Command Palette
Search for a command to run...
NVIDIA Jen-Hsun Huang は、H100 に比べて 30 倍高い推論機能と 25 分の 1 のエネルギー消費量を備えた GB200 をリリースし、AI4S 機能をマイクロサービスに転換しました。

「iPhone に AI の瞬間が到来しました。」NVIDIA GTC 2023 での Huang Renxun 氏の素晴らしい言葉が今でも私の耳に残っています。今年、AI の発展によって彼の言葉が真実であることが証明されました。
長年にわたり、AI の開発が加速し、NVIDIA のテクノロジーと環境保護の堀を揺るがすのが難しい中、GTC は当初の技術カンファレンスから、業界チェーン全体が懸念する AI 業界のイベントへと徐々にアップグレードしてきました。 NVIDIA が表示する「は、業界革新の鍵となる可能性があります。重要な触媒です。」
今年の 2024 GTC AI カンファレンスは予定通り、3 月 18 日から 3 月 21 日まで開催され、900 以上のカンファレンスと 20 以上の技術講演が開催されます。もちろん、最も注目を集めた演説は、やはり「レザーイエロー」の演説だった。以前に発表されたスケジュールでは、黄仁勲氏の演説は北京時間3月19日午前4時に始まり、午前6時まで続いた。たった今、黄氏は 2 時間の共有セッション中に次々と「AI 核爆弾」を投下しました。
* 新世代 GPU プラットフォーム Blackwell
* 最初の Blackwell ベースのチップ GB200 Grace Blackwell
※次世代AIスーパーコンピュータ DGX SuperPOD
※ AIスーパーコンピューティングプラットフォーム DGX B200
新世代ネットワークスイッチ X800シリーズ
※量子コンピューティングクラウドサービス
* 気候デジタルツインクラウドプラットフォーム Earth-2
* 生成 AI マイクロサービス
* 5 つの新しい Omniverse クラウド API
* DRIVE Thor、生成 AI アプリケーション用に特別に設計された車載コンピューティング プラットフォーム
※BioNeMoベーシックモデル
ライブリプレイリンク:
https://www.bilibili.com/video/BV1Z6421c7V6/?spm_id_from=333.337.search-card.all.click
クリソの使用
昨年の GTC カンファレンスで、Nvidia は計算リソグラフィ ライブラリ cuLitho を発表し、計算リソグラフィを 40 倍以上高速化できると発表しました。本日、Huang Renxun 氏は、TSMC と Synopsys が NVIDIA cuLipo をそのソフトウェア、製造プロセス、システムと統合して、チップ製造を高速化したことを紹介しました。共有ワークフローで cuLitho をテストしたところ、両社は合わせて、曲線フローでは 45 倍の速度向上、より伝統的なマンハッタン スタイルのフローでは 60 倍近くの効率向上を達成しました。
さらに、NVIDIA は、cuLitho プラットフォームの価値をさらに高めるために、生成 AI を適用するアルゴリズムを開発しました。具体的には、cuLithoをベースとした生産プロセスの効率化をベースに、この生成 AI アルゴリズムにより、さらに 2 倍の高速化が実現します。
レポートによると、生成 AI を適用することで、光の回折を考慮したほぼ完璧なリバース マスク ソリューションを作成し、従来の物理的手法を使用して最終的なマスクを導き出し、最終的に光近接効果補正 (OPC) 全体を補正できます。 ) プロセスが 2 倍高速になります。
兆パラメータ規模の生成 AI 用 Blackwell プラットフォーム

cuLitho のアプリケーションに関する上記の紹介は、どちらかというと「前菜」のようなもので、コンピュテーショナル リソグラフィー テクノロジの発展の見通しを示し、NVIDIA AI チップの世代間のアップグレードに対する基本的な保証をある程度提供します。
続いてメインの食事が始まります。 GPU アーキテクチャを 2 年ごとに更新するという Nvidia の伝統に従い、Huang がもたらした最初の主要製品は、より大型の新しい GPU-Blackwell プラットフォームです。彼はこう言いました。Hopper は素晴らしいですが、より強力な GPU が必要です。
ブラックウェル建築は、全米科学アカデミーに選出された最初のアフリカ系アメリカ人学者であるデビッド・ハロルド・ブラックウェルにちなんで名付けられました。

パフォーマンスの面では、Blackwell には 6 つの革新的なテクノロジーがあります。
* 世界で最も強力なチップ:Blackwell アーキテクチャの GPU は、カスタマイズされた 4NP TSMC プロセスを使用して製造され、2,080 億個のトランジスタを備えており、10 TB/秒のチップ間リンクを介して 2 つのエクストリーム GPU チップを 1 つの統合 GPU に接続します。 第 2 世代の Transformer エンジン: Blackwell は、新しい 4 ビット浮動小数点人工知能推論機能に基づいて、2 倍の計算とモデル スケールをサポートします。
* 第 5 世代 NVLink:NVIDIA NVLink の最新バージョンは、GPU あたり 1.8TB/秒という画期的な双方向スループットを実現し、最も複雑な LLM に対して最大 576 GPU 間のシームレスな高速通信を保証します。
* RAS エンジン:Blackwell を搭載した GPU には、信頼性、可用性、保守性を高めるための専用エンジンが組み込まれています。さらに、Blackwell アーキテクチャには、診断を実行し、AI ベースの予防保守を使用して信頼性の問題を予測するためのチップレベルの機能が追加されています。これにより、システムの稼働時間が最大化され、大規模な AI 導入の回復力が向上し、数週間または数か月にわたって中断なく稼働できるようになり、運用コストが削減されます。
* 安全な AI:パフォーマンスに影響を与えることなく AI モデルと顧客データを保護し、ヘルスケアや金融サービスなどのプライバシーに敏感な業界にとって重要な新しいネイティブ インターフェイス暗号化プロトコルをサポートします。
* 減圧エンジン:専用の解凍エンジンは、データベース クエリを高速化する最新の形式をサポートし、データ分析とデータ サイエンスに最大のパフォーマンスを提供します。
現在、AWS、Google、Meta、Microsoft、OpenAI、Tesla およびその他の企業が、Blackwell プラットフォームの予約を主導しています。
GB200 グレース・ブラックウェル

最初の Blackwell ベースのチップは GB200 Grace Blackwell Superchip と呼ばれます。2 つの NVIDIA B200 Tensor コア GPU を、900 GB/秒の超低電力 NVLink チップ間相互接続を介して NVIDIA Grace CPU に接続します。
このうちB200 GPUは、既存のH100に比べてトランジスタ数が2倍以上の2,080億個となっている。また、1 つの GPU で 20 ペタフロップスの高いコンピューティング パフォーマンスを提供できますが、1 つの H100 では最大 4 ペタフロップスの AI コンピューティング能力しか提供できません。さらに、B200 GPU には 192 GB の HBM3e メモリも搭載されており、最大 20 ペタフロップスの AI コンピューティング能力を提供します。 8 TB/秒の帯域幅。

GB200 は、NVIDIA GB200 NVL72 の主要コンポーネントです。NVL72 は、マルチノードの水冷式ラックマウント可能なシステムです。最も計算量の多いワークロードに適しており、72 個の Blackwell GPU と 36 個の Grace CPU を含む 36 個の Grace Blackwell スーパーチップが第 5 世代 NVLink で相互接続されています。
さらに、GB200 NVL72 には NVIDIA BlueField®-3 データ処理ユニットが含まれており、超大規模な人工知能クラウドでクラウド ネットワークの高速化、コンポーザブル ストレージ、ゼロトラスト セキュリティ、GPU コンピューティングの弾力性を実現します。同じ数の NVIDIA H100 Tensor コア GPU と比較して、GB200 NVL72 は LLM 推論ワークロードで最大 30 倍優れたパフォーマンスを提供し、コストとエネルギー消費を最大 25 倍削減できます。
次世代AIスーパーコンピュータ DGX SuperPOD
NVIDIA DGX SuperPOD は、効率的な新しい水冷ラックマウント アーキテクチャを採用し、NVIDIA DGX GB200 システム上に構築されています。FP4 精度で 11.5 エクサフロップスの AI スーパー コンピューティング能力と 240 TB の高速メモリを提供できます。また、ラックを追加することでより高いパフォーマンスに拡張できます。 DGX SuperPOD は、ハードウェアとソフトウェア上の何千ものデータ ポイントを継続的に監視するインテリジェントな予測管理機能を備えており、ダウンタイムと非効率の原因となるソースを予測して遮断し、時間、エネルギー、コンピューティング コストを節約します。
このうち、DGX GB200 システムには、36 個の NVIDIA Grace CPU と 72 個の NVIDIA Blackwell GPU を含む 36 個の NVIDIA GB200 スーパー チップが搭載されており、第 5 世代 NVLink を介してスーパーコンピューターに接続されています。
各 DGX SuperPOD は 8 個以上の DGX GB200 を搭載でき、NVIDIA Quantum InfiniBand を介して接続された数万個の GB200 スーパー チップに拡張できます。たとえば、ユーザーは NVLink インターコネクトに基づいて 576 個の Blackwell GPU を 8 個の DGX GB200 に接続できます。
AIスーパーコンピューティングプラットフォーム DGX B200
DGX B200 は、空冷式の従来のラックマウント型 DGX 設計を使用した、人工知能モデルのトレーニング、微調整、および推論のためのコンピューティング プラットフォームです。 DGX B200 システムは、新しい Blackwell アーキテクチャで FP4 精度を実現し、最大 144 ペタフロップスの AI コンピューティング パフォーマンス、1.4 TB の大容量 GPU メモリ、および 64 TB/秒のメモリ帯域幅を提供します。前世代と比較して、兆パラメータモデルのリアルタイム推論速度は 15 倍向上しました。
新しい Blackwell アーキテクチャに基づいた DGX B200 には、8 つの Blackwell GPU と 2 つの第 5 世代 Intel Xeon プロセッサが搭載されています。ユーザーは、DGX B200 システムを使用して DGX SuperPOD を構築することもできます。ネットワーク接続の点では、DGX B200 には 8 枚の NVIDIA ConnectX™-7 ネットワーク カードと 2 枚の BlueField-3 DPU が装備されており、最大 400 ギガビット/秒の帯域幅を提供できます。
新世代ネットワークスイッチシリーズ——X800
レポートによると、新世代ネットワーク スイッチ X800 シリーズは、大規模な人工知能向けに特別に設計されており、コンピューティングおよび AI ワークロードのネットワーク パフォーマンスの限界を突破します。
このプラットフォームには、NVIDIA Quantum Q3400 スイッチと NVIDIA ConnectX@-8 スーパー ネットワーク カードが含まれており、業界をリードする 800Gb/s のエンドツーエンド スループットを実現します。前世代の製品と比較して、帯域幅容量は 5 倍に増加しました。同時に、NVIDIA の Scalable Hierarchical Aggregation and Reduction Protocol (SHARPv4) を使用して、最大 14.4 Tflops のネットワーク内コンピューティング能力を実現します。前世代製品と比べて最大9倍性能が向上しました。
量子コンピューティングのクラウド サービスは科学研究と探査を加速します
NVIDIA の量子コンピューティング クラウド サービスは、同社のオープンソース CUDA-Q 量子コンピューティング プラットフォームに基づいています。業界で量子処理装置 (QPU) を導入している企業の 4 分の 3 が現在、このプラットフォームを使用しています。 Nvidia の量子コンピューティング クラウド サービスを使用すると、ユーザーは強力なシミュレーターや量子ハイブリッド プログラミング ツールなど、新しい量子アルゴリズムとアプリケーションを初めてクラウド上で構築してテストできます。
量子コンピューティング クラウドには、科学的探査を加速する次のような強力な機能とサードパーティ ソフトウェア統合が備わっています。
* トロント大学と共同で開発された生成量子署名ソルバー。大規模言語モデルを活用して、量子コンピューターが分子の基底状態エネルギーをより迅速に見つけることができるようにします。
* Classiq と CUDA-Q の統合により、量子研究者は大規模で複雑な量子プログラムを生成し、量子回路の詳細な分析と実行を行うことができます。
* QC Ware Promethium は、分子シミュレーションなどの複雑な量子化学問題を解決します。
気候デジタルツインクラウドプラットフォーム「Earth-2」リリース
Earth-2 は、異常気象の予測を可能にするために、気象と気候の大規模なシミュレーションと視覚化を実行するように設計されています。 Earth-2 API は AI モデルを提供し、CorrDiff モデルを使用します。
CorrDiff は、NVIDIA が発表した新しい生成 AI モデルで、SOTA 拡散モデルを使用します。生成された画像の解像度は、既存の数値モデルより 12.5 倍高く、1,000 倍速く、3,000 倍エネルギー効率が優れています。粗い解像度の予測の不正確さを克服し、意思決定に重要な指標を統合します。

CorrDiff は、超解像度を提供し、新しい重要な指標を合成し、高解像度のデータセットから局所的なきめの細かい気象の物理学を学習する、この種では初めての生成 AI モデルです。
創薬 AI マイクロサービスをリリースして、医薬品の研究開発、医療技術の反復、デジタル ヘルスを促進する
新しく発売された NVIDIA ヘルスケア マイクロサービス スイートには、クラウド ネイティブ アプリケーションを作成および展開するための構成要素として、最適化された NVIDIA NIM™ AI モデルと業界標準の API ワークフローが含まれています。これらのマイクロサービスには、高度なイメージング、自然言語と音声認識、デジタル バイオロジーの生成、予測、シミュレーションなどの機能があります。
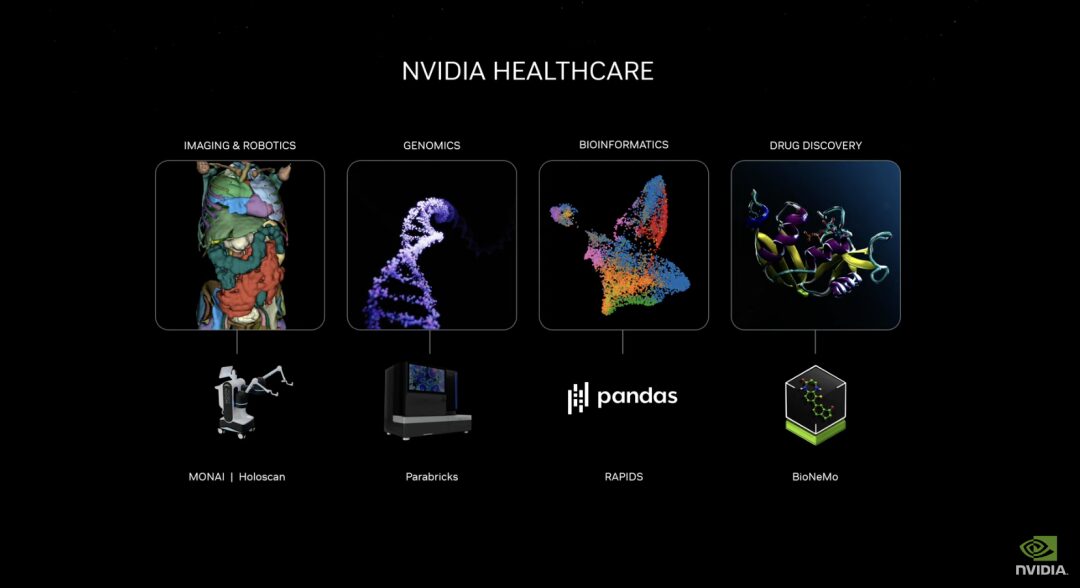
さらに、NVIDIA 高速化ソフトウェア開発キットと関連ツール (Parabricks®、MONAI、NeMo™、Riva、Metropolis など) に、NVIDIA CUDA-X™ マイクロサービスを通じてアクセスできるようになりました。
推論マイクロサービス
エンタープライズレベルの生成 AI マイクロサービスを多数リリースすると、企業はこれらのサービスを使用して、知的財産権を保持しながら、独自のプラットフォーム上でカスタム アプリケーションを作成および展開できます。
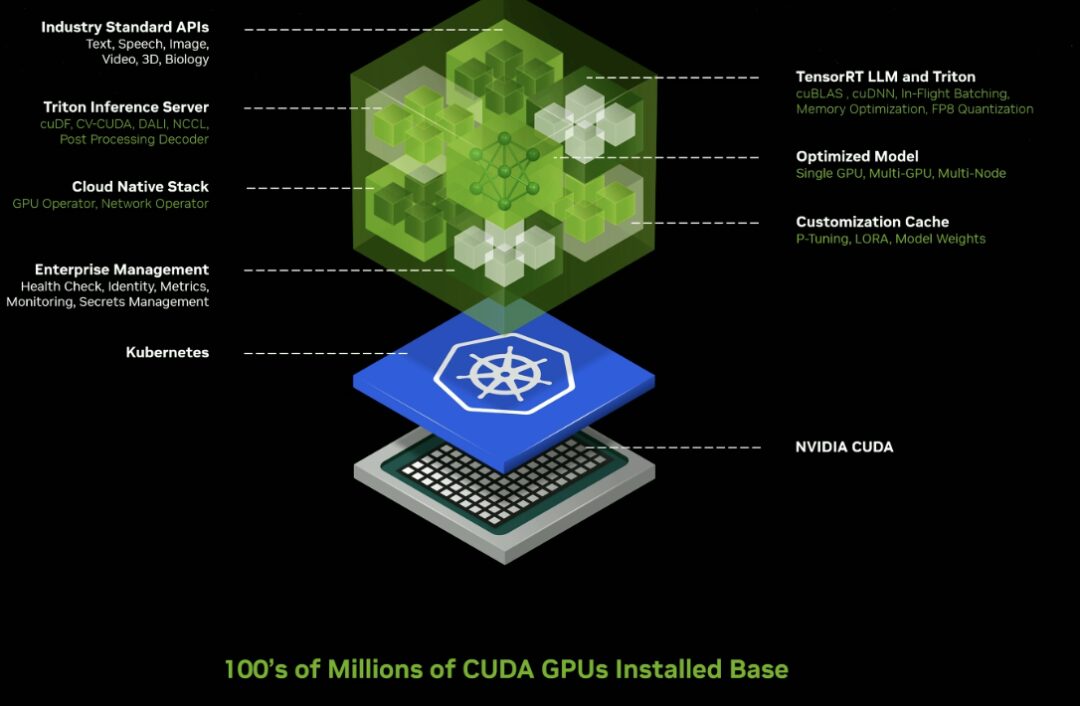
新しい GPU アクセラレーションの NVIDIA NIM マイクロサービスとクラウド エンドポイントにより、クラウド、データ センター、ワークステーション、PC にわたる数億の CUDA 対応 GPU で実行するように最適化された、事前トレーニング済み AI モデル用のクラウド エンドポイントが提供されます。
企業はマイクロサービスを使用して、データ処理、LLM のカスタマイズ、推論、取得、強化された生成と保護を高速化できます。
主要なアプリケーション プラットフォーム プロバイダーである Cadence、CrowdStrike、SAP、ServiceNow などを含む、幅広い AI エコシステムで採用されています。
NIM マイクロサービスは、Triton Inference Server™ や TensorRT™-LLM などの NVIDIA 推論ソフトウェアを活用した事前構築済みコンテナーを提供し、デプロイメント速度を数週間から数分に短縮できます。
産業用デジタル ツイン ソフトウェア ツールを強化する Omniverse Cloud API をリリース
開発者は、5 つの新しい Omniverse Cloud API を使用して、Omniverse コア テクノロジーを既存のデジタル ツイン設計および自動化ソフトウェア アプリケーションに直接統合したり、Apple Vision Pro にストリームするインタラクティブ産業用デジタル ツイン ストリームなどのロボットや自動運転車のテストと検証などのシミュレーション ワークフローに直接統合したりできます。
これらの API には次のものが含まれます。
* USD レンダリング:グローバル レイ トレーシング OpenUSD データの NVIDIA RTX™ レンダリングを生成
* 米ドル書き込み:ユーザーが OpenUSD データを変更および操作できるようにします。
*USD クエリ:シーン クエリとシーン インタラクションをサポートします。
*米ドル通知:USD の変更を追跡し、最新情報を提供します。
※オムニバースチャンネル:ユーザー、ツール、現実をリンクして、シナリオを超えたコラボレーションを実現
Huang Renxun 氏は、将来製造されるすべてのものにはデジタル ツインが搭載されると考えています。オムニバースは、物理的現実のデジタル ツインを構築および実行するためのオペレーティング システムであり、生成人工知能は、50 兆ドル規模の重工業市場のデジタル化の基礎技術です。 。
DRIVE Thor: Blackwell アーキテクチャによる生成 AI 機能、自動運転を強化
DRIVE Thor は、生成 AI アプリケーション用に設計された車載コンピューティング プラットフォームで、一元化されたプラットフォーム上で機能豊富な模擬運転機能と高度に自動化された運転機能を提供します。次世代の自動運転車の中央コンピュータとして、インテリジェント機能を 1 つのシステムに統合し、システム全体の効率を向上させ、コストを削減します。
DRIVE Thor は、新しい NVIDIA Blackwell アーキテクチャも統合します。このアーキテクチャは、Transformer、LLM、生成 AI ワークロード向けに設計されています。
BioNeMo: 創薬支援
BioNeMo 基本モデルは、DNA 配列を分析し、薬物分子の作用によるタンパク質の形状変化を予測し、RNA に基づいて細胞機能を決定することができます。
現在、BioNeMo が提供する最初のゲノム モデルである DNABERT は DNA 配列に基づいており、ゲノムの特定領域の機能を予測し、遺伝子の突然変異や変異の影響を分析するために使用できます。 2 番目の次期モデルである scBERT は、単一細胞 RNA 配列データでトレーニングされており、ユーザーはこれを遺伝子ノックアウト (つまり、特定の遺伝子の欠失または不活性化) の影響の予測や、次のような細胞タイプの識別などの下流タスクに適用できます。ニューロン、血液細胞、または筋肉細胞。
報道によると、現在世界中で100社以上の企業がBioNeMoに基づく研究開発プロセスを進めており、その中には東京に本拠を置くアステラス製薬、コンピューティングソフトウェア開発会社ケイデンス、医薬品研究開発会社イアンビックなどが含まれる。
最後に書きます
上記の多くの新製品に加えて、Huang Renxun 氏はロボット工学分野における NVIDIA のレイアウトも紹介しました。 Huang 氏は、動くものはすべてロボットであり、自動車産業がその重要な部分を占めることになると述べました。現在、NVIDIA コンピュータは自動車、トラック、配送ロボット、ロボット タクシーに使用されています。その後、Isaac Perceptor ソフトウェア開発キット、人型ロボット汎用基本モデル GR00T、NVIDIA Thor システムオンチップをベースとした新しい人型ロボットコンピュータ Jetson Thor が発売され、NVIDIA Isaac ロボット プラットフォームは大幅にアップグレードされました。
要約すると、2 時間の共有は、高性能の製品とモデルの高密度の紹介で満たされ、このようなペースが速く、内容が豊富な記者会見は、AI 業界の現在の発展状況と一致していました。スピードと繁栄。
AI時代の基盤として、高性能チップに代表されるコンピューティングパワーは、業界の開発サイクルと方向性を決定する鍵となります。現在、Nvidia が揺るがすのが難しい堀があることは疑いの余地がありません。多くの企業が Lao Huang を攻撃し始めており、OpenAI、Microsoft、Google なども独自の「軍隊」を育成していますが、このペアは依然として対立しています。現在の Nvidia にとって、それはさらに大きな推進力になる可能性があります。
オンライン生放送が終了した今、黄仁訓氏は新製品を発売するたびに、どのパートナーが新サービスを「予約」したかを紹介することになり、大手メーカーや巨人が例外なくリストに名を連ねている。将来的には、現在業界の最前線にいる企業が、業界の高度な生産性を活用して、より革新的な製品やアプリケーションを提供することにも期待しています。








