Command Palette
Search for a command to run...
AI4S に関する Li Feifei チームの最新の洞察: 生物学、材料、医療、尋問などをカバーする 16 の革新的なテクノロジーの概要

少し前のことですが、スタンフォード大学ヒューマンセンター人工知能(HAI)研究センターは、「2024年人工知能指数レポート」を発表した。スタンフォード HAI の 7 番目の傑作であるこの 502 ページのレポートは、2023 年の世界の人工知能の開発動向を包括的に追跡しています。例年に比べ、AI技術の基本動向、AI技術に対する世論、開発をめぐる政治的動きなど、研究対象を拡大し、今後のAI開発動向の予測を行っています。

哲学者のジョン・エチェマンド氏(左)が共同指導者
今回のレポートで最も目を引くのは新章――。科学と医学における人工知能の広範囲にわたる影響を探ります。このレポートでは、2023 年の科学分野における AI の輝かしい成果と、SynthSR や ImmunoSEIRA などの画期的なテクノロジーを含む医療分野における AI の重要なイノベーションが示されています。さらに、このレポートではAI医療機器に対するFDAの承認傾向の詳細な分析も提供されており、業界にとって貴重な参考資料となります。
公式アカウントをフォローし、バックグラウンドで「HAI2024」と返信すると、レポート全文がダウンロードできます
AI: 研究加速エンジン
「2024年人工知能指数レポート」では次のように述べられています。2023 年に、業界は 51 の有名な機械学習モデルを生み出しましたが、学術界が貢献したのは 15 モデルのみでした。さらに、新しくリリースされた 108 の基本モデルは産業界から、28 は学術から提供されています。
学術界の発展速度は産業界に比べて明らかに遅いですが、AIが科学的発見の分野で正式に使用されるのは2022年になることに注意する必要があります。アルゴリズム分類の効率を最適化する AlphaDev から、材料発見プロセスに革命をもたらす GNoME まで、私たちはより重要でより関連性の高い人工知能アプリケーションの出現を目の当たりにしてきました。
今日、AI は材料科学、気候変動、コンピューター サイエンスなどの多くの分野で開花しています。幸いなことに、中国はこの変化の先頭に立っている。中国科学技術情報院と科学技術部新世代人工知能開発研究センターがまとめた「中国AI科学イノベーションマップ研究報告書」によると、我が国の論文数は第1位となっている。 AI 主導の科学研究とローカライズされた AI 科学研究の基盤 ソフトウェアもますます成熟しており、研究者に豊富なデータセット、基本モデル、専門ツールを提供しています。
一般に、科学分野におけるAIの応用は多様化し、かつてないスピードで科学の発展・進歩を促進しています。ただし、科学用AIの現在の開発段階では、包括的な人材の不足、技術的ソリューションの再利用の難しさ、垂直分野における研究データの質の低さなどの問題も徐々に明らかになってきています。
例えば、「AI人材は科学研究に従事すべきか、それとも科学研究人材はAIを学ぶべきか」に関する議論では、学際的な知識の背景を持つ研究者が目立った。彼らは科学研究分野について深い洞察を持っているだけでなく、AIを学ぶことができる。さまざまな AI ツールやテクノロジーをすぐに使い始めることができますが、その希少性の程度は想像できるため、総合的な人材の育成は一夜にして実現するものではありません。したがって、AI と科学研究の間にコミュニケーションの橋をいかに迅速に構築するかは、科学のための AI の大規模な推進に関連する重要な問題です。
同時に、科学研究がカバーする豊富な分野について詳しく説明する必要はありません。異なる分野の背景を持つ研究者を擁することが難しい場合、研究グループによって研究の方向性が若干異なる場合があります。各チームでは AI ツールの使用の敷居が低くなり、モデルの微調整プロセスが簡素化され、科学研究分野での AI の推進がある程度加速される可能性があります。
テクノロジーの更新、自己反復、進歩を加速します
AI テクノロジーの進歩により、その応用範囲の広さと奥深さが促進されると同時に、アルゴリズムに対する要件もますます高くなりました。現在、ほとんどのアルゴリズムは、さらなる最適化を人間の専門家に依存することが困難な段階に達しており、その結果、計算上のボトルネックが増加しています。しかし、科学者たちはアルゴリズム分野の探究を決してやめませんでした。
アルファ開発
AlphaGo の魔法のタッチを再現
並べ替えアルゴリズムは、コンピューター システムがデータ項目を秩序だった方法で配置するための基本的なツールです。この分野で革新的なブレークスルーを達成するために、Google DeepMind は、コンピュータのアセンブリ命令という比較的研究の少ない領域を探索するという革新的なアプローチを採用しました。AlphaDev システムを通じて、DeepMind は CPU アセンブリ命令レベルから直接開始して、より効率的な並べ替えアルゴリズムを見つけることができます。
AlphaDev システムは、学習アルゴリズムと表現関数という 2 つのコア コンポーネントで構成されています。
学習アルゴリズムは高度な AlphaZero アルゴリズムを拡張し、深層強化学習 (DRL) とランダム検索最適化アルゴリズムを組み合わせて大規模な命令検索タスクを実行します。一方、表現関数は Transformer アーキテクチャに基づいており、最下位層をキャプチャできます。アセンブリ言語の構造を取得し、それを特別なシーケンス表現に変換します。
AlphaDevシステムを使用して、DeepMind は、現在の手動チューニング アルゴリズム、つまりソート 3、ソート 4、およびソート 5 よりも優れた固定長の短いシーケンスのソート アルゴリズムを発見し、関連するコードを LLVM 標準 C++ ライブラリに統合しました。特に注目に値するのは、ソート 3 アルゴリズムを発見する過程で、AlphaDev が、直感に反しているように見えて実際には近道だった方法を採用したことです。これは、AlphaGo が伝説的な囲碁棋士イ・セドルに対して使用した「ステップ 37」を思い出させます。予想外の戦略が最終的に勝利につながった。
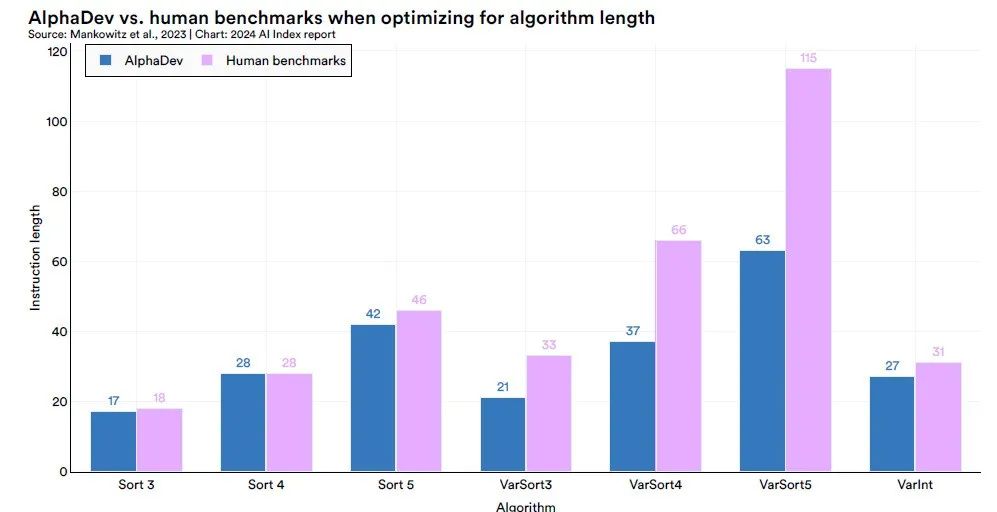
AlphaDev には、並べ替えアルゴリズム以外のアプリケーションもあります。 DeepMind は、その手法を一般化することで、9 ~ 16 バイト範囲のハッシュ アルゴリズムにも適用し、30% という大幅な高速化を達成しました。これは、AlphaDev が基礎となるコンピューティング タスクの最適化において幅広い可能性と応用価値を持っていることを示しています。
論文リンク:
https://www.nature.com/articles/s41586-023-06004-9
フレキシキューブ
AIを使用して高品質の3Dモデルを生成
シーンの再構築から生成 AI トラックに至るまで、新世代の AI モデルは、リアルで詳細な 3D モデルの生成において目覚ましい成功を収めています。これらのモデルは通常、標準の三角形メッシュとして作成されるため、メッシュの品質が重要です。この目的を達成するために、Nvidia の研究者は、3D ネットワーク生成パイプラインのメッシュ品質を大幅に向上させ、物理エンジンと統合して 3D モデルで柔軟なオブジェクトを簡単に作成できる新しいメッシュ生成方法 FlexiCubes を開発しました。
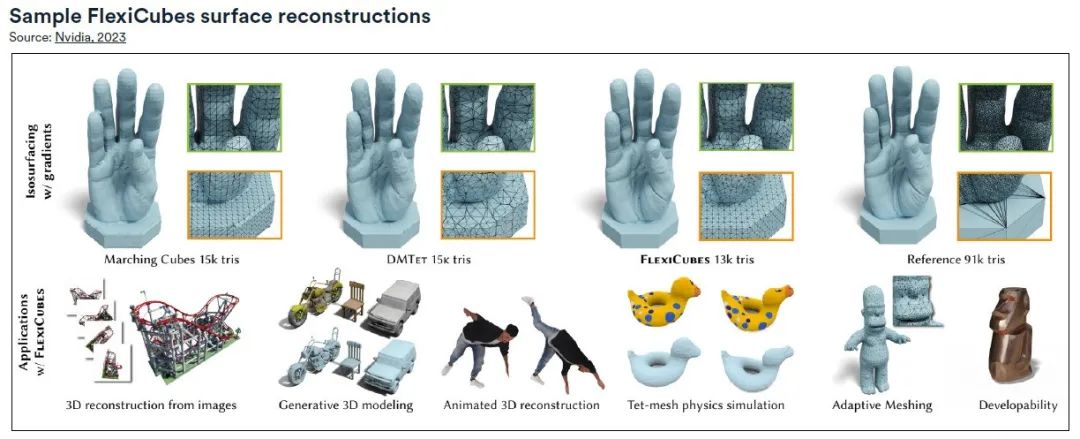
FlexiCube の重要なアイデアは、メッシュ生成中に正確な調整を可能にする「柔軟な」パラメータを導入することです。最適化プロセス中にこれらのパラメーターを更新することにより、メッシュの品質が大幅に向上します。このアプローチは、FlexiCube を、広く使用されている Marching Cubes アルゴリズムなどの従来のグリッドベースのパイプラインと対比させ、最適化ベースの AI パイプラインをシームレスに置き換えることができます。
FlexiCube によって生成された高品質のメッシュは、複雑な詳細の表現に優れており、AI で生成された 3D モデルの全体的なリアリズムと忠実度が向上します。これらのメッシュは物理シミュレーションで特に役立ち、写真測量や生成 AI などの分野で AI パイプラインが複雑な形状の詳細を正確にレンダリングできるようになります。
論文リンク:
https://research.nvidia.com/labs/toronto-ai/flexicubes
人力を超えた創造の加速と効率の向上
シンボット
AI を活用したロボット化学者
化学研究室の奥深くでは、革命が静かに進行中です。有機化合物の合成はもはや時間のかかる退屈なプロセスではなく、自動化の魔法によって加速されて現実のものとなります。この革命の中核となるのは、サムスン電子の科学者によって作成された自律型合成ロボット、Synbot です。
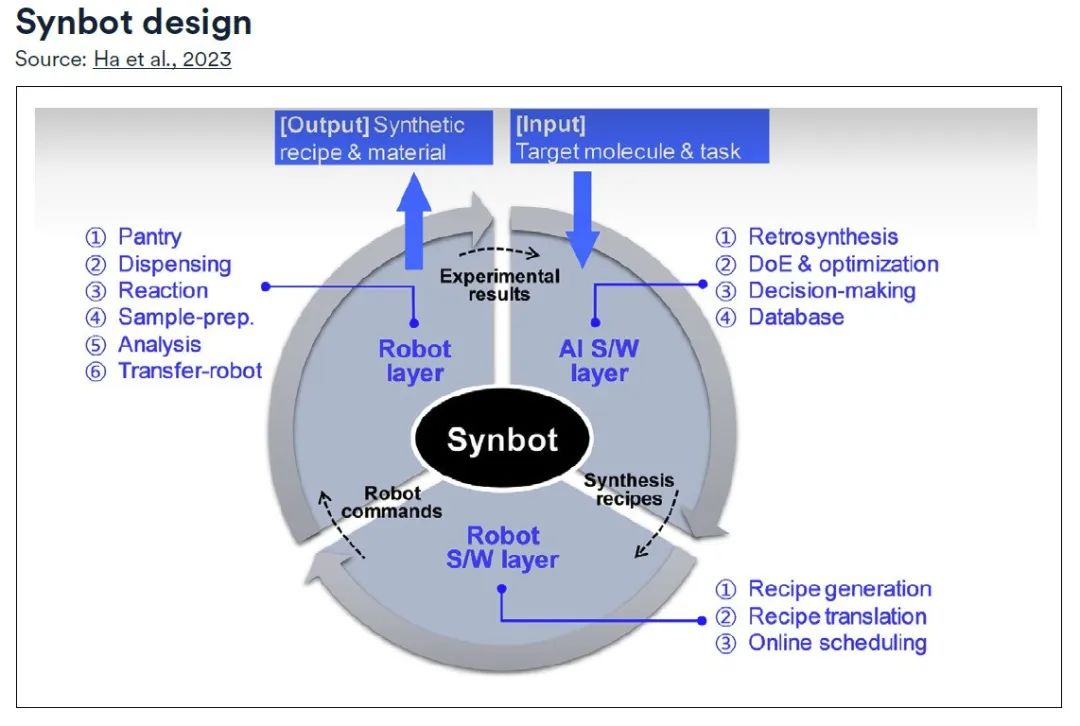
具体的には、Synbot は 3 つのレイヤーで構成されています。
※人工知能ソフトウェア層(AI S/W層):逆合成モジュール、実験計画および最適化モジュールを備えた包括的な計画プロセスを主導し、意思決定モジュールを使用して実験の方向性を導きます。
* ロボット S/W 層:レシピ生成モジュールと変換モジュールを通じて、それをロボットが操作可能なコマンドに変換する責任を負います。* ロボット層:オンラインスケジューリングモジュールの監督下で、合成ラボのさまざまな機能がモジュール化され、計画されたレシピが体系的に実行され、事前に定義された目標が達成されるまでデータベースが継続的に更新されます。
研究によると、Synbot は 24 時間で平均 12 件の反応を実行できます。人間の研究者がそのような実験を 1 日に 2 回実施できると仮定すると、Synbot は人間の研究者より少なくとも 6 倍効率的です。Synbot を追加することで、科学者は退屈な作業から解放され、イノベーションと探求により多くのエネルギーを注ぐことができます。
論文リンク:
https://www.science.org/doi/full/10.1126/sciadv.adj0461
GNoME
材料発見プロセスの再発明
Google DeepMind は Nature に次のような記事を掲載しました。材料探索に基づく AI ツールである GNoME (Graph Networks for Materials Exploration) は、38 万の安定した結晶構造を含む 220 万の新しい結晶予測 (人間の科学者によるほぼ 800 年分の知識の蓄積に相当) を発見しました。一部の材料は実験を通じて合成され、次世代電池や超伝導体などの技術革新を引き起こす可能性があると期待されています。
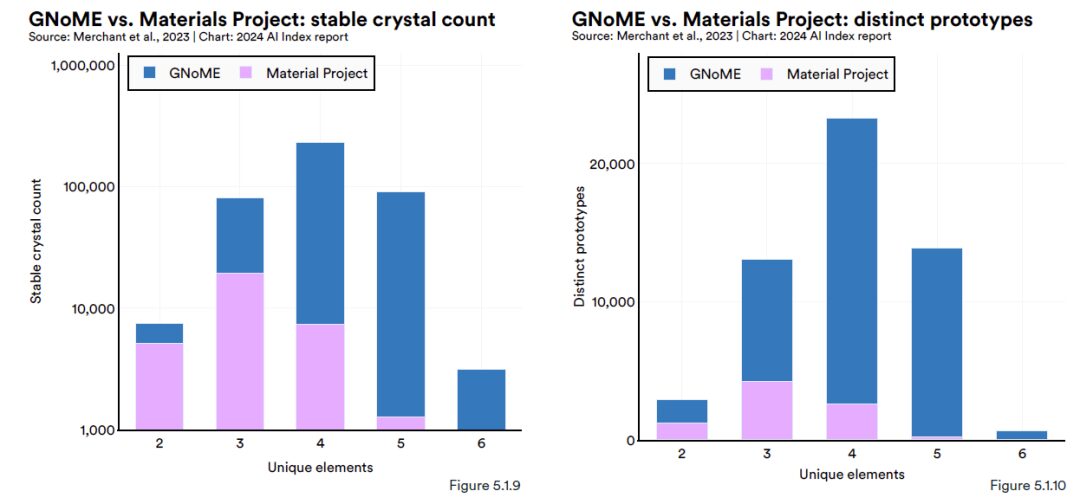
GNoME は高度なグラフ ニューラル ネットワーク (GNN) モデルであり、入力データは主に原子間の接続を形成するグラフの形式であるため、GNoME による新しい結晶材料の発見も容易になります。レポートによると、GNoME は新しい安定した結晶の構造を予測し、DFT (密度汎関数理論) を通じてテストし、結果として得られる高品質のトレーニング データをモデルのトレーニングにフィードすることができます。
この段階では、新しいモデルでは、材料の安定性の予測精度が 50% 付近から 80% まで向上し、新材料の発見率が 10% 未満から 80% を超えるまで増加します。(クリックしてレポート全文を表示: 人類より 800 年先を行く? DeepMind が深層学習を使用して 220 万個の新しい結晶を予測する GNoME をリリース)
変化を加速させ、生態環境に冷静に対処する「ハイイロサイ」
グラフキャスト
最も正確な世界の天気予報を生成します
Google DeepMindがリリースしたGraphCastは、機械学習とグラフニューラルネットワーク(GNN)をベースにした天気予報システムで、「符号化・処理・復号化」構成を採用しており、合計3,670万のパラメータを持ち、0.25度単位で天気を予測することができます。経度/緯度 (赤道で 28 km x 28 km) の高解像度。スコープは地球の表面全体をカバーします。各グリッド ポイントで、モデルは 5 つの地表変数 (気温、風速、風向、平均海面気圧など) と、37 の異なる高度での 6 つの大気変数 (比湿度、風速、風向、平均気圧など) を予測します。温度。
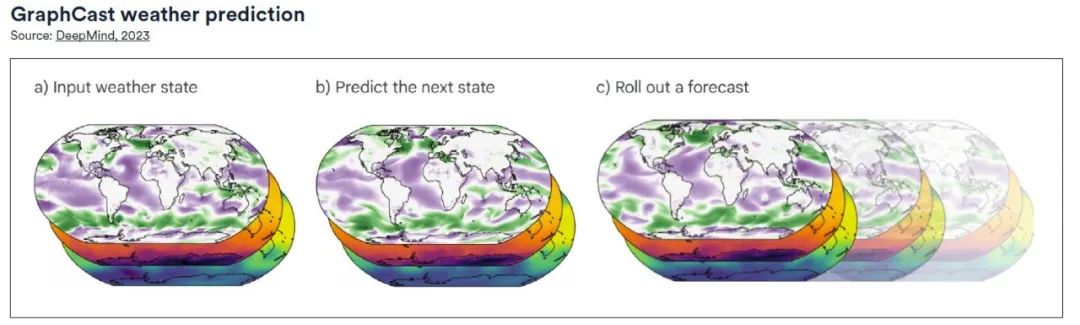
総合基礎テストでは、HRES (高解像度予測) を比較すると、GraphCast は 1,380 のテスト変数のうち、ほぼ 90% についてより正確な予測を提供します。比較分析に基づいて、GraphCast は従来の予測モデルよりも早く深刻な気象現象を特定することもできます。 (クリックするとレポート全文が表示されます: ヘイルストーム センターはデータを収集し、大規模なモデルは異常気象予測をサポートし、「ストーム チェイサー」が発生しています)
洪水予報
人工知能が洪水予測を変える
2018 年、Google は AI と強力なコンピューティング能力を使用して、より優れた洪水予測モデルを構築し、多くの国の政府部門と協力する Google Flood Forecasting Initiative を立ち上げました。 2023年Google の研究チームは、最大 5 日前までに洪水を確実に予測できる機械学習ベースの河川予測モデルを開発しました。5 年に 1 回の洪水イベントを予測する場合、そのパフォーマンスは毎年の洪水の場合、現在の予測よりも優れているか、同等です。このシステムは 80 か国以上をカバーできます。
この研究では、2 つの長期短期記憶ネットワーク (LSTM) のアプリケーションを通じて高度な河川予測モデルを構築します。モデルのコア アーキテクチャは、エンコーダ/デコーダ フレームワークに基づいています。具体的には、Hindcast LSTM モジュールは過去の気象データを処理し、Forecast LSTM モジュールは予測気象データを処理します。モデルの出力は、各予測時点での確率分布パラメーターであり、特定の時点での特定の川の流れの確率予測を提供します。
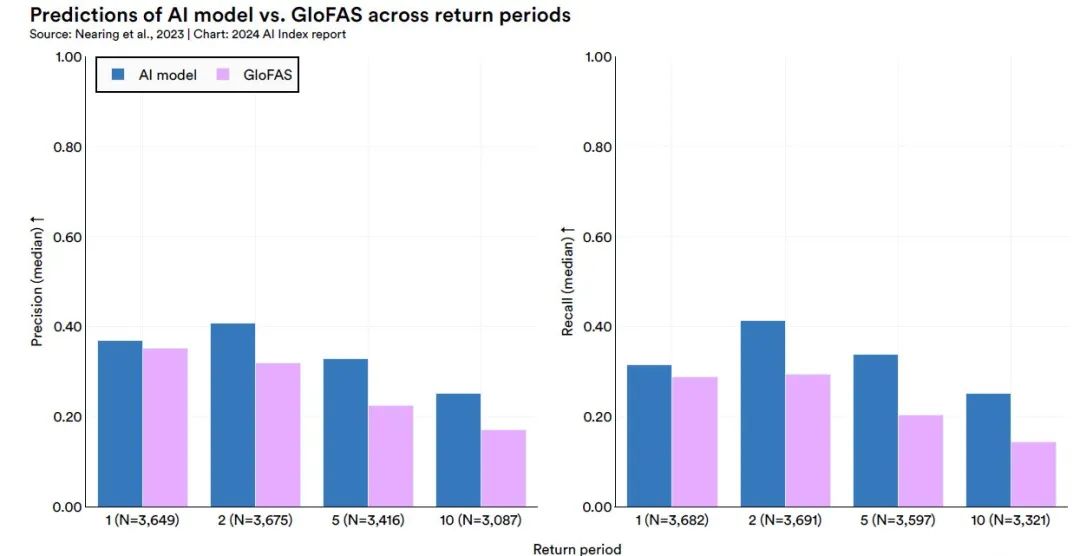
研究結果は次のことを示していますこのモデルは、現在世界をリードするモデリング システムであるコペルニクス緊急管理サービス世界規模洪水認識システム (GloFAS) のパフォーマンスを上回っています。この発見は、河川予測の分野における提案されたモデルの可能性と信頼性を裏付け、洪水警報と水資源管理のための新しい技術的手段を提供します。 (クリックしてレポート全文を表示: 世界 No.1 のシステムを破り、80 か国以上をカバーする Google の洪水予測モデルが再び Nature に登場)
AI: 医療の新時代をリードする
「2024年人工知能指数報告書」では、AI技術が医療画像、医療問答、医療診断などの分野で成果をあげていることが示されている。実際、医療や健康分野におけるAIの応用は古くから人々に知られていました。 AI は機械学習アルゴリズムを通じて大量の医療データを分析し、医師が病気をより正確に診断できるように支援します。たとえば、がんの検出では、AI が医療画像の小さな異常を識別できるため、早期診断の成功率が向上します。
さらに、AIは医薬品開発においても重要な役割を果たします。一方では、AI は、創薬標的と化合物の合成についての理解を深め、創薬のステップを最適化し、新薬の発売が成功する可能性を大幅に高めます。一方で、AI技術は、新薬の研究開発サイクルを短縮し、コストを削減し、医薬品の研究開発の効率と企業の競争力を大幅に向上させるために使用されます。
なお、「2024年人工知能指数報告書」では人工知能関連の医療機器もまとめられており、米国食品医薬品局(FDA)によるAI関連医療機器の承認件数は増加を続けている。 2022 年に FDA は 139 件の AI 関連医療機器を承認しましたが、これは前年比 12.1% 増加しており、この数は 2012 年以来 45 倍以上増加しており、現実の医療用途で AI が広く使用されていることがわかります。
実際の医療への AI テクノロジーの適用は多くの機会をもたらしましたが、AI の倫理問題、データプライバシー保護、技術的なボトルネック、監督と説明責任、学際的なコラボレーション、臨床医療など、解決すべき一連の課題にも直面しています。性的困難。特に、あI モデルの「ブラック ボックス」の性質により、その意思決定プロセスの説明が困難になります。これは、高度な透明性と追跡可能性が必要な医療診断にとって大きな課題です。解釈可能性の欠如は、AI 支援による診断結果に対する医師の信頼に影響を与える可能性があります。
したがって、技術の反復に加えて、政策、標準、監督、セキュリティなどの欠点を補う方法、およびそれ自体の「ブラックボックス」特性を除去する方法についても、依然として政府と関係者が共同で推進し、解決する必要がある。企業。
医療画像: より包括的で詳細なソリューションを提供
医用画像分野における AI 技術の応用は、診断支援からワークフローの改善、個別化医療の推進まで、ますます多様かつ奥深くなり、AI は医用画像にとって不可欠なツールとなりつつあります。
シンセSR
高解像度画像を変換して病変を修復します
MIT コンピューティングおよび人工知能研究所によって開発された SynthSR は、Open Access Series Imaging Research Dataset の 1 mm 等方性高磁場 MRI スキャン データと、39 領域の正確なセグメンテーションを使用して、超解像度畳み込みニューラル ネットワーク (CNN) をトレーニングします。脳内の関心(ROI)。この技術は、主に低磁場強度 (0.064 T) の T1 および T2 強調脳 MRI シーケンスをターゲットにしており、同時に磁化準備型高速勾配エコー (MPRAGE) 取得技術を使用し、1 mm の高分解能等方性空間分解能の生成を目指しています。 .高品質の画像。
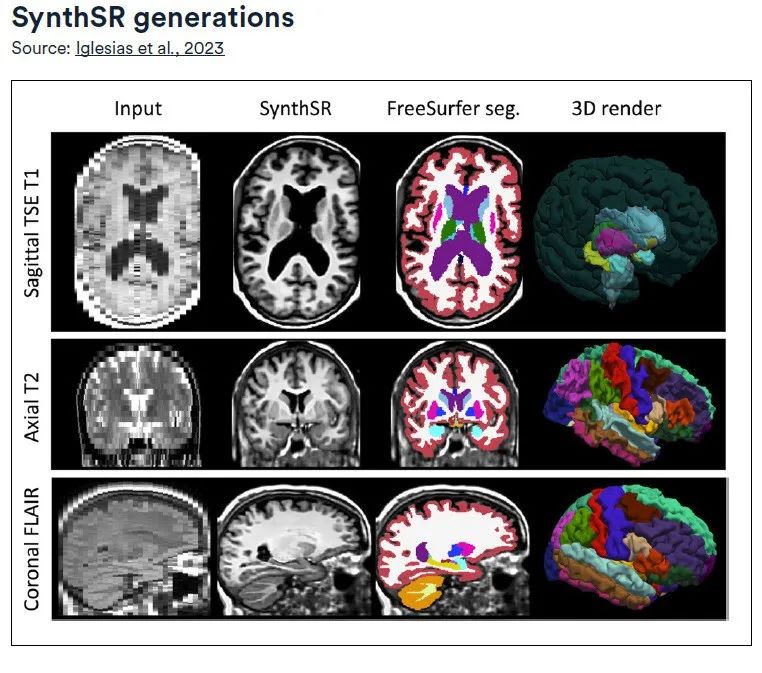
SynthSR の先進的な点は、さまざまな方向、さまざまな解像度、さまざまなコントラストからの臨床 MRI スキャン データを 1 mm 等方性 MPRAGE 画像に変換し、その過程で病変を修復できます。
変換された合成 MPRAGE 画像は、画像レジストレーションやセグメンテーションなどの既存の脳 MRI 3D 画像解析ツールに直接適用できます。追加のトレーニングは必要ありません。さらに、合成画像と実際の高磁場強度画像の間で脳の形態計測データを比較することにより、この研究は定量的神経放射線学の分野における LF-SynthSR の応用可能性をさらに検証しました。
論文リンク:
http://arxiv.org/pdf/2012.13340v1.pdf
CTパンダ
早期膵臓がん検診
膵臓がんは、単純CT画像では隠れた位置にあり、明らかな特徴がないという特徴を考慮し、Alibaba Damo Academy は、世界中の十数の医療機関の研究チームと協力して、無症状の人々を対象とした膵臓がんスクリーニング研究に AI を使用し、独自のディープラーニング フレームワークを構築し、最終的に膵臓がん早期発見モデル PANDA をトレーニングしました。
PANDA モデルは、さまざまな深層学習技術を使用して膵臓病変検出の効率と精度を向上させる高度な医用画像分析ツールです。このモデルは、まずセグメンテーション ネットワーク (U-Net) を利用して膵臓領域を特定し、次にマルチタスク畳み込みニューラル ネットワーク (CNN) を通じて画像内の異常を特定します。最後に、デュアルチャネル Transformer モデルを使用して、検出された異常を分類し、特定の膵臓病変の種類を特定しました。
この技術の主な利点は、AI アルゴリズムを使用して、肉眼では識別することが難しい単純 CT 画像内の小さな病変の特徴を拡大して識別できることです。これにより、早期膵臓がんの効率的かつ安全な検出が達成されるだけでなく、以前のスクリーニング方法における高い偽陽性率の問題も効果的に解決されます。
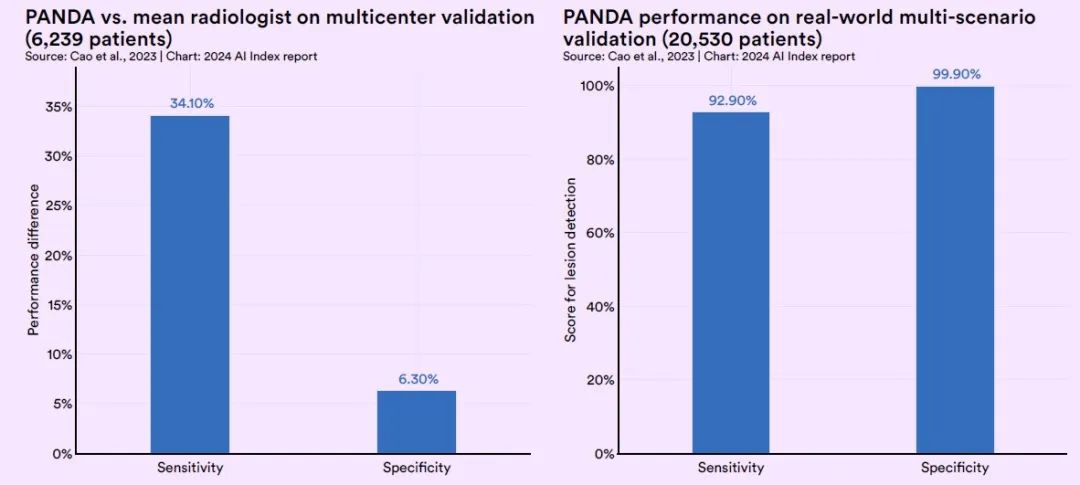
検証試験では、PANDA の感度は通常の放射線科医よりも 34.1% 高く、特異度は通常の放射線科医よりも 6.3% 高くなりました。約20,000人の患者を対象とした大規模な実世界試験では、PANDAの感度は92.9%、特異度は99.9%でした。(クリックしてレポート全文を表示: 20,000 件の症例の中から 31 件の診断漏れが特定され、アリババ ダモ病院が率先して膵臓がんのスクリーニングに「単純 CT + 大型モデル」を導入)
医療診断: 個別化された正確な診断と治療計画を作成します。
診断の効率と精度の向上から、個別化された治療オプションの提供に至るまで、AI テクノロジーは医療診断の分野で大きな可能性を秘めており、医療サービスの質と患者エクスペリエンスの向上に役立ちます。
結合プラズモニック赤外線センサー
神経変性疾患の診断を強化する
神経変性疾患の診断の分野では、前臨床バイオマーカーを検出するための有効なツールが不足しているため、パーキンソン症候群やアルツハイマー病などの疾患の早期診断が大きな課題に直面しています。質量分析法や酵素結合免疫吸着検定法 (ELISA) などの従来の検出方法はある程度役立ちますが、バイオマーカーの構造状態の変化を特定するには限界があります。
この問題に対応して、スイスのローザンヌ連邦エコール工科大学の研究チームは、神経変性疾患を検出するために、ニューラルネットワーク技術、表面増強赤外吸収(SEIRA)分光法を備えたプラズモン赤外センサー、免疫測定技術(ImmunoSEIRA)を組み合わせた革新的な診断方法を開発した。病気の段階と進行の定量化。
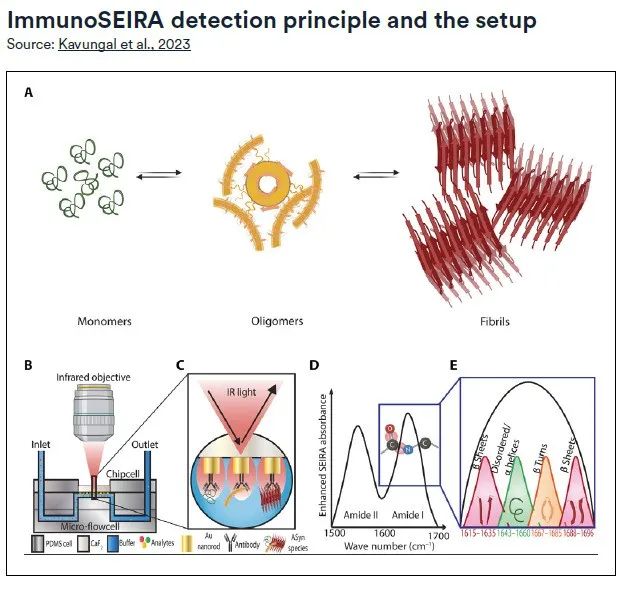
ImmunoSEIRA センサーは、特定のタンパク質に対する抗体で表面修飾された金ナノロッドのアレイを使用しており、極少量のサンプルからの標的バイオマーカーのリアルタイムの捕捉と構造分析を可能にします。その後、ニューラル ネットワークを使用して、ミスフォールドしたタンパク質、オリゴマー、線維状凝集体を特定し、前例のないレベルの検出精度が可能になりました。この方法の提案は、神経変性疾患の早期診断と正確な評価のための新しい技術的手段を提供します。
CoDoC
AIと医師の診断の論理的統合
Google DeepMind は、CoDoC と呼ばれる医療支援人工知能システムを開発しました。これは、医療画像の詳細な解釈と分析を行うように設計されており、システムは学習を通じて、いつ独自の判断に依存するか、いつ医師の意見を採用するかを決定できます。医師たち。
具体的には、DeepMind チームは、臨床医が AI ツールを使用して医療画像の解釈を支援するさまざまなアプリケーション シナリオを調査しました。あらゆる臨床設定の理論的なケースの場合、CoDoC システムはトレーニング データセットの各ケースに対して 3 つの入力のみを必要とします。* 初め、AI 出力の信頼スコアを予測します。範囲は 0 (明らかに病気ではない) から 1 (確実に病気である) です。※第二に、臨床医による医療画像の解釈。
* やっと、病気の客観的な存在。
注目に値するのは、CoDoC システムでは、医療画像自体に直接アクセスする必要はありません。
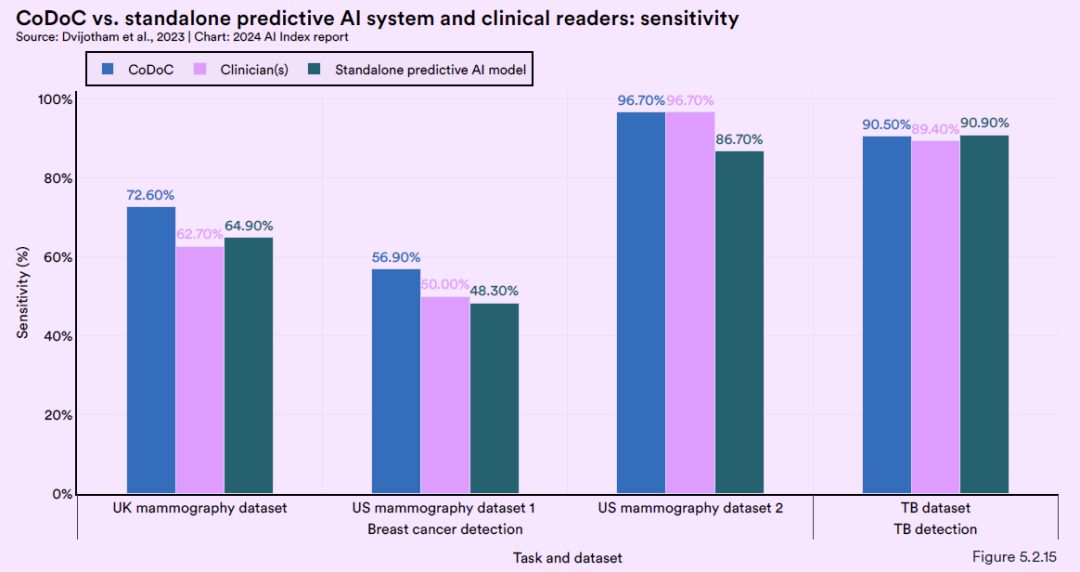
さらに、DeepMind は、複数の実世界の匿名化された過去のデータセットを使用して CoDoC システムを包括的にテストしました。テスト結果は、人間の医療専門知識と AI モデルの予測を組み合わせることで、最も正確な診断ソリューションを提供できることを示しています。この精度は、どちらかの方法のみを使用して達成できる精度を超えています。この発見は、AI が人間の専門家と協力して動作することの重要性を浮き彫りにし、医用画像診断の精度と信頼性の向上に関する新たな視点を提供します。
医療 Q&A: 診断の精度を向上させ、治療計画を最適化し、患者サービスのエクスペリエンスを向上させます。
2020 年に研究者らは、ナレッジ グラフに基づく医療質問応答システムである MedQA を提案しました。これは、ナレッジ グラフを使用して医療分野の構造化データおよび半構造化データを表現および保存し、グラフ検索などのテクノロジーを通じてナレッジ グラフからデータを取得します。 、推論または照合、または答えを生成します。 MedQA のリリース以来、医療知識 Q&A における AI の機能も幅広い注目を集めています。
GPT-4 メドプロンプト
90%を超える精度
Microsoft 研究チームが開発した GPT-4 Medprompt は、MedQA データセット (米国医師免許試験問題) において GPT-4 の精度が初めて 90% を超えました。BioGPT や Med-PaLM などの微調整手法を上回ります。研究者らはまた、Medprompt手法は一般的であり、医学だけでなく、電気工学、機械学習、法律、その他の専門分野にも適用できると述べた。
Medprompt は、次のような複数のプロンプト戦略を組み合わせたものです。*動的少数サンプル選択:研究者らはまず、text-embedding-ada-002 モデルを使用して、各トレーニング サンプルとテスト サンプルのベクトル表現を生成しました。次に、各テスト サンプルについて、ベクトル類似性に基づいてトレーニング サンプルから k 個の最も類似したサンプルが選択されます。* 自己生成の思考連鎖:思考連鎖 (CoT) 手法では、モデルに段階的に思考させ、一連の中間推論ステップを生成します。 Med-PaLM 2 モデルの専門家によって手作りされた思考連鎖の例と比較して、GPT-4 によって生成される思考連鎖の基本原理は長く、段階的な推論ロジックはよりきめ細かくなっています。
* オプションのシャッフル統合:GPT-4 が多肢選択式の質問を受ける場合、バイアスが生じる可能性があります。つまり、選択肢の内容に関係なく、常に A を選択するか、常に B を選択する傾向があります。これが位置バイアスです。この問題を軽減するために、研究者らは元のオプションの順序をシャッフルし、各ラウンドで異なるオプションの順序を使用して GPT-4 に複数ラウンドの予測を実行させることにしました。

調査によると、PubMedQA、MedMCQA、MMLUなどの複数の有名な医療ベンチマークの多肢選択セクションにおいて、2022年にMedpromptはトップランクのFlan-PaLM 540Bよりもそれぞれ3.0、21.5、16.2パーセントポイント高いことが示されています。その性能は当時最先端のMed-PaLM 2をも上回りました。
メディトロン-70B
最優秀医療オープンソース大規模言語モデル
GPT-4 Medprompt はクローズド ソース システムであるため、一般の人々による自由な使用は制限されています。この問題を解決するには、スイスのローザンヌ連邦工科大学エコール・ポリテクニックの研究者は、このシステムに基づいてメディトロン-70Bを開発しました。医療分野向けのオープンソースの高性能大規模言語モデル。
MediTron は深層学習アルゴリズムであり、Llama 2 アーキテクチャに基づいて構築され、Nvidia の Megatron-LM 分散トレーナーを使用して微調整されています。同時に、包括的な医療コーパスに関する拡張事前トレーニングが実行されました。このコーパスは、PubMed の論文、要約、国際的に認められた医療ガイドラインを厳選して集めたものです。
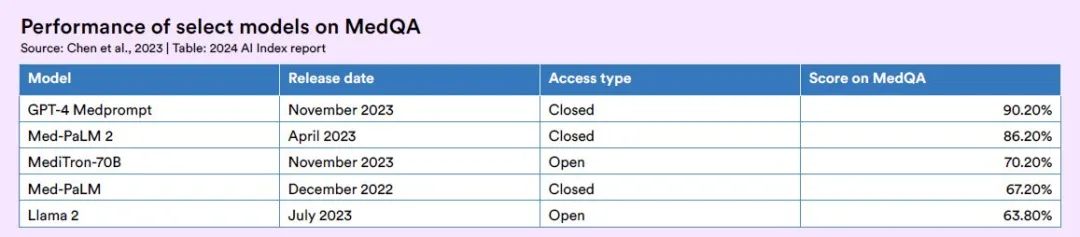
MediTronシリーズには、MediTron-7BとMediTron-70Bの2モデルがあります。で、MediTron-70Bの性能はGPT-3.5やMed-PaLMを上回り、GPT-4やMed-PaLM-2のレベルに近づいています。
オープンソースの医療LLMの開発を促進するために、開発チームは使用する医療事前トレーニングコーパスとMediTronモデルの重みコードを公開しました。 MedQA における MediTron-70B のスコアはオープンソース モデルの中で最高であり、これはオープンソースの医療 LLM の分野における重要な進歩を示す成果です。
論文リンク:
https://arxiv.org/pdf/2311.16079.pdf
メドアライン
健康管理の負担を軽減
医療におけるテキスト生成タスクに使用されている現在の電子医療記録 (EHR) の質問と回答のデータセットは、情報ニーズの分析や文書処理において臨床医が直面する複雑さを適切に捉えていません。
このギャップを埋めるために、さまざまな専門分野からなる 15 人の臨床医からなるチームが発足しました。 MedAlign - EHR データに基づくベンチマーク データセット。このデータセットには、983 件の実際の臨床質問とその説明、および 303 人の臨床医が提供した回答が含まれており、276 件の縦断 EHR データを分析して構築されました。
この研究は、複雑な臨床タスクにおけるLLMの有用性に関する評価ベンチマークの欠如に対処するだけでなく、現実的かつ包括的なコマンド応答データセットを提供することにより、ヘルスケア分野における自然言語生成の研究の進歩を前進させます。
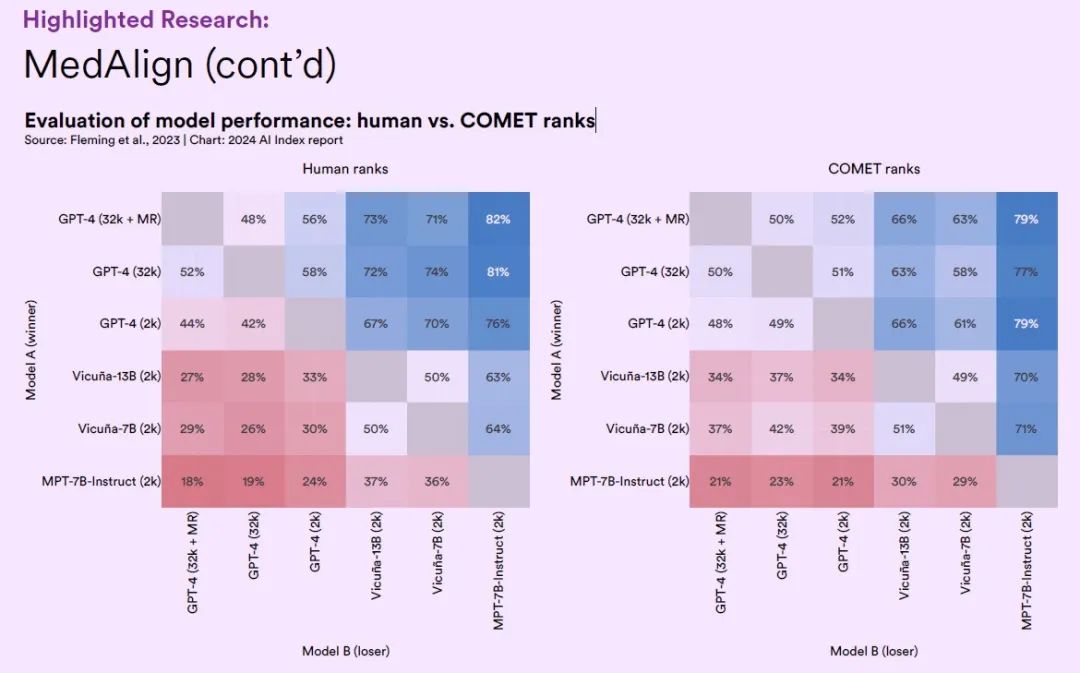
研究者らは、MedAlign データセット上で、さまざまな一般領域からの 6 つの大規模な言語モデルをテストし、臨床医が各大規模なモデルによって生成された応答の精度と品質を評価しました。
結果は次のようになります。複数ステップの最適化後の GPT-4 モデル バリアントは、65.0% の精度を達成しました。これは、一般的に他の LLM よりも一般的です。 EHR アプリケーションを幅広くカバーする最初のベンチマーク データ セットとして、MedAlign は、医療の管理負担を軽減するための人工知能テクノロジーの使用における重要な進歩を示しています。
論文リンク:
https://arxiv.org/pdf/2308.14089.pdf
医学研究: AI を使用して人間の健康に対する最強の防御線を構築する
テクノロジーの継続的な進歩に伴い、医療研究分野における AI テクノロジーの応用はより広範囲かつ奥深くなってきています。現在、科学者たちは AI の力を利用して人間の遺伝子コードを深く掘り起こし、AI を利用して強固な医療防御線を構築しています。
アルファミス
遺伝子内の病原性ミスセンス変異を効果的に特定する
Google DeepMind チームは、AlphaFold に基づいた新しい AI モデル、AlphaMissense をさらに開発しました。このモデルは、AlphaFold が提供する高精度タンパク質構造モデルと、関連配列から抽出された制約付き進化アルゴリズムを組み合わせたものです。 AlphaMissense のトレーニング プロセスは 2 つの段階に分かれています。
* 最初の段階は AlphaFold のトレーニングに似ており、タンパク質言語モデルの重みを高めることに焦点を当てます。
* 第 2 フェーズでは、病原性をより正確に照合するためのモデルの微調整に焦点を当て、集団内の頻度に基づいて変異に良性または病原性のラベルを割り当てます。
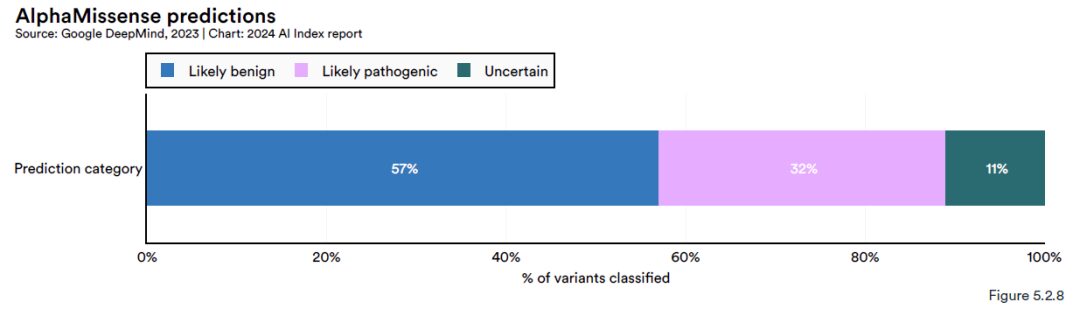
研究結果は次のことを示していますAlphaMissense は、ヒトのタンパク質をコードする遺伝子における 7,100 万個のミスセンス変異の予測に成功しました。ミスセンス変異は、タンパク質の機能に影響を与える遺伝的変異であり、がんを含むさまざまな病気を引き起こす可能性があります。これらの潜在的なミスセンスの亜種の中には、AlphaMissense は 89% バリアントを分類できます。そのうち約 57% は良性の可能性が高いバリアント (良性の可能性) と判断され、32% は病原性の可能性が高いバリアント (病原性の可能性) と判断され、残りのバリアントは不確かである Uncertain として分類されます。
この分類能力は、すべてのミスセンス変異のうち 0.1% のみを識別できた人間のアノテーターの分類能力をはるかに上回っています。 AlphaMissense の高い効率と精度は、遺伝性疾患の研究と臨床診断に強力なツールを提供します。
論文リンク:
https://www.science.org/doi/10.1126/science.adg7492
イブエスケープ
ウイルスのパンデミックに対する早期警告システム
ハーバード大学医学部とオックスフォード大学の研究チームは、革新的なユニバーサル モジュラー フレームワーク EVEscape を共同開発しました。パンデミック中に配列データや抗体の構造情報に依存せずに、ウイルスがエスケープする可能性を予測する機能。
EVEscape の SARS-CoV-2 パンデミック変異株の予測精度は、ハイスループットのディープミューテーション スキャン (DMS) テクノロジーに匹敵し、その応用は SARS-CoV-2 に限定されず、他の種類のウイルスにも拡張できます。この早期警告システムは公衆衛生上の意思決定と準備のための指針を提供し、パンデミックが人間の健康と社会経済に及ぼす悪影響を最小限に抑えるのに役立ちます。
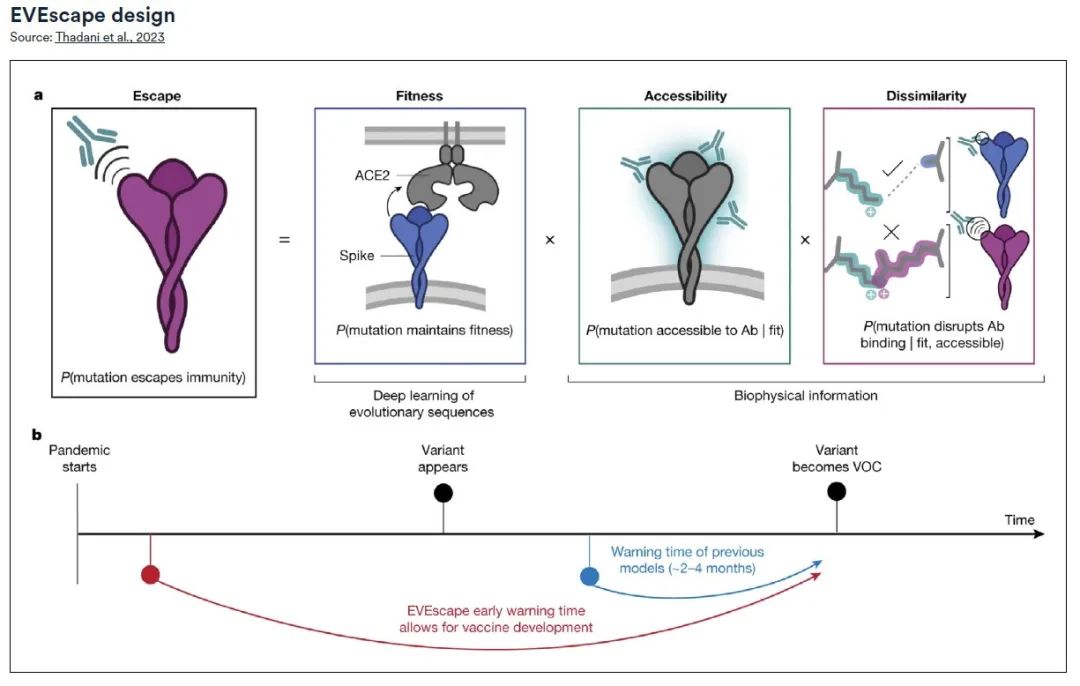
EVEscape フレームワークは 2 つの主要部分で構成されます。※パートは進化系列を生成するために使用されるモデルであり、このモデルは、ウイルスの突然変異の可能性についての洞察を提供し、EVE (進化的ウイルスエスケープ) プロジェクトで使用されるモデルに似ています。
* もう 1 つの部分は、ウイルスに関する詳細な生物学的および構造情報を含むデータベースです。これら 2 つのコンポーネントを統合することにより、EVEscape はウイルスの亜種が実際に出現する前にその特徴を予測することができます。
研究チームは、SARS-CoV-2パンデミックの遡及的分析を通じて、かなりの精度を維持しながら、従来の抗体や血清実験に依存する方法よりも数か月早くパンデミック回避の可能性のある変異を予測するEVEscapeの有効性を確認した。 EVEscape を使用して潜在的なエスケープ変異を早期に特定すると、ウイルスの蔓延をより効果的に制御するためのワクチンや治療法を設計するための重要な情報が得られます。
論文リンク:
https://doi.org/10.1038/s41586-023-06617-0
ヒトパンゲノムリファレンス
ヒトのパンゲノムの最初の草案を描く
21 世紀初頭、ヒトゲノム計画はヒト参照ゲノムの暫定草案の公開に成功し、人類が自らの生命の青写真を解釈する上で画期的な進歩を遂げました。ただし、当時のシーケンス技術の限界により、スケッチには塗りつぶされていない空白の領域がいくつかありました。
2023年、ワシントン大学医学部とカリフォルニア大学が主導する60機関の119人の科学者からなる国際コンソーシアムは、人工知能技術を利用して、ヒトのパンゲノムのより代表的な最新の草案を初めて開発した。
この草案では、高度な「ロングリードシーケンス」技術を使用して、世界中の異なる祖先背景を持つ47人からの94のゲノムサンプルの詳細な分析を実施しています。続いて、測定された長い DNA 断片は、カスタマイズされたアルゴリズムを通じて、より完全なゲノム配列に組み立てられます。研究の結果、ドラフトは予想される配列をカバーする点で 99% に達し、構造と塩基対の精度でも 99% を超えていることが示されました。
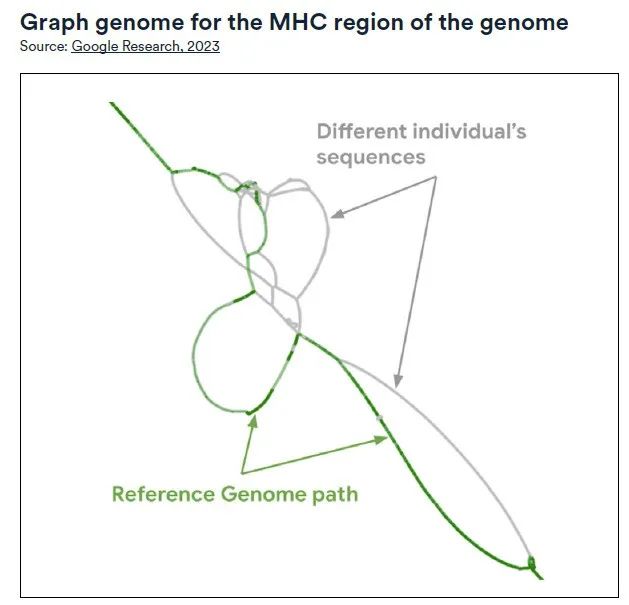
新しいスケッチを使用してショートリード データを分析する場合、古い GRCh38 ベースのワークフローと比較して、小さな遺伝的変異の検出誤差は 34% によって減少しましたが、ハプロタイプ構造変異の検出率は 104% によって増加し、1 億 1,900 万塩基対が追加されました。さらに、新しい草案では、遺伝子発現を調節する 2 つの重要な新しいコンポーネント、HIRA と SATB2 も明らかになりました。これらの発見は、ヒトゲノムの構造と機能をより深く理解する上で重要な意味を持ちます。
2024 年、AI が科学研究の未来をリードする
人工知能は、その驚くべき可能性により、科学の進歩と医療分野の進歩の中核的な推進力となりつつあります。 2024 年、AI の急速な発展は、これまでをはるかに上回るスピードと影響力で科学研究と医療に革命的な変化をもたらしています。 AI は知識の蓄積とイノベーションのサイクルを加速するだけでなく、複雑な問題を理解し解決する方法を再定義します。
科学研究の分野では、AI のアルゴリズムとモデルは、科学者による膨大なデータセットの処理と分析を支援し、データの背後に隠された洞察を明らかにします。これらは、複雑なシステムの挙動のシミュレーションと予測において大きな利点を示し、物理学、化学、生物学などの多くの基礎科学分野で画期的な発見につながりました。
医療分野では、AI 支援の診断ツールはより正確になり、病気の兆候を早期に検出し、よりタイムリーな治療を患者に提供できるようになりました。同時に、AIを個別化医療に応用することで、個々の遺伝情報やバイオマーカーを分析することで、患者にとってより正確な治療計画をカスタマイズできるようになり、治療効果と患者の生活の質が大幅に向上します。
また、医薬品の研究開発における AI の役割を過小評価することはできません。分子の活性や薬の副作用を予測することで、新薬が研究室から市場に届くまでのサイクルが大幅に短縮され、研究開発コストが削減され、新薬の発売が加速されます。
AI の進歩のあらゆる段階は、人間の知恵の長い川に落とされた石のようなものであり、波紋を引き起こし、科学研究と医学の境界を押し広げます。ツールを使いこなすのが得意な人間は、最終的にその力を身につけることができます。この興奮をきっかけに、私たちは人々がより賢く、より健康になる新しい時代に向かって進んでいきます。








