Command Palette
Search for a command to run...
天文学: CNN とアクティブ ラーニングを使用して 400 万の銀河画像の異常を特定する

銀河の異常は宇宙を理解する鍵を握っています。しかし、天体観測技術の発展に伴い、天文データは天文学者の解析能力を超えて指数関数的に増加しています。
ボランティアはオンラインで天文データの処理に参加できますが、いくつかの簡単な分類しか実行できず、重要なデータの一部を見逃す可能性があります。
この目的を達成するために、研究者らは畳み込みニューラル ネットワークと教師なし学習に基づいた Astronomaly アルゴリズムを開発しました。最近、西ケープ大学の研究者らは、大規模なデータ分析で初めて Astronomaly を使用し、400 万枚の銀河の写真から宇宙の異常を探ろうとしました。
著者 | 雪才
編集者 | 三陽市 鉄塔
この記事は、HyperAI Super Neural WeChat パブリック プラットフォームで初めて公開されました~
銀河の異常は宇宙を理解する鍵となります。サーベイ望遠鏡で記録された画像を分析することで、研究者は銀河の異常を特定し、宇宙の起源と進化について推論することができます。
しかし、このプロセスは深刻な課題に直面しており、なぜなら、天体観測データの量は指数関数的に増加しているからです。間もなく開設されるベラ ルービン天文台を例に挙げると、この天文台には世界最大のデジタル カメラが設置されており、毎晩 20 TB、10 年間で 60 PB のデータを記録し、約 200 億個の銀河を測定すると予想されています。 32兆回の観測、研究者が手動で分析できる限界をはるかに超えています。

図 1: 建設中のベラ・ルービン天文台
2007 年 7 月、一部の研究者が Galaxy Zoo プロジェクトを立ち上げました。Webボランティア募集による天体観測画像分類の推進。このプロジェクトには約 15 万人のボランティアが参加し、スローン デジタル スカイ サーベイ (SDSS) によって記録された 100 万個の銀河の 4,000 万枚以上の画像を分類しました。
図 2: Galaxy Zoo プロジェクトのホームページ
しかし、ボランティアはいくつかの基本的な作業しか行うことができず、画像の詳細は見落とされがちです。機械学習は画像解析やデータ分類が得意で、天文解析でも大きな可能性を秘めています。教師あり学習は天文データ分析で広く使用されていますしかし、これらのアルゴリズムは大量のトレーニング データと事前定義を必要とし、異常を検出するパフォーマンスが低くなります。
この目的を達成するために、2021 年に研究者らは、畳み込みニューラル ネットワーク (CNN) に基づいた教師なし機械学習アルゴリズム Astromaly を開発しました。このアルゴリズムは、さまざまなタスクで優れたパフォーマンスを発揮します。最近、西ケープ大学の研究者らは Astronomaly を使用して約 400 万枚の銀河画像を分析しました。このアルゴリズムは初めて大規模なデータ分析に適用され、これまで見落とされていた異常を発見しました。この結果は、arXiv でプレプリントとして公開されています。
この結果はarXivで公開されています
論文リンク:
https://arxiv.org/abs/2309.08660
実験プロセス
データセット: ダークエネルギー調査カメラ
この研究のデータセットは、主に測量用ダークエネルギーカメラ (DECaLS) の公開データ (DR8) の第 8 バッチの g、r、z バンドで記録された画像です。
その後、データセット内の画像がフィルタリングされます。標準的な銀河モデルに適合しない画像を除外しながら、アーティファクトや星によって隠された画像を削除します。最終的に3,884,404枚の銀河画像が残されました。
特徴抽出:CNN+PCA
Astronomaly の計算効率を向上させるには、高次元の画像から特徴を抽出し、それらを低次元のベクトルに変換する必要があります。
この研究では、事前トレーニングされた CNN を使用して画像から特徴を抽出します。 CNN の各層は、入力画像に対してさまざまな変換を実行して、画像の特徴を表すベクトルを生成します。
CNN は最終的に、1,280 個の画像特徴を含むベクトルを出力します。次に、研究者らは主成分分析 (PCA) を使用して、データの次元をさらに削減しました。 PCA は、データの分散に基づいて相関変数のセットを相関のない主成分に変換する、一般的に使用される統計手法です。PCA により、画像の次元はさらに 26 に縮小され、Astronomaly の処理効率が向上します。
異常監視:iForest + アクティブ ラーニング
天文学的には、異常監視のために Isolation Forest (iForest) アルゴリズムと Local Outlier Factor (LOF) アルゴリズムを組み合わせています。データ テストでは、LOF アルゴリズムを大規模データに適用するのは困難ですが、iForest アルゴリズムはデシジョン ツリーを通じて画像内の異常を迅速に発見できます。したがって、その後の分析では iForest アルゴリズムが使用されました。
その後、Astronomaly は K 最近傍アルゴリズム (NS) と直接回帰アルゴリズム (DR) を通じて能動学習を実行し、データセット内の画像の異常スコアを継続的に更新します。
NS アルゴリズムは、手動で注釈が付けられた少数の評価に基づくランダム フォレスト回帰アルゴリズムを通じて、すべての画像に対するユーザーの評価を予測できます。 DR アルゴリズムは、画像に対するユーザーの評価を直接「シミュレート」しようとします。
最後に、2 つのアルゴリズムのスコアリング結果が、評価のために手動でラベル付けされたデータと比較されます。

図 3: 注釈付き画像の一部
ラベル 0 の結果は、左から右にアーティファクト、マスク、および低い S/N 比を示します。ラベル 5 の結果は左から右に、銀河融合、重力レンズに対応し、まだ分類されていません。
重力レンズは、レンズによる光の屈折と同様に、近くの光が直線で進まなくなる、強い重力物体の影響です。
比較検証:リコールカーブ + UMAP
研究者らは、iForest、NS、DR アルゴリズムを使用して検証セット内のデータを予測しました。評価セットには 184 個の異常が含まれています。 iForest アルゴリズムでは、異常スコアが最も高い 500 枚の画像の中で 15 個の異常のみが検出されましたが、DR アルゴリズムと NS アルゴリズムでは両方とも 84 個の異常が検出されました。
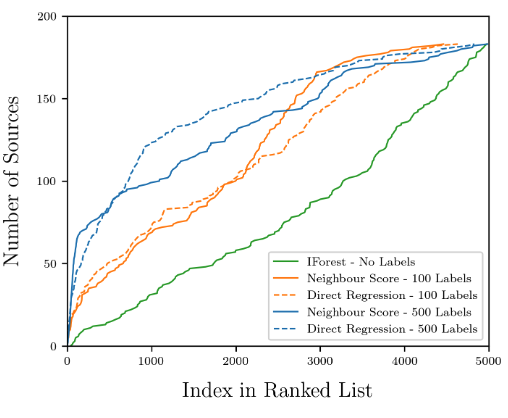
図 4: さまざまなアルゴリズムの予測結果
さらに研究者らは、iForest アルゴリズムと NS アルゴリズムの予測結果をアーティファクト、重力レンズ、銀河融合に基づいて分類し、iForest アルゴリズムのパフォーマンスが低い理由を発見しました。
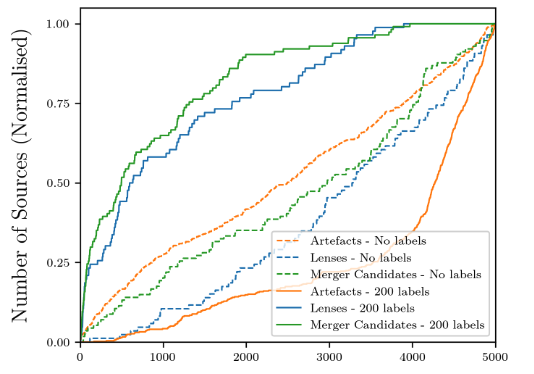
図 5: iForest (破線) アルゴリズムと NS (実線) アルゴリズムの結果の分類
図に示すように、iForest アルゴリズムによって検出された異常のほとんどはアーティファクトです。これらの技術的異常も異常ではありますが、科学的価値はありません。上記の結果は次のことを示しています。NS および DR アルゴリズムは、Astronomaly が人工物からの干渉を迅速に排除し、宇宙の異常を発見するのに役立ちます。
同時に、研究者らは均一多様体近似投影 (UMAP) を使用して検証セット内の画像を分類しました。
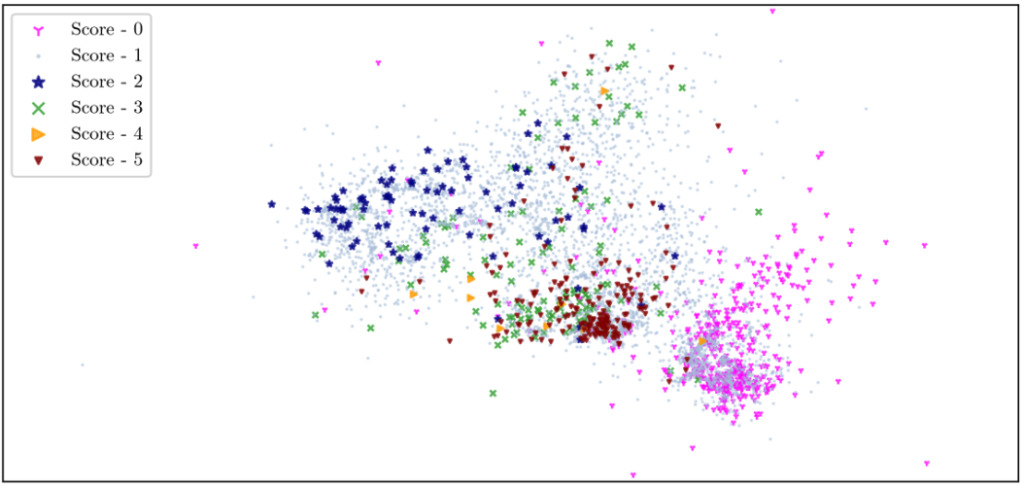
図 6: 評価セットの UMAP の結果
UMAP は、異常スコアに基づいて画像を分類します。スコアが 1 の画像は、通常の銀河、つまり特別な条件のない銀河の画像です。さまざまな画像の周囲には多数の 1 点の通常の画像が存在し、iForest アルゴリズムの予測の障害となります。
図では、スコア 0 のアーティファクトとスコア 5 の異常が密なクラスターに分割されていることがわかり、両方のタイプの画像に明らかな特徴があることがわかります。しかし同時に、2 種類の画像の分布が非常に近いため、iForest アルゴリズムによる誤判定が発生しやすくなります。
大規模なアプリケーション:注釈を付けて探索する
さまざまなアルゴリズムのパフォーマンスを評価した後、研究者らはデータセット全体に対して NS アルゴリズムを使用しました。
図からわかるように、データに注釈が付けられていない場合、つまりアクティブ ラーニングなしの iForest アルゴリズムでは、結果に曲線はほとんど表示されません。これは、iForest アルゴリズムでは、最も高い 2,000 データの中で異常が 1 つしか検出されなかったためです。異常スコア。
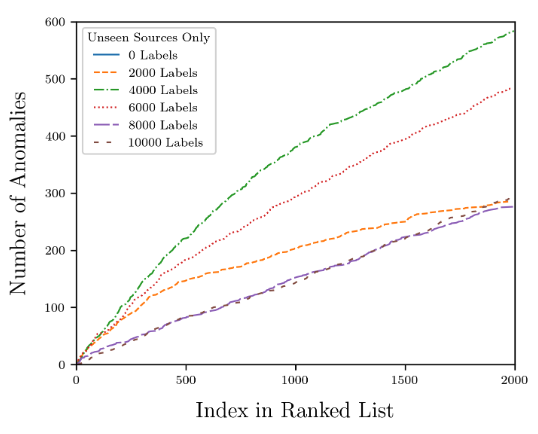
図 7: 異なるアノテーション数での NS アルゴリズムの予測結果
しかし、データセット内の 2,000 のデータ ポイントに注釈を付けた後、Astronomaly はアクティブ ラーニングを通じて画像内の異常を迅速に見つけることができました。注釈の数が 4,000 になると、Astronomaly は最も多くの新しい異常を発見します。、その後減少し始めます。これは、現時点では追加の注釈は必要なく、データ セットを増やすことができることを示しています。
追跡調査:1635/2000
データセット内のすべての画像を分析した後、 Astronomaly は、異常スコアが最も高かった 2,000 枚の画像から、8 つの重力レンズ、18 の未分類現象、1,609 の銀河融合を含む 1,635 の異常を発見しました。

図8: Astronomalyによって発見された重力レンズ

図 9: Astromaly によって発見された未分類の異常

図 10: Astronomaly によって発見された銀河融合
宇宙へ向かうAI
天体観測データは増加の一途をたどっており、天文学においてもデータ解析を得意とするAIの地位が徐々に高まってきています。2020年にはすでに英国ウォリック大学の研究者らがAIを活用し、NASAの古いデータから50個の新しい惑星を発見した。
同時に、「チャイナ・スカイ・アイ」として知られる口径500メートルの球面電波望遠鏡(FAST)も、過剰なデータ量の問題に直面している。そして AI が解決策を提供します。 2021年、FASTはTencent Youtu Laboratoryと協力してFASTデータを分析し、すぐに5つのパルサーを発見しました。
AI は他の面でも真価を発揮します。 2019年、イベント・ホライゾン・テレスコープ(ETH)チームは世界初のブラックホールの写真を公開した。 4年後、アメリカの研究者らはAIを使って写真を処理し、ブラックホールを「美化」するためのより高精細なブラックホールの写真を入手した。

図 11:元のブラック ホールの写真 (左) と処理されたブラック ホールの写真 (右)
おそらく人間と同じように、AI も星や海に到達するという野望を持っています。今、それは宇宙への一歩を踏み出し、広大なデータの海の中で宇宙の進化に関する手がかりを探しています。新しい惑星、新しいパルサー、新しい宇宙異常に至るまで、AI は天文学の新しい未来を切り開きます。
参考リンク:
[1]https://zoo4.galaxyzoo.org/?lang=zh_cn#/classify
[2]https://www.cas.cn/kj/202009/t20200901_4757754.shtml
[3]https://www.thepaper.cn/newsDetail_forward_22699012
この記事は、HyperAI Super Neural WeChat パブリック プラットフォームで初めて公開されました~








