Command Palette
Search for a command to run...
UIUC Li Bo 氏への独占インタビュー | 使えるものから信頼できるものへ、AI に関する学術コミュニティの究極の考え方

この記事は、HyperAI Super Neural WeChat パブリック プラットフォームで初めて公開されました~
ChatGPT の出現により、AI はテクノロジー界に再び衝撃を与え、その衝撃は広範囲に影響を及ぼし、テクノロジー界を 2 つの派閥に分けました。 1 つのグループは、AI の急速な発展が近い将来に人間に取って代わる可能性があると信じていますが、この「脅威理論」は不合理ではありませんが、もう 1 つのグループも異なる見解を提唱しています。AIの知能レベルは未だに人間に追いついていないか、「犬以下」であり、人類の未来を脅かすには程遠い。
確かに、この論争は早期に警告する価値があるが、2023年のWAICサミットフォーラムで張成啓教授をはじめとする多くの専門家や学者の見解として、AI に対する人間の期待は常に有益なツールです。つまり、「脅威理論」に比べれば、それは単なるツールにすぎません。さらに注意が必要なのは、それが信頼できるかどうか、そしてその信頼性を高めるにはどうすればよいかということです。結局のところ、AI が信頼できなくなったら、その将来の発展はどうなるでしょうか?
では、信頼性の基準は何でしょうか?そして、今日の分野はどこにあるのでしょうか?HyperAI は幸運にも、この分野で最先端の学者であるイリノイ大学の准教授と協力することができました。彼は IJCAI-2022 コンピューターと思想賞、スローン研究賞、国立科学財団キャリア賞、AI の注目すべき 10 を受賞しています。 、TR-35 Award、Intel Rising Star などの賞についてコメントした MIT Technology Li Bo 氏が、彼女の調査と紹介に続いて詳細な議論を行い、AI セキュリティ分野の開発動向を整理しました。

2023年の李波 IJCAI YES
機械学習は諸刃の剣です
タイムラインを延長すると、その過程における李波の研究プロセスは、信頼できる AI の開発の縮図でもあります。
2007 年、Li Bo は情報セキュリティを専攻する学部プログラムに入学しました。この間、国内市場ではネットワークセキュリティへの注目が高まり、ファイアウォールや侵入検知、セキュリティ評価などさまざまな製品やサービスが開発され始めていましたが、全体としてはまだ発展途上にありました。今考えると、この選択はリスクはあるものの、正しいスタートでした。李波は、このような「新しい」分野で自らの安全保障研究を開始すると同時に、その後の研究の基礎も築いた。

Li Bo は学部時代に同済大学で情報セキュリティを学びました。
博士レベルでは、李波氏はさらに、AIセキュリティの方向性に注目した。私がまだあまり主流ではないこの分野を選んだのは、興味だけではなく、恩師の励ましと指導によるところが大きいです。この専攻は当時特に主流ではなかったので、李波さんの選択は非常に危険でしたが、それでも彼女は学部時代に情報セキュリティの蓄積を頼りに、AIとセキュリティの組み合わせが非常に重要であることを痛感しました。明るい。
当時、李波とその家庭教師は主にゲーム理論の観点から研究を行っていました。分析に Stackelberg ゲームを使用するなど、AI の攻撃と防御をゲームにモデル化します。
Stackelberg ゲームは、通常、戦略的リーダーと追随者の間の相互作用を記述するために使用され、AI セキュリティの分野では、攻撃者と防御者の関係をモデル化するために使用されます。たとえば、敵対的な機械学習では、攻撃者は機械学習モデルをだまして偽の出力を生成させようとしますが、防御者はそのような攻撃を検出してブロックします。シュタッケルベルクのゲームを分析、研究することで、Li Bo のような研究者は、効果的な防御メカニズムと戦略を設計して、機械学習モデルのセキュリティと堅牢性を強化できます。
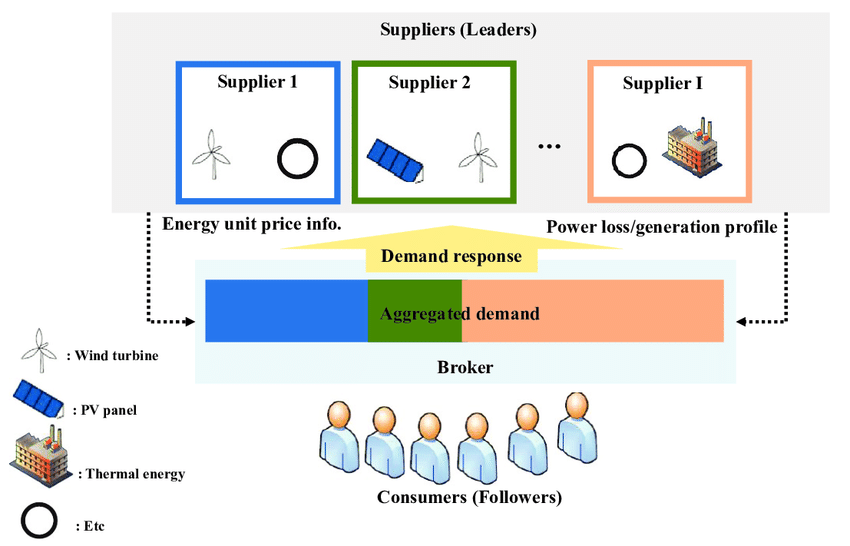
シュタッケルベルクのゲームモデル
2012 年から 2013 年にかけて、ディープラーニングの人気により、あらゆる分野への機械学習の浸透が加速しました。しかし、機械学習は AI テクノロジーの開発と変革を促進する重要な力ではありますが、両刃の剣であるという事実を隠すことはできません。
一方で、機械学習は大量のデータからパターンを学習して抽出することができ、複数の分野で優れたパフォーマンスと効果を実現します。たとえば、医療分野では、病気の診断と予測を支援し、より正確な結果と個別の医療アドバイスを提供します。一方で、機械学習にはいくつかのリスクもあります。まず、機械学習のパフォーマンスはトレーニング データの品質と代表性に大きく依存します。データにバイアスやノイズなどの問題が発生すると、モデルに誤った結果や差別的な結果が容易に生じる可能性があります。
さらに、このモデルは個人情報に依存する可能性もあり、プライバシー漏洩のリスクを引き起こします。さらに、悪意のあるユーザーが入力データを変更することでモデルを意図的に欺き、その結果、誤った出力が生じる可能性もあります。
このような背景から、Trustworthy AI が登場し、その後数年で世界的なコンセンサスへと発展しました。 2016年、欧州議会法務委員会(JURI)は「ロボットに関する民事法規則に関する欧州委員会への立法勧告に関する報告書草案」を発表し、欧州委員会は人工知能技術のリスクをできるだけ早く評価すべきだと主張した。 2017年、欧州経済社会委員会はAIに関する意見を発表し、AIの倫理と監視と認証のための標準システムを開発する必要があると主張した。 2019年、欧州連合は「信頼できるAIの倫理ガイドライン」と「アルゴリズムの責任と透明性のあるガバナンスの枠組み」を発表した。
国内では、学者の何継峰氏が 2017 年に初めて信頼できる AI の概念を提案しました。 2017年12月、工業情報化部は「新世代人工知能産業の発展を促進するための3か年行動計画」を発表した。 2021年、中国情報通信技術院と京東総合研究所は共同で国内初の「信頼できる人工知能白書」を発表した。

「信頼できる人工知能白書」記者会見サイト
信頼できる AI 分野の台頭により、AI はより信頼性の高い方向に進み、李波氏の個人的な判断も裏付けられました。科学研究と機械学習の対立に専念し、彼女は自らの判断に従って UIUC の助教授に就任し、自動運転分野における「ディープラーニング視覚分類に対する堅牢な物理世界攻撃」の研究成果は、米国でも認められました。英国ロンドンの科学博物館で永遠に集めましょう。
AI の発展に伴い、信頼できる AI の分野は間違いなく、より多くの機会と課題に直面するでしょう。 「私個人としては、セキュリティは永遠のテーマだと考えています。アプリケーションやアルゴリズムの発展に伴い、新たなセキュリティリスクや解決策も出現します。これがセキュリティの最も興味深い点です。AIのセキュリティは、AIや社会の発展と同じ頻度で起こるでしょう」 。」 李波氏は語った。
大型模型の信頼性から垣間見える現場の現状
GPT-4 の出現はあらゆる人の注目を集めています。これが第 4 次産業革命の始まりだと信じている人もいれば、AGI の転換点だと信じている人もいます。チューリング賞受賞者のヤン ル クン氏はかつて、「ChatGPT は AGI を理解していません」と公に述べました。現実世界では5年以内に廃止されるだろう。「もう誰も使っていない。」
この点に関して、李波氏は、この大型モデルの流行の波に非常に興奮していると述べた。なぜなら、この流行の波は間違いなくAIの開発を真に促進しており、この傾向は信頼できるAIの分野に対するより高い要求も提起するからである。特に、自動運転、スマート医療、バイオ医薬品など、高い安全性要件と高度な複雑性を伴う一部の分野ではそうです。
同時に、信頼できる AI の新しい応用シナリオや新しいアルゴリズムもさらに登場するでしょう。しかし、李波も後者の見解に完全に同意し、現在のモデルはまだ現実世界を真に理解していません。彼女と彼女のチームの最新の研究結果は、大規模なモデルには依然として多くの信頼できるセキュリティ上の脆弱性があることを示しています。
Li Bo 氏と彼のチームによるこの研究は、主に GPT-4 と GPT-3.5 に焦点を当て、有害なコンテンツ (毒性)、ステレオタイプ バイアス (ステレオタイプ バイアス)、敵対的堅牢性 (敵対的堅牢性)、および配布外の堅牢性 (out-of-of) を研究しました。 -配布堅牢性)、コンテキスト学習(インコンテキスト学習)における生成されたサンプルサンプル(デモンストレーション)の堅牢性、プライバシー(プライバシー)、異なる環境における機械倫理(機械倫理)、公平性(公平性)など 8 新たな脅威の脆弱性さまざまな角度から発見されます。
用紙のアドレス:
https://decodingtrust.github.io/
具体的には、Li Bo氏と彼のチームは、GPTモデルが誤解を招きやすく、暴言や偏った反応を生み出し、トレーニングデータや会話履歴の個人情報が漏洩する可能性があることを初めて発見した。同時に、標準ベンチマーク テストでは GPT-4 の方が GPT-3.5 よりも信頼できるパフォーマンスを示しましたが、敵対的なジェイルブレイク システムとユーザー プロンプトを組み合わせると、GPT-4 は攻撃に対してより脆弱であることもわかりました。 4 誤解を招く指示も含め、指示に従ってください。
したがって、推論能力の観点から見ると、AGI の到来にはまだ長い道のりがあり、AGI が直面する主な問題はモデルの信頼性を解決することである、と Li Bo 氏は考えています。過去には、李波氏の研究チームは、データ駆動型学習と知識強化に基づく論理推論フレームワークの開発にも注力しており、知識ベースと推論モデルを使用して大規模なデータ駆動型モデルの信頼性の欠点を補うことを望んでいた。 。彼女は、将来に目を向けると、機械学習の推論能力をさらに刺激し、モデルの脅威の抜け穴を補うことができる、新しくて優れたフレームワークがさらに登場すると信じています。
それでは、大規模モデルの信頼性の現状から、信頼される AI 分野の一般的な方向性を垣間見ることができるでしょうか?誰もが知っているように、安定性、汎化能力(解釈可能性)、公平性、プライバシー保護は信頼できる AI の基盤であり、4 つの重要なサブ方向でもあります。Li Bo 氏は、大規模なモデルの出現に伴い、新しい機能により、コンテキスト学習における分散外の例の敵対性や堅牢性など、新たな信頼性の制約が必然的に生じると考えています。この文脈では、いくつかのサブディレクションが相互に促進し、それによってそれらの間の本質的な関係に新しい情報や解決策が提供されます。 「たとえば、私たちの以前の研究では、機械学習の一般化と堅牢性がフェデレーテッド ラーニングにおける双方向の指標となり得ること、またモデルの堅牢性がプライバシーなどの関数とみなせることが証明されました。」
信頼されるAIの未来に期待
信頼できる AI 分野の過去と現在を振り返ると、李波氏に代表される学術コミュニティ、大手テクノロジー企業に代表される産業界、政府がそれぞれ異なる方向で模索し、一連の成果を上げていることがわかります。 。将来に目を向けると、李波氏は「AIの発展は止められない。AIの安全性と信頼性を確保することによってのみ、AIをさまざまな分野に安全に適用できる」と述べた。
信頼できるAIを具体的に構築するにはどうすればよいでしょうか?この質問に答えるには、まず「信頼できる」とは一体何なのかを考える必要があります。 「統一された信頼できる AI 評価基準を確立することが、現時点で最も重要な課題の 1 つであると思います。」最近の知源会議と世界人工知能会議では、信頼できる AI についての議論が前例のないほど高まっていることがわかりますが、議論のほとんどは依然として議論レベルにとどまっており、体系的な手法の指針が欠けています。業界でも同様のことが当てはまり、一部の企業は関連するツール キットやアーキテクチャ システムを立ち上げていますが、パッチベースのソリューションでは 1 つの問題しか解決できません。したがって、多くの専門家が同じ点を繰り返し言及しており、この分野では信頼できる AI 評価基準がまだ不足しています。
李波はそれを深く感じ、「保証された信頼できる AI システムの前提条件は、信頼できる AI 評価基準を持つことです。」さらに、彼女の最近の研究「DecodingTrust」は、さまざまな観点から包括的なモデルの信頼性評価を提供することを目的としていると述べた。産業界にまで拡大すると、アプリケーション シナリオはますます複雑になり、信頼できる AI 評価にさらなる課題と機会がもたらされます。さまざまなシナリオではより信頼できる脆弱性が現れる可能性があるため、これにより信頼できる AI の評価基準がさらに向上する可能性があります。
総括する、Li Bo 氏は、信頼できる AI 分野の将来は、包括的でリアルタイムに更新される信頼できる AI 評価システムの形成と、これに基づいてモデルの信頼性の向上に焦点を当てる必要があると考えています。「この目標を達成するには、学界と産業界が緊密に協力して、一緒に達成するためのより大きなコミュニティを形成することが必要です。」
UIUC Secure Learning Lab GitHub ホームページ
GitHub プロジェクトのアドレス:
同時に、李波氏が勤務する安全学習研究所もこの目標に向けて取り組んでいます。彼らの最新の研究成果は主に次の方向に配布されています。
1. データ駆動型学習に基づく検証可能で堅牢な知識強化型論理推論フレームワーク。データ駆動型モデルと知識強化型論理推論を組み合わせることで、データ駆動型モデルのスケーラビリティと一般化機能を最大限に活用し、ロジックを使用することを目的としています。推論により、モデルのエラー修正機能が向上します。
この方向で、Li Bo と彼のチームは学習推論フレームワークを提案し、その認証の堅牢性を証明しました。結果は、このフレームワークが、単一のニューラル ネットワーク モデルのみを使用し、十分な数の条件を分析するアプローチよりも大きな利点があることを証明できることを示しています。同時に、彼らは学習推論フレームワークをさまざまなタスク領域に拡張しました。
関連論文:
* https://arxiv.org/abs/2003.00120
* https://arxiv.org/abs/2106.06235
* https://arxiv.org/abs/2209.05055
2. DecodingTrust: 言語モデルの信頼性を評価するための最初の包括的なモデル信頼性評価フレームワーク。
関連論文:
* https://decodingtrust.github.io/
3. 自動運転分野では、セーフティクリティカルシーン生成・テストプラットフォーム「SafeBench」を提供。
プロジェクトアドレス:
* https://safebench.github.io/
その上、Li Bo氏は、チームが今後もスマートヘルスケア、金融、その他の分野に注力する計画であることを明らかにした。「信頼できる AI アルゴリズムとアプリケーションのブレークスルーは、これらの分野でより早期に現れるかもしれません。」
助教授から終身教授へ: 一生懸命働けばすべては自然に起こる
李波氏の紹介から、次のことを理解するのは難しくありません。信頼できる AI という新興分野には、早急に解決しなければならない問題がまだ多くあります。したがって、学術界であれ、李波氏のチームに代表される産業界であれ、現時点ではすべての関係者がまず、来るべき需要の急増に完全に対応することを模索している。信頼できる AI の分野が台頭する前に李波が冬眠して研究に集中していたように、興味があり楽観的である限り、成功するのは時間の問題です。
この姿勢は、UIUC で 4 年以上勤務してきた Li Bo 自身の教育の道にも反映されています。今年、彼は終身教授の称号を授与された。彼女は、専門職の称号を評価するための厳格なプロセスがあり、その評価には研究成果や他の上級学者の学術的評価などが含まれると紹介しました。課題はありますが、しかし、「一つのことに熱心に取り組んでいる限り、他のことはうまくいくでしょう。」同時に彼女は、米国の終身教授制度は教授にもっと自由を与え、よりリスクの高いプロジェクトを実行する機会を与えているとも述べた。そのため、李波のためにもチームと協力していくつかの新しいことに挑戦するつもりだ。 「理論と実践においてさらなるブレークスルーを達成したいと考えています。」

イリノイ大学准教授、IJCAI-2022 Computers and Ideas Award、Sloan Research Award、National Science Foundation CAREER Award、AI's 10 to Watch、MIT Technology Review TR-35 Award、Dean's Research Excellence Award、CW Gear Outstanding を受賞Beginning Teacher Award、Intel Rising Star Award、Symantec Research Laboratory Fellowship、Google、Intel、MSR、eBay、IBM、さらには複数のトップ機械学習およびセキュリティカンファレンスで最優秀論文賞を受賞。
研究の関心: 機械学習、セキュリティ、プライバシー、ゲーム理論が交わる、信頼できる機械学習の理論的および実践的側面。
参考リンク:
[1] https://www.sohu.com/a/514688789_114778
[2] http://www.caict.ac.cn/sytj/202209/P020220913583976570870.pdf
[3] https://www.huxiu.com/article/1898260.html
この記事は、HyperAI Super Neural WeChat パブリック プラットフォームで初めて公開されました~








