Command Palette
Search for a command to run...
LLM が人狼をプレイ: 清華大学は、複雑なコミュニケーション ゲームに大規模モデルが参加できる能力を検証
作者:ビンビン
編集者: Li Baozhu、三陽
清華大学の研究チームは、コミュニケーション ゲームのフレームワークを提案し、大規模言語モデルが経験から学習する能力を実証し、さらに大規模言語モデルには信頼、対立、偽装、リーダーシップなど、事前にプログラムされていない戦略的行動があることも発見しました。
近年、人狼やポーカーなどのゲームにAIを活用する研究が注目を集めています。自然言語コミュニケーションに大きく依存する複雑なゲームに直面し、AIエージェント 曖昧な自然言語の発話から情報を収集し、推論する必要がありますが、これにはより実用的な価値と課題があります。 GPT のような大規模な言語モデルが大幅に進歩するにつれて、複雑な言語を理解し、生成し、推論する能力が継続的に向上しており、人間の行動をシミュレートするある程度の可能性が示されています。
これに基づいて、清華大学の研究チームは、人間によるデータへの注釈なしで、凍結された大規模言語モデルを使用して人狼をプレイできるコミュニケーション ゲームのフレームワークを提案しました。このフレームワークは、大規模な言語モデルが経験から自律的に学習する能力を示しています。興味深いことに、研究者らは、大規模言語モデルには、信頼、対立、変装、リーダーシップなど、ゲーム内で事前にプログラムされていない戦略的行動があることも発見しました。これは、コミュニケーション ゲームをプレイする大規模言語モデルについてのさらなる研究の触媒として機能する可能性があります。

紙を入手してください:
https://arxiv.org/pdf/2309.04658.pdf
モデル フレームワーク: 大規模な言語モデルを使用したウェアウルフの実装
誰もが知っているように、人狼ゲームの重要な特徴は、すべてのプレイヤーが最初は自分のキャラクターしか知らないことです。彼らは、自然言語コミュニケーションと推論に基づいて他のプレイヤーの役割を推測する必要があります。したがって、人狼で優れたパフォーマンスを発揮するには、AI エージェントが自然言語の理解と生成に優れているだけでなく、他者の意図の解読や心理の理解などの高度な能力も備えている必要があります。
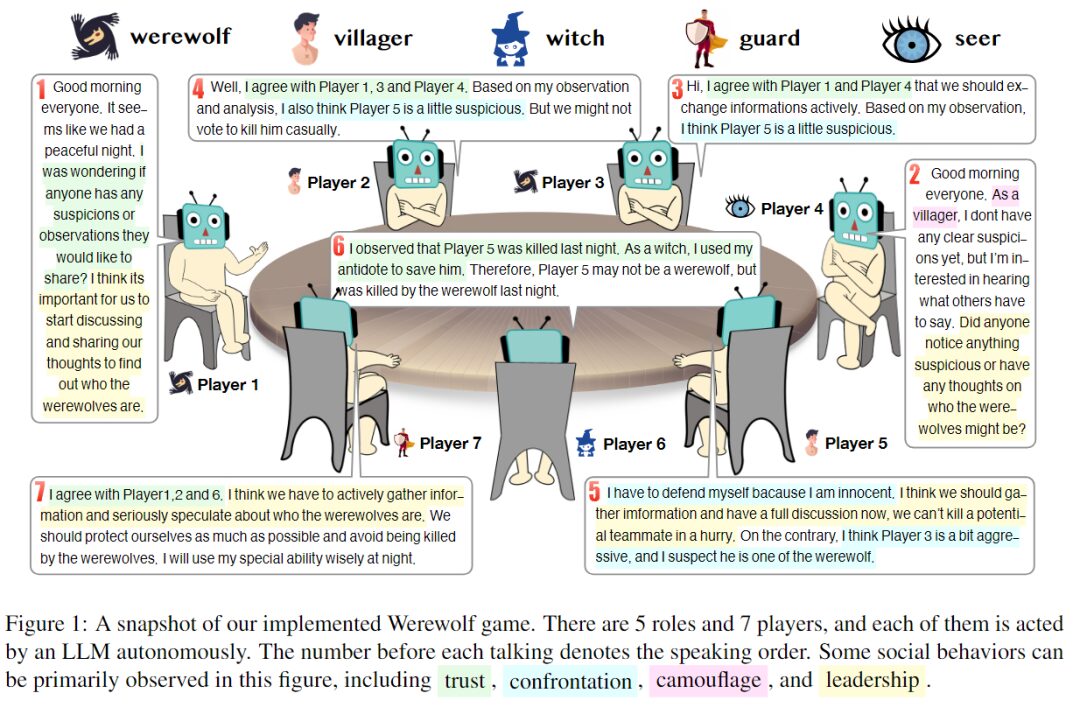
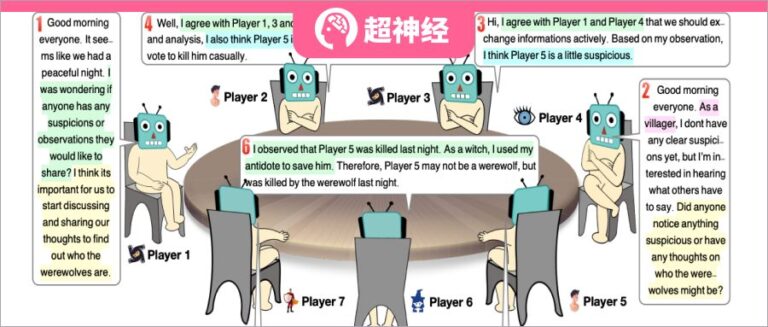
プレイヤーは合計 7 人で、それぞれの役割は大規模な言語モデルによって独立して実行されます。各スピーチの前の数字はスピーチの順序を示します
この実験では、研究者らは 7 人のプレイヤーを 5 つの異なる役割 (狼男 2 人、民間人 2 人、魔女 1 人、警備員 1 人、預言者 1 人) を演じるように設定しました。各ロールは、プロンプトによって生成される独立したエージェントです。次の図は、応答としてプロンプトを生成するためのフレームワークを示しており、4 つの主要な部分で構成されています。

応答のプロンプト概要を生成します。斜体はコメントです。
- ゲームのルール、割り当てられた役割、各キャラクターの能力と目標、ゲーム戦略に関する経験的知識。
- コンテキストの長さが限られているという問題を解決します。有効性と効率性を考慮して、鮮度、情報量、完全性の 3 つの観点から履歴情報を収集し、大規模な言語モデルに基づいて各 AI エージェントにコンパクトなコンテキストを提供します。
- モデルパラメータを調整せずに、過去の経験から推奨事項を抽出します。
- プロンプト、推論を引き起こす思考の連鎖。
また、研究者らは、複数の大規模な言語モデルの接続を可能にする ChatArena と呼ばれる最先端のフレームワークを使用して設計を実装しました。このうち gpt-3.5-turbo-0301 モデルはバックエンド モデルとして使用されます。キャラクターが話す順序はランダムに決定されます。同時に、選択可能な事前定義質問の数 L を 5、自由質問の数 M を 2、提案抽出時に最大 50 件の経験を保持するなどの一連のパラメータを設定しました。
実験プロセス: 実現可能性と歴史的経験の影響
経験プールの構築: 経験を活用したフレームワークの有効性を評価する
人狼ゲームでは、人間のプレイヤーが使用する戦略は経験とともに変化する可能性があります。同時に、あるプレイヤーの戦略は他のプレイヤーの戦略の影響を受ける場合もあります。したがって、理想的な人狼 AI エージェントは、経験を蓄積し、他のプレイヤーの戦略から学ぶことができる必要があります。
この目的を達成するために、研究者らは、パラメータを調整せずに言語モデルが経験を学習できるようにする「ノンパラメトリック学習メカニズム」を提案した。 一方では、研究者は各ラウンドの終了時にゲームに関するすべてのプレイヤーのレビューを収集し、経験プールを形成します。一方、ゲームの各ラウンドでは、研究者はエクスペリエンス プールから最も関連性の高いエクスペリエンスを取得し、そこからエージェントの推論プロセスをガイドするための提案を抽出します。
エクスペリエンス プールのサイズは、パフォーマンスに大きな影響を与える可能性があります。したがって、研究チームは、10、20、30、および 40 ラウンドのゲーム ラウンドを使用して、各ラウンドでプレイヤー 1 ~ 7 に異なる役割をランダムに割り当てました。経験プールは評価のためにラウンドの終了時に更新されます。 。
次に、民間人、予言者、衛兵、魔女には経験値プールが装備されていますが、ウェアウルフは除外されています。この方法は、AI Wolf のパフォーマンス レベルが変化しないと仮定することができ、他の AI エージェントのパフォーマンス レベルを測定するための基準として機能します。
予備実験では、図 2 プロンプトで提供されるゲーム戦略の経験的知識が、経験から学習するプロセスのガイダンス メカニズムとして機能できることが示されています。これは、人間のゲームプレイからのデータを活用してエクスペリエンス プールを構築する方法についてさらなる研究に価値があることを示唆しています。
エクスペリエンスプール内の提案の妥当性を検証する
エクスペリエンスプールから推奨事項を抽出する有効性を研究するために、研究チームは勝率と平均期間を使用して大規模な言語モデルのパフォーマンスを評価しました。
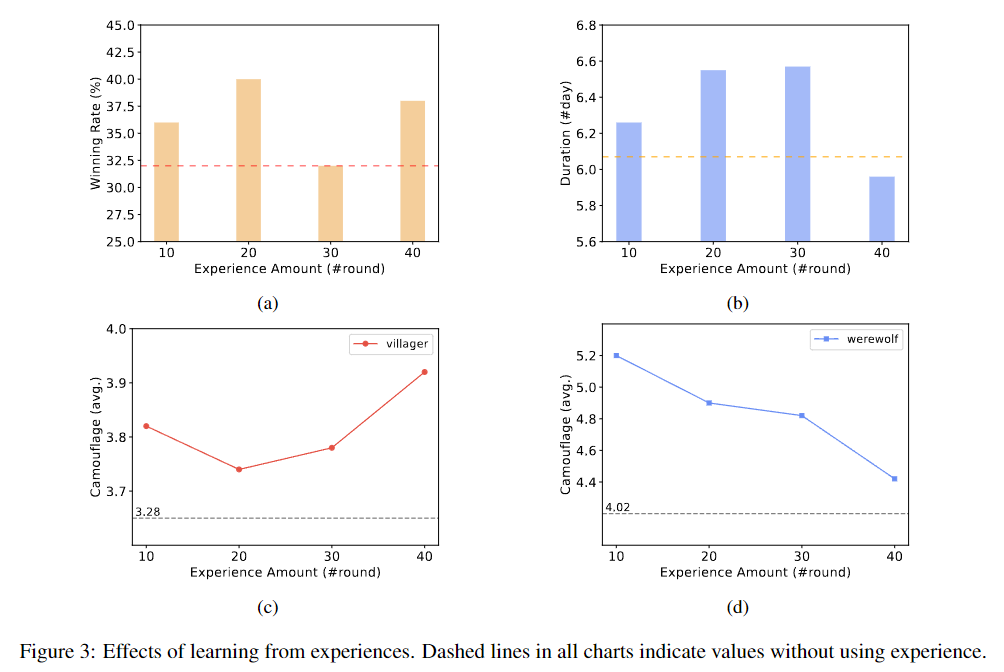
経験から学ぶ効果。すべてのグラフの破線は経験を使用しない場合の値を表します。
a. 歴史経験の異なるラウンドを使用した場合の民間側の勝率の変化
b. 異なるラウンドの歴史的経験を使用する場合の民間側の期間の変更
c. ゲーム内で民間人が変装する回数の傾向
d. ゲーム内で人狼が変装する回数の傾向
実験では、ゲームを 50 ラウンドプレイしました。この結果は、経験から学ぶことで民間側の勝率が向上する可能性があることを示唆しています。 10 ラウンドまたは 20 ラウンドの歴史的経験を使用すると、民間側の勝率と試合時間に大きなプラスの影響があり、この方法の有効性が実証されました。しかし、40ラウンドの経験から学び、民間側の勝率はわずかに向上しましたが、平均持続時間は減少しました。
一般的に、このフレームワークは、大規模な言語モデルのパラメーターを調整することなく、AI エージェントが経験から学習する能力を示しています。ただし、この方法は経験値が多いと効果が不安定になる場合があります。また、実験ではAIウルフの能力は変わらないと仮定したが、実験結果の分析により、この仮定が当てはまらない可能性があることが判明した。その理由は、民間人は歴史的経験から欺くことを学ぶことができるが、狼男の行動もまた経験によって改善され、変化するからである。
これは、複数の大規模な言語モデルがマルチパーティ ゲームに参加する場合、他のモデルの機能が変化すると、そのモデルの機能も変化する可能性があることを示しています。
アブレーション研究:フレームワークの各部分の必要性を検証する
メソッドの各コンポーネントの必要性を検証するために、研究者らは完全なメソッドと特定のコンポーネントを削除したバリアントを比較しました。
研究チームはバリアントモデルの出力から 50 の回答を抽出し、手動評価を実行しました。アノテーターは出力が妥当かどうかを判断する必要があります。不合理の例としては、幻覚、他の人の役割を忘れる、直観に反する行動を取るなどが挙げられます。
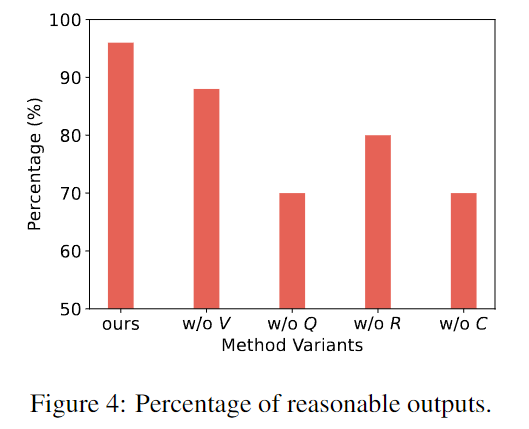
横軸はこの研究枠組みとその他のバリエーションを表し、縦軸は 50 ラウンド ゲームにおける妥当な出力の割合を表します。
上の図は、この研究のフレームワークが、フレームワークの各部分に必要な特定のコンポーネントを欠いている他のバリアントよりも合理的で現実的な応答を生成できることを示しています。
興味深い現象: AI は戦略的な動作を示します
実験中、研究者らはAIエージェントが、ゲームの指示やプロンプトでは明示的に言及されていない戦略、つまり人間がゲーム内で体現する信頼、対立、変装、リーダーシップを使用していることを発見した。
信頼
「信頼」とは、他のプレイヤーが自分と同じ目標を共有し、その目標に従って行動すると信じることを意味します。
たとえば、プレイヤーは自分たちに有害な情報を積極的に共有したり、特定の瞬間に他のプレイヤーに加わって誰かを敵だと非難したりすることがあります。大規模な言語モデルが示す興味深い動作は、特定の証拠と独自の推論に基づいて信頼するかどうかを決定する傾向があり、グループ ゲームで独立して考える能力を示しています。
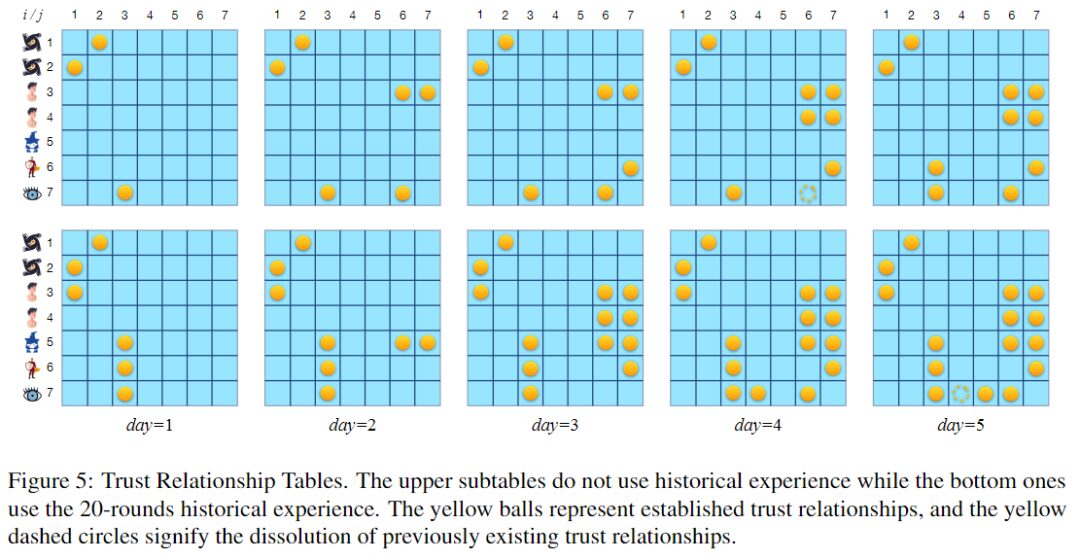
信頼関係テーブル。黄色のボールは確立された信頼関係を表し、黄色の点線の円は以前に存在した信頼関係の解消を表します。
上の図は 2 つの信頼関係テーブルを示しています。上のテーブルは経験値プールを使用しないラウンドに対応し、下のテーブルは 20 ターン ゲームから構築された経験値プールを使用するラウンドに対応します。どちらのラウンドも期間は5泊です。 20 回の歴史的経験を活用すると、大規模な言語モデルは信頼関係、特に双方向の信頼を確立する傾向があるようです。
実際、ゲームの成功を促進するには、必要な信頼関係をタイムリーに確立することが重要です。これが勝率を上げるために経験を活用する理由の 1 つかもしれません。
対決
「対決」とは、2 つの陣営の対立する目標に向かってプレーヤーがとる行動を指します。
たとえば、夜に明らかに他人を狼男として攻撃したり、日中に他人を狼男だと非難したりすることは、どちらも対立的な行動です。特殊な能力を持ったキャラクターが身を守るために行う行動も、対決行動です。
P1 (狼男): 私は再び P5 を排除することを選択します。
P3(ガード):私はP5を守ることにしました。
P1 の非協力的で攻撃的な行動が注目を集めたため、一部のプレイヤーは P1 がウェアウルフではないかと疑うかもしれません。そこで、防御力の高いガードは、翌日の夜、P1が排除したいターゲット(P5)を守ることを選択した。 P5 がチームメイトである可能性があるため、警備員は狼男の攻撃に対して P5 を支援することを選択します。
狼男の攻撃と他のプレイヤーの防御は対立アクションとみなされます。
迷彩
「変装」とは、身元を隠したり、他人に誤解を与えたりする行為を指します。情報が不完全な競争環境では、アイデンティティと意図を曖昧にすることで生存性が向上し、ゲームの目標を達成するのに役立ちます。
P1 (狼男): みなさん、おはようございます!昨夜は死者は出ませんでした。民間人として、これ以上お話しすることはできません。
上の例では、狼男が民間人であると主張していることがわかります。実際、狼男だけでなく、預言者や魔女などの重要な登場人物も、身の安全を確保するために民間人に変装することがよくあります。
リーダーシップ
「リーダーシップ」とは、他のプレイヤーに影響を与え、ゲームの進行をコントロールしようとする行為を指します。
たとえば、狼男は他人に狼男側の意図に従って行動するようにアドバイスする場合があります。
P1 (狼男): みなさん、おはようございます!昨夜何が起こったのか分かりませんが、預言者は P5 が狼男であると考えています。
P4 (人狼): P5 に同意します。また、P3 は狼男だと思います。民間人を守るために P3 に投票することをお勧めします。
上の例に示されているように、狼男は予言者に自分の身元を明らかにするよう求めます。これにより、他の AI エージェントが民間人に変装した狼男を信じる可能性があります。他人の行動に影響を与えようとするこの取り組みは、人間の行動に似た大規模な言語モデルの社会的特性を示しています。
Google、41のゲームをマスターするAIエージェントをリリース
清華大学の研究チームが提案したフレームワークは、大規模な言語モデルが経験から学習する能力を持っていることを証明し、LLMが戦略的な動作をすることも証明している。これにより、複雑なコミュニケーション ゲームにおける大規模な言語モデルのパフォーマンスを研究するための想像力が高まります。
実際のアプリケーションでは、ゲームをプレイする AI は、1 種類のゲームだけをプレイする AI では満足できなくなります。昨年 7 月、Google AI はマルチゲーム エージェントをリリースし、マルチタスク学習で大きな進歩を遂げました。エージェントをトレーニングするために、新しい意思決定トランスフォーマー アーキテクチャが採用されました。これは、少量の新しい要素で迅速に微調整できます。ゲームデータを使用すると、トレーニングがより速くなります。
41 ゲームをプレイしたこのマルチゲーム エージェントの総合的なパフォーマンス スコアは、DQN などの他のマルチゲーム エージェントの約 2 倍であり、1 つのゲームのみでトレーニングされたエージェントに匹敵することさえあります。今後、AIエージェントがゲームに参加したり、複数のゲームに同時に参加したりしたときに、どのような豊かで興味深い研究が生み出されるのか、楽しみにしたいところです。








