Command Palette
Search for a command to run...
千年暗号の新たな解釈、ディープマインドがギリシャ語碑文を解読するためのイサカを開発

碑文や石板は、過去の文明の思想、文化、言語を体現したものです。数千年前に書かれた暗号を解読するには、碑文作成者はテキストの復元、時間の帰属、地域の帰属という 3 つの主要なタスクを完了する必要があります。
主流の研究方法は「文字列照合」、つまり、記憶に頼ったり、コーパスにクエリを実行して類似したフォントの碑文を照合したりするものですが、結果の混乱や誤った判断につながります。
この目的を達成するために、DeepMind とヴェネツィアのフォスカリ大学は、AI を使用して人類学者がギリシャ語碑文を解読できるように支援する Ithaca を共同開発しました。
著者 | ゼロを追加
編集者 | 三陽市
エピグラフィーは、過去の文明の思想、文化、言語を結びつける、碑文、タブレット、古代の碑文の研究です。現在、学術コミュニティは、これらの遺産をどのように深く研究し、理解するかという重要な問題に直面しています。
一般に、碑文と碑文を解釈するには、碑文作成者は次の 3 つの基本的なタスクを完了する必要があります。
- テキスト修復:テキストの欠落部分を補完します。
- 年代学的帰属: 碑文が書かれた時期を特定します。
- 地理的帰属: 碑文が書かれた最初の場所を決定します。
これらのタスクを完了するには、エピグラファーは文脈と既存のコーパスに基づいて多数の比較研究を行う必要があります。デジタルコーパスの登場により、研究者の負担はある程度軽減されるものの、文字列照合手法が採用されることで混乱や結果の誤判断が生じることがよくあります。同時に、古いために多くの碑文が損傷したり紛失したりするため、作業はさらに複雑になります。

碑文修復図
AI は、複雑な統計パターンを発見して適用して、人間には処理が難しい大量のデータを分析するのが得意です。。したがって、DeepMind とヴェネツィアのカフォスカリ大学の研究者は、テキストの復元、時間の帰属、および地域の帰属において碑文作者を支援するために Ithaca を共同開発しました。
実験により、イサカテキスト修復作業の精度は62%に達し、時間帰属誤差は30年以内、地理帰属精度は71%に達し、良好な相乗効果があることが確認されました。関連論文は「Nature」に掲載されています。

関連する結果が「Nature」に掲載されました
紙を入手してください:
https://www.nature.com/articles/s41586-022-04448-z
Ithaca の関連コードは GitHub プラットフォームでオープンソース化されており、エピグラファーはパブリック インターフェイスを使用して研究を行うこともできます。
ソースコード: https://GitHub.com/deepmind/Ithaca
パブリックインターフェース: https://Ithaca.deepmind.com
実験プロセス
データセット
機械操作可能な碑文コレクション I.PHI
研究者らは、パッカード人文科学研究所のギリシャ碑文の検索可能な公開データセットである PHI に基づいて研究を実施しました。
注: PHI は、パッカード人文科学研究所の検索可能なギリシャ語碑文の公開データセットの略です
機械の操作を容易にするために、研究者は PHI 内のテキストをフィルタリングし、デジタル ID を割り当て、選択したテキストに対応する注釈の位置と時間情報を割り当て、最終的に I.PHI データセットを取得しました。
I.PHI データセットは現在、機械で操作可能な最大の碑文データセットであり、78,608 個の碑文が含まれています。。

I.PHI データセットの例
アルゴリズムトレーニング:主要3業務の研修を実施
1. テキスト修復: クロスエントロピー損失関数を使用して入力テキストの一部をマスクし、マスクされた文字を予測するように Ithaca モデルをトレーニングします。
2. 時間の帰属: イサカは 10 年間隔で、紀元前 800 年を、ターゲット確率分布と呼ばれる等しい確率の期間に離散化しました。カルバック・ライブラー発散を使用して、予測確率分布とターゲット確率分布の差を最小限に抑えます。
3. 地域属性: クロスエントロピー損失関数を使用し、地域メタデータをターゲット ラベルとして使用し、平滑化係数 10% のラベル平滑化テクノロジを適用して過剰適合を回避します。
これに基づいて、Ithaca は、LAMB オプティマイザーを 3 × 10 まで使用して、Google Cloud Platform 上の 128 個の TPU v4 ポッドで 8,192 テキストのバッチ サイズで 1 週間のトレーニングを実施しました。-4 学習率は Ithaca パラメータを最適化します。
モデル構造:イサカモデルは4つのパーツで構成されています
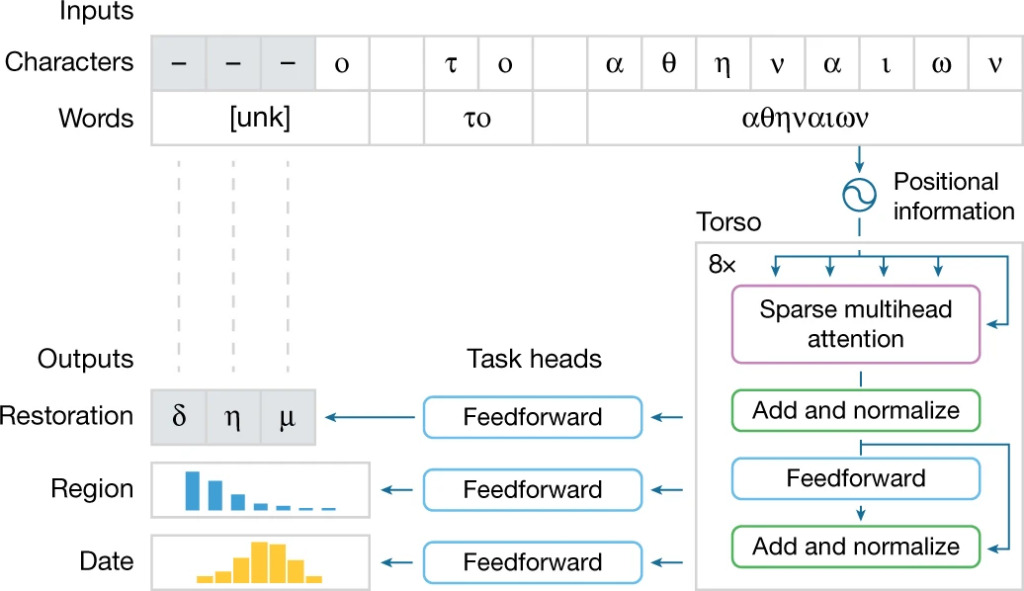
Ithaca モデルのタスク処理フロー
Ithaca モデルの構造は次の 4 つの部分に要約できます。
1. 入力: 入力テキストを文字と単語として処理して、Ithaca が個々の文字を理解し、それらを単語に統合して文脈を理解できるようにします。不明な単語や破損した単語は特殊記号「unk」に置き換えられます。
2. 胴体: Ithaca の胴体は、重畳された Transformer ニューラル ネットワーク アーキテクチャを採用しており、アテンション メカニズムを使用して、モデルの意思決定プロセスに対する入力文字や単語の影響を測定します。
トランク部分では、Ithaca は入力テキストと位置情報を結合し、入力文字の数に等しい長さのシーケンスに正規化します。このシーケンス内の各項目は 2,048 次元の埋め込みベクトルです。シーケンスは 3 つの異なるタスク ヘッドに転送されます。
3. タスク ヘッド: Ithaca には 3 つの異なるタスク ヘッドがあり、各ヘッドは浅いフィードフォワード ニューラル ネットワークで構成され、テキスト修復、時間的帰属、および地域的帰属タスクの処理に特化しています。
4. 出力: 3 つのタスク ヘッドはそれぞれ対応する結果を出力します。
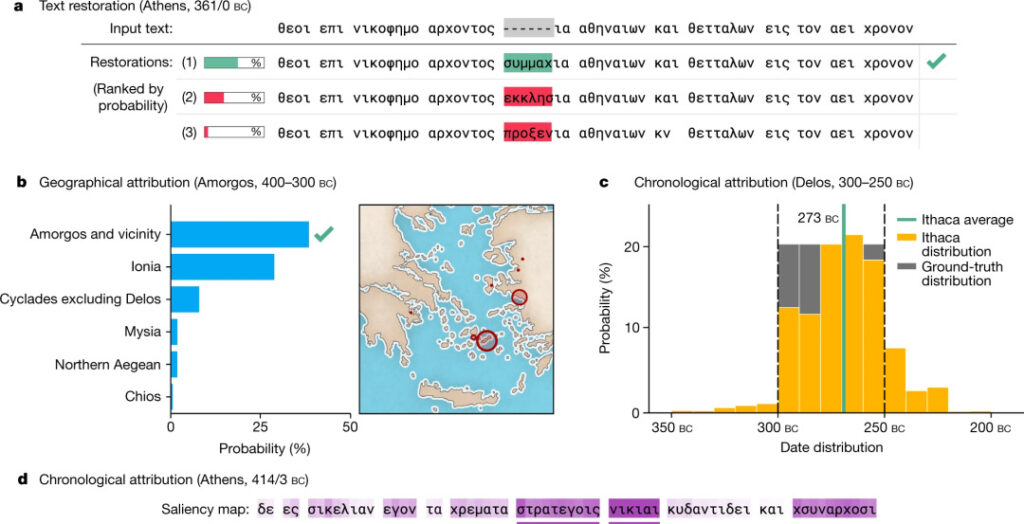
イサカの出力結果
- テキスト修復: Ithaca は 3 つの欠落文字を予測し、確率でランク付けされた上位 20 のデコード予測のセットを提供します (上記の a)。
- 地域属性: Ithaca は入力テキストを 84 の地域に分割し、マップとヒストグラムを使用して、可能な地域予測ランキング リスト (上記 b) を直感的に実装します。
- 時間的帰属: 時間的帰属タスクの解釈可能性を拡張するために、Ithaca は紀元前 800 年から西暦 800 年まで遡り、単一の日付値を出力するのではなく、日付のカテゴリ分布を予測します (上記の c)。
モデルのトレーニング結果
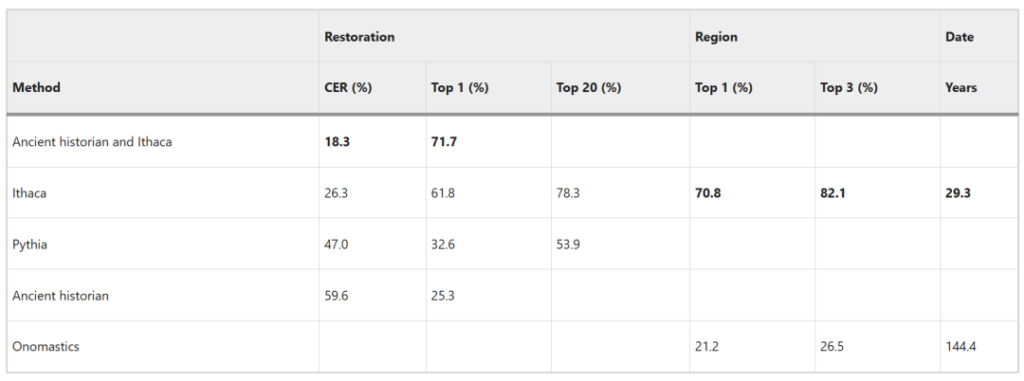
総合比較:イサカは優れたパフォーマンスを持っています
* 4つの比較メカニズム
1. 古代の歴史家: 人類学者はトレーニング セットを使用してテキスト内の類似点を見つけ、それらをイサカの結果と比較します。
2. 古代歴史家とイサカ: イサカは、碑文作者がイサカと人類学者の間の相乗効果を評価するために 20 の可能な修復を提供します。
3. Pythia: テキスト修復タスク用のシーケンス間リカレント ニューラル ネットワーク。Ithaca のテキスト修復パフォーマンスを評価します。
4. オノマティクス: 研究者たちは、時間と空間におけるギリシャ名の既知の分布を使用して、一連のテキストの時間と地理的帰属を完了し、イサカの時間と地理的帰属のパフォーマンスを評価しました。
※3大評価指標
1. 文字誤り率 (CER、文字誤り率): テキスト修復タスクを評価し、最も高い予測修復シーケンスとターゲット シーケンスの間の正規化された差を計算します。
2. 上位 k 位の精度: テキスト修復タスクまたは地域属性タスクを評価し、正しいラベルを含む予測結果の中で最も確率が高い上位 k 位の結果の割合を計算し、一般に上位 1 位の精度を使用します。
3. 距離メトリック (方法): 時間帰属タスクを評価し、予測分布の平均値とグラウンド トゥルース間隔の間の距離を年単位で計算します。
※実験結果
1.文字の修復

テキスト修復タスク
a:オリジナルの碑文。
b: ロードス・オズボーンの修復された碑文。
c: Pythia で修復されたバージョン。ローズ オズボーン バージョンと 74 個の不一致があります。
d: イサカ復元バージョン。ロードス オズボーン バージョンと 45 個の不一致があります。
図の正しく修復された部分は緑色で示され、エラーは赤色で強調表示されます。
元の碑文 (IG II² 116) には 378 文字が欠けています。2003 年にローズ オズボーンによって完了した修復に基づくと (図 b)、イサカの CER は 26.3% で、トップ 1 の精度は 61.8% に達します。
イサカの CER はエピグラファーと比較して 2.2 倍低いです。 Ithaca のトップ 20 の予測精度は 78.3% で、Pythia の 1.5 倍です。
2. 地理的帰属
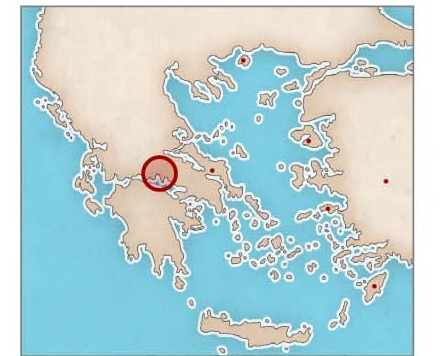
地理的帰属タスク
地理的帰属タスクでは、Ithaca はトップ 1 の精度 70.8%、トップ 3 の精度 82.1% を達成しました。上の画像は、イサカがマニュミッションの碑文をデルフィ地域に正しく帰属させたことを示しています。
3. 時間の帰属
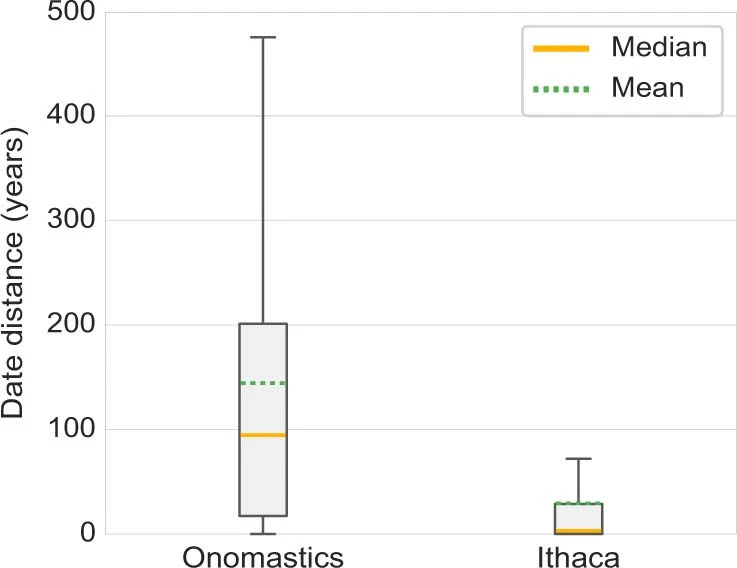
時間的帰属タスク
時間帰属タスクでは、人間の専門家の予測の平均は 144.4 年、中央値は 94.5 年でしたが、イサカの予測とグラウンドトゥルースの間隔との平均ギャップは 29.3 年、ギャップの中央値はわずか 3 年でした。
3 つのタスクにおける Ithaca のパフォーマンスに基づいて、結果は次のように要約されます。
人間の専門家や Pythia と比較して、Ithaca は 3 つの主要なタスクで優れたパフォーマンスを実証しました。
人間の専門家が Ithaca と協力したところ、CER 18.3% とトップ 1 の精度 71.7% が達成されました。、エピグラファーが単独で作業した場合と比較して 3.2 倍および 2.8 倍の改善が見られ、単独でタスクを完了した Ithaca と比較して大幅な改善が見られました。イサカの優れた相乗効果を実証。
イサカの実験結果の比較
時間の帰属:私争いを解決する
一部の碑文の時間帰属については議論の余地があり、伝統的な時間帰属に使用されるシグマ年代測定基準は、これらの碑文が紀元前 446/5 年より前のものであるか、またはそれ以降であるかを判断することはできません。
以下の碑文は伝統的に紀元前 446/5 年の日付とされていますが、最近、紀元前 424/3 年と日付が変更されました。

物議を醸した碑文(部分)
この物議を醸している碑文グループは I.PHI データセットに存在しており、イサカの時間帰属の結果は、シグマ年代測定基準に基づく伝統的な歴史的解釈を覆し、新たに発見された地上真実とは平均 5 年異なっています。
これは次のことを証明します。Ithaca は、歴史家が日付の範囲を絞り込み、歴史的出来事の時期を推定する精度を向上させるのに役立ちます。
AI 対人間: 1 + 1 > 2?
Ithaca の結果出力部分は非常に興味深いものです。これは単一の答えを出力するのではなく、研究者が選択できるさまざまな結果を提供します。
これは、他の AI 開発者やユーザーから学ぶ価値があります。AI の出力に依存するのではなく、AI を使用して「道を見つけ」、いくつかの間違った答えを排除し、独立した思考の深さと幅を広げる方が良いでしょう。
AI のコンピューティング能力と人間の創造性と深い思考を組み合わせた Ithaca は、AI と連携して作業するためのパラダイムを開拓するのに役立ちます。
将来的には、AI と人間の学者が協力して「1+1 > 2」の目標を達成することを期待しています。
参考文献:
https://www.nature.com/articles/s41586-022-04448-z
https://www.nature.com/articles/d41586-023-03212-1
- 以上 -








