Command Palette
Search for a command to run...
2024 Meet AI Compiler 北京オフラインミートアップが予定されています! 1,000 万レベルの命令微調整データセット InfinityInstruct オープンソース

高品質の命令データは、大規模な言語モデルのトレーニングと最適化に不可欠なリソースであり、モデルのパフォーマンスを向上させる基礎となります。最近、北京知源人工知能研究所は、オープンソースのデータセットに基づいた高品質のフィルタリングされたデータと、データを通じて構築された高品質の命令データを含む、数千万の高品質の命令微調整データセットのオープンソースプロジェクトInfinityInstructをリリースしました。合成方法。
このカンファレンスでは、モデル検証済みの 300 万の高品質な中国語と英語の命令データ セット InfInstruct-3M の最初のバッチがオープンソース化されました。hyper.ai の公式 Web サイトがオンラインになりました。このデータ セットを使用し、独自のアプリケーション データで基本モデルを微調整して、高品質の専用の中国語と英語のバイリンガル対話モデルを迅速に作成できます。
6 月 10 日から 6 月 14 日までの hyper.ai 公式 Web サイトの更新の概要:
* 高品質の公開データセット: 10
* 高品質なチュートリアルのセレクション: 2
* コミュニティ記事選択: 4 記事
* 人気のある百科事典のエントリ: 5
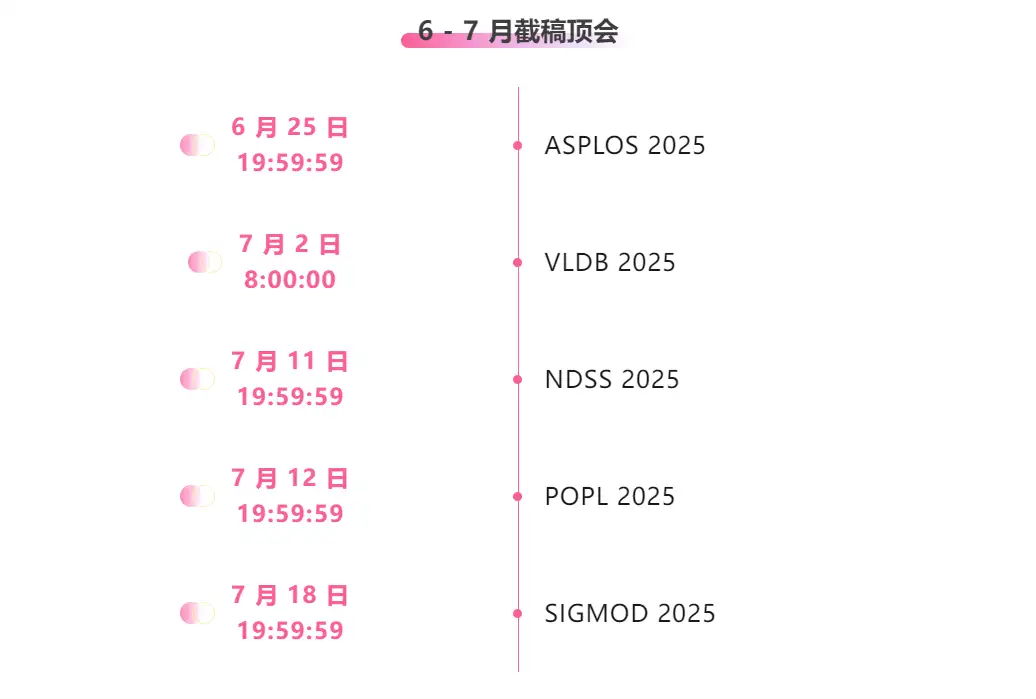
※6月~7月の提出締切:5日
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. InfInstruct-3M は数千万の命令微調整データ セットを起動します
このデータ セットは、Beijing Zhiyuan Artificial Intelligence Research Institute によって開始されました。このプロジェクトの目標は、大規模な言語モデルの命令追跡機能をサポートする数百万の命令を含むデータ セットを開発し、それによってモデルのパフォーマンスを向上させることです。このバージョンは InfinityInstruct-3M 命令データセットで、最終バージョンは 6 月末にリリースされる予定です。
直接使用します:https://go.hyper.ai/iG7gN
2. LooGLE の長い文脈理解能力ベンチマーク データ セット
このデータセットは、長期的なコンテキストの理解における人工知能システムの機能を評価および改善するために設計されたベンチマーク データセットです。関連論文がACL2024に受理されました。
直接使用します:https://go.hyper.ai/S6dSZ
3. InternVid-Full 高品質大規模ビデオテキストデータセット
このデータセットには、詳細なテキスト説明を含む 700 万本以上のビデオが含まれており、16 のシーンと約 6,000 のアクションの説明が含まれており、総再生時間は約 760,000 時間になります。関連論文は、2024 年表現学習国際会議 (ICLR 2024) でスポットライトを獲得しました。
直接使用します:https://go.hyper.ai/AnaLl
4. ドメイン適応型セマンティックセグメンテーション用の LoveDA リモートセンシング土地被覆データセット
このデータセットは、リモート センシングの分野で使用される土地被覆データセットであり、ドメイン適応型セマンティック セグメンテーション用に特別に設計されており、5,987 枚の高解像度画像と 166,768 個の注釈付きセマンティック オブジェクトが含まれています。
直接使用します:https://go.hyper.ai/ShKyN
このデータセットは、都市建築に焦点を当てた画像データセットであり、通常、これらの画像は、特に建物の検出、セマンティック セグメンテーション、インスタンス セグメンテーションなどのタスクでコンピューター ビジョン モデルをトレーニングおよび評価するために使用できます。 、および関連する結果は CVPR 2024 に含まれています。
直接使用します:https://go.hyper.ai/ddNqv
6. 廃棄物分類 リサイクル可能な廃棄物および家庭廃棄物の分類データセット
このデータセットには、30 の異なるカテゴリのさまざまなリサイクル可能な材料、一般廃棄物、家庭用品をカバーする 15,000 枚の画像 (各 256 × 256 ピクセル) が含まれており、廃棄物の分類とリサイクルの分野の研究開発に豊富で多様なリソースを提供します。
直接使用します:https://go.hyper.ai/kOiKG
7. BIRDS 525 SPECIES 525種の鳥画像データセット
データセットには、合計 525 種の鳥、84,635 枚のトレーニング画像、2,625 枚のテスト画像、2,625 枚の検証画像が含まれています。
直接使用します:https://go.hyper.ai/pfw5d
8. OpenEarthMap グローバル高解像度土地被覆マッピング ベンチマーク データセット
このデータセットは、6 大陸 44 か国の 97 地域をカバーする 5,000 枚の航空画像と衛星画像の 220 万セグメントで構成されており、地上サンプリング距離 0.25 ~ 0.5 m で手動で注釈が付けられた 8 カテゴリーの土地被覆ラベルが付いています。関連する論文結果は WACV 2023 に含まれています。
直接使用します:https://go.hyper.ai/ubxmO
このデータセットは、日本の漫画の機械翻訳評価データセットです。5 つの異なるスタイルの漫画 (ファンタジー、恋愛、バトル、サスペンス、ライフ) が含まれています。データセットには、合計 1,593 文、848 シーン、214 ページが含まれています。東京大学マントラチームが発表した漫画。
直接使用します:https://go.hyper.ai/ISqUR
このデータセットは、人間の知覚に基づいて 47 のカテゴリに分類された 5,640 枚の画像で構成されており、各カテゴリには 120 枚の画像があり、各画像の主要な属性と関節属性のリストが含まれています。
直接使用します:https://go.hyper.ai/aUYi3
その他の公開データセットについては、以下をご覧ください。
選択された公開チュートリアル
Stability AI と Tripo AI によって開発された TripoSR は、1 つの画像から高品質の 3D モデルを 1 秒で生成でき、必要な計算能力も非常に少ないため、一般のユーザーがローカル デバイスで簡単に使用できます。このチュートリアルの環境は、誰もが実行して体験できるようにセットアップされています。
オンラインで実行:https://go.hyper.ai/is9qe
LGM (Large Multi-View Gaussian Model) は、テキスト プロンプトまたはシングルビュー画像から高解像度 3D モデルを生成するための革新的なフレームワークです。この方法では 5 秒で 3D オブジェクトを生成でき、トレーニング解像度を 512 に高めることで、高解像度の 3D コンテンツの生成を実現します。このチュートリアルは、LGM のデモ実装です。
オンラインで実行:https://go.hyper.ai/pFnhg
また、Stable Diffusion チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に注目し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりするためにグループに参加してください。
注目のコミュニティ記事
1. イベント プレビュー | 2024 Meet AI Compiler 北京プレミアは 7 月 6 日に予定されています。
Meet AI Compiler 北京プレミアは、2024 年 7 月 6 日に中国科学院計算技術研究所 1 階の講堂で開催されます。幸運にも、上海交通大学、計算技術研究所、中国科学院、マイクロソフト リサーチ アジアなどから多くの上級 AI コンパイラー専門家をこのミートアップに招待します。彼らはエキサイティングなテーマの共有とラウンドテーブルディスカッションを提供し、実装シナリオにおける AI コンパイラーテクノロジーの応用と画期的な進歩について話し合います。登録するには「原文を読む」をクリックしてください!
完全なイベント情報を表示:https://go.hyper.ai/EA1uw
2.今だけ! Apple が Apple Intelligence をリリース、ChatGPT への無料アクセスを正式に発表、Siri がメジャーアップデートを受信
先週、Apple は Apple Intelligence をリリースし、iOS 18 と Siri にメジャーアップデートを導入しました。以前から噂されていた Apple と OpenAI の連携がついに正式に発表されました。ChatGPT と統合された Siri は、より自然でコンテキストに合わせたパーソナライズされたものとなり、日常のタスクを簡素化し、スピードアップすることができます。この記事では、Apple Intelligence、Siri、iOS 18 のアップデートを紹介し、Siri の開発プロセスについても整理します。これにより、Apple の AI 機能を Siri にアップグレードすることの重要性がさらにわかります。
レポート全体を表示します。https://go.hyper.ai/kWmHC
3. CVPR 2024 最優秀論文候補!深セン大学と香港理工大学が共同で MemSAM をリリース:「すべてをセグメント化」モデルを医療ビデオのセグメンテーションに適用
深セン大学コンピューター・ソフトウェア学部と香港理工大学インテリジェントヘルス研究センターが共同で結成したチームは、新しい心エコー検査ビデオセグメンテーションモデルMemSAMを提案した。このモデルは、少数のポイント ヒントで最先端のパフォーマンスを実現し、注釈が限られた完全教師ありメソッドと同等のパフォーマンスを実現し、ビデオ セグメンテーション タスクに必要なヒンティングと注釈の要件を大幅に軽減します。この記事は、研究の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/2s73Q
4. AlphaFoldの韓国版?深層学習モデル AlphaPPIMd: タンパク質間複合体の構造アンサンブル探索用
延世大学のWang Jianmin博士らは、深層学習と生成AIを組み合わせ、Transformerベースの生成ニューラルネットワークを使用してタンパク質間複合体の構造セットを探索する方法を学習し、複数の分子動力学軌道から学習してタンパク質の構造に影響を与えた。 -タンパク質複合体と速度論的メカニズムの重要な残基。タンパク質間の結合に関する機構的な洞察を提供します。この記事は、研究の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/MdgoV
人気のある百科事典の項目を厳選
1.相互ランキング融合RRF
2. マスクされた言語モデリング MLM
3. 学習率 学習率
4. YOLOv10 リアルタイムのエンドツーエンドのオブジェクト検出
5. コルモゴロフ・アーノルド表現定理
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
ステーションBのライブブロードキャストプレビュー
Jeff Dean は、Google の上級研究員兼コンピュータ サイエンティストであり、MapReduce や TensorFlow の開発など、分散システムと人工知能における先駆的な業績で知られており、Google テクノロジーの開発における重要人物の 1 人です。今週、スーパー ニューロ TV はジェフ ディーンのスピーチとインタビューを生中継します。
次の表は、編集者が全員に向けて選択したコンテンツのプレビューです↓↓↓
| 日付 | 時間 | コンテンツ |
| 6月17日月曜日 | 18:00 | ジェフ・ディーンが機械学習の 5 つの主要トレンドについて語る |
| 6月18日火曜日 | 18:00 | AI をすべての人に提供しましょう |
| 6月19日水曜日 | 18:00 | AI の将来に対するジェフ ディーンの前向きな見解 |
| 6月20日(木) | 18:00 | スタンフォード医療ビッグデータカンファレンスでのジェフ・ディーン氏の講演 |
| 6月21日金曜日 | 18:00 | ディープラーニングに関するジェフ・ディーン氏の講演 |
| 6月22日土曜日 | 18:00 | Google Brain と Brain Residency |
| 6月23日(日) | 18:00 | Jeff Dean がディープラーニングを使用して問題を解決する方法について語ります |
スーパー ニューラル TV ステーションは、7 時間 24 日中断のない生放送を放送しており、ワンクリックで AI 分野の「電子マスタード」を収穫できます。
http://live.bilibili.com/26483094
主要な人工知能学会をワンストップで追跡:https://hyper.ai/events
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
* 1,300 を超える公開データセットに対して国内の高速ダウンロード ノードを提供
* 400 以上の古典的で人気のあるオンライン チュートリアルが含まれています
* 100 以上の AI4Science 論文ケースを解釈
* 500 以上の関連用語クエリをサポート
*Apache TVM の最初の完全な中国語ドキュメントを中国でホストします
学習の旅を始めるには、公式 Web サイトにアクセスしてください。








