Command Palette
Search for a command to run...
LLaMA 3 Chinese Chat のワンクリック展開 (2,000 カテゴリと 100 万枚の写真を含む Food2K データセットのダウンロードを含む)

少し前に Llama 3 の強力なオープンソース リリースが AI 関係者全員を興奮させましたが、純粋な中国語のサポートはあまり良くなく、中国語の質問に基づいた回答に対して対応する言語に柔軟に切り替えることができません。
hyper.ai は今週 LlaMA 3 の中国語版をリリースしました - LlaMA 3 中国語チャットの展開推論チュートリアル、「中国語の質問に英語で答える」ときの恥ずかしさを効果的に解決し、会話をより自然でスムーズにします。モデルと環境はチュートリアルでデプロイされています。推論を体験するには API アドレスを開くだけです。
待ちきれません、試してみたいです🥳:
同じ中国語のトレーニング データセット🤖:
5 月 27 日から 5 月 31 日までの hyper.ai 公式 Web サイトの更新の概要:
* 高品質の公開データセット: 10
* 高品質なチュートリアルのセレクション: 2
* コミュニティ記事選択: 4 記事
* 人気のある百科事典のエントリ: 5
※6月提出締切:4日
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. Llama 3 中国文化データセット
このデータ セットは、Llama 3 中国文化データ セットのコレクションであり、firefly 形式に統合されており、firefly ツールで使用して Llama 3 中国語モデルを直接トレーニングできます。
直接使用します:https://go.hyper.ai/uJlfk
2. LCCC 大規模クリーン中国語会話コーパス
このデータセットには主に、LCCC ベース (680 万会話) と LCCC 大 (1,200 万会話) の 2 つの部分が含まれています。研究チームは、このデータセット内の対話データの品質を保証するために、厳密なデータ フィルタリング プロセスを設計しました。フィルタリングされたデータセットは、短いテキストの対話モデリングの研究を促進できます。
直接使用します:https://go.hyper.ai/bDzEG
3. Food2K 大規模な食品識別データセット
Food2K は、2,000 の食品カテゴリと 100 万を超える画像を含む大規模な食品認識データセットです。
直接使用: https://go.hyper.ai/TpfUJ
4. COYO-700M 画像・テキストペアデータセット
COYO-700M には、7 億 4,700 万の画像とテキストのペアとその他の多くのメタ属性が含まれており、HTML ドキュメント内の多くの有益な代替テキストとそれに関連する画像のペアを収集します。
直接使用: https://go.hyper.ai/fWI1i
5. GLH-Bridge大判リモートセンシング画像ブリッジターゲット検出データセット
このデータ セットには、6,000 枚の大判超高解像度リモート センシング画像が含まれており、さまざまな背景にまたがる橋の例が 60,000 件近くあり、手動で正確に注釈が付けられています。画像形式は 2048×2048 ~ 16384×16384 ピクセルで、次の 2 つのオブジェクト セットが含まれています。回転フレームと水平フレームのタグを検出します。
直接使用: https://go.hyper.ai/cHPeb
6. MMDialog マルチモーダル オープン ドメイン マルチターン ダイアログ データ セット
このデータセットは、大規模なマルチモーダル オープンドメイン対話データセットであり、108 万件の完全な対話セッション、4,000 を超える対話トピック、および 153 万枚の非重複画像 (対話セッションごとに平均 2.59 枚の画像) が含まれています。
直接使用: https://go.hyper.ai/iAbI2
7. インドのピマ糖尿病データセット
このデータセットの目的は、もともと国立糖尿病・消化器・腎臓病研究所が提供したもので、データセットに含まれる特定の診断測定値に基づいて、患者が糖尿病であるかどうかを診断的に予測することです。
直接使用: https://go.hyper.ai/XqJXe
8. LamaH-CE 中央ヨーロッパの水文学および環境科学の大規模サンプル データセット
LamaH-CE には、859 の測定流域およびさまざまな (流域) 属性の流出および気象時系列が含まれています。水文気象時系列には日次および時間別の時間分解能があり、品質マーカーが含まれています。すべての気象およびほとんどの流出時系列は 35 年以上に及びます。
直接使用します:https://go.hyper.ai/UPZvA
9. CAMELS-GB UK 流域属性と水文気象時系列データセット
このデータセットは、英国の 671 の集水域の水文気象時系列と景観属性を提供します。これは、英国国立河川流域アーカイブからの河川の流れ、集水域の属性、集水域の境界を、新しい一連の気象時系列と集水域の属性とともに照合します。
直接使用します:https://go.hyper.ai/KA29l
10. HQ-Edit コマンドベースの画像編集データセット
HQ-Edit には、入力画像、出力画像、詳細な編集手順を含む約 200,000 の編集例が含まれています。
直接使用します:https://go.hyper.ai/xjahh
その他の公開データセットについては、次のサイトをご覧ください。:
選択された公開チュートリアル
1. ワンクリックで Llama 3- Chinese-Chat-8b デモをデプロイします
このチュートリアルで使用されるモデルは、Llama 3 の最初の中国語バージョンです。これは、中国語と英語のユーザー向けに細かく調整された指示を備えた言語モデルであり、ロール プレイングやツールの使用などの複数の機能を備えています。コンテナーを複製して起動し、生成された API アドレスを直接コピーするだけで、モデル上で推論を実行できます。
オンラインで実行:https://go.hyper.ai/i3r7D
2.オンラインチュートリアル丨ソラのテクニカルルートと同じ!世界初のオープンソース Vincent Video DiT モデルである Latte をワンクリックで展開
Latte は、2023 年 11 月にオープンソース化されたビデオ生成の革新的なモデルです。Latte は、世界初のオープンソースの Vincent ビデオ DiT として、有望な結果を達成しました。このチュートリアルでは、Latte プロジェクトのエフェクトのデモを実装します。
オンラインで実行: https://go.hyper.ai/LFfmt
ステーションBのライブブロードキャストプレビュー
Apple は 6 月 10 日から 14 日まで WWDC 2024 を開催し、皆様に Apple についてもっと理解していただくために、Super NeuroB ライブ ブロードキャスト ルームでは、これまでの WWDC カンファレンス、エグゼクティブ インタビュー、関連ドキュメンタリーなどを取り上げた「Apple Special Topic」ビデオを引き続き放送します。その他充実したコンテンツ。その時、スーパーナーブはビデオアカウントとB局でもリアルタイムで放送されます。今すぐ予約して、お見逃しなく~

以下の表は、編集者が選んだ来週の生放送内容を皆さんに予告したものです↓↓↓
| 日付 | 時間 | コンテンツ |
| 6月1日 月曜日 | 18:00 | ジョブズ略歴 |
| 6月2日火曜日 | 18:00 | 何がリンゴをリンゴたらしめているのか |
| 6月3日水曜日 | 18:00 | スティーブ・ジョブズ vs ビル・ゲイツのインタビュー |
| 6月4日(木) | 18:00 | iPhone初の発売カンファレンス |
| 6月5日金曜日 | 18:00 | スティーブ・ジョブズの歴史 |
| 6月6日土曜日 | 18:00 | Appleは破産寸前をどうやって生き延びたのか |
| 6月7日日曜日 | 18:00 | ティム・クックの歴史 |
スーパー ニューラル TV ステーションは、7 時間 24 日中断のない生放送を放送しており、ワンクリックで AI 分野の「電子マスタード」を収穫できます。
http://live.bilibili.com/26483094
注目のコミュニティ記事
1. 【データセット概要】気象庁が訓練データカタログを初公開! CAMELS 米国の天文および気象データセットおよびその他のデータが公式 Web サイトでオンライン化されました
先週、中国気象局は膨大な気象データをまとめた「人工知能気象大型モデル訓練特別データカタログ」を初めて発表した。カタログは気象庁公式ホームページからダウンロードできるようになりました。さらに、誰もが関連データリソースを理解して利用できるようにするために、HyperAI Super Neural は今週、関連研究の進歩をより促進し、気象研究の新たな章を開くために 10 個の高品質気象災害データセットも編集しました。
詳細情報を取得します。https://go.hyper.ai/kK87m
2. 世界中の 2,000 以上の水文観測所からのデータを分析およびトレーニングした後、中国科学院チームは、監視データのない地域で洪水予測を実現する ED-DLSTM をリリースしました。
中国科学院成都山岳災害環境研究所の欧陽朝軍氏のチームは、流域と気象要因の静的属性をエンコードすることで、2,000 以上の水文データを使用する AI ベースの流出洪水予測モデル ED-DLSTM を提案しました。モデルトレーニングのために世界中の観測所を利用して、モニタリングデータを使用した流域と、地球規模でのモニタリングデータを使用しない流域における流出予測の問題を解決してみます。この記事は、研究の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/eG6H5
3. ブレイン コンピューター インターフェイス: これは現代医学のプラグインであり、麻痺患者にとっては大きな賭けです。
清華大学、浙江大学、スタンフォード大学、ブラウン大学、ジョンズ・ホプキンス大学およびその他の国内外の大学は、ブレイン・コンピューター・インターフェースに関する関連研究を行っています。この記事では、コンセプトから始まり、ブレイン・コンピュータ・インターフェースの3つの主要な実装形態、国内外の有名大学の具体的な研究事例、ブレイン・コンピュータ・インターフェースの倫理と安全性について紹介します。
レポート全体を表示します。https://go.hyper.ai/W3pPf
4. 天文学のトップジャーナルである MNRAS に参加してください!中国科学院の上海天文台は AI を使用して 99.8% の検出精度で 107 件の中性炭素吸収線を発見しました
中国科学院上海天文台の研究者、Ge Jian氏のチームは、ディープラーニング手法を使用して、スローン・スカイ・サーベイの第3段階で発表されたデータの中から中性炭素吸収線を検索し、その組成の謎を明らかにした。宇宙初期の銀河内の冷たいガス雲の研究を行い、宇宙初期の中性炭素吸収線の 107 例を発見しました。この記事は、研究の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/qirkz
人気のある百科事典の項目を厳選
1. エポック
2. 神経放射線場 NeRF
3. スケーリングの法則
4. YOLOv10 リアルタイムのエンドツーエンドのオブジェクト検出
5. コルモゴロフ・アーノルド・ネットワーク
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
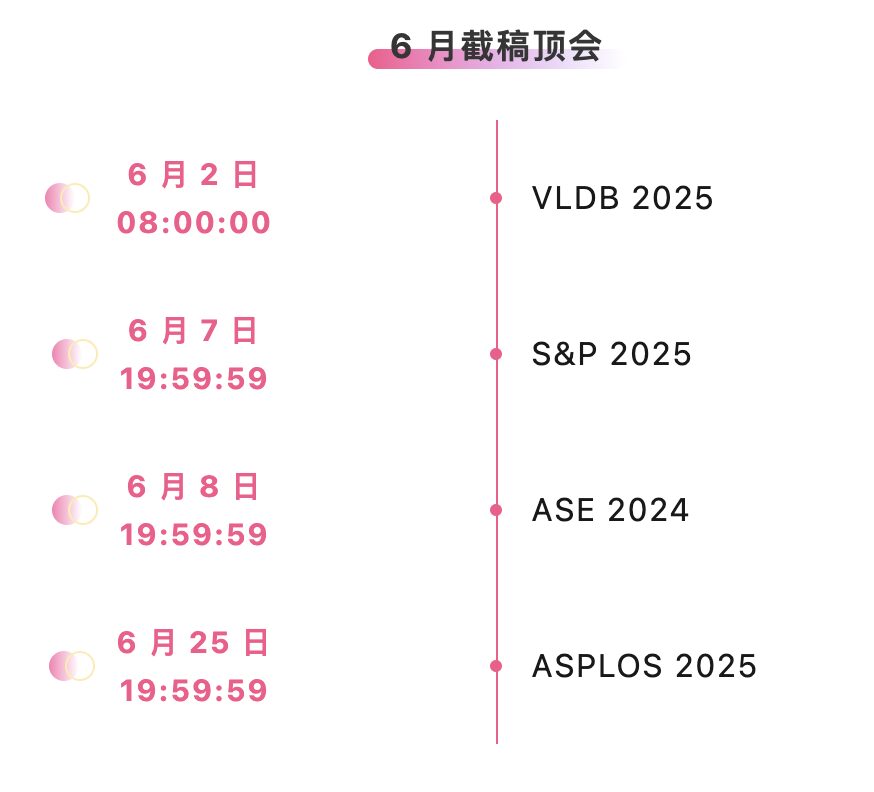
主要な人工知能学会をワンストップで追跡:
https://hyper.ai/events
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
* 1,200 を超える公開データセットに対して国内の高速ダウンロード ノードを提供
* 300 以上の古典的で人気のあるオンライン チュートリアルが含まれています
* 100 以上の AI4Science 論文ケースを解釈
* 500 以上の関連用語クエリをサポート
*Apache TVM の最初の完全な中国語ドキュメントを中国でホストします
学習の旅を始めるには、公式 Web サイトにアクセスしてください。








