Command Palette
Search for a command to run...
米AGUがAI活用マニュアルを公開、6つの主要ガイドラインを明らかに

爆発的な AI アプリケーション: リスクと機会が共存する
宇宙および環境科学の分野では、天気予報や気候シミュレーション、エネルギーや水の管理などのアプリケーションで AI ツールがますます使用されています。私たちは AI アプリケーションのかつてない爆発を経験していると言えます。これに伴う機会とリスクに直面して、私たちはより慎重に考える必要があります。
米国地球物理学連合 (AGU) による追跡レポートは、AI ツールが広範に適用されていることをさらに明らかにしています。2012 年から 2022 年にかけて、要約で AI に言及する論文の数は急激に増加し、天気予報、気候シミュレーション、資源管理などにおける AI の多大な影響が浮き彫りになりました。
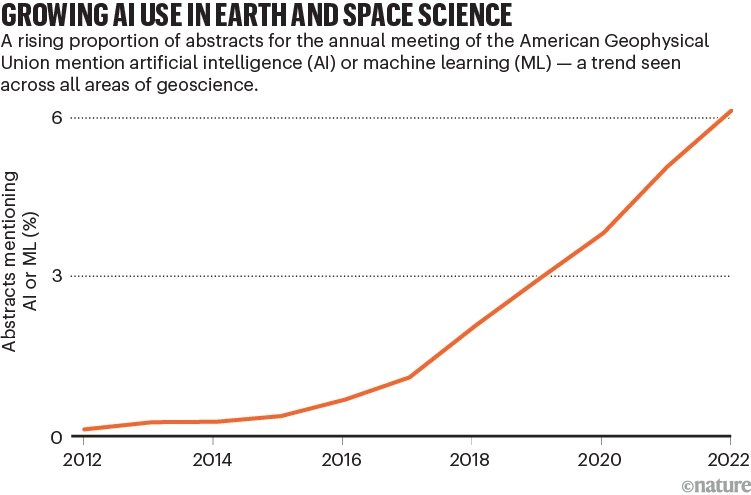
AI関連の論文出版動向
ただし、AI は強力な力を発揮する一方で、潜在的なリスクももたらします。その中には、トレーニングが不十分なモデルや不適切に設計されたデータセットが、信頼性の低い結果や潜在的な損害につながる可能性があります。たとえば、入力データ セットとして竜巻レポートが与えられた場合、より多くの気象現象が観測され報告されるため、トレーニング データは人口密集地域に偏る可能性があります。その結果、モデルは都市部の竜巻を過大評価し、地方の竜巻を過小評価して被害を引き起こす可能性があります。
この現象はまた、人々はいつ、どの程度まで AI を信頼し、起こり得るリスクを回避できるのかという重要な考えを引き起こすきっかけにもなりました。
NASAの支援を受けて、AGUは「宇宙科学および環境科学における人工知能の応用」のための一連のガイドラインを開発するために専門家を招集した。、AI アプリケーションに存在する可能性のある倫理的および道徳的問題に焦点を当て、宇宙科学および環境科学の特定の分野に限定されず、あらゆる範囲の AI アプリケーションに対するガイダンスを提供します。関連コンテンツは「Nature」に掲載されています。

Nature に論文が掲載されました
論文リンク:
https://www.nature.com/articles/d41586-023-03316-8
公式アカウントをフォローし、背景にある「ガイドライン」に返信すると論文全文のPDFが入手できます。
信頼を築くための 6 つのガイドライン
現時点では、AI/ML の信頼性の問題については、まだ様子見の姿勢が多くの人にあります。研究者/研究機関が AI に対する信頼を築くのを支援するために、AGU は 6 つのガイドラインを確立しました。
元の意味を保つために、著者は原文と一緒に翻訳を添付します。
研究者向けのガイダンス
1. 透明性、文書化、報告
AI/ML 研究では、透明性と包括的な文書化が重要です。データとコードを提供するだけでなく、参加者と、不確実性や偏見への対処を含め、参加者が問題をどのように解決したかを文書化します。コンセプト開発から応用まで、研究プロセス全体を通じて透明性を考慮する必要があります。
2. 意図性、解釈可能性、説明可能性、再現可能性、複製可能性
AI/ML を使用して研究を行う場合、意図性、解釈可能性、再現性、複製可能性を考慮する必要があります。オープンな科学的手法を優先し、モデルの解釈可能性と再現性を向上させ、AI モデルを説明する手法の開発を奨励します。
3. リスク、バイアス、影響
データセットとアルゴリズムの潜在的なリスクとバイアスを理解し、管理することは研究にとって重要です。リスクと偏見の原因、およびこれらの問題を特定する方法をより深く理解することで、有害な結果をより効果的に管理および対応でき、公共の利益と成果を最大化できます。
4. 参加型の方法
AI/ML 研究では、包括的な設計と実装のアプローチを採用することが重要です。さまざまなコミュニティ、専門分野、背景を持つ人々が、特に研究の影響を受ける可能性のあるコミュニティに対して発言権を持てるようにします。研究における包括性を確保するには、知識の共同生産、プロジェクトへの参加、コラボレーションが不可欠です。
研究機関、出版社、協会、投資家などの学術団体向けのガイダンス
5. アウトリーチ、トレーニング、および指導的な実践
学術団体は、研究者、実務者、資金提供者、および広範な AI/ML コミュニティを含む、AI/ML の倫理的使用に関するトレーニングを確実に行うために、さまざまな業界にサポートを提供する必要があります。科学協会、機関、およびその他の組織は、AI/ML の倫理トレーニングをサポートするためのリソースと専門知識を提供し、研究における AI/ML の価値と限界について社会の意思決定者を教育して、AI/ML の悪影響を軽減する責任ある意思決定を行う必要があります。
6. 組織、機関、出版社、協会、資金提供者に対する考慮事項
学術団体には、行動規範、原則、報告方法、意思決定プロセス、トレーニングなど、AI/ML の倫理問題に関する関連ポリシーを確立および管理する責任があり、価値観を明確にし、ガバナンス構造を設計する必要があります。倫理的な AI/ML 実践を確実に実施するための、文化の構築を含みます。さらに、倫理的慣行が現場全体で確実に実施されるようにするには、組織や機関全体でこれらの責任を強制することが必要です。
AIアプリケーションに関するより詳細なアドバイス
1. ギャップや偏見に注意する
AI モデルとデータに関しては、ギャップやバイアスに注意することが重要です。データの品質、カバレッジ、人種的偏見などの要因はすべて、モデル結果の精度と信頼性に影響を与える可能性があり、それが予期せぬリスクを引き起こす可能性があります。
たとえば、環境データの網羅性や現実性は、一部の領域では他の領域よりもはるかに優れています。頻繁に雲の障害物があるエリア (熱帯雨林など) やセンサーのカバー範囲が狭いエリア (極地など) では、提供されるデータの代表性が低くなります。
データセットの豊富さと質は、多くの場合、裕福な地域に偏り、長い差別の歴史を持つコミュニティなど、恵まれないグループは無視されています。このデータは、国民、企業、政策立案者に推奨事項や行動方針を提供するためによく使用されます。たとえば、健康データでは、白人からのデータに基づいてトレーニングされた皮膚科アルゴリズムは、黒人の皮膚病変や発疹の診断の精度が低かったです。
機関は研究者のトレーニング、データとモデルの精度のレビュー、AI モデルの使用を監督する専門委員会の設立に重点を置く必要があります。
2. AI モデルがどのように機能するかを説明する方法を開発する
研究者が古典的なモデルを使用して研究を行って論文を発表する場合、読者は多くの場合、基礎となるコードや関連仕様へのアクセスを提供することを期待します。しかし、研究者はそのような情報を提供することがまだ明示的に義務付けられていないため、研究者が使用する AI ツールの透明性と説明可能性が欠如しています。これは、同じアルゴリズムを使用して同じ実験データを処理したとしても、異なる実験方法では結果が正確に再現されない可能性があることを意味します。したがって、発表された研究では、研究者は他の人が結果を評価できるように、人工知能モデルを構築および展開する方法を明確に文書化する必要があります。
研究者らは、モデル間比較を実施し、データ ソースを比較グループに分けて検討することを推奨しています。業界は、AI モデルが統計的信頼レベルに見合った評価で結果を生み出すことができるように、AI モデルがどのように機能するかを説明および評価するためのさらなる標準とガイダンスを早急に必要としています。
現在、研究者と開発者は、Explainable AI (XAI) と呼ばれるテクノロジーに取り組んでいます。これは、出力を定量化または視覚化することで、人工知能モデルがどのように機能するかをユーザーがより深く理解できるようにすることを目的としています。たとえば、短期天気予報では、数分ごとに取得される大量のリモートセンシング観測データを人工知能ツールで分析できるため、過酷な気象災害を予測する能力が向上します。
出力結果がどのように達成されたのかについての明確な説明は、予測の妥当性と有用性を評価するために重要です。たとえば、火災や洪水の可能性と範囲を予測する場合、そのような解釈は、人間が公衆に警告を発するか、他の AI モデルの出力を使用するかを決定するのに役立つ可能性があります。地球科学では、XAI は入力データの特徴を定量化または視覚化して、モデル出力で何が起こっているかをよりよく理解しようとします。研究者はこれらの説明を調べて、それが合理的であることを確認する必要があります。

環境観察の評価には人工知能ツールが使用されています
3. パートナーシップを築き、透明性を促進する
研究者は、データとコードの共有、複製可能性と再現性を確保するためのさらなるテストの検討、手法のリスクとバイアスへの対処、不確実性の報告など、あらゆる段階で透明性に重点を置く必要があります。これらの手順では、メソッドのより詳細な説明が必要です。包括性を確保するために、研究チームには、さまざまな種類のデータを扱う専門家だけでなく、データに貢献したコミュニティ メンバーや調査結果の影響を受ける可能性のあるコミュニティ メンバーを含める必要があります。たとえば、ある AI ベースのプロジェクトでは、カナダのタル族の伝統的な知識と、先住民族以外の方法で収集されたデータを組み合わせて、水産養殖に最適な地域を特定しました。 (詳細については go.nature.com/46yqmdr を参照してください)。

水産養殖プロジェクトの写真
4. データのキュレーションと管理に対するサポートを継続する
学際的な研究分野におけるデータ、コード、およびソフトウェアのレポート要件は、FAIR の原則 (検索可能、アクセス可能、相互運用可能、再利用可能) に準拠する必要があります。 AI と機械学習に対する信頼を築くには、バグと解決策が公開された、認知され、品質が信頼できるデータセットが必要です。
現在の課題はデータの保管です。汎用リポジトリの普及により、データの出所追跡や自動アクセスに影響を与えるメタデータの問題が発生する可能性があります。一部の高度な主題研究データ リポジトリは、品質チェックと情報補足サービスを提供していますが、これには通常、人的資源と時間のコストの投資が必要です。
さらに、この記事では、リポジトリに対する財政的サポート、さまざまなリポジトリ タイプの制限、ドメイン固有のリポジトリに対する需要の欠如などの問題についても取り上げています。学術団体、資金提供機関などは、適切なデータ リポジトリのサポートと維持に継続的な財政投資を提供する必要があります。
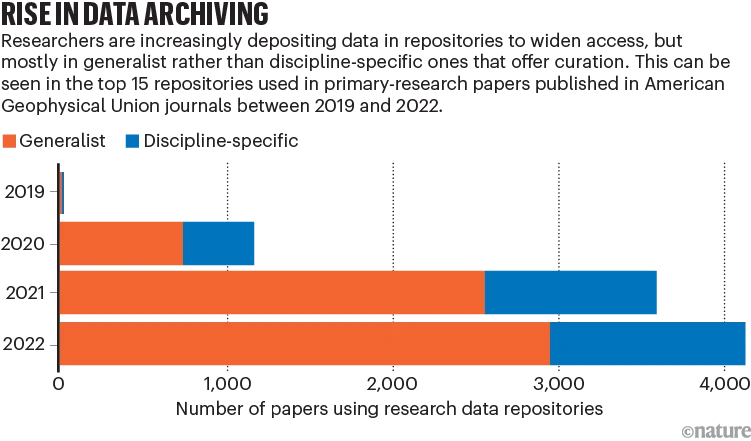
研究者は汎用データ リポジトリを選択する傾向が高まっています
5. 長期的な影響を検討する
科学における人工知能と機械学習の広範な利用を研究する際には、これらのテクノロジーが社会的格差を削減し、信頼を高め、さまざまな意見や意見に積極的に対応できるようにするための長期的な影響に焦点を当てることが重要です。
AI活用については中国の言うことを聞く
近年、我が国のAI分野でも「AIをどう使うか、AIをどう活用するか」が大きな話題となっている。
今年の Two Sessions の代表者の目には、人工知能は、生成 AI (AIGC)、大規模な事前トレーニング モデル、知識駆動型 AI は業界に新たな機会をもたらしており、技術開発の「時間枠」をつかむ必要があります。
Xiaomi Groupの創設者兼会長兼最高経営責任者(CEO)であるLei Jun氏は、科学技術イノベーション産業チェーンを奨励および支援し、バイオニックロボット産業の計画と配置を促進することを提案し、自動車のライフサイクル全体におけるデータセキュリティ基準の策定を加速した。業界の発展を導き、自動車データの共有と利用を促進するための自動車データ共有メカニズムとプラットフォームを構築します。
360 の創設者である周宏儀氏は、中国の「Microsoft + OpenAI」の組み合わせを生み出し、大規模モデル技術の研究を主導し、オープンソースのクラウドソーシングのオープンイノベーションエコシステムを構築したいと考えています。
学者のZhang Boli氏は、スマート医薬品の主要技術と機器の研究開発を支援し、バイオ医薬品機器の開発を促進するために、大規模なバイオ医薬品製造プロジェクトを立ち上げることを提案した。
2 つのセッションの代表者と委員会メンバーが人工知能の取り組みについて非常に楽観的であることがわかります。私たちは、AI がテクノロジーに力を与えるだけでなく、信頼を築き、慎重に使用するという方針のもと、企業や社会の発展にさらに役立つことも期待しています。
参考文献:
https://www.nature.com/articles/d41586-023-03316-8
https://doi.org/10.22541/essoar.168132856.66485758/v1








