Command Palette
Search for a command to run...
山東大学、有機化合物の逆合成経路を4ステップで特定する解釈可能な深層学習アルゴリズムRetroExplainerを開発

逆合成は、目的の生成物を効率的に合成するための一連の適切な反応物を見つけることを目的としています。これは有機合成経路を解く重要な方法であり、有機合成経路設計の最も簡単かつ基本的な方法でもあります。
初期の逆合成研究は主にプログラミングに依存していましたが、後にこの研究は AI に引き継がれました。しかし、既存の逆合成法は主にシングルステップ逆合成に焦点を当てており、解釈可能性が低く、分子の短距離情報と長距離情報の両方を考慮することができないため、性能が制限されています。
この目的を達成するために、山東大学の Wei Leyi 氏と中国電子科学技術大学の Zou Quan 氏の研究グループは共同で RetroExplainer を開発しました。この説明可能な深層学習アルゴリズムは、有機化合物の逆合成ルートを 4 つのステップで特定し、簡単に入手できる反応物を提供できます。 RetroExplainer は、有機化学の逆合成研究に強力なツールを提供することが期待されています。
著者 | 雪才
編集者 | 三陽
有機化学逆合成は、目的の生成物を効率的に合成するための一連の適切な反応物を見つけることを目的としています。。この工程は、コンピュータ支援合成において欠かせない基本的な作業です。
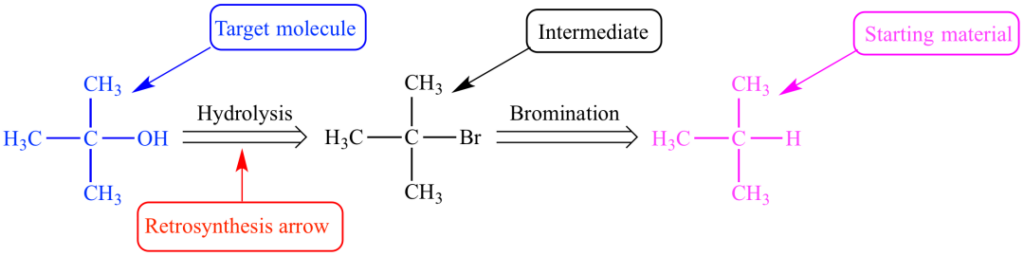
図 1: tert-ブタノールの逆合成経路
1960年代には、Corey らはプログラミングを通じて逆合成分析を実行しようとしました。、有機化学シミュレーション合成 (OCSS) ソフトウェアを開発しました。しかし、データ量が増えると、その作業はすぐにAIに取って代わられる。中でもディープラーニング(Deep Learning)モデルは大きな期待を集め、大きな成果を上げています。
初期の AI 逆合成研究では、研究者は反応テンプレートに基づいて生成物から反応物まで逆方向に作業すること、つまりテンプレートベースの逆合成を行うことがよくありました。。その中でも、多層パーセプトロンに基づく分子指紋は、製品のエンコードやテンプレートの選択によく使用されます。
続いて、研究者たちは、テンプレートフリーおよびセミテンプレート合成法の探索を開始しました。、主に次のものが含まれます。
1. シーケンスベースの逆合成。
2. チャートベースの逆合成。
2 つの主な違いは、分子の表現です。前者は SMILES 仕様などの線形化された文字列を使用して分子を表現しますが、後者は分子グラフ モデルを使用して分子を表現し、主に反応中心 (RC、Reaction Center) とシントンの完成 (Synthon) の予測を含みます。
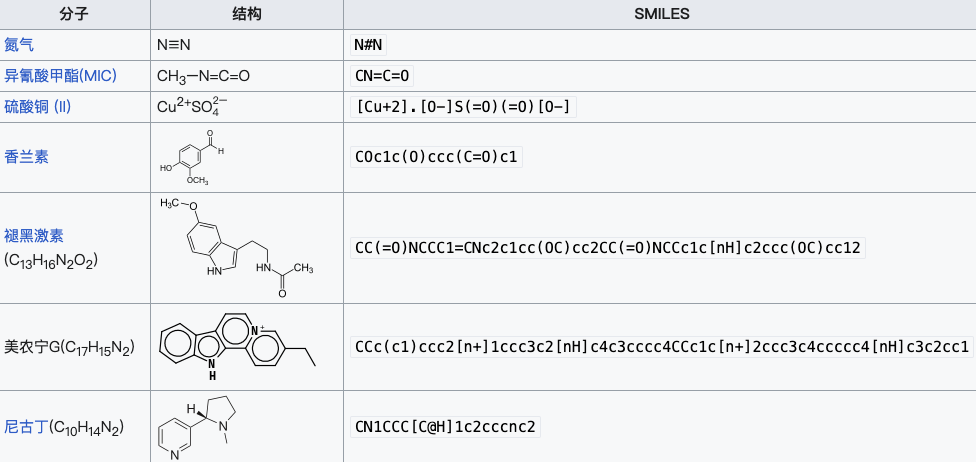
図 2: いくつかの物質の SMILES 表現
既存の逆合成法では大きな進歩が見られましたが、しかし、内因性の問題がまだ 3 つあります:
1.配列ベースの逆合成では分子情報が失われますが、グラフベースの逆合成では配列情報と分子の長距離特性が無視されます。。どちらの方法も特徴の学習には制限があり、パフォーマンスを向上させるのは困難です。
2.深層学習に基づく逆合成手法は解釈可能性が低い。テンプレートベースの逆合成はわかりやすい合成ルートを提供しますが、アルゴリズムの意思決定メカニズムはまだ曖昧であり、モデルの再現性と実現可能性を考慮する必要があります。
3.既存の手法は主にシングルステップ逆合成に焦点を当てています。この方法では合理的な反応物が得られるように見えますが、これらの反応物は購入が難しいか、複雑な後処理が必要になる場合があります。したがって、実際の化学合成では多段階逆合成の方が意味があると考えられます。
この目的を達成するために、山東大学のWei Leyiと中国電子科学技術大学のZou Quanの研究グループが共同でRetroExplainerを開発 。このアルゴリズムは、アルゴリズムの解釈可能性と実現可能性を考慮しながら、深層学習に基づく逆合成予測を実行できます。 RetroExplainer は、ほぼ 12 のベンチマーク データ セットで他のアルゴリズムを上回り、提案された合成ルートにおける 86.9% の反応は文献によって検証されました。この成果は「Nature Communications」誌に掲載されました。

この成果は「Nature Communications」に掲載されました
論文リンク:
https://www.nature.com/articles/s41467-023-41698-5
公式アカウントをフォローし、バックグラウンドで「レトロシンセシス」と返信すると、論文全文のPDFが入手できます
実験プロセス
アルゴリズム構築:モジュール + サブグリッド
逆合成分析プロセス全体には、分子のグラフィカルエンコード、マルチタスク学習、意思決定、およびマルチステップ合成ルート予測の 4 つのステップが含まれます。
RetroExplainer には主に、多感覚マルチスケール グラフ トランスフォーマー (MSMS-GT)、動的適応マルチタスク学習 (DAMT)、解釈可能な意思決定モジュール、ルート予測モジュールの 4 つのモジュールが含まれています。
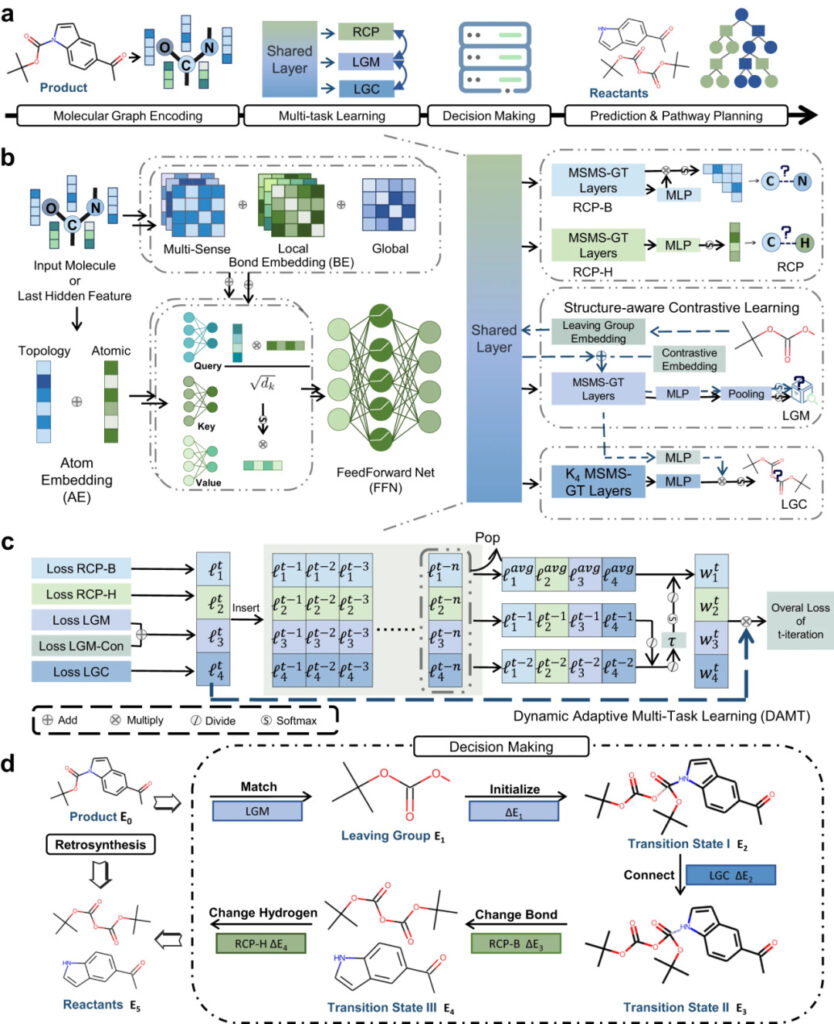
図 3: RetroExplainer とそのモジュールの概略図
a: RetroExplainer プロセス図。
b: MSMS-GT アーキテクチャ。
c: DAMT アルゴリズムの概略図。
d: 反応メカニズムと同様の意思決定プロセス。
MSMS-GT は、原子の化学結合埋め込みとトポロジカル埋め込みを通じて重要な化学情報を取得します。コード化された情報は、マルチヘッド アテンション メカニズムを通じて分子ベクトルに融合されます。
DAMT モジュールでは、分子情報が反応中心予測 (RCP)、離脱群一致 (LGM、離脱群一致)、および離脱群接続 (LGC、離脱群接続) サブグリッドに同時に入力されます。
RCP は化学結合と原子に隣接する水素原子の数の変化を特定し、LGM は生成物中の脱離基をデータベース内の脱離基と照合し、LGC は脱離基を生成物残基に関連付けます。
意思決定モジュールは、5 つの逆合成アクションと決定曲線のエネルギー スコア (E、エネルギー スコア) に基づいて生成物を反応物に変換し、分子集合プロセスを逆にシミュレートします。
最後に、ヒューリスティック ツリー検索アルゴリズムを使用して、反応物の可用性を確保しながら効率的な生成物合成ルートを見つけます。
性能比較:USPTO ベンチマーク データセット
RetroExplainer のパフォーマンスを検証するために、研究者らは米国特許商標庁 (USPTO) に含まれる化学反応に基づく他の 21 の逆合成アルゴリズムと比較しました。評価指標はトップ k の精度でした。
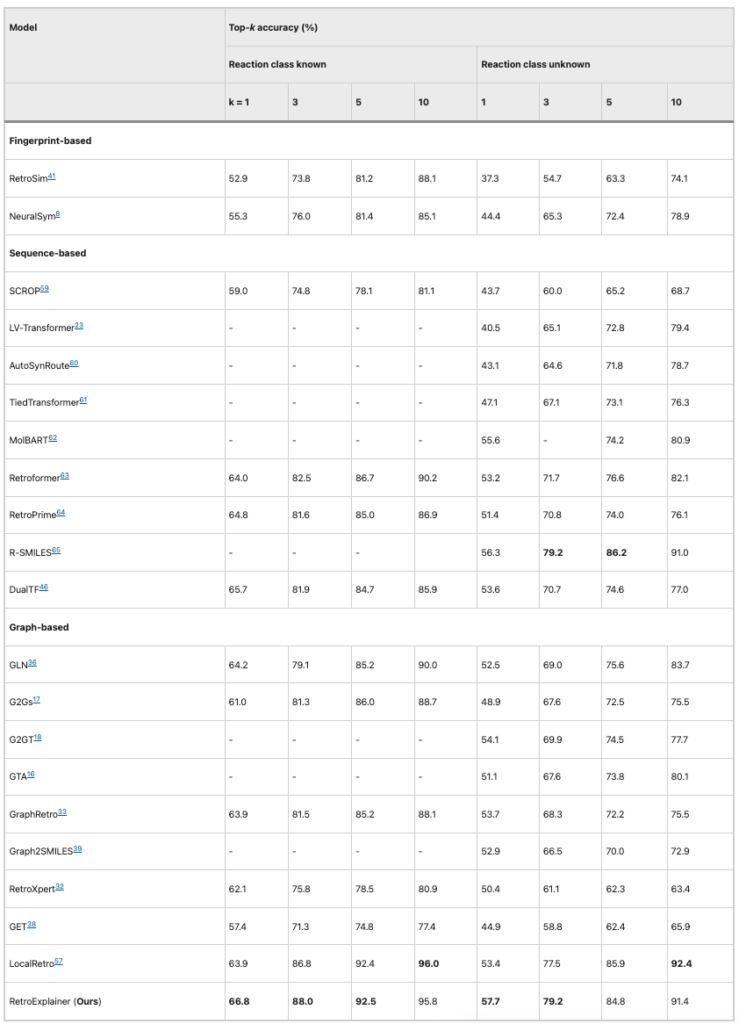
表 1: RetroExplainer と他のアルゴリズム (USPTO-50K) のパフォーマンス比較
USPTO-50K データセットに基づくと、8 つの評価指標のうち、RetroExplainer は 5 つの分野で他のアルゴリズムを上回り、平均精度で第 1 位にランクされています。。 RetroExplainer はトップ 10 の精度では LocalRetro ほど良くありませんが、両者の差はわずか 1% です。
類似分子の影響を排除するために、研究者らは谷本類似度を使用してデータを再分割し、最も精度の高い 2 つのアルゴリズムである R-SMILE と LocalRetro と比較しました。
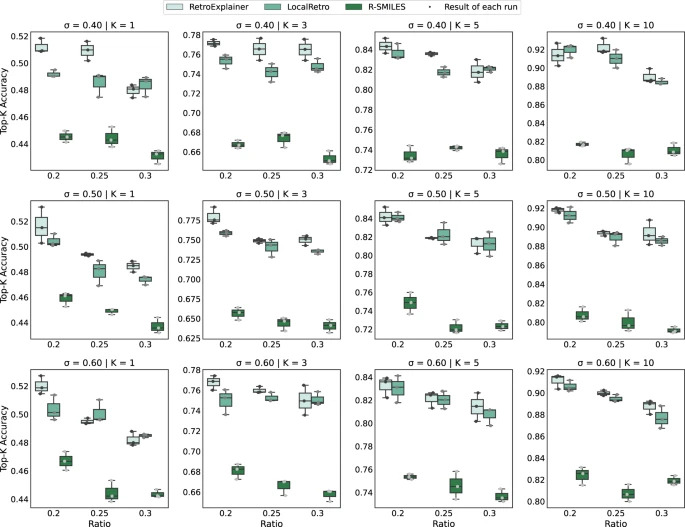
図 4: 異なるデータセットでの RetroExplainer、R-SMILES、および LocalRetro のパフォーマンスの比較
この結果から、RetroExplainer の安定性と適応性を反映して、ほとんどのデータ セットでパフォーマンスが向上していることがわかります。
その後、研究者らは、より大規模な USPTO-MIT および USPTO-FULL データセットでアルゴリズムのパフォーマンスを比較しました。 RetroExplainer のすべての指標は他のアルゴリズムよりも優れており、他のアルゴリズムとの差はさらに大きくなります。これは、RetroExplainer が大規模なデータ分析においてより大きな可能性を秘めていることを示しています。
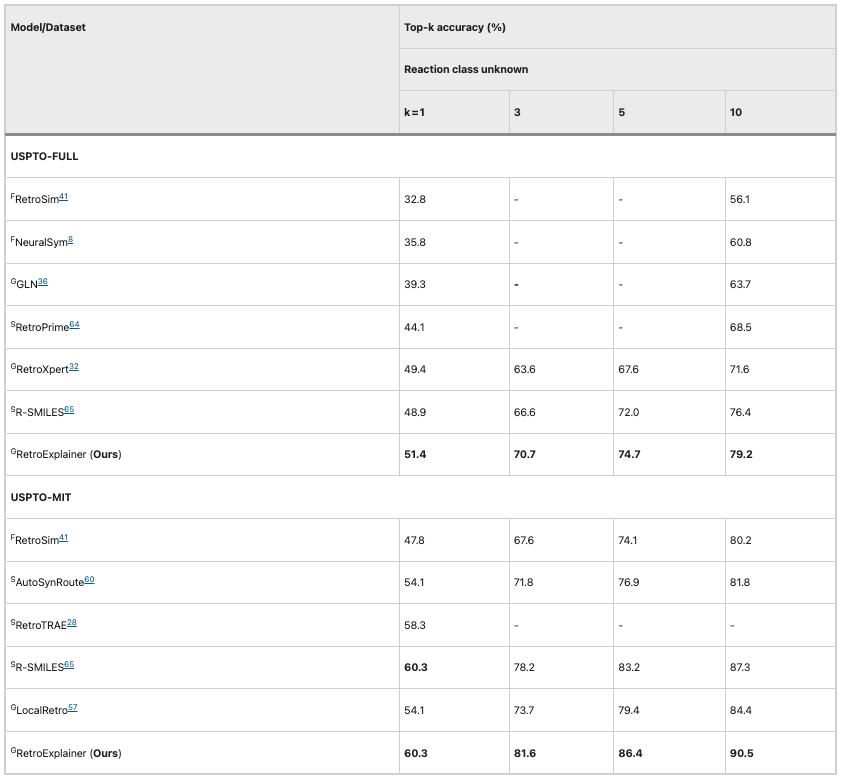
表 2: RetroExplainer と他のアルゴリズム (USPTO-MIT および USPTO-FULL) のパフォーマンスの比較
解釈可能性:意思決定の視覚化
研究者らは、二分子求核置換反応 (SN2) にヒントを得て、深層学習に基づく分子アセンブリに基づいた、解釈可能な逆合成予測プロセスを設計しました。意思決定プロセスには、元の生成物 (P)、脱離基マッチング (S-LGM)、初期化 (IT)、脱離基接続 (S-LGC)、反応中心の化学結合の変更 (S-RCP)、変更の 6 つの段階が含まれます。水素原子 (HC) の数。
DAMT のサブグリッドは、最終決定への寄与に基づいて各ステージのエネルギー スコア (E) を生成します。
具体的なプロセスは次のとおりです。
1. P ステージでは、各ステージの E を 0 に初期化します。
2. S-LGM 段階では、LGM モジュールの予測確率に基づいて脱離基が選択されます。
3. S-LGM 段階で選択された脱離基の E と、RCP および LGM モジュールによって予測された応答事象確率を加算して、IT 段階のエネルギーを取得します。
4. S-LGC および S-RCP ステージでは、動的計画アルゴリズムに基づいて、検索ツリー内のすべての可能なノードが展開されます。 Eを固定しながら、事前に設定したしきい値よりも確率が高いイベントを選択します。
5. 得られた分子図が原子価規則に適合するように水素原子の数と各原子の形式電荷を調整し、最終的な E を計算します。
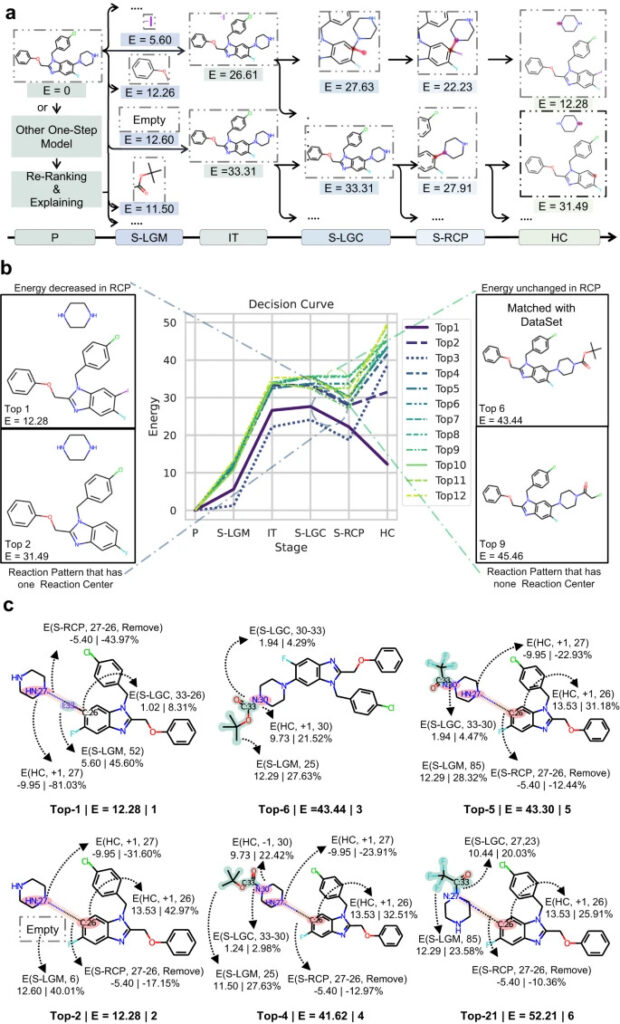
図 5: RetroExplainer の意思決定プロセス
a: RetroExplainer の 2 つの予測結果の検索ルート。
b: 上位 12 の予測ルートの決定曲線。
c: 合成経路を表す 6 つの構造変化プロセス。
E の変化に基づいて意思決定曲線を描くことで、RetroExplainer の意思決定プロセスを分析し、RetroExplainer の予測誤差を見つけることができます。
図に示すように、生成物の正しい合成ルートはアミンの脱保護反応であるはずですが、RetroExplainer では 6 位にランク付けされており、1 位は CN カップリング反応です。分析の結果、RetroExplainer は HC 段階でアミンの水素原子の数を増やす傾向があり、この違いが生じていることがわかりました。これは、RetroExplainer が HC 段階で同様の構造を持つ分子に対して同様の誤った判断をする可能性があることを示しています。
1位と2位のRetroExplainerの反応を比較すると、研究者らは、E が反応の難しさに関係している可能性があることを発見しました。。反応 1 における I:33 と C:26 の結合はエネルギーの削減にはつながりませんが、C:26 での水素原子の結合には前の反応の 13 倍のエネルギーが必要です。同時に、I:33 の導入により、CN カップリング反応が直面する選択性の問題が弱まります。
同時に、立体障害はRetroExplainerの予測結果にも影響を与える。 4位と21位の反応を比較すると、分子構造は同じですが、脱離基が対称なNに結合しているため、Eに差が生じています。
パスの計画:マルチステップ予測合成ルート
RetroExplainer の予測の実用性を向上させるために、研究者たちは RetroExplainer を Retro アルゴリズムと組み合わせ、後者の単一ステップ予測をマルチステップ予測に置き換えました。
気管支拡張薬プロトキロールを例として、RetroExplainer はこの製品の 4 段階の合成ルートを設計しました。その後、研究者らはこれらの 4 段階の反応に関する文献調査を実施し、その実現可能性を探りました。
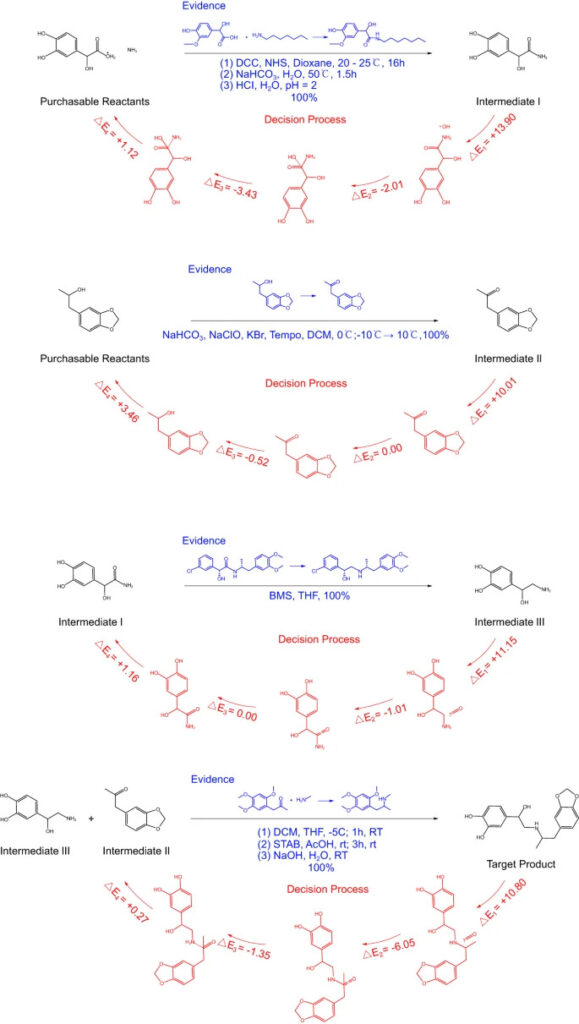
図6: RetroExplainerが提案したプロトトールの4段階合成ルート
図中の青い文字は参考文献に記録されている同様の反応、赤い部分はRetroExplainerの意思決定プロセスです。
多くの反応ではまったく同一の参照は見つかりませんでしたが、同様の高収率反応が見つかりました。また、RetroExplainer は 101 のケースに対して 176 の実験を設計し、そのうち 153 で SciFinder で同様の反応を見つけることができました。
上記の結果は、RetroExplainer の逆合成の予測が他の現在のアルゴリズムよりも優れていることを示しています。同時に、RetroExplainer の意思決定は透明性があり解釈可能であり、反応の複数段階の計画がより実現可能です。 RetroExplainer は、有機化学の逆合成研究に強力なツールを提供することが期待されています。
パフォーマンスと説明可能性、AI のパラドックス
説明可能性は AI をさまざまなシナリオに適用するための重要な要素です。自動運転、医療診断、金融保険などの業界における AI の継続的な開発に伴い、AI の意思決定プロセスはますます重要になり、ますます現実的、社会的、さらには法的な問題に直面しています。
同時に、説明可能性は、ユーザーが AI を理解、維持、使用し、AI アプリケーション分野で新しい概念を発見して理解するのに役立ちます。説明可能性は結果の実現可能性も反映し、この決定の利点が最大であることをユーザーに伝えます。
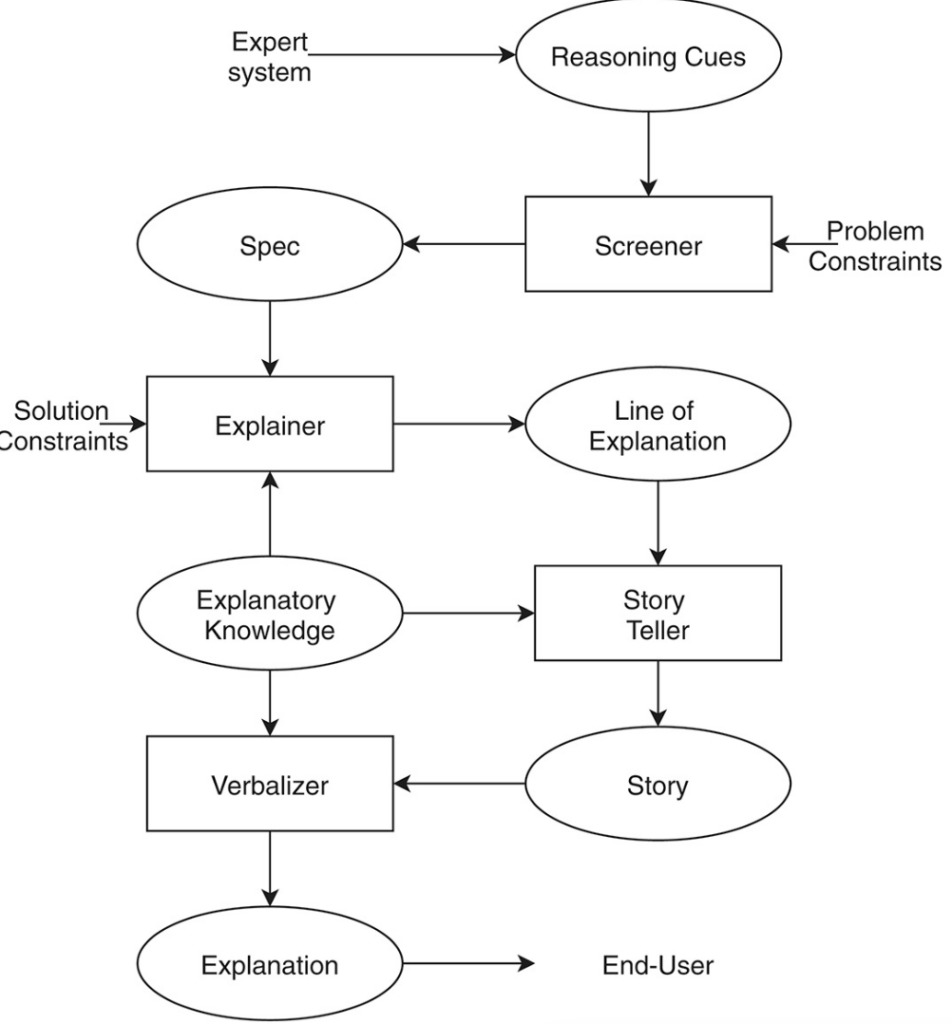
図 7: 問題解決プロセスの説明ステップ
しかし、モデルのパフォーマンスとモデルの解釈可能性は、ScienceAI を悩ませる大きな問題ですモデルのパフォーマンスが良好で、テスト セット全体で良好な堅牢性がある場合は、高次元の深度特徴を使用する方が良いかもしれませんが、物理的な意味はありません。これは、私たちがよく呼ぶものです。科学研究の解釈可能性はほとんどが貧弱です。”。
逆に、よく説明された特徴量を使用すると、物理的には非常に解釈しやすいものの、実際のモデルのパフォーマンスはデータに大きく依存し、別のデータセットを変更するとモデルのパフォーマンスが低下します。
両者の矛盾を統一する良い方法はまだ見つかっていないが、今回の研究では、研究者らはAIの意思決定プロセスを段階的に視覚化した。これにより、ユーザーは各段階でのさまざまな予測結果のスコア変化を明確に理解し、AI の意思決定プロセスを理解し、開発者がモデルを最適化することが容易になります。
説明可能な AI が継続的に開発されることで、人々の AI への理解が深まり、AI の意思決定プロセスが理解しやすくなります。将来的には、人間と機械の間のインタラクションは増加し続け、インタラクションの敷居はさらに低くなり、AIはより多くのシナリオで使用され、生活がより便利でインテリジェントになるでしょう。
参考リンク:
[1]http://www.chem.ucla.edu/~harding/IGOC/R/retroSynthetic.html
[2]https://zh.wikipedia.org/zh-cn/簡易分子線形入力仕様
[3]https://wires.onlinelibrary.wiley.com/doi/10.1002/widm.1391








