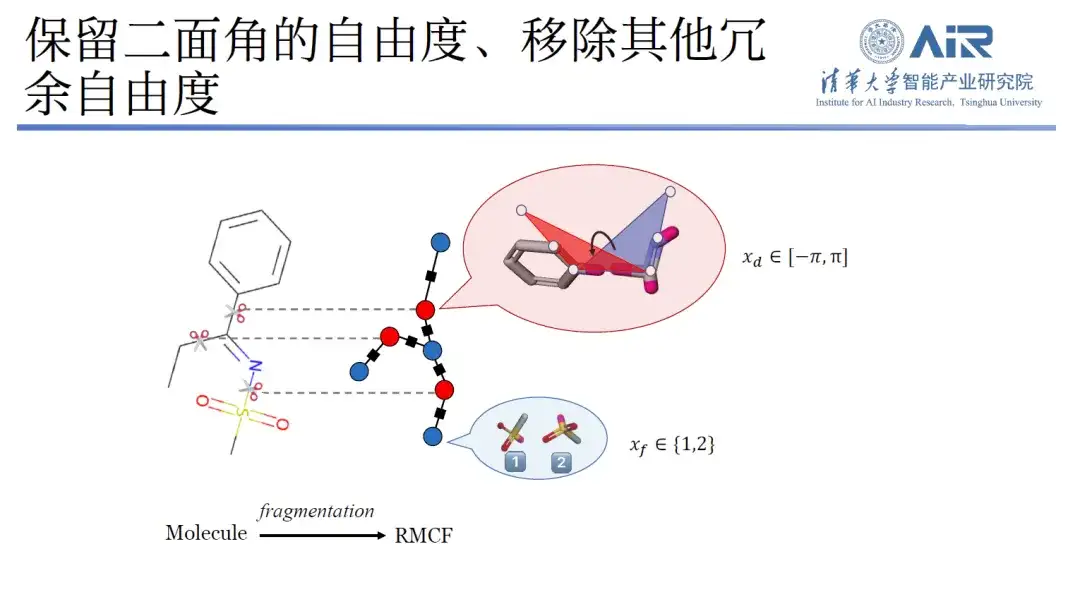
具体的には、本研究では、三次元構造を二次元表現に変換し、分子フラグメンテーション処理により、各分子内の自由度を最小化し、フラグメント間の自由度を最大化するダイナミックプログラミング技術を用いて、最小値を容易に解くことができます。 -max 問題を解決し、アルゴリズムを使用してすべての分子をターゲット データ構造に切り込みます。
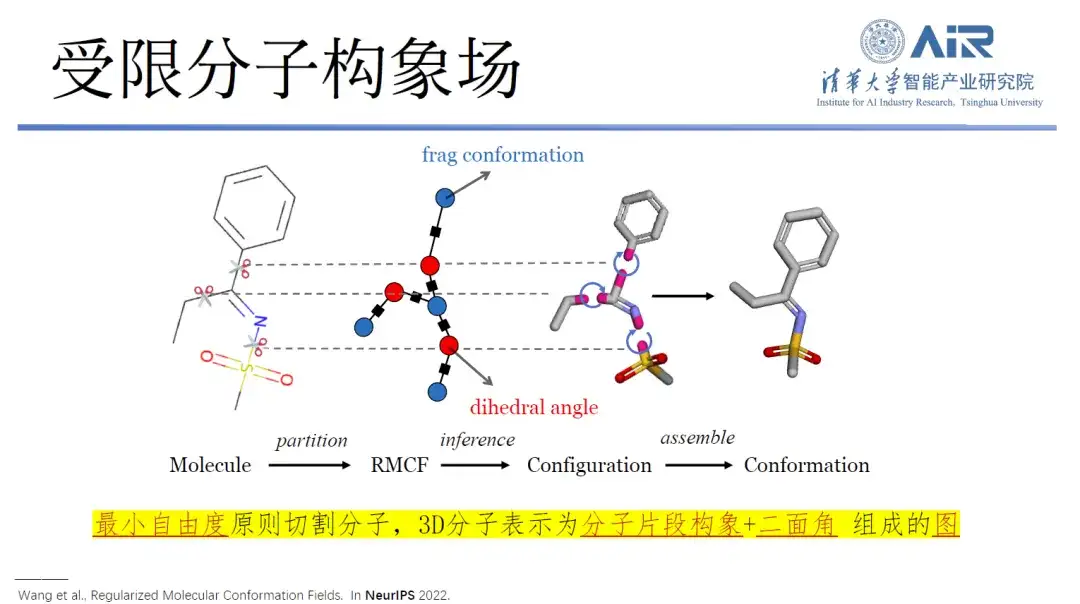
論文のタイトル:規則化された分子立体配座フィールド
論文リンク:https://neurips.cc/virtual/2022/poster/53277
「この新しいデータ構造により、将来的に分子を生成する必要が生じた場合、関連研究が非常に少ないデータ量で分子空間を構築できるようになります。この考え方は非常に重要です!」
実空間からスペクトル空間まで、タンパク質の幾何学的および化学的情報を効率的に取得します
分子研究に加えて、Zhou Hao 教授のチームはタンパク質の構造と機能の研究にも興味を持っています。
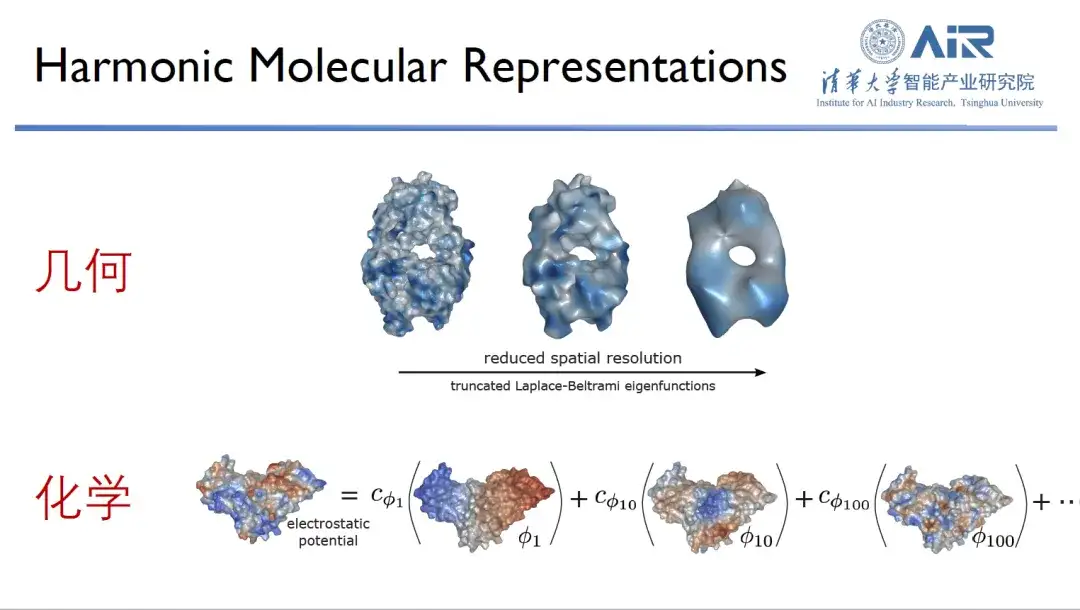
タンパク質を研究するとき、研究者は通常、幾何学的情報と化学的情報という 2 つの次元からタンパク質を観察します。タンパク質の形状と表面の化学情報がその機能にとって重要であることは、その 2 つが相補的である場合にのみ、タンパク質が最適に機能することができることはよく知られています。
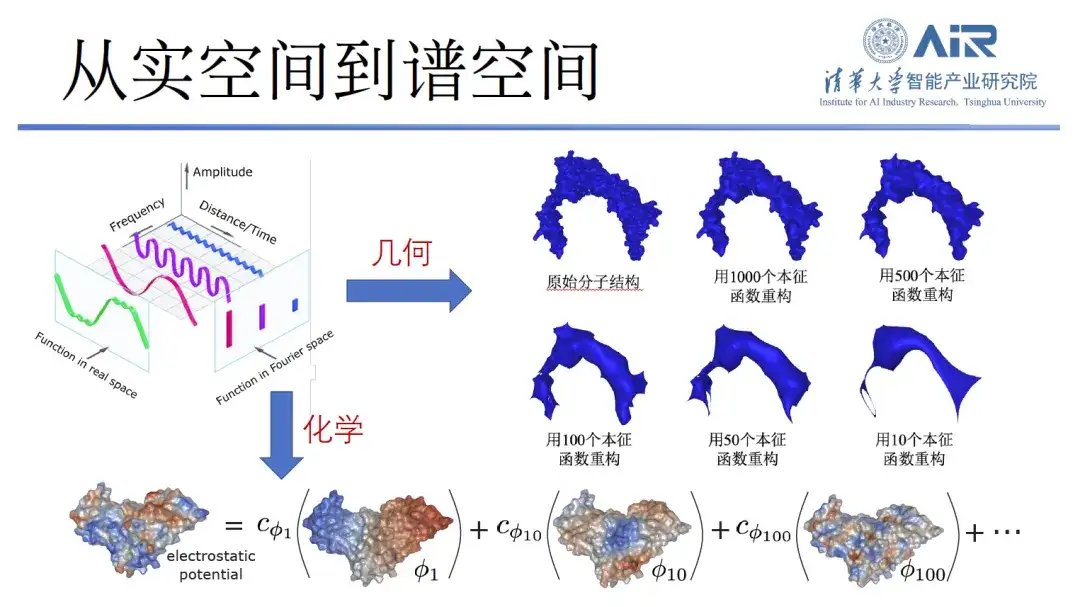
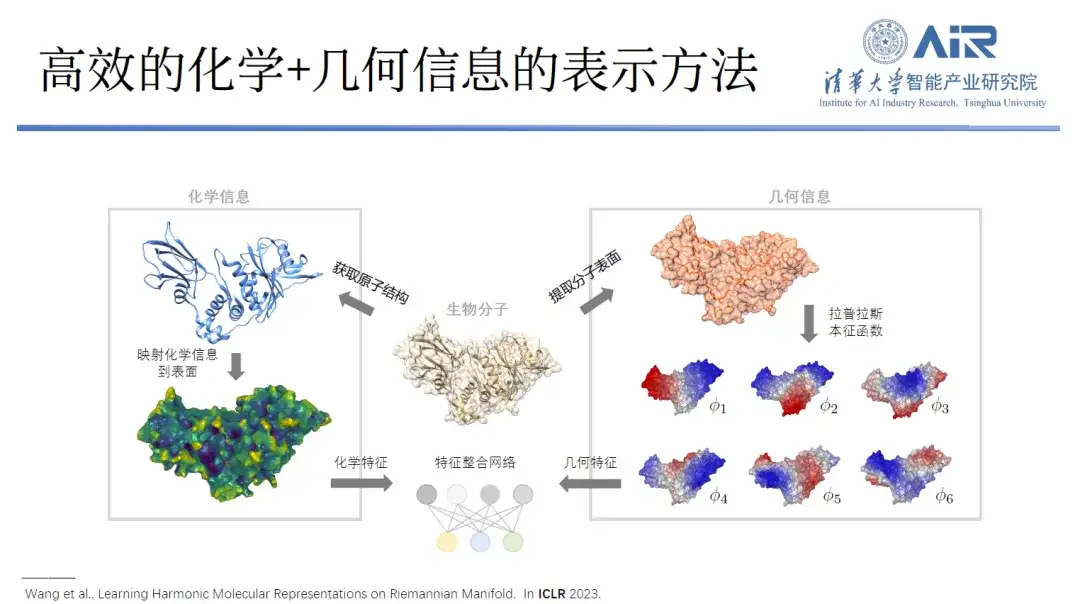
タンパク質の化学的および幾何学的情報を効率的に表現するには、Zhou Hao 教授のチームは、タンパク質を実空間からスペクトル空間に変換し、固有関数を使用してタンパク質を表現しました。たとえば、10 個の固有関数を使用してタンパク質の低周波情報を取得し、その大まかな輪郭を解決します。さらに、より多くの固有関数を使用すると、より多くの高周波情報を取得でき、1,000 個の固有関数を使用すると、ほぼすべてのタンパク質情報が取得されます。
論文のタイトル:リーマン多様体における調和分子表現の学習
論文リンク:https://iclr.cc/virtual/2023/poster/10900
「上記の方法の利点は、タンパク質の幾何学的情報だけでなく、その化学情報もコピーできることです。」それぞれの固有関数を新しい空間とみなすことができ、タンパク質表面の化学情報をこの固有空間にマッピングすることができ、幾何学的情報と化学情報の両方を同じ空間で表現することで、複雑な実空間の問題を単純なスペクトル空間に変換することができます。問題。
生成アルゴリズムから始まり、適応分子の生成モデルを設計する
最もコンパクトで固有の分子およびタンパク質空間が発見されましたが、これらの空間の特定に成功した後、直面する次の疑問は次のとおりです。生成人工知能を使用してターゲット分子を効果的に取得する方法。
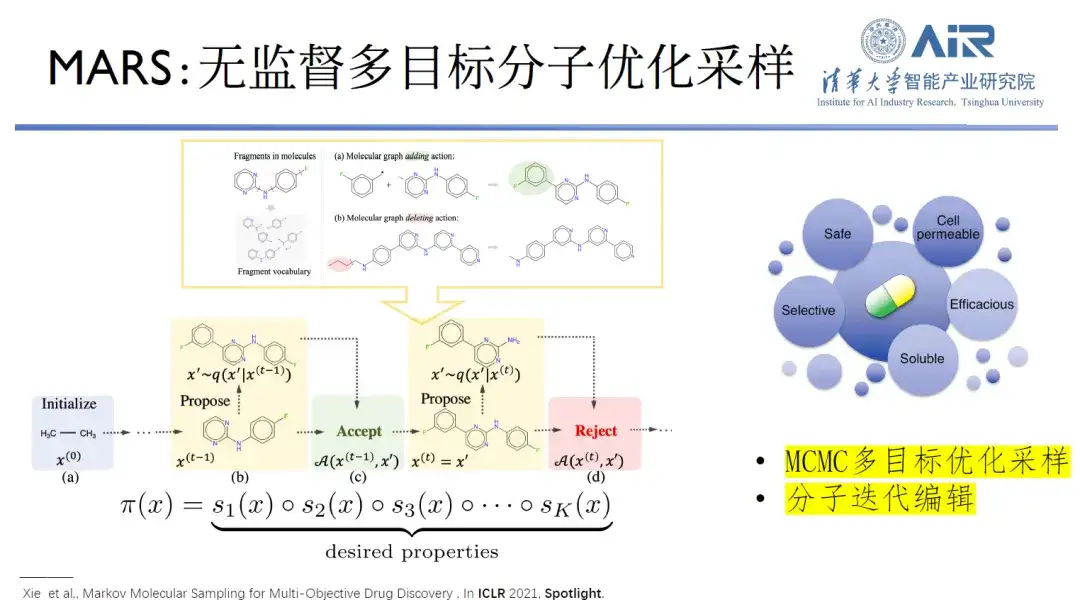
論文のタイトル:MARS: 多目的創薬のためのマルコフ分子サンプリング
論文リンク:https://iclr.cc/virtual/2021/poster/3352
最適な分子生成モデルを見つけるために、Zhou Hao 教授のチームは、教師なしの多目的分子最適化サンプリングを使用して 2D 分子設計を行う MARS と呼ばれるモデルを開発しました。分子設計プロセスでは、複雑で高度な分子設計の問題が発生します。次元空間でのサンプリング。マルコフ連鎖モンテカルロ (MCMC) フレームワークを使用して分子を編集すると、注意深いバランス条件が満たされていれば、任意のターゲット分子を生成できます。
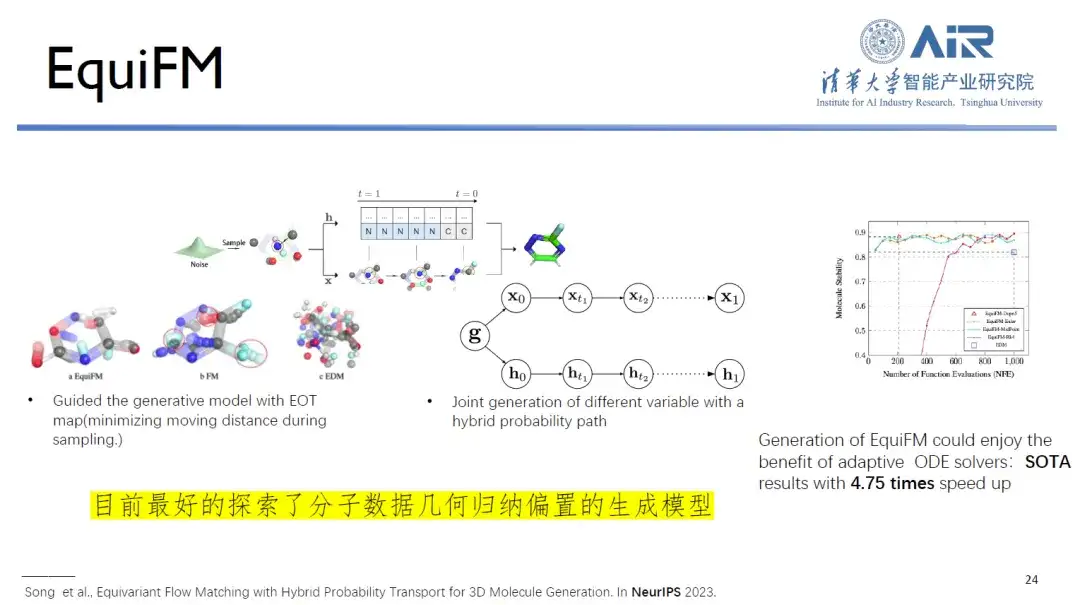
論文のタイトル:ハイブリッド確率輸送による等変流量マッチング
論文リンク:https://neurips.cc/virtual/2023/poster/70795
同時に、Zhou Hao 教授のチームが提案した EquiFM は、現在、分子データの幾何学的誘導バイアスの調査において最もパフォーマンスの高い生成モデルであり、複数の分子生成ベンチマーク テストで優れたパフォーマンスを達成しており、平均サンプリング速度が 1 倍向上しています。 4.75倍。
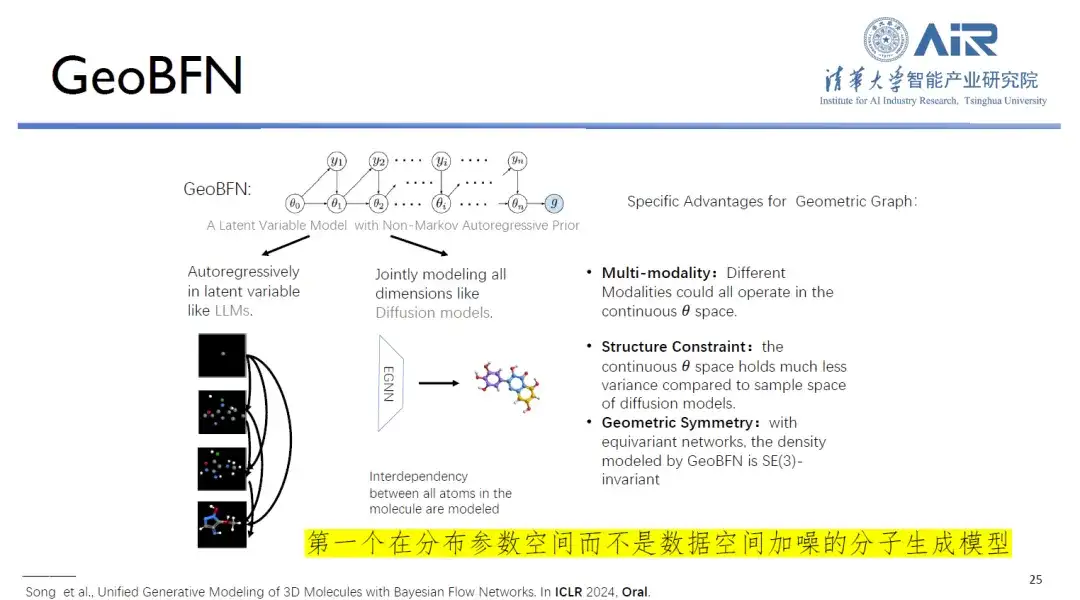
論文のタイトル:ベイジアン フロー ネットワークを介した 3D 分子の統合生成モデリング
論文リンク:https://iclr.cc/virtual/2024/oral/19764
さらに、GeoBFN 分子生成モデルの核心は、データ空間内のすべての分子データをガウス平均分散空間に変換することで、正当性が高く真の分布に近い分子を生成することです。これに関して、周昊教授は次のように述べた。「これは現時点で最も適切な分子の深層生成モデルであり、開発の大きな可能性を秘めています。」
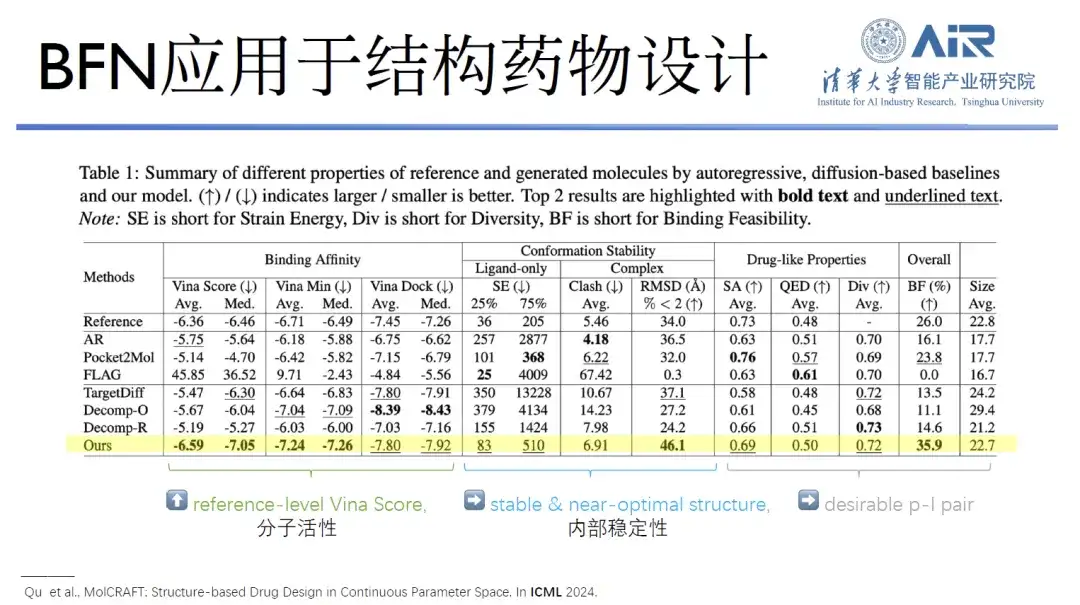
論文のタイトル:MolCRAFT: 連続パラメータ空間における構造ベースの薬剤設計
論文リンク:https://icml.cc/virtual/2024/poster/34336
これらの研究に加えて、Zhou Hao 教授のチームは、GeoBFN を構造薬物設計に適用する可能性を探る論文を国際機械学習会議 (ICML) で発表しました。結果は、このモデルを使用して生成された分子が非常に安定した立体構造と優れた活性を持っていることを示しています。
基盤構築からスタートし、膨大なデータ知識が豊富な事前トレーニング基盤を構築
最後に、Zhou Hao 教授は、ベースの構築から始めて、膨大なデータ知識が豊富な事前トレーニングベースを確立する方法を全員に共有しました。
既存の研究では、小分子によって生成される実験データは非常に希少であり、この問題を解決するためにコンピューターサイエンスの手法を使用しようとすることは重要なアイデアです。
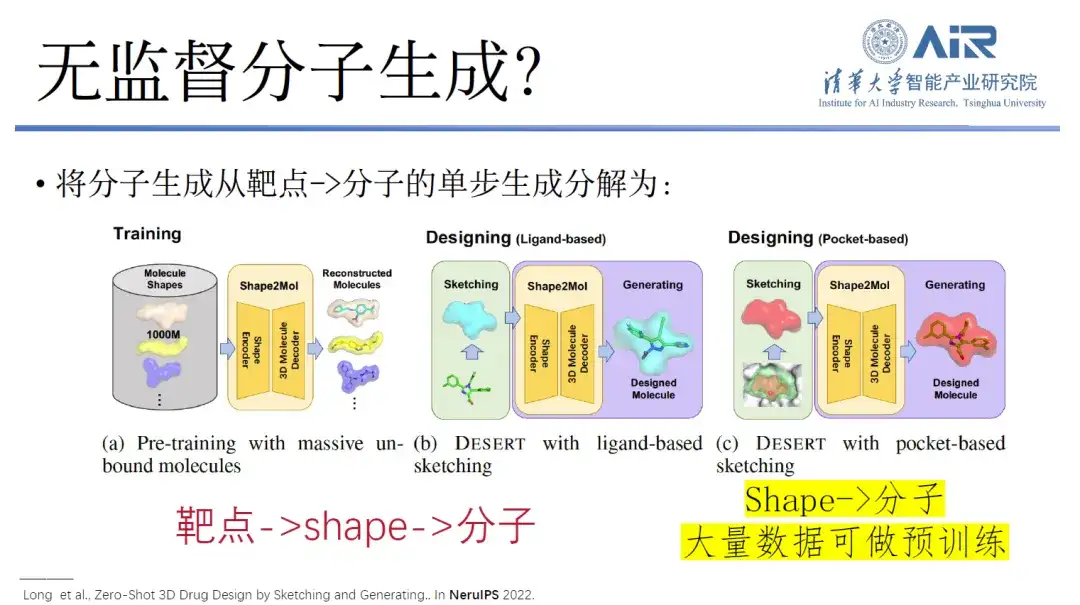
論文のタイトル:スケッチと生成によるゼロショット 3D 医薬品設計
論文リンク:https://neurips.cc/virtual/2022/poster/54457
これに関して、周昊教授のチームは新しいアイデアを提案しました。つまり、ターゲットから分子への分子生成の単一ステップの生成と分解は、ターゲットから形状へ、そして形状から分子へのプロセスになります。実際、ターゲット点から分子までの直接のデータ量は非常に少ないですが、形状から分子までのデータ量は非常に多く、ターゲット点からさまざまな形状を収集して実行するのに十分です。形状から分子までの大規模な分析。事前トレーニングされたモデルをスケールします。最終的には、標的から分子への移行が間もなく可能になり、さらには教師なしまたは教師なしの薬物分子設計を達成することもできるようになるでしょう。
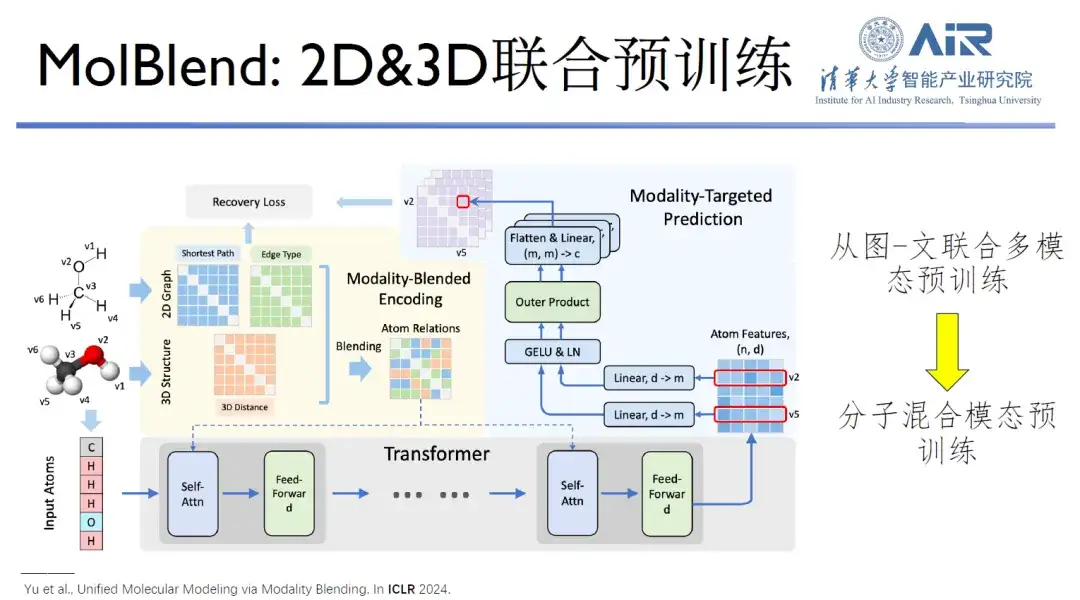
論文のタイトル:モダリティブレンディングによるマルチモーダル分子事前トレーニング
論文リンク:https://iclr.cc/virtual/2024/poster/17824
さらに、彼らが提案した MolBlend モデルは、2 次元と 3 次元の分子の事前トレーニングを実現します。これは、グラフィックの事前トレーニングから分子の事前トレーニングへの拡張の典型的なケースです。
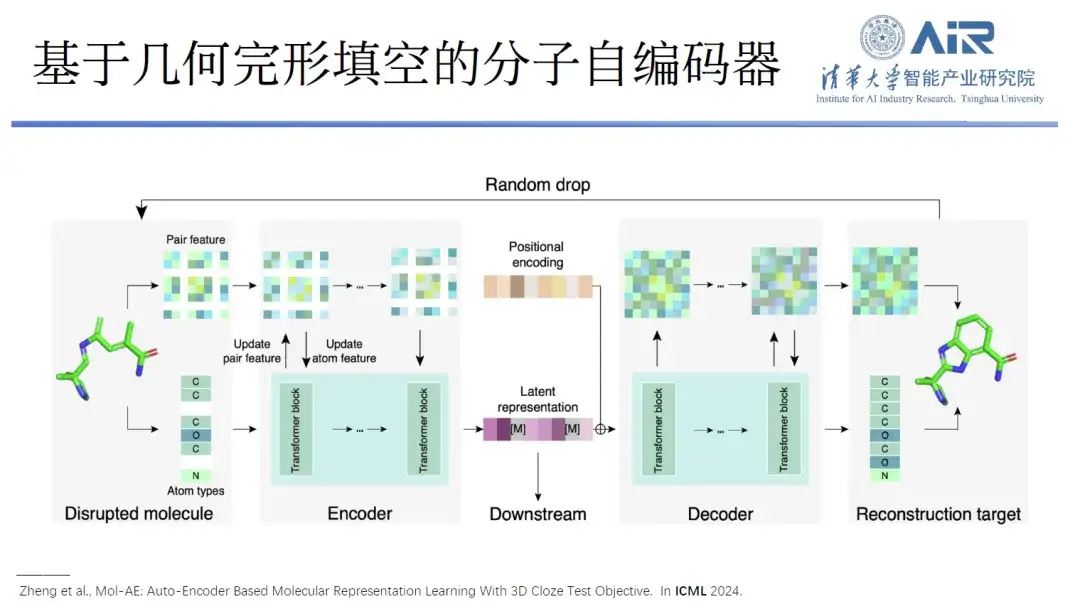
論文のタイトル:Mol-AE: 3D Cloze テスト目標を使用した自動エンコーダー ベースの分子表現学習
論文リンク:https://icml.cc/virtual/2024/poster/33340
加えて、彼らはまた、幾何学的クローゼに基づいた分子オートエンコーダー Mol-AE を提案しました。提案されたモデルは、現在の最先端の 3 次元分子モデリング手法と比較して、実際の分子構造における原子の空間的関係をより良く学習できます。大幅なパフォーマンスの向上。

タンパク質に関する一般的なトレーニング前の研究も、彼らが選択した方向性です。現在の一般的なタンパク質の事前トレーニングは、主に DeepMind Alphafold シリーズ、David Baker の RoseTTAFold シリーズ、Meta ESM シリーズの 3 つのカテゴリに分類されていることがわかります。Zhou Hao 教授のチームは現在、ESM-AA モデルを開発しています。
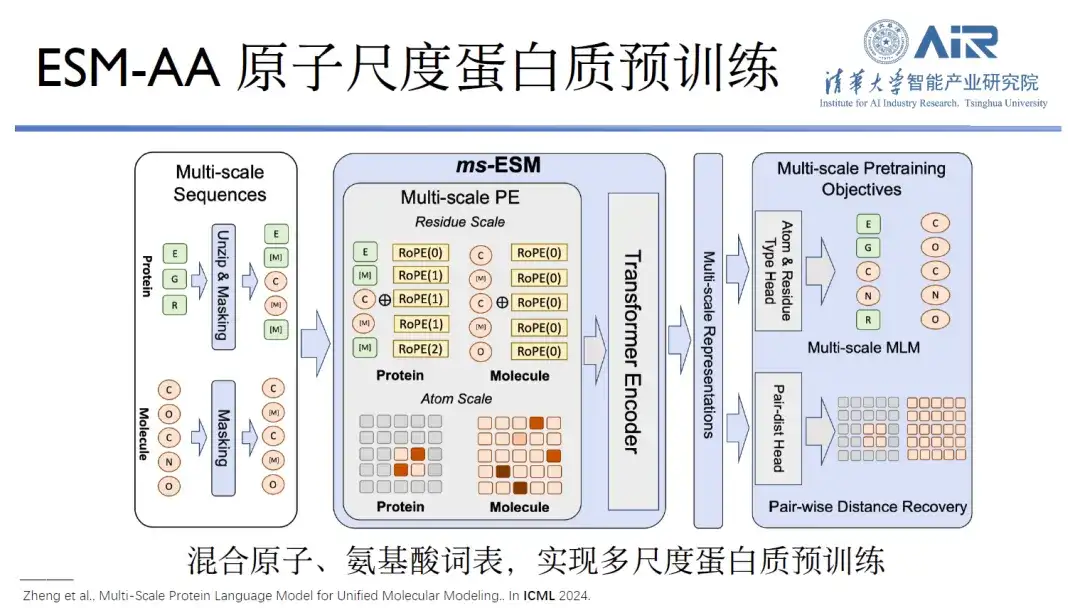
論文のタイトル:統一分子モデリングのためのマルチスケールタンパク質言語モデル
論文リンク:https://icml.cc/virtual/2024/poster/35119
これは、Alphafold2 から Alphafold3 へのアップグレードで全原子ベースが構築されたためであり、RoseTTAFold シリーズについても同様です。ESM シリーズのみがまだ全原子ベースを構築していません。 Zhou Hao教授のチームは、原子とアミノ酸の語彙を組み合わせることで、タンパク質と小分子の共同タスクにおいて、事前予測トレーニングのみよりも優れたパフォーマンスを実現できるとしている。 ESM などのベース、他のタンパク質の事前トレーニングまたは低分子の事前トレーニング ベース。
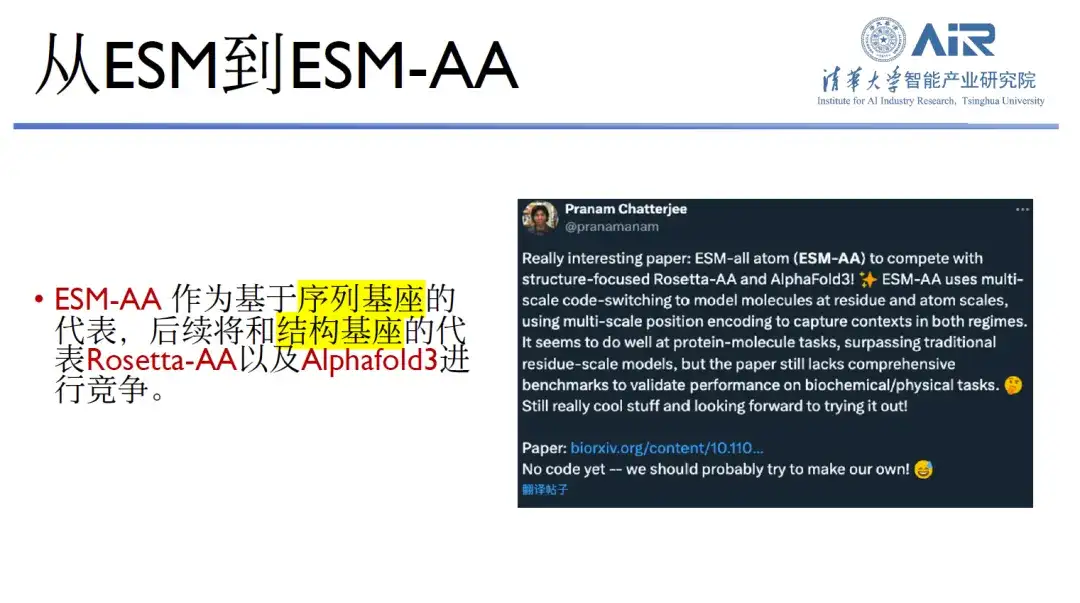
この事前トレーニングベースはTwitterでも広く称賛されています。 ESM-AAは、配列塩基の代表として、構造塩基の代表であるRoseTTAFoldやAlphafold3と競合することになると、Zhou Hao教授は述べた。
周昊教授について
Zhou Hao 氏、1990 年生まれ、清華大学准研究員、博士。研究の方向性は、複雑な記号システムのための生成人工知能であり、その主な用途には、非常に大規模な言語モデル、分子生成、タンパク質設計、新材料発見などが含まれます。

彼はかつて ByteDance の研究科学者および副所長を務め、テキスト生成および AI 支援医薬品設計のための ByteDance の研究開発チームの設立を主導しました。開発された製品は世界 20 か国以上で使用されており、ユーザーベースを持っています。 10億以上。彼は、ICML、NeurIPS、ICLR、ACL などの主要な人工知能会議のフィールドチェアを長年務めており、人工知能に関する重要な国際会議で 80 以上の論文を発表しています。中国人工知能学会の 2019 年度優秀博士論文賞、自然言語処理分野のトップ国際会議である ACL 2021 Best Paper Award (1/3350)、および 2021 中国コンピュータ学会 NLPCC 若手新進学者賞を受賞。








