Command Palette
Search for a command to run...
トップ天文学雑誌 MNRAS に掲載されました!中国科学院の上海天文台は AI を使用して 99.8% の検出精度で 107 件の中性炭素吸収線を発見しました

人々は星を見上げますが、その遠くにある星の光は実際に数十億年の時空を旅して、古代の物語を伝えています。中性炭素吸収線は、初期の銀河における冷たいガス雲の重要なプローブであり、その存在は人々に星の謎を覗き込むための窓を提供します。
星の進化の過程で、星の爆発によって放出される物質には豊富な化学元素が含まれており、これらの元素は星の内部で核融合反応を起こし、爆発とともに周囲の空間に拡散します。その中で、炭素、酸素、ケイ素、その他の元素を含む星間塵も、爆発が広がるにつれて星間物質中に濃縮され、新しい星や惑星系の形成に重要な物質的基盤を提供するだけでなく、星間物質を冷却して凝縮させます。星間物質はその過程で重要な役割を果たします。
研究によると、さまざまな星間物質では、波長 1560 および 1656 の中性原子炭素 (CI) の吸収線を使用して、大量の冷たいガスを検出でき、それによって分子雲、星間塵、星の形成が明らかになります。しかし、CI 吸収線を含むクエーサー スペクトルの現在のサンプル サイズは小さすぎて、全体的な化学存在量の進化と初期宇宙における銀河の進化を理解するための強力なツールとはなりません。
最近、中国科学院上海天文台の研究員格建氏が率いる国際チームは、ディープラーニング手法を使用して、スローン計画の第 3 段階で発表されたデータの中から中性炭素吸収線 (CⅠ吸収線) を検索しました。 Sky Survey により、初期宇宙の銀河の内部冷却が明らかになり、ガス雲の組成の謎が明らかになりました。宇宙初期の中性炭素吸収線が 107 件発見されました。この発見は、宇宙初期の銀河の進化に対する人々の理解を新たにするだけでなく、天文学研究における人工知能の大きな可能性を証明するものでもあります。関連する研究結果は、王立天文学協会 (MNRAS) の月刊通知に掲載されています。
研究のハイライト:
- この研究では、修正された深層学習アルゴリズムを使用して、Mg II 吸収線をマーカーとして使用して CI 吸収線を検索します。
- この研究では、宇宙初期の中性炭素吸収線が107件発見され、得られたサンプル数は、これまでに得られたサンプルの最大数のほぼ2倍でした。
- この研究により、これまでよりも多くの微弱な信号を検出できるようになり、宇宙や銀河の初期進化に関する将来の研究に新たな研究手法が提供されることになります。

用紙のアドレス:
https://doi.org/10.1093/mnras/stae799
データセット: Mg II 吸収線をマーカーとして使用して、500 万個のランダムサンプルが生成されます。
C Ⅰ吸収線は検出が難しいため、この研究では探索範囲を狭め、Mg Ⅱ吸収線を持つことが知られているQSO(準恒星天体、クエーサー)のみを調査し、他の原子を発見するための基礎としてMg Ⅱ吸収線を使用しました。種の摂取のために。さらに、この研究では 1.3 を研究することを選択しました。これにより、検索対象の総数は約 14,000 件に削減されます。
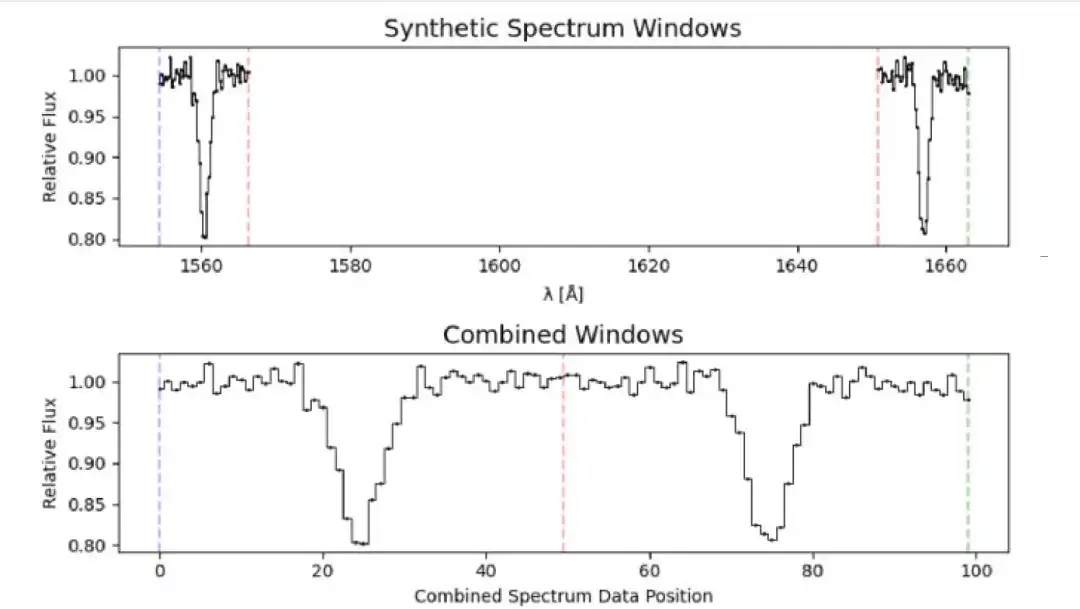
2 つの C Ⅰ 吸収線は通常非常に弱くまれであることを考慮すると、1560 Å と 1656 Åare の残りの波長内では互いに大きく離れており、これがディープ ニューラル ネットワークの検索の困難さを高めています。したがって、本研究は「フェイクダブレット法」を革新的に提案した。2 本の C Ⅰ 吸収線の周囲のスペクトル領域の一部を抽出して、疑似タイプの C Ⅰ 二重吸収線を形成できます。
2 つの 12 Å ウィンドウを結合して 100 素子長の一次元フラックス アレイを形成すると、吸収線間の波長範囲全体を排除しながら、局所的なスペクトル特性と信号ノイズを明確に表示できるため、サンプル サイズと計算要件が削減されます。その後、深層学習プログラムで Mg II と Ca II の二重吸収線を簡単に検索できます。ニューラル ネットワークを適切にトレーニングすると、クエーサー スペクトル内の不飽和 CI 二重吸収線を検索できます。
Mg II 吸収線の吸収赤方偏移値の不確実性により、実際の検索で使用されるスペクトルには最大約 ±0.25 Å の波長偏差が含まれる場合があります。この目的を達成するために、この研究では、生成された各サンプルの CI 吸収線に同じ範囲のランダム オフセットを適用し、同数の陽性サンプルと陰性サンプルを含む合計 500 万個のサンプルを生成しました。このうち、陽性サンプルには 2 つの CⅠ 吸収線が含まれており、分散パラメータは 0.05 ~ 0.8 Å の範囲の一様分布からランダムに抽出されます。陰性サンプルには CⅠ 吸収線が含まれておらず、分散パラメータは均一な分布からランダムにサンプリングされた 0.2 ~ 1.0 Å の範囲。
トレーニング データ セット内のノイズをシミュレートするために、この調査ではガウス分布からサンプルをランダムに抽出し、三角分布からサンプリングすることによって各スペクトルに信号対ノイズ比 (SNR) を割り当てます。このプロセスの結果、トレーニング セットの平均 S/N 比は約 8.0 となり、SDSS DR12 の 100,000 QSO スペクトルの平均 S/N 比 8.4 に非常に近づきました。同時に、この研究では、弱い CI 吸収線を検出するモデルの能力を強化するために、合成データセットの S/N 比を意図的に低い値に偏らせました。
モデルの構築: モデルの精度は 99.8% と高く、畳み込みニューラル ネットワークが非常に有効であることが確認されています。
この研究の畳み込みニューラル ネットワーク モデルは、各入力スペクトル内の 2 つの CI 吸収線を識別するように設計されました。モデルは、単一の畳み込み層、正規化層 (バッチ正規化)、平坦化層 (平坦化層)、および 3 つの密な層 (密層) を含む、いくつかの主要なコンポーネントで構成されます。
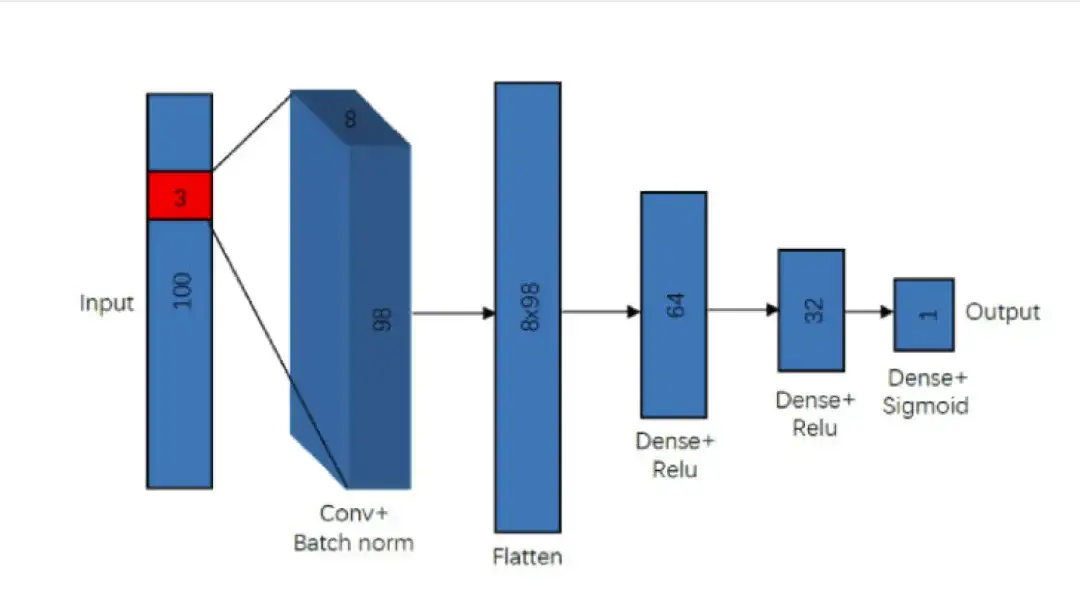
この研究では、モデルに入力する前に各スペクトルに対してノイズ正規化を実行し、モデルのノイズの影響を効果的に排除しました。ノイズ正規化の後、フラックス値を 0 ~ 1 の範囲に保つために、結果を 30 で割って 0.5 を加算することも検討しました。これにより、モデルの最初の層 (畳み込み) のデータが正規化され、部分的に役立ちます。第 2 層の仕様の一貫性 (バッチ正規化)。
畳み込み層は主にスペクトル線とその位置を検出するために使用されます。広範な実験とテストの結果、8 つのフィルターと 3×3 のカーネル サイズを備えた単一の畳み込み層で十分であることがわかりました。
畳み込み後、サンプルは正規化レイヤー (バッチ正規化) を通過し、データが後続の Dense レイヤー (Dense レイヤー) の正しい値の範囲内にあることを確認します。 Flatten 層は主に入力を「平坦化」するために使用されます。つまり、畳み込み層からの多次元特徴出力を 1 次元ベクトルに取り込むために使用されます。
モデルの最初の 2 つの高密度層は両方とも線形活性化関数 (ReLU) を使用し、ドロップアウト層が割り当てられます。同時に、出力層も、シグモイド活性化関数を使用して、ニューロンを 1 つだけ含む高密度層になります。この比較的シンプルな設計は、トレーニングと検索が非常に高速であると同時に、優れた検出精度を提供します。
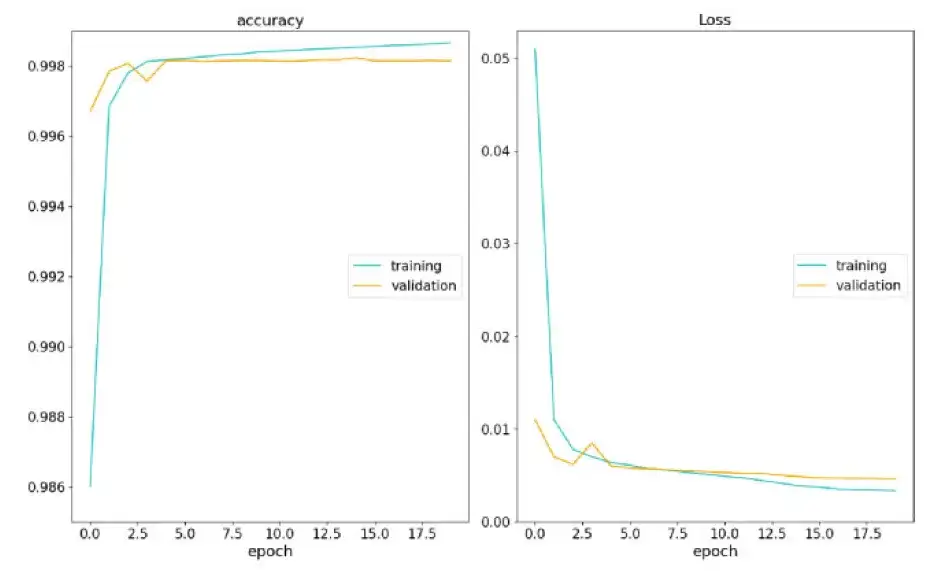
それ以来、モデルは合計 20 回の反復を受けてきました。各反復では、すべてのトレーニング サンプルが 32 個のグループでモデルに渡されます。全体として、モデルの精度は 99.8% です。この高い精度は、畳み込みニューラル ネットワークがスペクトル内の CI 吸収線の検出に非常に効果的であることを証明しています。
研究結果: 107 個の CI 吸収線が選択され、CNN は弱い信号を探索する無限の可能性を秘めています。
この研究では、訓練された CNN を最終的に使用して、1.3 < Z(abs) < 2.7 の間の赤方偏移を持つクエーサーに焦点を当てて、Mg II カタログから 14,509 個のクエーサー スペクトル データ セットを検索しました。
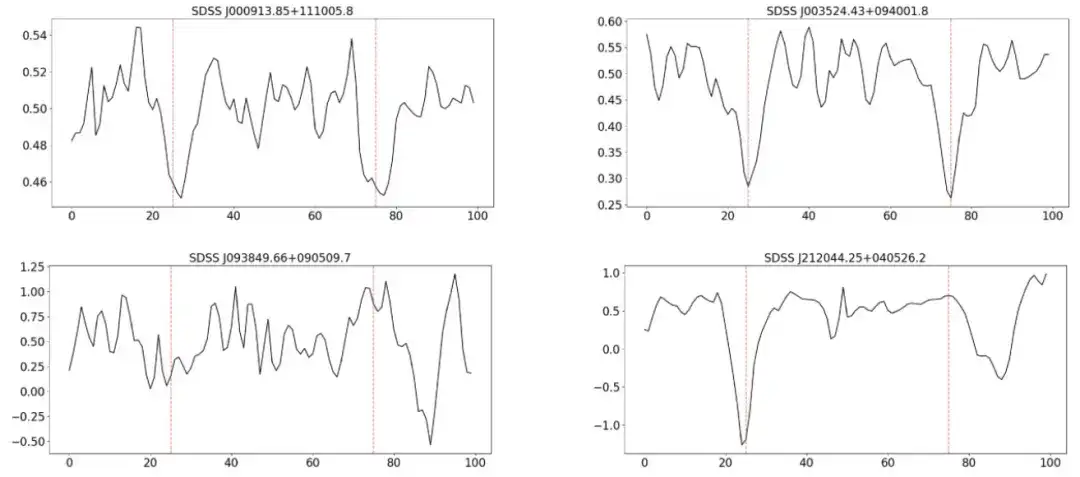
吸収線を検出および選択する手順は次のとおりです。
初期の CNN 認識
CNN はバイナリ分類器として導入され、この研究では 14,509 個のクエーサー スペクトルが 0 から 1 までのスコアで評価されました。 0.5 閾値を超えるスコアを持つスペクトルは CI 吸収線候補として分類され、この方法によるさらなる分析のために合計 2,056 個の候補サンプルが選択されました。
手動検査とライン検証
この研究ではさらに、正確な波長と隣接する吸収特性との違いに焦点を当て、手動検査によって CI 吸収線を検証しました。 CI ラインが適切に配置されている場合でも、そのデュアルが大きく逸脱している場合、これらも除外されます。最終的な候補サンプルは 400 個に減りました。
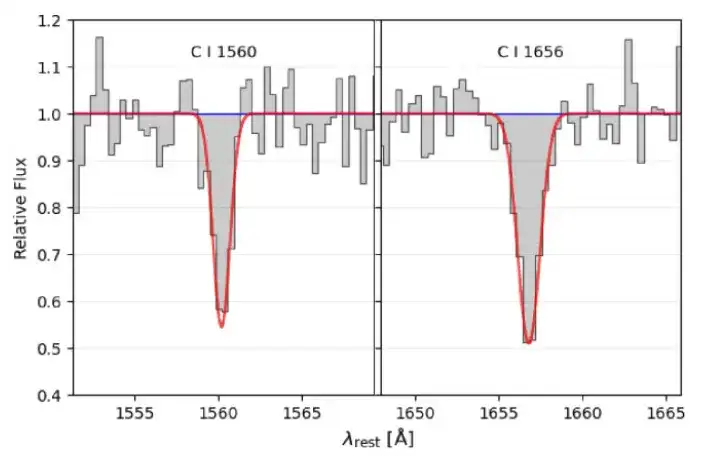
詳細なスペクトル線フィッティングと信号対雑音比の計算
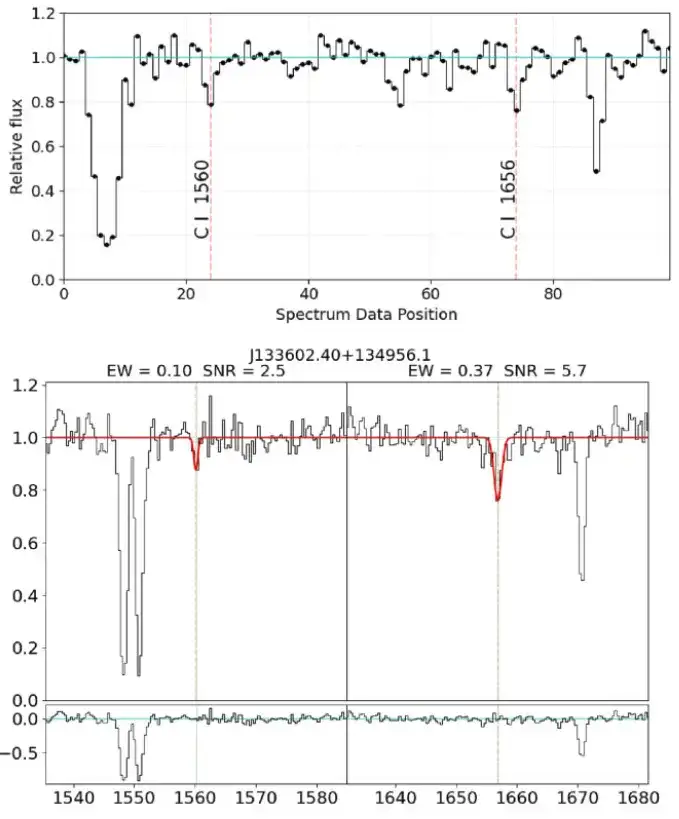
一次元ガウス モデルを使用して、候補 CI 吸収線をフィッティングしました。これは 2 つの重要な基準に基づいています。第 1 に、λ1656 の静的等価幅 W は λ1560 より大きくなければなりませんが、λ1560 が 3 σ 信頼区間内にある限り、W(λ1560) は W(λ1656) を超えることが許可されます。 、最小許容信号対雑音比はそれぞれ 2.5 と 3 です。これらの基準によれば、候補サンプルの範囲は 142 に絞り込まれます。
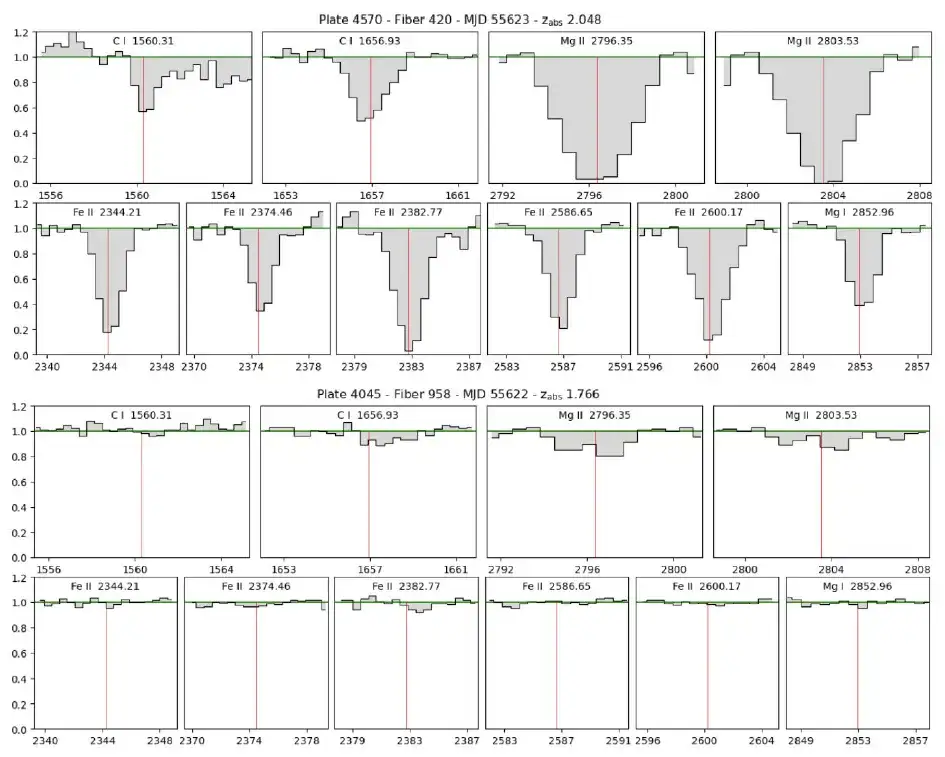
目視検査とスペクトル線の相互参照
残りの各候補材料は最終的な視覚検査を受け、具体的には追加のスペクトル線が CI 線の相対強度と一致するかどうかを検査しました。この研究では、CI ラインが顕著であるものの、他のすべてのスペクトル ラインが欠落している候補サンプルを除外しました。最終候補サンプルは合理化され、107 件の炭素吸収性テストの最終カタログが作成されました。以下の表は、いくつかの CI 吸収線を示しています。
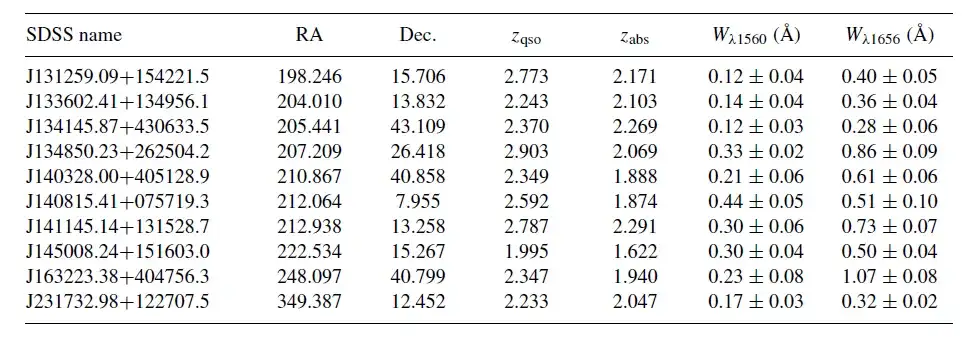
この研究では、ターゲット名、座標、赤方偏移、静的等価幅などの詳細とともに、最終カタログに 10 種類の炭素吸収体がリストされています。結果は、最も強い炭素吸収体の W(λ1656) が 1.92 Å であるのに対し、最も弱い炭素吸収体の静的等価幅は 0.1 Å であることを示しています。同時に、CNN トレーニング方法により、全体的な CI 吸収線の等価幅がより小さくなり、より低い赤方偏移で CI 吸収線を検出できます。
この研究では、CNN 法を効果的に使用して、広い波長を持つ 2 つの弱い炭素吸収線を検出できることも示しました。この方法は、クェーサーのスペクトル内の他の多くの線、または同様の連続スペクトル (恒星のスペクトルなど) を持つ他の線が互いに大きく離れており、吸収線または輝線の任意の組み合わせを検索するためのさまざまな研究において重要であることを考慮して採用できます。
天文学分野における AI アプリケーションは、人類が星や海に向かって移動するのに役立ちます
実際、Ge Jian 教授の最新の研究は、天文学分野における AI テクノロジーの応用における氷山の一角を明らかにしたにすぎません。天文学が発展し続けるにつれて、膨大なデータ管理から深宇宙探査における正確なナビゲーション、遠方の銀河の詳細な研究まで、私たちが直面する課題はますます複雑になり、そのすべてに従来の手法を超えたソリューションが必要です。
AI テクノロジーの導入は、天体観測によって生成された膨大なデータセットを処理および分析できるだけでなく、パターン認識、予測モデリング、自動観測において重要な役割を果たし、宇宙に関する知識の限界を大幅に拡大します。
ここ数年、研究者は宇宙を理解するために AI をますます活用し始めています。 2022 年、米国エネルギー省のアルゴンヌ国立研究所のコンピューター科学者は、シカゴ大学、イリノイ大学アーバナ シャンペーン校、NVIDIA、IBM などの機関と協力して、AI とスーパーコンピューターを組み合わせました。1カ月分のデータを7分以内に処理し、ブラックホールの合体によって生成される4種類の重力波信号も特定した。
2023年マスク氏が正式に設立 xAI 宇宙の本質を理解することを目標とする会社です。マスク氏はかつてインタビューで、「ある意味、宇宙を理解しようとする人工知能が人間を絶滅させる可能性は低い。なぜなら、私たちは宇宙の興味深い部分だからだ。今年5月、xAI社は6ドル以上を受け取った」と語った。 10億ドルのシリーズB資金調達により、設立から10か月足らずの同社の評価額は約180億米ドルとなった。
2024 年 4 月中国科学院国立天文台の人工知能作業グループは、新世代の天文モデル「Star Language 3.0」を発表した。Tongyi Qianwen オープンソース モデルに基づいて、国立天文台の興隆天文台望遠鏡アレイ Mini Sitian に接続することに成功しました。これは科学分野における大型モデルの典型的な事例であり、天体観測分野における大型モデルの初めての応用でもあります。
広大な宇宙では、常に未知のものが既知の領域よりも大きいように見えますが、AI の探求はすでに目覚ましい成果を上げ始めています。テクノロジーが成熟し続けるにつれて、AI は将来、宇宙に関するさらなる謎を明らかにし、人類が宇宙をより深く理解できるようになり、私たちを星の海へと導くだろうと信じる理由があります。








