Command Palette
Search for a command to run...
30 人の学者が共同で Nature レビューを発表、AI が科学研究パラダイムをどのように再構築するかを分析した 10 年間のレビュー

科学的発見は、仮説形成、実験計画、データ収集、分析など、相互に関連するいくつかの段階を含む複雑なプロセスです。近年、AI と基礎科学研究の統合がますます深まり、科学者は AI の助けを借りて科学研究の進歩を加速し、科学研究結果の実装を促進することができます。
権威ある学術雑誌「Nature」に、スタンフォード大学コンピュータサイエンス・遺伝子工学部の博士研究員Hanchen Wang氏、ジョージア工科大学計算科学工学部のTianfan Fu氏、および米国科学院のYuanqi Du氏による論文が掲載された。コーネル大学コンピュータサイエンス学部 他 30名、この論文は、過去 10 年間の基礎科学研究における AI の役割をレビューし、残された課題と欠陥を提案します。
この記事はその論文を要約したものです。
論文全文を読む:https://www.nature.com/articles/s41586-023-06221-2

AIと基礎科学研究を組み合わせた事例 出典: 論文の原文、HyperAI により中国語に翻訳
01 AI を活用した科学研究データの収集と整理
実験プラットフォームによって収集されるデータの規模と複雑さは増大し続けるため、高速で生成されたデータを選択的に保存および分析するには、リアルタイム処理とハイパフォーマンス コンピューティング (HPC) に依存する必要があります。
データの選択
粒子衝突実験を例にとると、毎秒 100 TB 以上のデータが生成され、既存のデータ伝送およびストレージ技術に大きな課題をもたらします。これらの物理実験では、99.99% を超えるメタデータをリアルタイムで検出し、無関係なデータを破棄する必要があります。ディープラーニングや自動オフエンコーダーなどのテクノロジーは、同様の科学研究における異常なイベントを特定するのに役立ち、データの送信と処理のプレッシャーを大幅に軽減します。
現在、これらの技術は物理学、神経科学、地球科学、海洋学、天文学などの分野で広く使用されています。
データの注釈
擬似ラベル付けとラベル伝播は、煩雑なデータ アノテーションを置き換える上で非常に重要であり、モデルが少量の正確にラベル付けされたデータだけで大量のデータに自動的にラベル付けできるようになります。
データ生成
自動データ強化と深層生成モデルを通じて、追加の合成データ ポイントを生成してトレーニング データを拡張できます。実験により、敵対的生成ネットワーク (GAN) が多くの分野でリアルな画像を合成できることが証明されました。この範囲は、粒子衝突イベント、病理学的断面、胸部 X 線、磁気共鳴コントラスト、三次元 (3D) 材料の微細構造、遺伝子配列に対するタンパク質の機能などをカバーします。
データの最適化
AI により、画像の解像度が大幅に向上し、ノイズが低減され、真円度測定時の誤差が排除されるため、各現場での高精度の一貫性が維持されます。アプリケーション例には、ブラック ホールなどの時空間領域の視覚化、物理的な粒子衝突のキャプチャ、生細胞画像の解像度の向上、さまざまな生物学的環境における細胞種類の検出の向上などが含まれます。
02 科学データの意味のある表現を学ぶ
ディープラーニングは、さまざまな抽象レベルで科学データの意味のある表現を抽出し、最適化できます。高品質の表現では、簡潔でアクセスしやすい状態を維持しながら、データ関連情報をできるだけ多く保持する必要があります。これらの要件を満たす 3 つの新しい戦略を次に示します。幾何事前分布、自己教師あり学習、言語モデリング。
幾何事前分布
幾何学と構造は科学研究にとって重要です。対称性は幾何学の重要な概念です。空間方向に安定しており、変化しません。科学的な画像分析では、学習された表現に幾何学的事前分布を統合することが効果的であることが証明されています。
幾何学的な深層学習
グラフ ニューラル ネットワークは、基礎となる幾何学的構造およびリレーショナル構造を含むデータセットに対する深層学習の主な方法となっています。科学的問題に応じて、研究者は複雑なシステムを捉えるためにさまざまなグラフ表現を開発してきました。
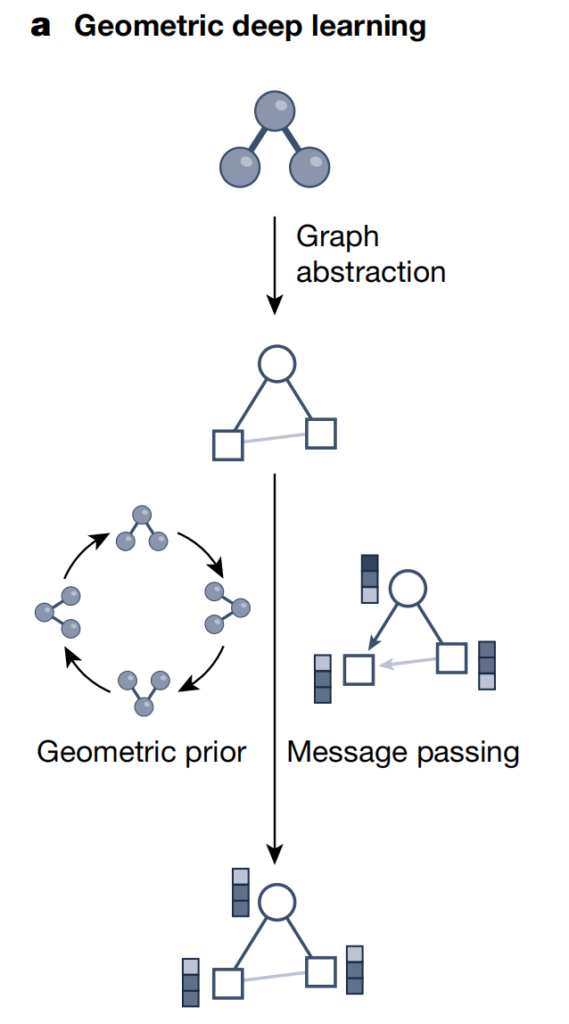
上の図に示すように、幾何学的な深層学習では、グラフ構造と神経情報伝達戦略を使用して、分子/材料などの科学データの幾何学、構造、対称情報を統合します。この方法では、他の幾何学的事前条件 (不変性や算術シーケンス制約など) を考慮しながら、グラフ構造のエッジに沿ってニューラル情報を交換して潜在表現 (埋め込みベクトル) を生成します。したがって、幾何学深層学習では、複雑な構造情報を深層学習モデルに組み込むことで、基礎となる幾何学データセットをよりよく理解して処理できます。
自己教師あり学習
自己教師あり学習を使用すると、モデルは明示的なラベルに依存せずにデータセットの一般的な特徴を学習でき、下流の学習タスクを実行するためにモデルを微調整する前に、大規模なデータセットから学習するための重要な前処理ステップとして使用できます。ラベルのないデータから大規模に転送可能な特徴。幅広い科学的理解を備えたこのような事前トレーニング済みモデルは、普遍的なターゲット予測子となります。さまざまなタスクに適応できるため、効率が向上し、純粋に監視された方法を超えています。
上の図に示すように、衛星画像などのさまざまなサンプルを効果的に表現するには、それらの類似点と相違点の両方を捉える必要があります。対照学習などの自己教師あり学習戦略は、強化されたピア データを生成し、正のデータを調整し、負のデータ ペアを分離することにより、この目標を達成できます。この反復プロセスにより埋め込みが強化され、その結果、有益な潜在表現が得られ、下流の予測タスクのパフォーマンスが向上します。
言語モデリング
マスク言語モデリングは、自然言語と生物学的配列の自己教師あり学習によく使われる方法です (下図を参照)。

自然言語処理と生物学的配列処理は相互に影響を及ぼします。トレーニング プロセス中の目標はシーケンス内の次のトークンを予測することですが、マスクベースのトレーニングでは、自己教師ありタスクは双方向シーケンス コンテキストを使用してシーケンス内のマスクされたトークンを回復することです。タンパク質言語モデルは、アミノ酸配列をコード化し、構造的および機能的特性を捕捉し、ウイルス変異体の進化的適合性を評価することができます。生化学シーケンスを扱う場合、化学言語モデルは広大な化学空間を効果的に探索できます。
上の図に示すように、マスクされた言語モデリングは、自然言語や生物学的シーケンスなどのシーケンス データのセマンティクスを効果的にキャプチャできます。この方法では、入力内のマスク要素を Transformer モジュールにフィードします。これには、位置エンコードなどの前処理ステップが含まれます。灰色の線はセルフ アテンション メカニズムを表し、色の深さはマスクされていない入力の表現を組み合わせてマスクされた入力を正確に予測します。このメソッドは、入力の多くの要素にわたってこの自動プロセスを繰り返すことにより、高品質のシーケンス表現を生成します。
変圧器のアーキテクチャ
Transformer は、グラフ ニューラル ネットワークと言語モデルを統合し、自然言語処理を支配し、地震信号検出、DNA およびタンパク質の配列モデリング、生物学的機能に対する配列変動の影響のモデリング、記号回帰などの分野で使用されて成功しています。
神経演算子
関数空間間のマッピングを学習することにより、ニューラル オペレーターは離散化不変であり、あらゆる入力離散化に取り組むことができ、メッシュ細分化の際に制限値に収束します。ニューラル オペレーターがトレーニングされると、再トレーニングすることなく任意の解像度で評価できます。
03 AIを活用した科学的仮説(仮説)の生成
AI は、ノイズの多い観測から候補となる記号表現を特定することで仮説を生成できます。これらは、オブジェクトの設計、ベイズ事後確率の仮説の立て方の学習、およびそれらを使用して科学データや知識と互換性のある仮説を生成するのに役立ちます。
科学的仮説のブラックボックス予測子
弱教師あり学習は、ノイズの多い、限定された、または不正確な監視がトレーニング信号として使用されるモデルをトレーニングするために使用できます。
AI メソッドは高度なシミュレーションを通じてトレーニングされており、大規模な分子ライブラリを効果的にスクリーニングするために使用されています。ゲノミクスでは、Transformer アーキテクチャが DNA 配列を使用して遺伝子発現値を予測するようにトレーニングされており、それによってタンパク質のフォールディングにおける遺伝的変異を特定します。 AlphaFold2 は、アミノ酸配列の 3D 原子座標からタンパク質を予測できます。素粒子物理学では、陽子に固有のチャーム クォークを特定するには、考えられるすべての構造をスクリーニングし、実験データをすべての潜在的な構造に当てはめることが必要です。
順方向の問題に加えて、逆方向の問題を解決するために AI がますます使用されています。
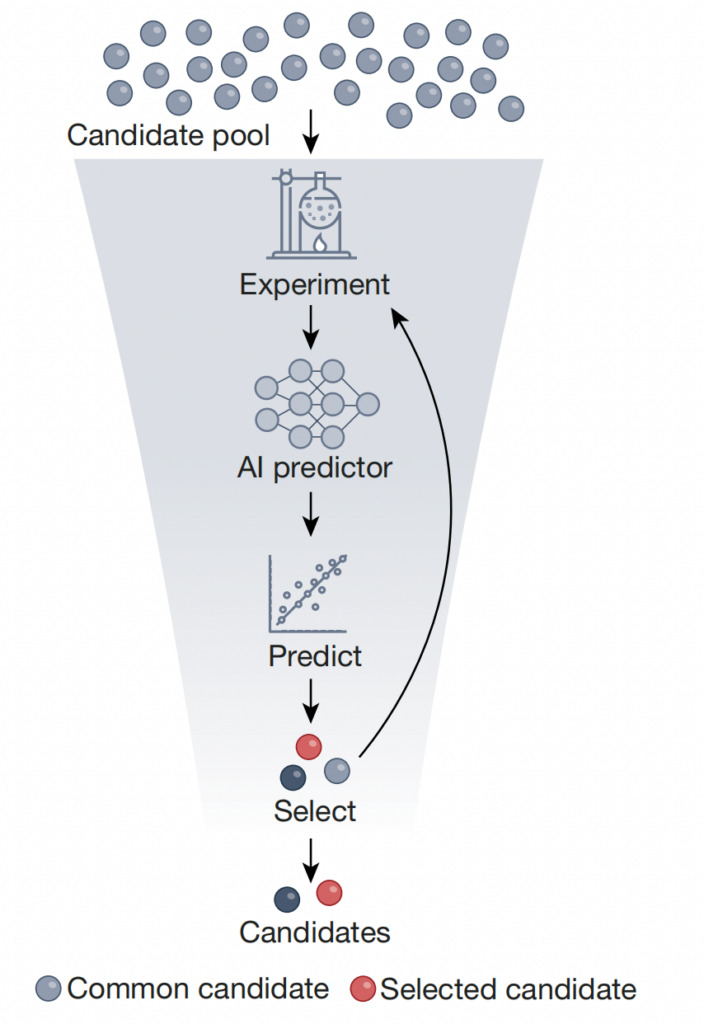
上の図に示すように、ハイスループット スクリーニングとは、実験的に生成されたデータ セットでトレーニングされた AI 予測子を使用して、理想的な特性を持つ少数のターゲット オブジェクトを選別することを指します。これにより、候補オブジェクト ライブラリの合計サイズが数桁減少します。この方法では、自己教師あり学習を使用して、多数の非スクリーニング オブジェクトで予測子を事前トレーニングし、ラベル付きの読み出しとフィルター処理されたオブジェクトのデータセットで予測子を微調整できます。研究室での評価と不確実性の定量化により、このアプローチを改良してスクリーニングプロセスを合理化し、費用対効果と時間効率を改善し、最終的に候補化合物、材料、生体分子の同定を加速することができます。
組み合わせ仮説空間を探索する
手動で設計されたルールに依存する従来の方法と比較して、AI 戦略を使用して各検索の報酬を評価し、より価値の高い検索方向を特定できます。
最適化問題の場合、進化的アルゴリズムを使用して記号回帰タスクを解決できます。。組み合わせ最適化は、分子設計の各ステップが個別の意思決定プロセスとなる、望ましい薬物特性を持つ分子の発見などのタスクにも適用できます。さらに、強化学習手法は、タンパク質発現の最大化、アマゾン平原における水力発電の計画、粒子加速器パラメータ空間の探索など、さまざまな最適化問題にうまく適用されています。
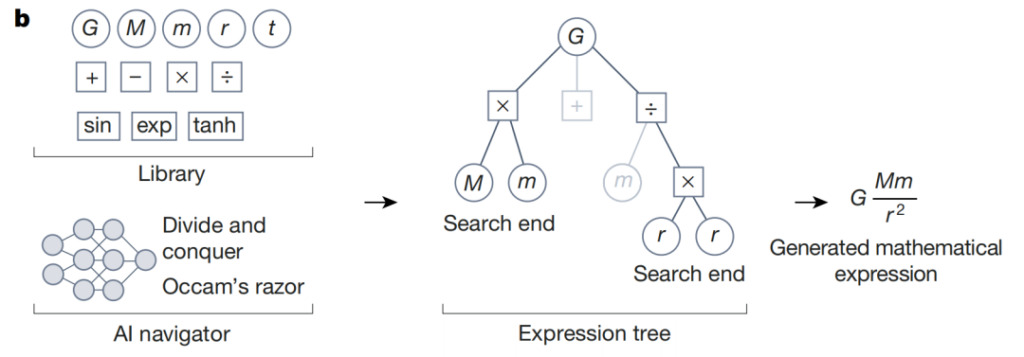
上の図に示すように、シンボリック回帰プロセス中に、AI ナビゲーターは強化学習エージェントによって予測された報酬と設計基準 (オッカムの剃刀など) を使用して、候補仮説の最も有望な要素に焦点を当てます。次の例は、ニュートンの重力の法則の数学的表現の背後にある推論を示しています。スコアの低い検索パスは、シンボリック式ツリーに灰色の枝として表示されます。予測される最高の報酬に関連する行動に導かれ、この反復プロセスにより、データと一貫性があり、他の設計基準を満たす数式が得られます。
微分可能な仮説空間を最適化する
微分可能空間は、局所的な最適解を効果的に見つけることができる勾配ベースの方法に適しています。勾配ベースの最適化を有効にするには、通常、次の 2 つのアプローチが使用されます。
* VAE のようなモデルを使用して、離散候補仮説を潜在的に微分可能な空間にマッピングします。
* 離散仮定を微分可能空間内で最適化できる微分可能オブジェクトに緩和します (この緩和は、離散変数を連続変数に置き換えたり、元の制約のソフト バージョンを使用したりするなど、さまざまな形式を取ることができます)。
天体物理学では、事前学習されたブラック ホール波形モデルに基づいて重力波検出器のパラメーターを評価するために VAE が使用されてきました。この方法は、従来の方法よりも 6 桁高速です。材料科学では、熱力学則をオートエンコーダーと組み合わせて、結晶構造マップを識別するための解釈可能な潜在空間を設計します。
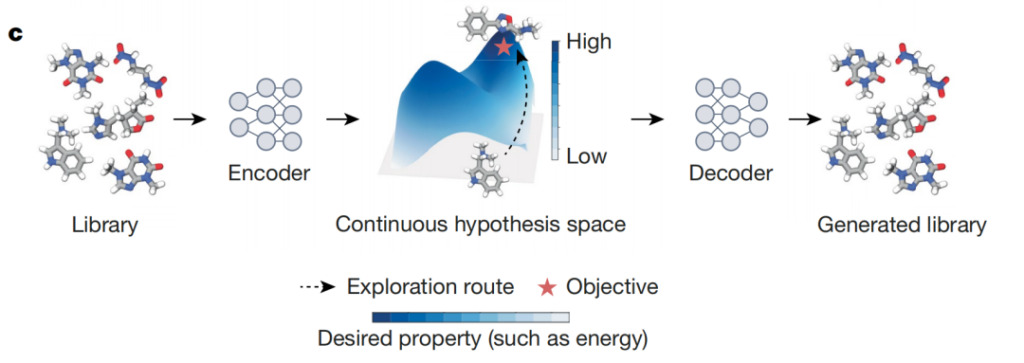
上の図に示すように、AI 微分器は、離散オブジェクト (化合物など) を微分可能な連続潜在空間内のポイントにマッピングできるオートエンコーダー モデルです。このスペースにより、膨大な化学ライブラリから特定の生化学エンドポイントを最大化する化合物を選択するなど、ターゲットの最適化が可能になります。理想的なブループリントは学習された潜在空間を表しており、より高い予測スコアを持つオブジェクトが集中している領域を濃い色で示しています。この潜在空間を使用すると、AI 差別化ツールは、赤い星アノテーションの期待される特性を最大化するオブジェクトを効率的に識別できます。
04 AIを活用した実験とシミュレーション
コンピューター シミュレーションは、高価な実験室での実験に代わるものであり、より効率的で柔軟なテストの可能性を提供します。ディープラーニングは、効率的なテストのために仮説を特定および洗練し、コンピューターシミュレーションで観察を仮説に結びつけることを可能にします。
科学的仮説を効率的に評価する
AI システムは実験計画と最適化ツールを提供します。これらのツールは、従来の科学的手法を強化し、必要な実験の数を減らし、リソースを節約できます。
具体的には、AI システムは、実験テストの 2 つの重要なステップ、つまり計画とガイダンスを支援できます。 AI 計画は、実験の設計、効率の最適化、未知の領域の探索に対する体系的なアプローチを提供します。同時に、AI ガイダンスは実験プロセスを高収量の仮説に向け、システムが以前の観察から学習して実験プロセスを調整できるようにします。これらの AI 手法には、モデルベース (シミュレーションと事前知識を使用) の手法と、機械学習アルゴリズムのみに基づくモデルフリーの手法があります。
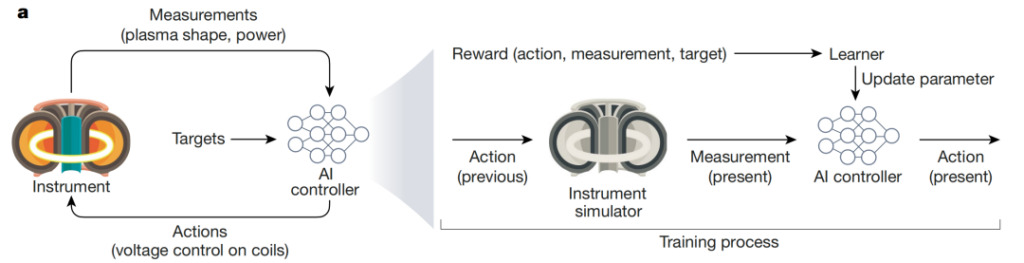
上の写真は、複雑で動的な核融合プロセスを制御するための AI の使用を示しています。Degrave らは、トカマク炉内の磁場を通じて核融合を制御できる AI コントローラーを開発しました。 AI エージェントは、電圧レベルとプラズマ構成のリアルタイム測定値を受け取り、実験目標 (通常の電力供給の維持など) を達成するために磁場を制御するアクションを実行します。コントローラーはシミュレーションを通じてトレーニングされ、報酬関数を使用してモデル パラメーターを更新します。
シミュレーションを利用して仮定から観測値を導き出す
既存のコンピューター シミュレーション テクノロジーは、システムの基礎となるメカニズムに対する人間の理解と認識に大きく依存しており、AI システムは複雑なシステムの主要なパラメーターにより正確かつ効率的に適応し、複雑なシステムを制御できる微分方程式を解き、複雑なシステムの状態をモデル化できます。コンピュータシミュレーションを強化するためのシステム。
分子力場を例に挙げると、それらは解釈可能ですが、さまざまな機能の表現には制限があり、生成プロセスには強い帰納的バイアスと豊富な科学的知識が必要です。分子シミュレーションの精度を向上させるために、高価で正確な量子力学データに適応した AI ベースの神経ポテンシャルが開発され、従来の力場に代わりました。
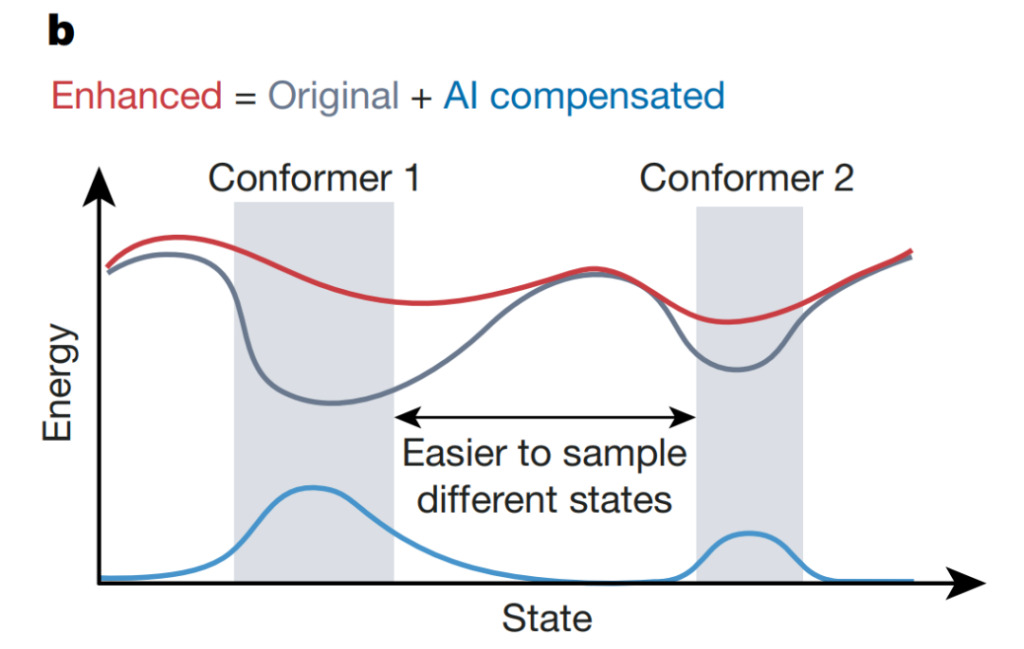
複雑なシステムの計算シミュレーションにおいて、AI システムはタンパク質の立体構造間の遷移などの異常なイベントの検出を高速化できます。上の図に示すように、Wang らはニューラル ネットワークに基づく不確実性推定器を使用して、元の位置エネルギー (ポテンシャル) を補償するように位置エネルギーの増加を誘導し、システムが極小値 (灰色) を取り除くことができます。構成スペースをより迅速に探索できます。このアプローチにより、シミュレーションの効率と精度が向上し、複雑な生命現象のより深い理解につながります。
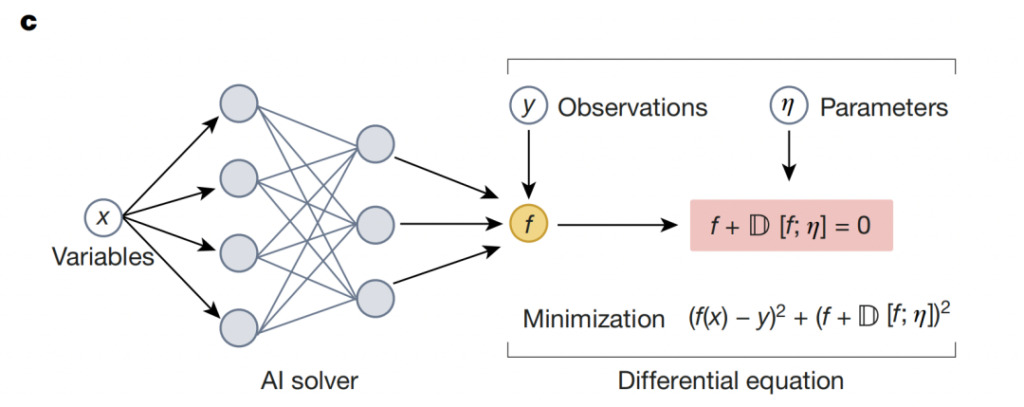
ニューラル ソルバーは物理学と深層学習の柔軟性を組み合わせます:ドメイン知識に基づいてニューラル ネットワークを構築する
05 科学のための AI の道のりは長い
AI システムは科学的理解に貢献し、データからモデルを構築し、データとシミュレーションやスケーラブル コンピューティングを組み合わせることで、視覚化や検出が難しいプロセスやオブジェクトを研究し、新しいアイデアを系統的に生成できることが証明されています。ただし、AI 使用時のセキュリティとプライバシーの問題を確保するために、このプロセスは依然として成熟したテクノロジーの導入と切り離せないものです。
科学研究で AI を責任を持って使用するには、研究者は AI システムの不確実性、エラー、実用性レベルを測定する必要があります。 AI システムの継続的な開発により、AI はこれまで手の届かなかった科学的発見への扉を開くことが期待されていますが、理論、手法、ソフトウェアおよびハードウェアのインフラストラクチャをサポートするにはまだ長い道のりがあります。
参考文献:








