Command Palette
Search for a command to run...
「クジラの顔認識」が開始されました。ハワイ大学は 50,000 枚の画像を使用して認識モデルをトレーニングし、平均精度は 0.869 でした。

内容の概要:顔認識は人間の身元をロックすることができます。この技術はクジラ類にも拡張されており、「背びれ認識」があります。 「背びれ識別」は、画像認識技術を活用し、背びれから鯨類の種を識別する。従来の画像認識は畳み込みニューラル ネットワーク (CNN) モデルに依存していますが、これには大量のトレーニング画像が必要で、特定の単一種しか認識できません。最近、ハワイ大学の研究者らは、クジラ類のアプリケーションで良好に機能する複数種の画像認識モデルをトレーニングしました。
キーワード:画像認識 クジラ目 ArcFace
著者|ダザニー
編集者|三陽市玄軒
この記事は、HyperAI Super Neural WeChat パブリック プラットフォームで初めて公開されました。~
クジラ目は海洋生態系の代表的な動物および指標生物であり、海洋生態環境を保護する上で極めて高い研究価値を持っています。従来の動物の識別では、現場で動物の写真を撮り、個々の出現の時間と場所を記録する必要がありますが、これには多くの手順が含まれ、複雑なプロセスです。中でも、異なる画像から同じ人物を識別する画像マッチングには特に時間がかかります。
タインらによる 2014 年の研究では、マダライルカ (Stenellalongirostris) の 1 年間にわたるキャッチアンドリリース調査中に、画像のマッチングには 1,100 時間以上の手作業がかかり、プロジェクト総コストのほぼ 3 分の 1 を占めました。。
最近、ハワイ大学のフィリップ T. パットンなどの研究者は、50,000 枚を超える写真 (24 種のクジラ目と 39 のカテゴリを含む) を使用して、ArcFace 分類ヘッドの複数種画像認識モデルに基づく顔認識アルゴリズムをトレーニングしました。このモデルは、テスト セットで 0.869 の平均精度 (MAP) を達成しました。このうち 10 ディレクトリは MAP スコアが 0.95 を超えています。
この研究は、「写真識別への深層学習アプローチが 20 種類のクジラ類で高いパフォーマンスを実証」というタイトルで、Methods in Ecology and Evolution 誌に掲載されました。

研究成果は『Methods in Ecology and Evolution』に掲載されました。
用紙のアドレス:
https://besjournals.onlinelibrary.wiley.com/doi/full/10.1111/2041-210X.14167
データセット: 25 種、39 カタログ
データ紹介
Happywhale と Kaggle は、世界中の研究者と協力して、大規模な複数種の鯨類データセットを構築しました。このデータセットは、背びれ/横向きの画像から個々のクジラ目を識別するようチームに求められた Kaggle コンテスト用に収集されました。データ セットには 25 種の 41 のカタログが含まれており、各カタログには 1 つの種が含まれており、一部のカタログの種は繰り返し表示されます。
この研究では、2 つの競合ディレクトリを削除しました。1 つはトレーニングとテスト用の低品質の画像が 26 枚しかなく、もう 1 つのディレクトリにはテスト セットがなかったためです。最終的なデータセットには、50,796 個のトレーニング画像と 27,944 個のテスト画像が含まれており、そのうち 50,796 個のトレーニング画像には 15,546 個の ID が含まれています。これらのアイデンティティのうち、9,240 (59%) にはトレーニング イメージが 1 つだけあり、14,210 (91%) にはトレーニング イメージが 5 つ未満あります。
データセットとコードアドレス:
https://github.com/knshnb/kaggle-happywhale-1st-place
トレーニングデータ
複雑な画像の背景の問題を解決するために、一部の参加者は、画像内のクジラ類を自動的に検出し、その周囲に境界ボックスを描画できる画像トリミング モデルをトレーニングしました。下の図からわかるように、このパイプラインには、YOLOv5 や Detic などの異なるアルゴリズムを使用する 4 つのクジラ検出器が含まれています。検出器の多様性によりモデルの堅牢性が向上し、実験データのデータ拡張が可能になります。

図 1: 競争セット内の 9 つのディレクトリからの画像と 4 つの鯨類検出器によって生成された境界ボックス
各境界ボックスが生成するクロップの確率は、赤の場合は 0.60、オリーブ グリーンの場合は 0.15、オレンジの場合は 0.15、青の場合は 0.05 です。トリミング後、研究者らは、EfficientNet-B7 バックボーンと互換性があるように、各画像のサイズを 1024 x 1024 ピクセルに変更しました。
サイズ変更後、アフィン変換、サイズ変更とトリミング、グレースケール、ガウスぼかしなどのデータ拡張技術を適用します。モデルを避ける重度の過学習。
データ拡張とは、トレーニング プロセス中に元のデータを変換または拡張してトレーニング サンプルの多様性と量を増やし、それによってモデルの汎化能力と堅牢性を向上させることを指します。
モデルのトレーニング: 種と個体の認識に対する 2 つのアプローチ
以下の図は、図のオレンジ色の部分に示すように、モデルのトレーニング プロセスを示しています。研究者らは画像認識モデルを背骨、首、頭の 3 つの部分に分割しました。
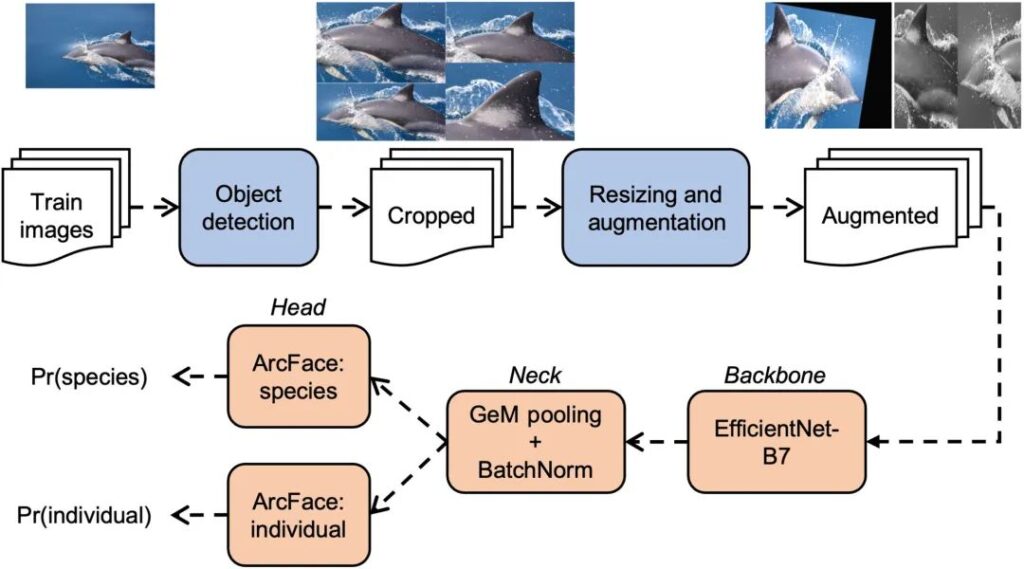
図 2: 複数種の画像認識モデルのトレーニング パイプライン
図の最初の行は前処理ステップです (例としてマイルカ Delphinus delphis の画像を使用します)。作物は 4 つのターゲット検出モデルから生成され、データ拡張ステップによって 2 つのサンプル画像が生成されます。
下の行は画像分類ネットワークのトレーニング ステップを示しています。背骨から首、頭まで。
イメージはまずネットワークを経由してバックボーンに送られます。過去 10 年間にわたる一連の研究により、ResNet、DenseNet、Xception、MobileNet など、数十の人気のあるバックボーンが生み出されてきました。検証され、EfficientNet-B7 はクジラ類のアプリケーションで最高のパフォーマンスを発揮します。
Backbone は画像を取得した後、一連の畳み込み層とプーリング層を介して画像を処理し、画像の簡略化された 3 次元表現を生成します。 Neck は、この出力を特徴ベクトルとも呼ばれる 1 次元ベクトルに変換します。
どちらの頭部モデルも、特徴ベクトルをクラス確率、つまり Pr(種) または Pr(個人) に変換します。それぞれ種の識別と個体の識別に使用されます。これらの分類ヘッドは、動的マージンを備えたサブセントリック ArcFace と呼ばれ、一般に複数種の画像認識シナリオに適用できます。
実験結果:平均精度 0.869
テスト セット (24 種の 39 カタログ) 内の 21,192 枚の画像に対して予測が行われ、平均精度 (MAP) 0.869 が得られました。以下の図に示すように、平均精度は種によって異なり、トレーニング画像やテスト画像の数には依存しません。
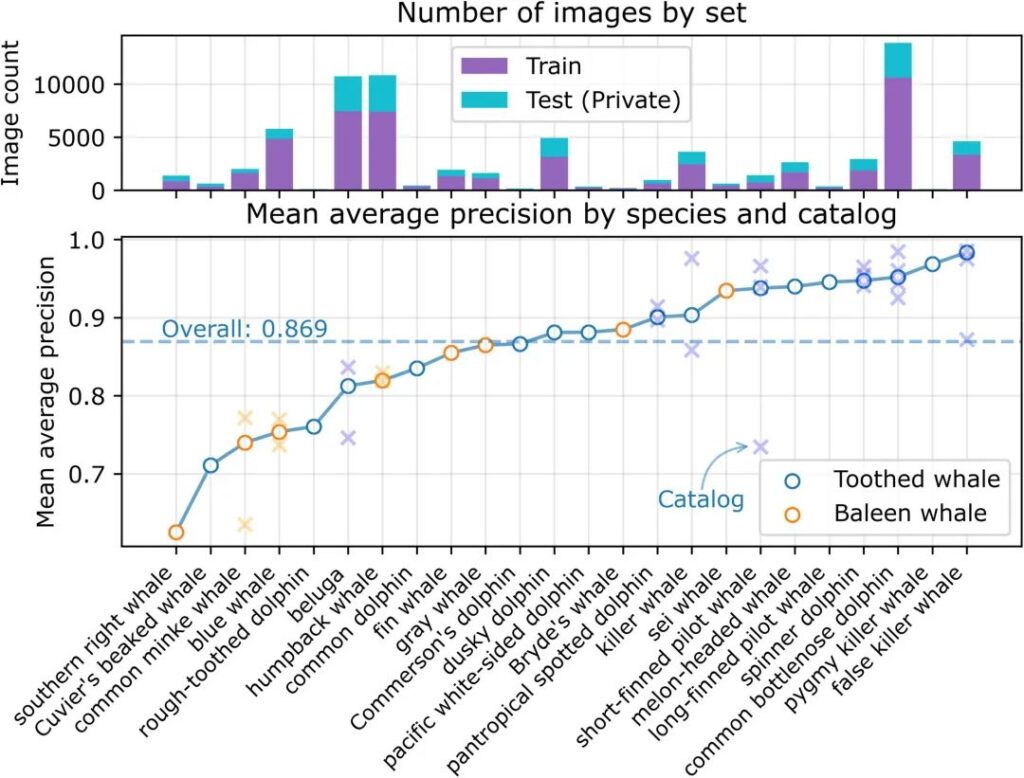
図 3: テスト セットの平均精度
上部のパネルには、目的別 (つまり、トレーニングまたはテスト)、種ごとの画像の数が表示されます。複数のカタログを持つ種は x で表されます。
この図は、ハクジラを識別する場合にはモデルのパフォーマンスが向上しますが、ヒゲクジラを識別する場合にはパフォーマンスが低下することを示しています。ヒゲクジラのうち、平均以上のスコアを記録したのは 2 種だけでした。
複数カタログ種のモデルのパフォーマンスにも違いがありました。たとえば、ミンククジラ (Balaenoptera acutorostrata) の異なるカタログ間の MAP スコアはそれぞれ 0.79 と 0.60 です。シロイルカ (Delphinapterus leucas) やシャチなどの他の種も、カタログ間でその性能が大きく異なります。
この点に関して、研究者らはこのディレクトリレベルのパフォーマンスの違いを説明する理由を見つけられませんでしたが、しかし、彼らは、ぼやけ、一意性、マークの混乱、距離、コントラスト、水しぶきなどの定性的な指標が画像の精度スコアに影響を与える可能性があることを発見しました。
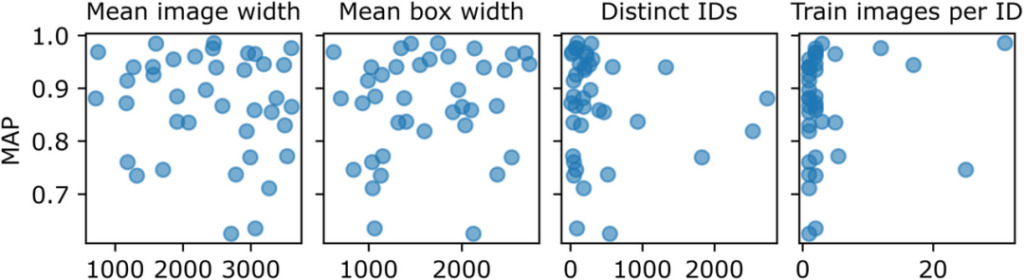
図 4: ディレクトリレベルのパフォーマンスの違いに影響を与える可能性のある変数
図の各点は競合データセット内のディレクトリを表し、ピクセルは画像と境界ボックスの幅を表します。個別の ID は、トレーニング セット内の個別の個人の数を表します。しかし、カタログレベルの MAP と、平均画像幅、平均境界ボックス幅、トレーニング画像の数、個別の個体の数、個体ごとのトレーニング画像の数の間に明確な相関関係はありません。
上記に基づいて、研究者らは、このモデルを予測に使用すると、7 種を表す 10 カタログの平均精度が 0.95 よりも高く、従来の予測モデルよりもパフォーマンスが優れていることを提案しました。これは、このモデルの使用がさらに優れていることを示しています。個人を正確に識別できます。さらに研究者らは、実験中に鯨類研究について注意すべき7つのポイントもまとめた。
- 背びれの認識が最も優れた結果を示しました。
- 個別の特徴が少ないカタログのパフォーマンスは低かった。
- 画質は重要です。
- 色で動物を識別するのは難しい場合があります。
- トレーニングセットと比較して特性の差が大きい種ほど、スコアが低くなります。
- 前処理は依然としてハードルです。
- 動物の模様の変更はモデルのパフォーマンスに影響を与える可能性があります。
Happywhale: 鯨類研究のための市民科学プラットフォーム
この記事のデータセットの紹介で言及されている Happywhale は、鯨類の画像を共有するための公共科学プラットフォームです。目標は、大規模なデータセットのロックを解除し、写真 ID の迅速な照合を容易にすることです。そして、一般向けの科学研究への関与を生み出します。
Happywhale公式サイトアドレス:
Happywhale は 2015 年 8 月に設立されました。共同創設者のテッド チーズマンはカリフォルニア州モントレー湾で育ち、子供の頃からホエールウォッチングが好きで、南極大陸とジョージア島に何度も旅行しました。アドベンチャー、南極探検と極地の観光管理に20年以上の経験があります。

テッド・チーズマン、Happywhale 共同創設者
2015年、テッドは21年間働いたチーズマンズ・エコロジー・サファリズ(自然主義者でもあったテッドの両親が1980年に設立したエコ旅行代理店)を辞め、ハッピーホエール・プロジェクトに参加した。 科学的研究データを収集して、クジラ類をさらに理解し、保護します。
わずか数年のうちに、Happywhale.com は鯨類研究への最大の貢献者の 1 つとなりました。膨大な数の鯨類識別画像に加えて、鯨類の移動パターンを理解するための多くの洞察も提供します。
参考リンク:
[1]https://baijiahao.baidu.com/s?id=1703893583395168492
[2]https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0086132
[3]https://phys.org/news/2023-07-individual-whale-dolphin-id-facial.html#google_vignette
[4]https://happywhale.com/about
この記事は、HyperAI Super Neural WeChat パブリック プラットフォームで初めて公開されました。~








