Command Palette
Search for a command to run...
オンラインチュートリアル丨ソラのテクニカルルートに似ています!世界初のオープンソース Wensheng Video DiT モデル Latte をワンクリックで導入可能

OpenAI が Sora を発表して以来、「Vincent Video」のコンセプトと関連アプリケーションが大きな注目を集めています。そしてソラの人気に伴い、その背後にあるキーテクノロジーであるDiT(Diffusion Transformers)も「考古学的に発掘」されています。

実際、DiT は 2 年前にオープンソース化された Vincentian ダイアグラム モデルであり、その開発者は Peebles と Xie Senin であり、Peebles は Sora のプロジェクト リーダーの 1 人でもあります。
DiT モデルが提案される前は、Transformer はその強力な特徴抽出機能とコンテキスト理解機能により、自然言語処理の分野をほぼ独占していました。 U-Net は、その独自のアーキテクチャと優れたパフォーマンスにより、画像生成および拡散モデルの分野を支配しています。 DiTの最大の特徴は、普及モデルにおけるU-NetアーキテクチャをTransformerアーキテクチャに置き換えたことにある。興味深いことに、この研究の結果は、イノベーションの欠如を理由に 2023 年に CVPR によって拒否されました。
U-Net と比較して、Transformer はグローバルな依存関係を学習し、セルフ アテンション メカニズムを通じてシーケンス データの長距離の依存関係を処理でき、画像のグローバルな特徴を処理する際に大きな利点があります。さらに、Transformer アーキテクチャに基づく DiT は、計算効率と生成効果も大幅に向上し、画像生成の大規模アプリケーションをさらに促進します。
ただし、ビデオ データは高度に構造化され複雑な性質を持っているため、DiT をビデオ生成の分野にどのように拡張するかが課題です。この点について、上海人工知能研究所の研究チームは、2023 年末に世界初の Vincent ビデオ DiT: Latte をオープンソース化しました。 Latte は、Sora テクノロジーと同様の自社開発モデルとして、自由に展開できます。Wensheng ビデオ テクノロジーを探求したい人にとって、オープンソースの Latte は間違いなく誰にでも練習する機会を提供します。
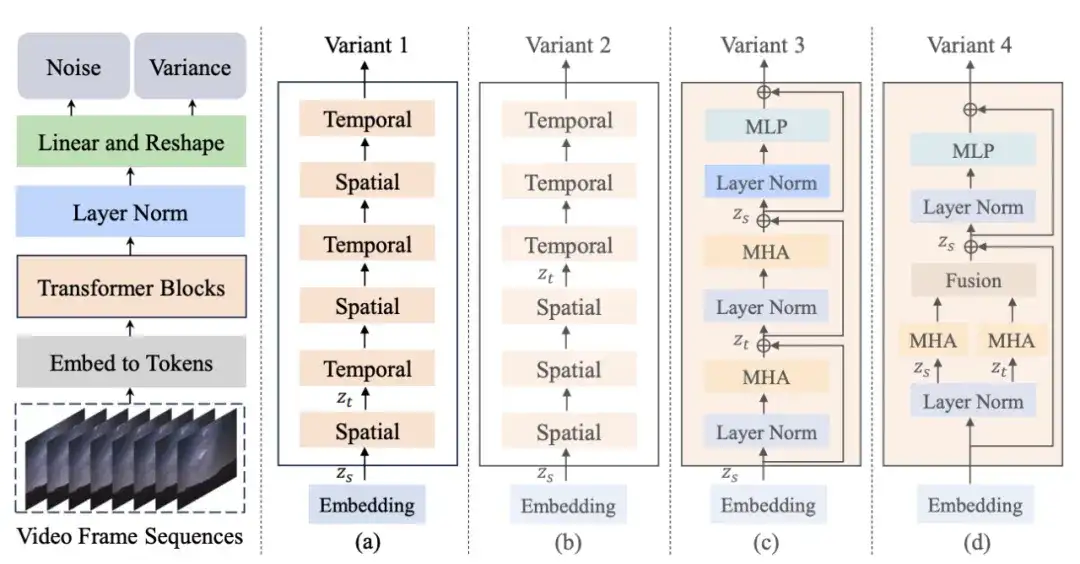
まず、Latte は、事前トレーニングされた変分オートエンコーダー (VAE) を通じて入力ビデオを潜在空間の特徴にエンコードし、そこからトークンを抽出します。次に、これらのトークンは、上記のいずれかのバリエーションの対応する Transformer 構造を使用してエンコードおよびデコードされます。生成プロセス中、モデルは学習した逆拡散プロセスに基づいて潜在空間内の低ノイズのビデオ フレーム表現を徐々に復元し、最終的にそれを連続的でリアルなビデオ コンテンツに再構築します。
Latteの研究開発チームである上海人工知能研究所が中国中央ラジオテレビと協力して、両社は共同で初の中国オリジナルVincent Video AIシリーズアニメーション「千秋の詩への頌歌」を立ち上げ、CCTV-1総合チャンネルで放送された。業界関係者らは、中国初のAIアニメーションの発表により、将来的には我が国の文生ビデオアプリケーションの導入が加速し、映画・テレビ業界の制作プロセスが再構築され、映画・テレビの革命的発展が促進される可能性があると分析している。テレビアニメ制作、ゲーム開発、広告デザインなど。
これに関連して、より多くのクリエイティブ ワーカーや文生ビデオ愛好家がテクノロジーのトレンドに追いつくことができるよう、HyperAI Super Neural は、「Latte 世界初のオープンソース Vincent Video DiT」チュートリアルを開始しました。このチュートリアルでは、誰もが利用できる環境をセットアップしました。モデルがダウンロードされてトレーニングされるまで待つ必要はなくなり、ワンクリックでモデルを開始し、テキストを入力して即座にビデオを生成できます。
チュートリアルのアドレス:https://hyper.ai/tutorials/32065
編集者は「サングラスをかけた犬」というテキストを使用して、サングラスをかけた犬のビデオを生成しました。これは非常にハンサムです。

デモの実行
1. hyper.ai にログインし、「チュートリアル」ページで「Latte、世界初のオープンソース文生ビデオ DiT」を選択し、「このチュートリアルをオンラインで実行する」をクリックします。

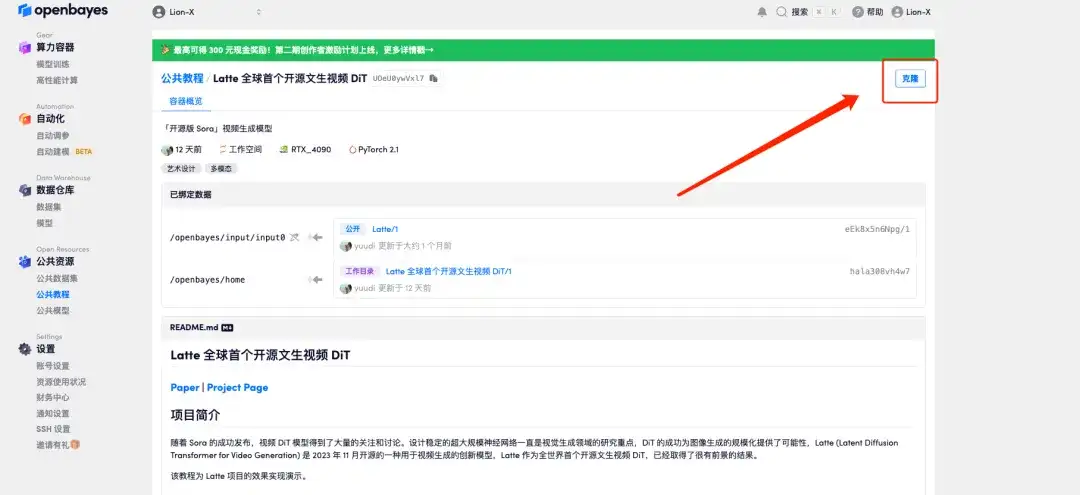
2. ページがジャンプしたら、右上隅の「クローン」をクリックしてチュートリアルを独自のコンテナにクローンします。
3. 右下隅の「次へ: コンピューティング能力の選択」をクリックします。
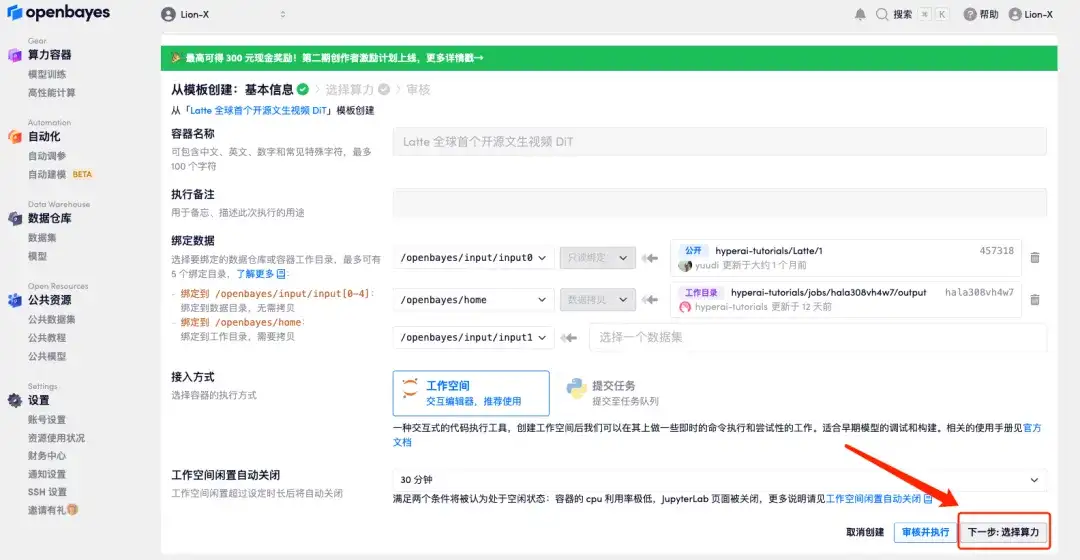
4. ジャンプ後、「NVIDIA GeForce RTX 4090」を選択し、「次へ: 確認」をクリックします。以下の招待リンクを使用してサインアップした新規ユーザーは、4 時間の RTX 4090 + 5 時間の CPU を無料で入手できます。
HyperAI ハイパーニューラルの専用招待リンク (ブラウザに直接コピーして開きます):https://openbayes.com/console/signup?r=6bJ0ljLFsFh_Vvej
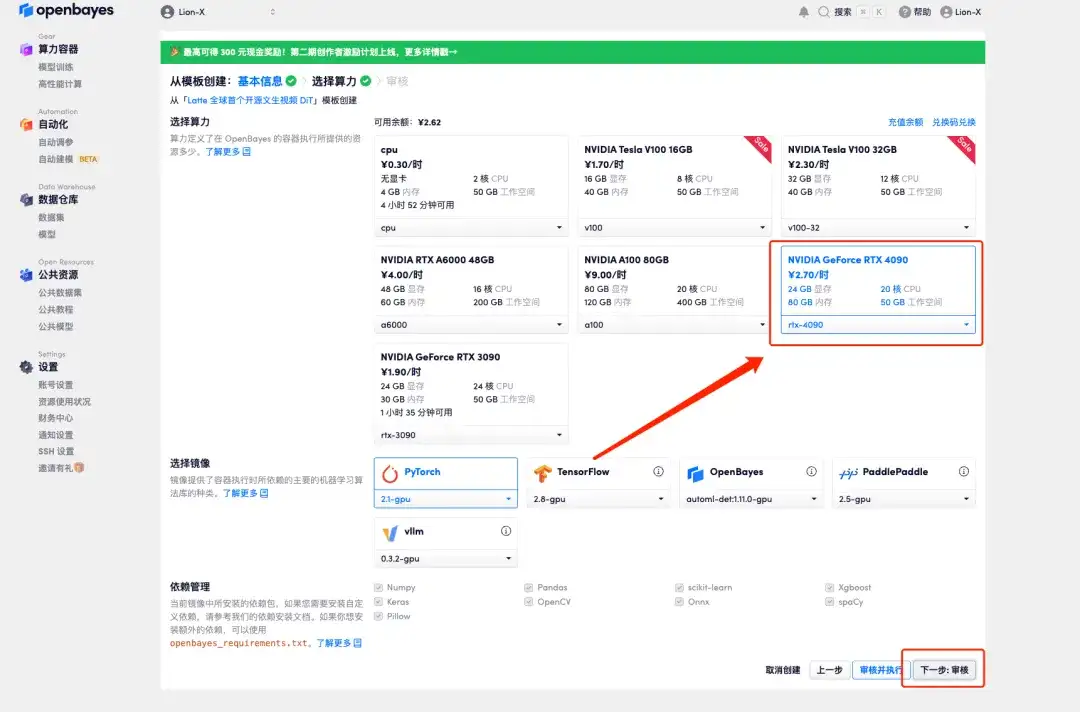
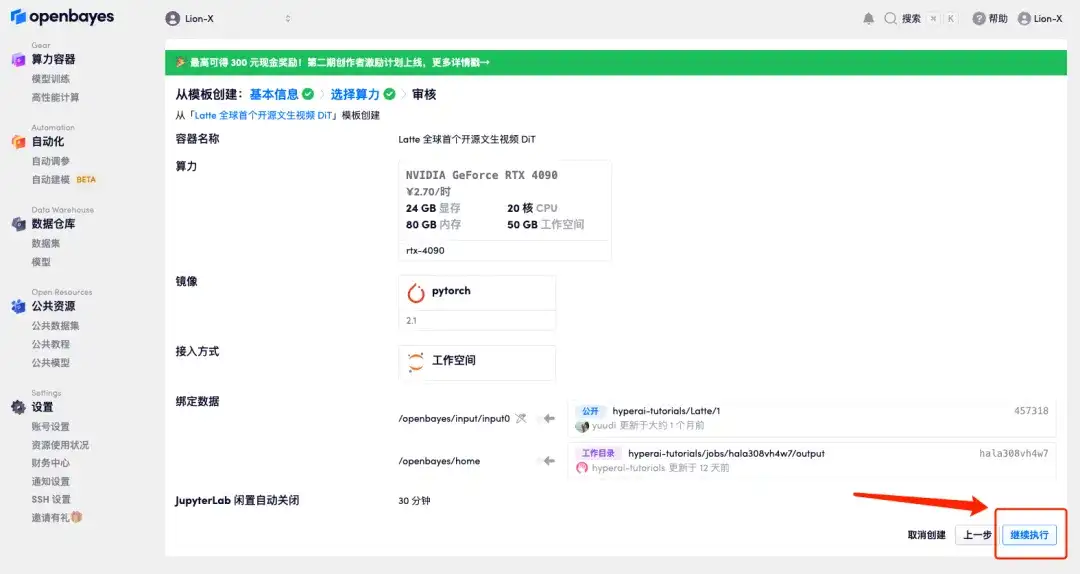
5. [続行] をクリックし、リソースが割り当てられるまで待ちます。最初のクローンには約 3 ~ 5 分かかります。ステータスが「実行中」に変わったら、「ワークスペースを開く」をクリックします。
10 分以上「リソースを割り当てています」状態が続く場合は、コンテナを停止して再起動してみてください。再起動しても問題が解決しない場合は、公式 Web サイトのプラットフォーム カスタマー サービスにお問い合わせください。
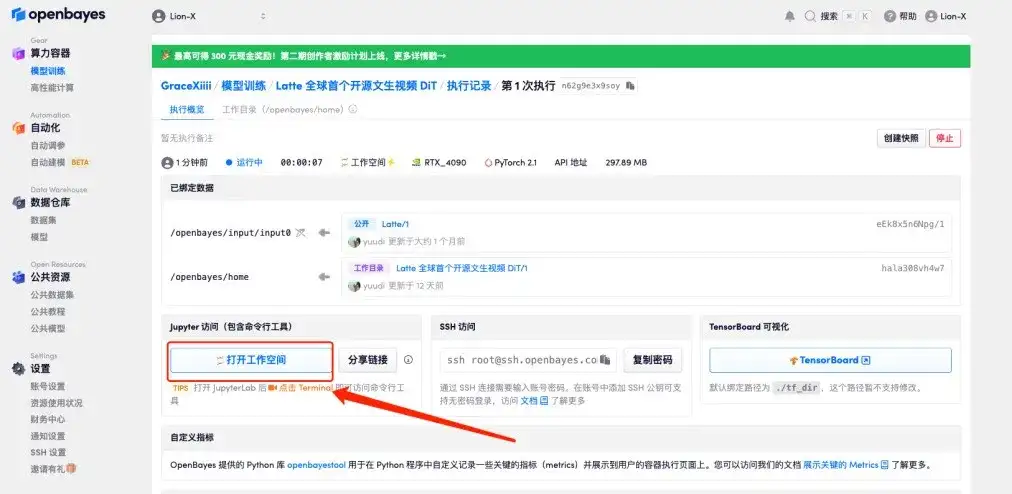
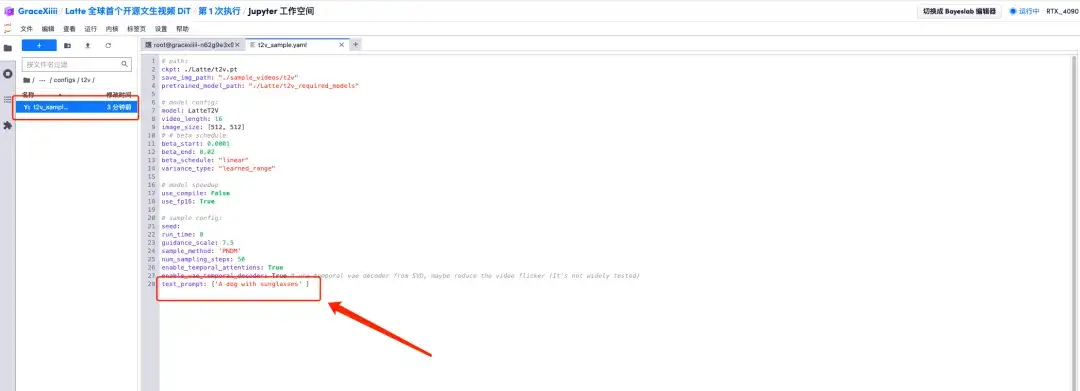
6. ワークスペースを開いた後、左側のメニューのパスに従って構成ファイル home/Latte/configs/t2v/t2v_sample.yaml を開き、text_prompt の下にプロンプト「例: サングラスをかけた犬」を入力し、保存します。 Ctrl+S。
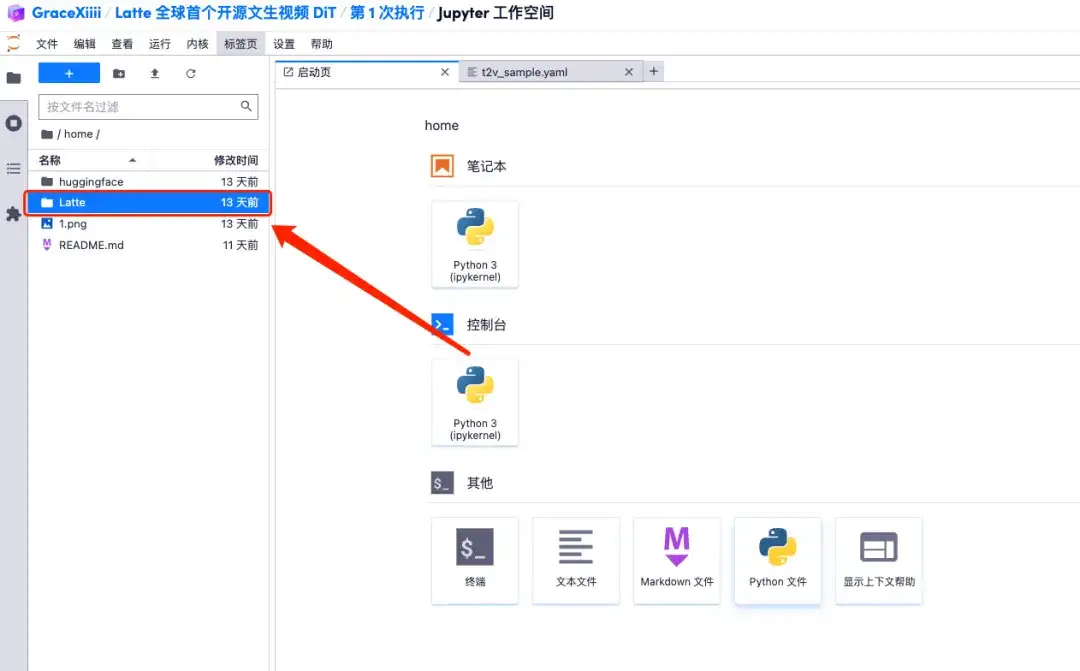
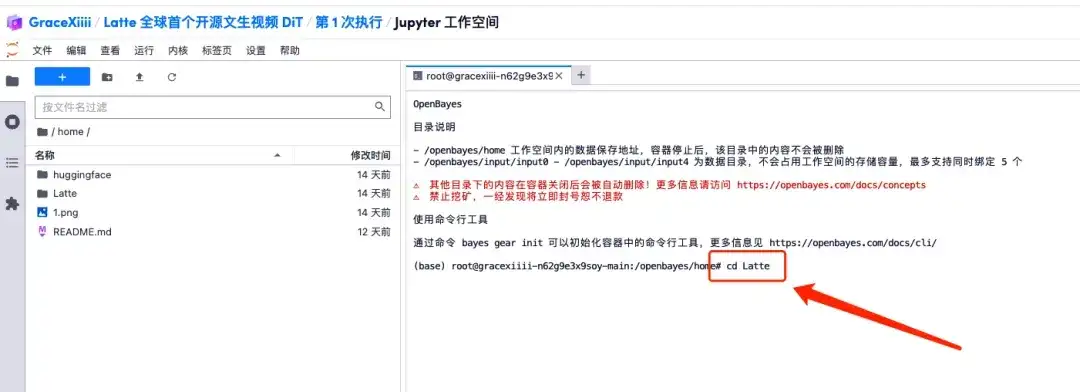
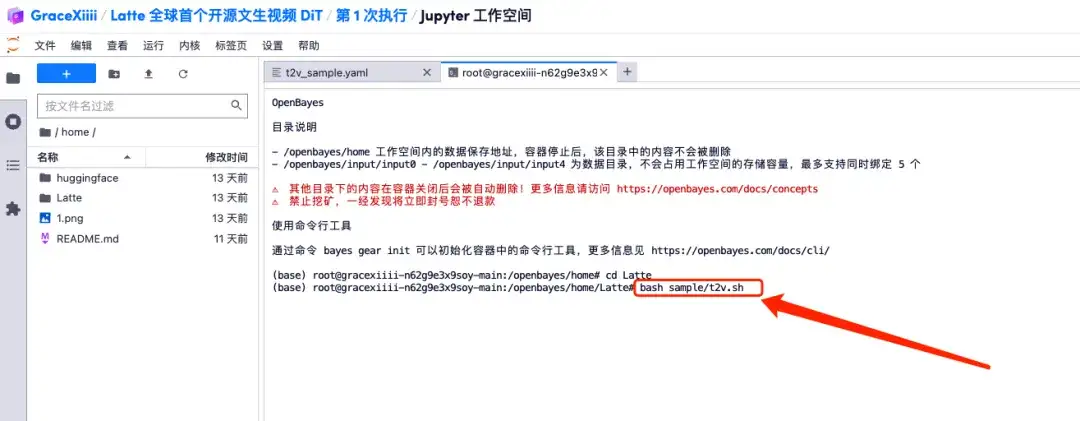
7. 保存後、新しい端末ページを作成し、「cd Latte」と入力して Enter キーを押し、「Latte」ディレクトリに入ります。 「bashサンプル/t2v.sh」と入力して、高解像度ビデオを生成します。
エフェクト表示
1. プログレスバーに「100%」と表示されたら、左側のメニューバー「Latte/sample_videos」を開き、生成したビデオを見つけて右クリックしてダウンロードします。MP4 ビデオは直接視聴できないため、視聴する前にダウンロードする必要があることに注意してください。
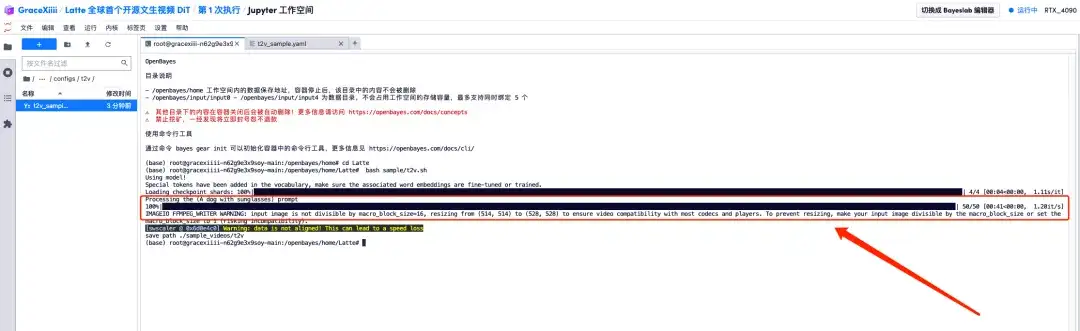
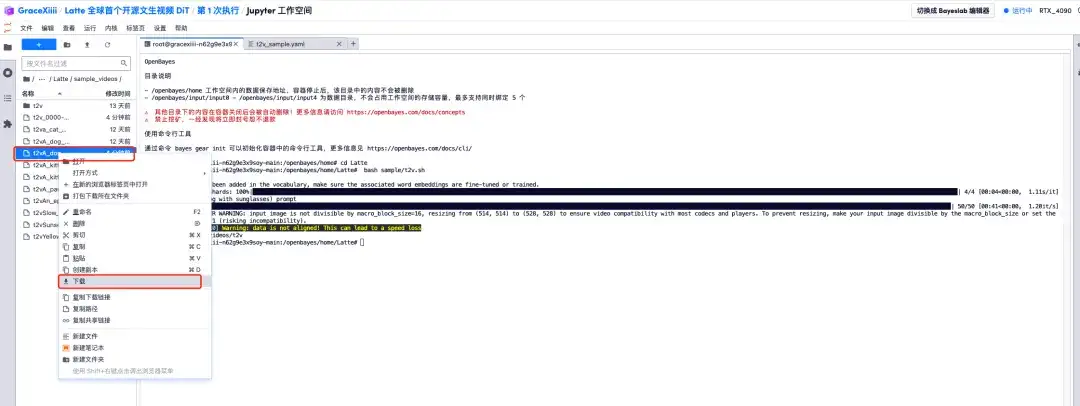
2. サングラスをかけた子犬の動画が生成されます!

現在、HyperAI 公式 Web サイトでは、Jupyter Notebook にまとめられた数百の厳選された機械学習関連のチュートリアルを公開しています。
リンクをクリックして、関連するチュートリアルとデータ セットを検索します。https://hyper.ai/tutorials
以上が今回 HyperAI Super Neural が共有したコンテンツのすべてです。高品質なプロジェクトを見つけたら、バックグラウンドでメッセージを残してください。さらに、「安定拡散チュートリアル交換グループ」も設立しており、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりするために、友人がグループに参加することを歓迎します。








