Command Palette
Search for a command to run...
古い薬物を再利用、セントラルサウス大学のチームが薬物の再配置に適応型グラフ畳み込みネットワークを使用する AdaDR をリリース

現代社会では、人類は腫瘍、糖尿病、心血管疾患などのますます流行する複雑な病気と闘い続ける必要があり、元の薬では市場の需要を完全に満たすことができなくなり、新薬の研究開発が不可欠です。しかし、従来の創薬プロセスは時間と投資がかかり、過去の薬剤や放棄された化合物の中から新薬や治療標的を積極的にスクリーニングできれば、明らかに研究開発コストを大幅に節約し、研究開発効率を向上させることができます。
ドラッグ・リポジショニング、または「古い薬物の再利用」は、既存の治療法を新しい疾患プロセスに適用する、FDA 承認の医薬品開発手法です。たとえば、シルデナフィルはもともと胸痛の治療に使用されていましたが、後にこれが PDE5 (ホスホジエステラーゼ 5 型阻害剤) 阻害剤であることが発見され、シルデナフィルが市場で普及するようになりました。
薬剤リスクの軽減、臨床評価サイクルの短縮、低コスト、高効率という利点により、既存の薬剤の再配置は現在の業界研究の注目のスポットとなっています。深層学習の急速な発展に伴い、グラフ畳み込みネットワーク (GCN) は薬物の再局在化タスクに広く使用されています。ただし、既存の GCN ベースの方法では、ノードの機能とトポロジを深く統合するには限界があります。これに応えて、セントラルサウス大学の研究者らは「適応グラフ畳み込みネットワークによる薬物再配置」というタイトルの論文をバイオインフォマティクス誌に発表した。
この研究では、ノードの特徴とトポロジーを深く統合することによって薬物を再配置するための、AdaDR と呼ばれる適応型 GCN 手法を提案します。従来のグラフ畳み込みネットワークとは異なり、AdaDR は適応グラフ畳み込み演算を通じてネットワーク間のインタラクティブな情報をシミュレートし、それによってモデルの表現能力を強化します。
具体的には、AdaDR はノードの特徴とトポロジからエンベディングを同時に抽出し、アテンション メカニズムを利用してエンベディングの適応重要度の重みを学習します。
実験結果は、AdaDR が薬物再配置において複数のベースライン手法よりも優れていることを示しています。さらに、ケーススタディでは、新たな薬物疾患の関連性を発見するための探索的分析が提供されます。
研究のハイライト:
* この研究は、トポロジーと特徴空間でグラフ畳み込み演算を実行する、薬物再局在化タスク用の適応グラフ畳み込みネットワーク フレームワークを提案します。
* トポロジー構造と特徴の違いを考慮して、この研究ではアテンション メカニズムを使用してそれらを完全に統合し、モデル結果への寄与を区別します。
* この研究で提案されたモデルは、薬物の再配置タスクにおいて実用的であり、薬物開発の失敗のリスクを軽減するのに役立ちます。
用紙のアドレス:
https://academic.oup.com/bioinformatics/article/40/1/btad748/7467059
データセットのダウンロードアドレス:
公式アカウントをフォローし、バックグラウンドで「移転」と返信すると全文PDFが表示されます
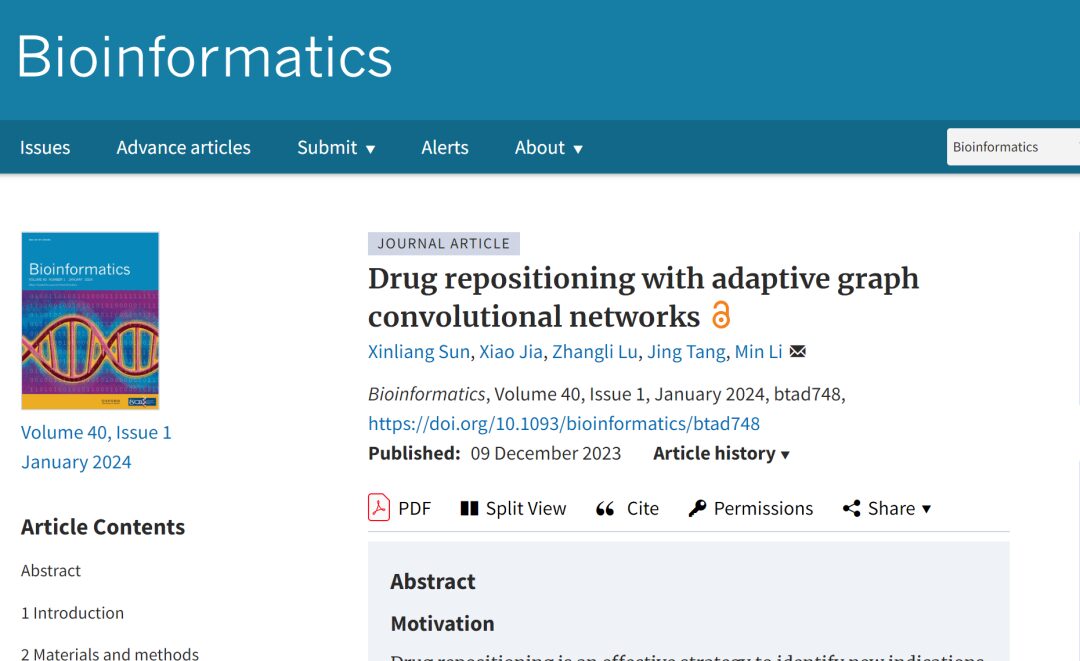
データセット: 4 つの主要なベンチマーク データセットを利用
提案モデルの性能を総合的に評価するために、この研究では、薬物再配置タスクで広く使用されている 4 つのベンチマーク データセット、つまり Gdataset、Cdataset、Ldataset、LRSSL を利用しました。
*Gデータセット:ゴールドスタンダードのデータセットと考えられており、このデータセットには、DrugBank の 593 の薬剤と、OMIM データベースにリストされている 313 の疾患の間で確認された 1,933 の薬剤と疾患の関連性が含まれています。
*Cdataset:663 の薬物、409 の疾患、および 2,352 の相互作用に関する薬物と疾患の関連性が含まれています。
*Lデータセット:CTD データセットから編集されたこのデータには、269 種類の薬剤と 598 種類の病気の間の 18,416 件の関連性が含まれています。
*LRSSL:763 の薬剤と 681 の疾患に関する 3,051 の検証済みの薬剤と疾患の関連性が含まれています。
同時に、薬物/疾患の特徴マップを構築するために、研究では薬物と疾患の類似性の特徴も利用しました。データセットの統計を次の表に示します。
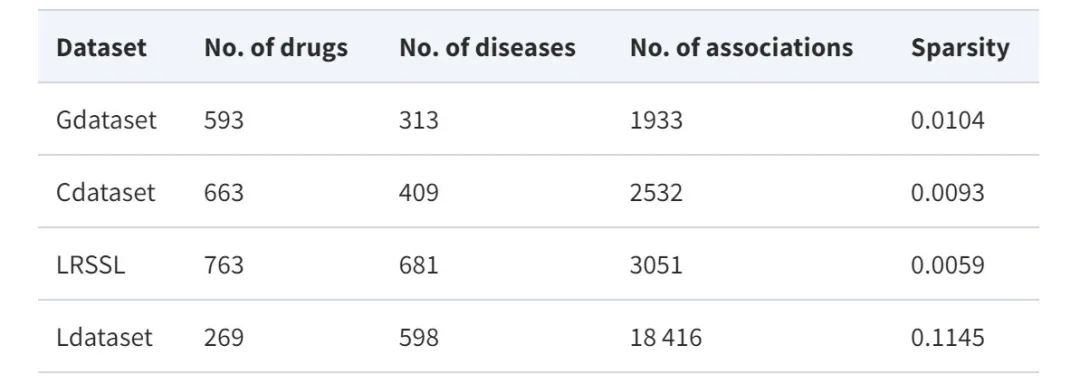
モデル アーキテクチャ: 新しい適応型 GCN フレームワーク AdaDR
この研究で提案された AdaDR モデル フレームワークには、主に 3 つのコンポーネントが含まれています。以下に示すように:
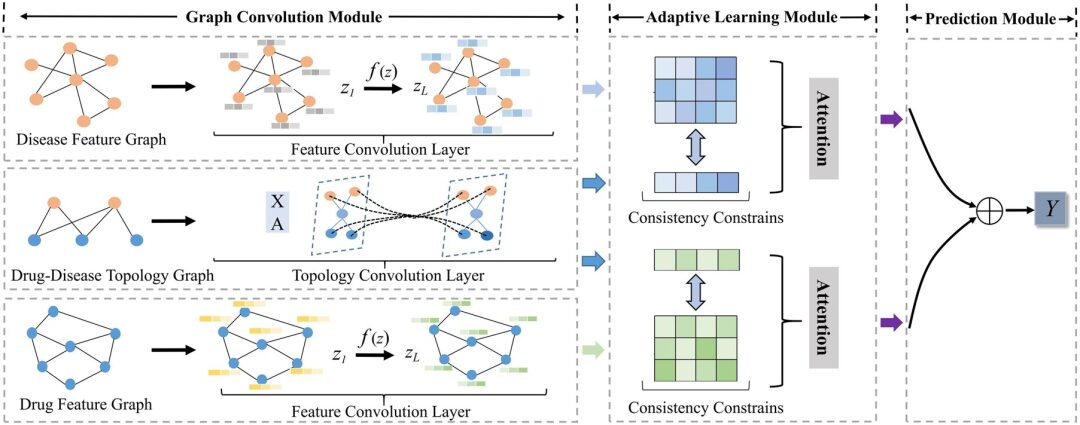
* グラフ畳み込みモジュール:特徴空間および位相空間での薬剤/疾患の埋め込みを表現するために使用される特徴畳み込み層とトポロジカル畳み込み層が含まれます。
* 適応学習モジュール:アテンション メカニズムを利用して、取得されたエンベディングの重要性を区別します。このモジュールでは、一貫性制約を使用して、フィーチャと位相空間の間の共通の意味情報を抽出します。
* 予測モジュール:エンベディングを出力として連結して結果を予測します。
研究結果: AdaDR は薬物再配置において複数のベースライン手法を上回ります
全体として、AdaDR は新しいモデルとして、薬物再配置タスクのパフォーマンスを大幅に向上させることができます。
まず、相互検証のパフォーマンスです。この研究では、AdaDR と他のモデルに対して 10 倍の相互検証を実施し、結果の平均と標準偏差を計算しました。
結果によると、AdaDR の機能統合機能により、10 回の 10 倍相互検証で得られた 4 つのデータセットの最終平均結果は、すべての比較方法よりも優れています。
たとえば、4 つのベンチマーク データ セット Gdataset、Cdataset、LRSSL、Ldataset では、この研究の結果は、準最適な手法である DRHGCN の AUPRC (適合率再現率下の領域) よりそれぞれ 9.8%、9.1%、9.1%、および 7.1% 高く、新しい手法の有効性を十分に示しています。
次に、新薬の潜在的な適応を予測する機能です。この研究では、新薬の潜在的な適応を予測する AdaDR の能力を評価するための新しい実験が実施されました。
他の 7 つの方法と比較して、AdaDR は最高のパフォーマンスを実現します (下図の青いヒストグラムは AdaDR を表します)。 AUROC (受信機動作特性曲線の下の面積) に関しては、以下の図 (a) に示すように、AdaDR は 0.948 という AUROC 値を達成しており、これは他の方法よりも優れています。一方、以下の図 (b) に示すように、AdaDR は 0.393 の AUPRC を達成し、これは他のすべての方法よりも高くなります。
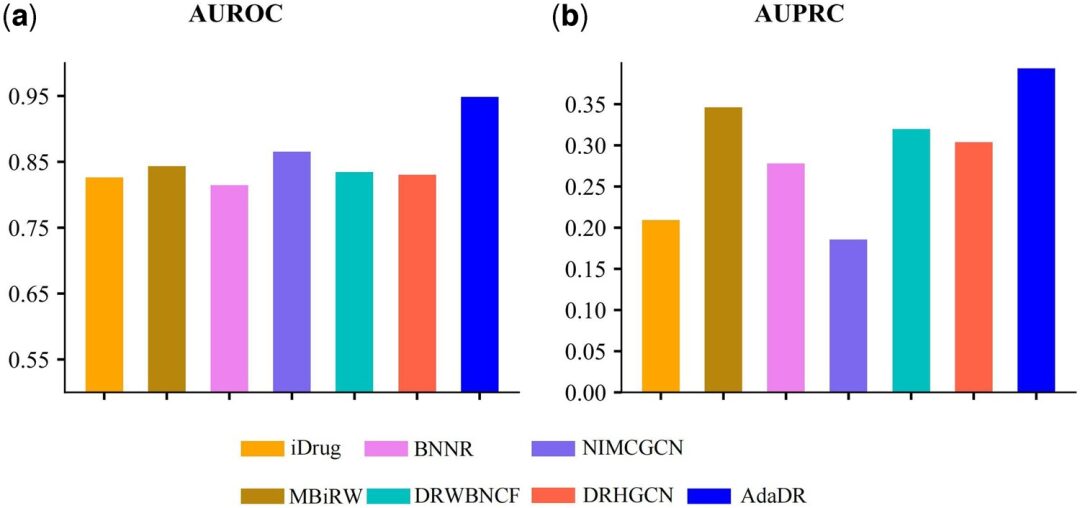
(a) AdaDR および他の競合手法を適用して得られた予測結果の AUROC。
(b) AdaDR および他の競合手法を適用して得られた予測結果の AUPRC。
AdaDRの性能をさらに検証するために、研究チームはアルツハイマー病(AD)と乳がん(BRCA)を予測する候補薬にもAdaDRを適用したことは注目に値する。
中でもアルツハイマー病は進行性の神経変性疾患であり、現時点では有効な治療薬がありません。乳がんは、さまざまな発がん因子の作用により乳房上皮細胞が制御不能に増殖する現象です。パクリタキセル、カルボプラチンなど、乳がんの治療薬はすでに多数ありますが、薬剤の選択肢が増えれば、より良い治療選択肢が得られる可能性があります。以下の表は、証拠に基づいた裏付けのある薬剤候補を示しています。
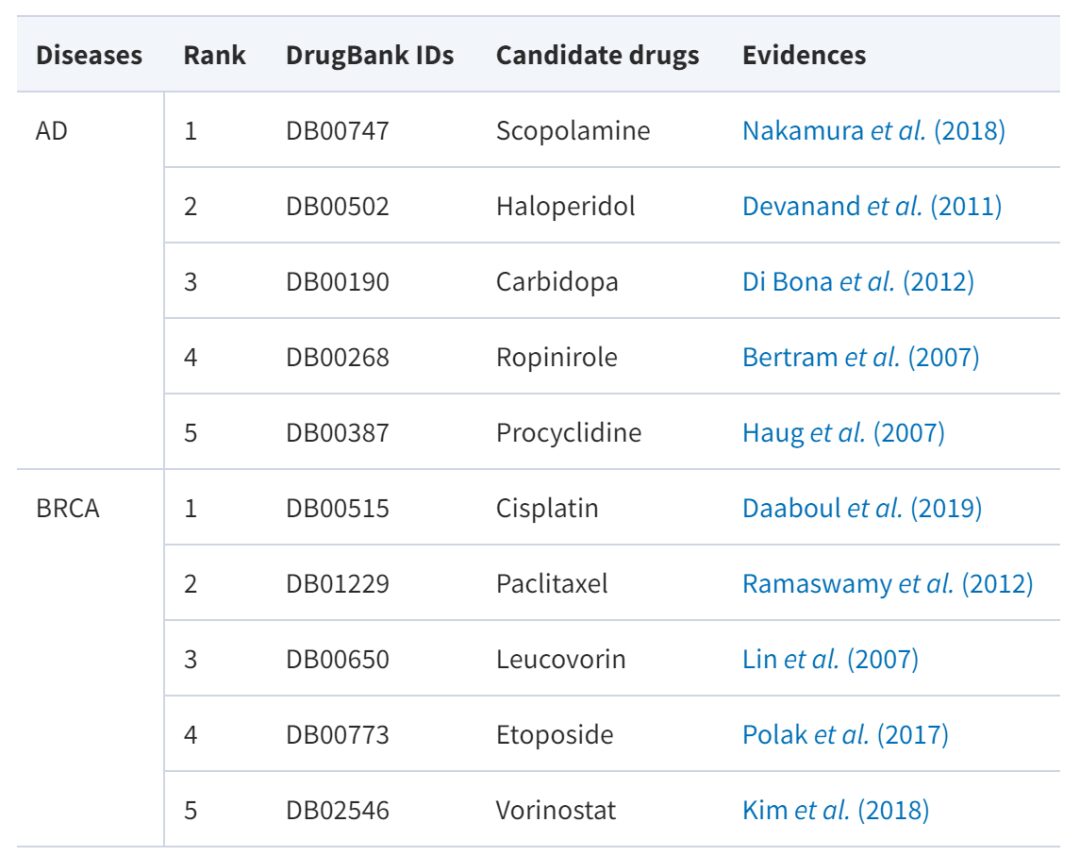
AdaDR 予測スコアの上位 5 つの薬剤の中には、信頼できる情報源や文献によって検証された多くの証拠がすでに存在していることがわかります (成功率 100%)。さらに、研究のモデルは解釈可能な結果を生み出すことができます。パクリタキセルを例にとると、このモデルはパクリタキセルが乳がんを治療できると予測しています。これは確かに信頼できる情報源や文献によって裏付けられています。
興味深いことに、研究者らはドセタキセルがトレーニングセットに含まれていることを発見しました。そして、パクリタキセルとドセタキセルは、同じパクリタキセルコアを持つ類似した分子です。これは、新しいモデルが薬物の類似性情報を利用して意味のある予測を行えることを反映しています。
医薬品の研究開発への投資収益率は低下し続けており、医薬品の再配置が状況を打開する鍵となる可能性がある
現在、製薬会社は前例のない変化の真っ只中にいます。新型コロナウイルス感染症のパンデミックとその後の経済不況により、製薬会社は一連の課題と不確実性に直面しており、イノベーションによる収益はすべての製薬会社にとって最優先事項となっています。
バイオ医薬品企業は過去 10 年間、イノベーションのための研究開発に多額の投資を行ってきましたが、同じ期間で収益は大幅に減少しました。デロイト センター フォー ヘルス ソリューションズが発表した「2019年医薬品イノベーション収益率評価」によると、2019年の製薬業界の研究開発投資収益率は2010年以来最低水準のわずか1.8%でした。 10 件のレポートに示されたデータから判断すると、製薬企業の研究開発投資収益率は過去 10 年間減少傾向にあります。
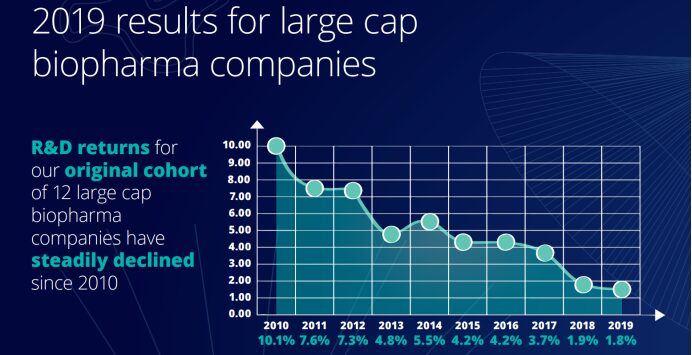
それだけでなく、各新薬の発売後のピーク売上高も2018年の4億700万米ドルから2019年には3億7600万米ドルに減少し、初めて4億米ドルを下回り、2010年の8億1600万米ドルの半分以下となった。 2010 年と比較すると、新薬の発売コストは 2010 年の 11 億 8,800 万米ドルから 2019 年の 19 億 8,100 万米ドルへと 67% 増加しました。ピーク時の売上高の減少は、新薬を市場に出すまでの平均コストの増加とは対照的であり、製薬会社が開発プロセスにこれまで以上に長い時間を費やしていることを示しています。
薬剤の再配置により、薬剤を市場に出すまでに必要な初期のコストと時間を節約できるため、基礎研究の取り組みから臨床治療への移行が迅速化されます。業界関係者によると、新薬は研究開発の開始から販売承認まで、一連の体外試験、前臨床動物試験、臨床第I相、第II相、第III相試験を経る必要があり、通常は10~15年かかるという。 、少なくとも10億ドルの費用がかかります。比較すると、リポジショニングされた薬剤のコストは平均わずか 3 億ドルで、市場に出るまでに約 6 年半かかることがいくつかの調査結果で示唆されています。
薬物再配置には、主に機械学習に基づく方法、ビッグデータマイニングによる位置決め方法、および生体内位置決めに基づく方法が含まれます。機械学習とビッグデータマイニングに基づくドラッグリポジショニング技術は、生体内ベースの方法と比較して、高速かつ低コストという利点があり、潜在的に強力な技術となっています。
記事「機械学習とビッグデータマイニングに基づくドラッグリポジショニングアルゴリズムのレビュー」では、近年の計算によるドラッグリポジショニングの研究の進歩について紹介しています。
で、従来の機械学習アルゴリズムに基づく手法、まず、薬物と副作用の情報、薬物の化学構造情報、疾患と遺伝子関連の情報が統合され、次に特徴抽出と特徴選択を通じてトレーニング データが取得され、次に関連する機械学習アルゴリズムがトレーニング用に選択されます。トレーニングされたアルゴリズム モデルは、薬物再配置結果を取得するために使用されます。
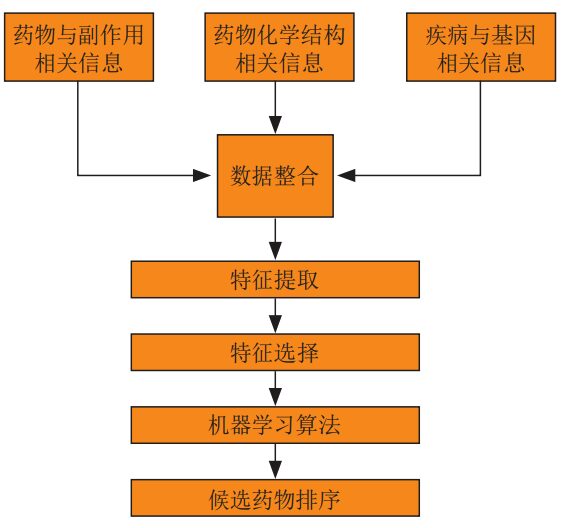
深層学習ベースの手法では、一部の研究者は、医薬品開発のさまざまな側面においてディープ ニューラル ネットワークと他のさまざまな機械学習手法を系統的に比較し、その結果、ディープ ラーニングが従来の機械学習アルゴリズムよりも優れていることが示されました。
ネットワーク類似性推論手法では、中国華東科技大学の研究チームは、既知の薬物の新しい標的を推測するために薬物と標的の二部ネットワークトポロジー的類似性のみを使用するネットワークベース推論(NBI)手法を提案した。
ビッグデータマイニング技術の発展により、機械学習とビッグデータマイニングアルゴリズムに基づく薬物の再配置は、病気の治療にますます効果的な方法を提供することになり、生物医学研究の焦点となっています。合理的な推論と計算モデリングが将来の薬物再配置プロセスにおいて重要な役割を果たすと信じる理由があります。
参考文献:
1.https://www.cn-healthcare.com/article/20191224/content-527902.html
2.https://pps.cpu.edu.cn/cn/article/pdf/preview/b286f85e-a37a-4007-ab94-918629aef556.pdf
3.https://mp.weixin.qq.com/s/lD-HyfwUHiX4f-llS6lykQ








