Command Palette
Search for a command to run...
極度の降水量を正確に予測するために、コロンビア大学がニューラル ネットワーク Org-NN のアップグレード バージョンを発表

内容の概要:近年、環境変化が激化し、世界各地で異常気象が頻発しており、降水量の正確な予測は人類にとっても自然環境にとっても非常に重要です。従来のモデルは、降水量の予測のばらつきが小さく、小雨に偏っており、極端な降水量を適切に予測できません。
キーワード: 異常気象のための暗黙的学習ニューラル ネットワーク
この記事は、HyperAI Super Neural WeChat パブリック プラットフォームで初めて公開されました~
台風「ドゥスリ」の影響で、北京では7月29日から数日連続で大雨が降り始め、一部の地域では非常に激しい雨が降った。非常に激しい雨が海河流域で流域全体に大規模な洪水を引き起こし、門頭溝市や涿州市などで大洪水が発生した。
7月31日のCCTVの報道によると、今回の大雨の間、北京市は1,000万立方メートル以上の水を放出し貯留したが、これは頤和園内の昆明湖約5つを排水するのに相当する。極端な降水量をタイムリーかつ正確かつ効果的に予測することで、気象災害による死傷者を最小限に抑え、損失を軽減できます。
従来の気候モデルのパラメータ化には、サブグリッドスケールの雲の構造と組織情報が欠如しており、粗い解像度での降水強度とランダム性に影響を及ぼし、極端な降水状況を正確に予測できなくなります。コロンビア大学の LEAP 研究室は、全球嵐解析シミュレーションと機械学習を使用して、情報欠落の問題を解決し、より正確な予測方法を提供する新しいアルゴリズムを作成しています。
現在、この研究は「PNAS」に掲載されており、論文タイトルは「対流組織の暗黙的学習が降水確率を説明する」となっています。

論文はPNASに掲載されました
論文アドレス: https://www.pnas.org/doi/10.1073/pnas.2216158120#abstract
準備: 10 日間の気象データ + 2 つのニューラル ネットワーク
データと処理
実験チームが使用したデータセットは次のとおりです。大気モデルシステム (SAM) DYAMOND (非静力学領域でモデル化された大気大循環のダイナミクス) 第二段階比較プロジェクトでシミュレーションされた大気循環ダイナミクスの一部。このプロジェクトでは、北半球の冬の 40 日間を比較およびシミュレーションしました。実験者は最初の 10 日間をモデルのスピンアップとして使用し、最後の 30 日間のトレーニング セットとしてランダムに 10 日間を選択しました。
研究者は適切なデータを選択し、そして、これらのデータを、GCM サイズのグリッドと同等または同等の粒度の粗いサブドメインに分割します。
次に、トレーニング、検証、およびテストのデータセットを提供するために、チームは 10 日間を 6 日間、2 日間、および 2 日間にそれぞれトレーニング、検証、テストに分割しました。また、降水の原因 (トリガー) ではなく降水の強度のみに焦点を当てるために、降水量がしきい値 (0.05 mm/h) を超えるサンプルのみが保持されます。 。最終的に、サンプルの総数は 108 になりました。
ニューラルネットワークアーキテクチャ
実験では、研究者らは 2 つのニューラル ネットワークを使用しました。従来モデルBaseline-NN(ベースラインニューラルネットワーク)と新たに提案されるOrg-NN 。
Baseline-NN は完全に接続されたフィードフォワード ネットワークであり、学習率は世代ごとに調整されます。従来のモデルとして、Baseline-NN は大規模な変数にアクセスして降水量を予測することしかできません。
Org-NN にはオートエンコーダが含まれており、そのエンコーダ部分には 3 つの 1 次元畳み込み層と 2 つの全結合層が含まれています。。エンコーダーの入力はサイズ 32 x 32 の高解像度 PW (降水量) 異常で、出力は組織変数、組織次元はネットワークのハイパーパラメーターであり、研究者はこれを 4 に設定しました。デコーダは組織変数を受け取り、元の高解像度フィールドを再構築します。これはエンコーダとはまったく逆の構造です。 Org-NN のニューラル ネットワーク部分は Baseline-NN と似ていますが、組織の潜在変数 (org) が入力として追加される点が異なります。 。
どちらも TensorFlow バージョン 2.9 を使用して実装され、ハイパーパラメータは Sherpa 最適化ライブラリを使用して調整されました。
実験結果
実験チームは 2 つのモデルを事前トレーニングしました。ニューラル ネットワークの予測パフォーマンスを評価するために、研究者らは、回帰モデルのパフォーマンスを定量化するために一般的に使用される指標である R2 を選択しました。。計算式は次のとおりです。
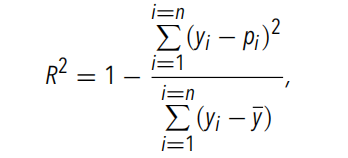
従来モデル Baseline-NN
実験チームは最初に Baseline-NN を使用しました。以下の図は、入力として粗粒度の PW、SST、qv2m、および T2m を使用した場合の降水量の予測可能性を示しています。。このうち、qv2m と T2m は境界層の状態に関する情報を Baseline-NN に提供するために使用されます。実験チームは粗粒化PWをグループに分け、各グループ内の粗粒化降水量の予測値と実際の値を平均しました。各グループに含まれる粗粒降水量の分散も計算されます。。
PW:可降水量、可降水量
SST:海面水温、海面水温
qv2m:地表付近2mの比湿度、地表付近の比湿度
T2m:地表付近2mの空気湿度、地表温度
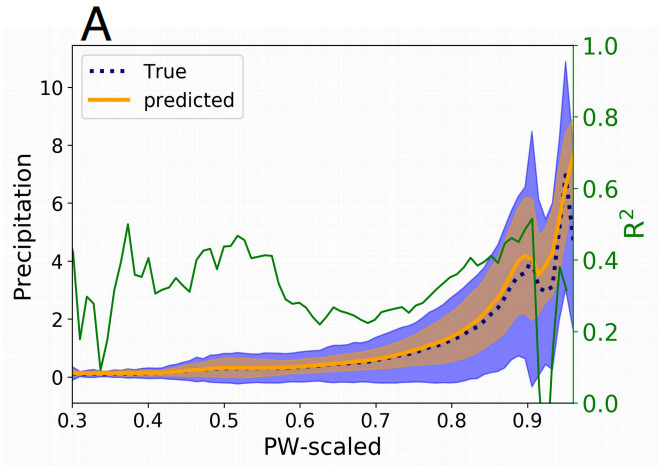
図 1: PW ビンにわたる粗粒降水量の平均
点線: 真の平均降水量
オレンジライン: 予測平均降水量
緑の線: 各 PW ビンで計算される R2
斜線部分: 各グループ内の分散
ベースライン NN は、PW 条件下での降水量平均 (つまり、グループの平均) の主要な挙動と、臨界点付近で発生する急速な遷移を正確に回復します。しかし、実験チームは、全球嵐のシミュレーションで観察された降水量の変動を説明できないことを発見であり、そのパフォーマンス (すべてのサンプルの R2 値によって推定) は約 0.45 です。 R2 値が低いということは、降水量の変動性はある程度把握できますが、投入量と降水量の間に強い関係は見つかりません。、各 PW ビンに対して計算された R2 値は 0.5 を超えません。
同時に、実験チームはBaseline-NNによって予測された降水量の確率密度関数と実際の降水量も比較しました。これは、モデルが降水量分布の裾を予測できないこと、つまり、極端な降水量を予測できないことを示しています。。
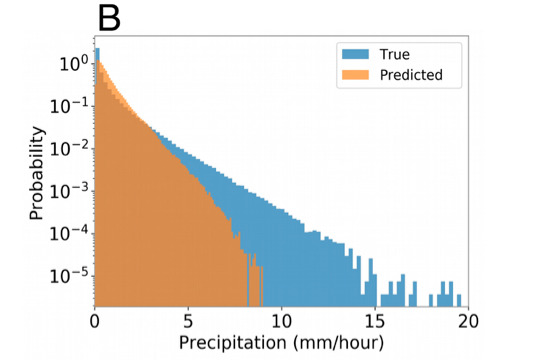
図2:降水量の確率密度関数の模式図
青い部分: 実際の降水量の確率密度関数
オレンジ色の部分: 予測降水量に基づく確率密度関数
研究者らはまた、Baseline-NN をさらにテストするために、ニューラル ネットワークの入力の 1 つとして、粗い粒度での総雲量を使用しました。。総雲量は気候モデルのパラメーター化された変数であり、降水量とは直接関係がないため、これをニューラル ネットワークへの入力として使用すると、降水量のパラメーター化に直接使用される結露水に関する手がかりが得られる可能性があります。これは実際には予測改善にほとんど貢献しませんが、平均雲量が降水量の正確な予測に関連する情報を提供しないことを強調しています。さらに、実験チームはさらなる分析を通じて、CAPE と CIN は予測子として使用できず、予測結果を改善できないことを確認しました。。
図 3: 降水確率密度関数図
青い部分: 実質降水確率密度関数
オレンジ色の部分: 降水確率密度関数を予測します
ある:入力は[PW、SST、qv2m、T2m、顕熱流束、潜熱流束]
b: 入力は[PW、SST、qv2m、T2m、総雲量]
c: 入力は[PW、SST、qv2m、T2m、CAPE、CIN]です。
結論としては、Baseline-NN は降水量と変動を正確に予測する能力が低いということです。。
新型Org-NN
次に実験チームは、予測に Org-NN を使用するという従来の方法を覆しました。 Org-NN にはオートエンコーダーが含まれているため、バックプロパゲーションを通じてニューラル ネットワークの目的関数からフィードバックを直接受け取ることができます。したがって、オートエンコーダーは関連情報を受動的に抽出して、降水量予測を向上させることができます。。
以下の図は、粗視化変数と org を入力とした Org-NN の降水量予測結果を示しています。 Baseline-NN と比較して、Org-NN は大幅な進歩を遂げています。すべてのデータ ポイントで計算すると、予測 R2 は 0.9 に増加します。 PW の各区間では、降水量の少ない区間を除いて、計算された R2 値はほぼ 0.80 に近くなります。
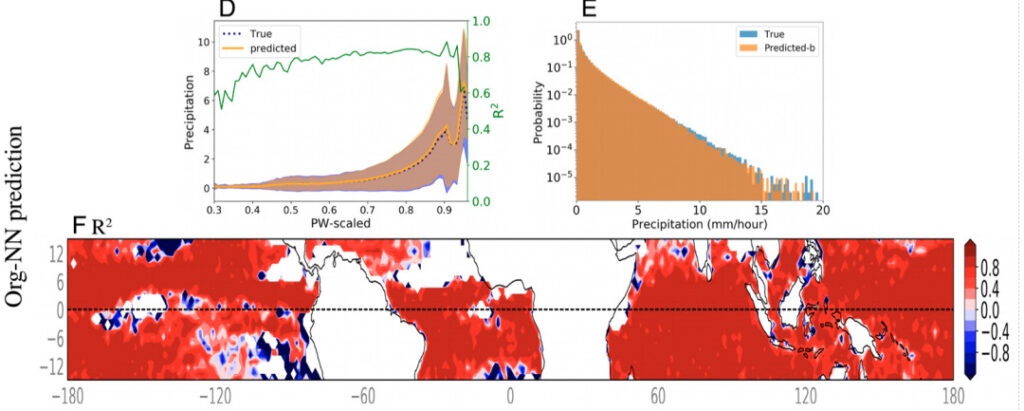
図4:Org-NN予測結果グラフ
D: PW ビンの粗粒降水量平均
E:降水量の確率密度関数の模式図
F: 図 D の各緯度経度位置の各タイム ステップで計算された R2 値。図の白い領域は 0.05 mm/h 未満の降水量を表しており、モデルの入力から除外されています。 Org-NN の R2 値は、降水量閾値に達しない地点付近の地域を除いて、ほとんどの地域で 0.8 より大幅に高くなります。
実験チームは、Org-NN のパフォーマンスをさらに定量化するために、Org-NN と高解像度降水モデルの間で実際の降水量の確率密度関数を比較しました。 Org-NN は、極度の降水量に相当する分布の裾野を含む確率密度関数を完全に捕捉していることがわかりました。これは、Org-NN が極端な降水条件を正確に予測できることを示しています。
実験チームによって得られた結果は、org を入力に組み込むことにより、降水量予測が大幅に改善されることを示しています。これは、サブグリッドスケールの構造が、現在の気候モデルにおける対流と降水量のパラメータ化に重要な欠落情報である可能性があることを示唆しています。。
実験プロセスの概要
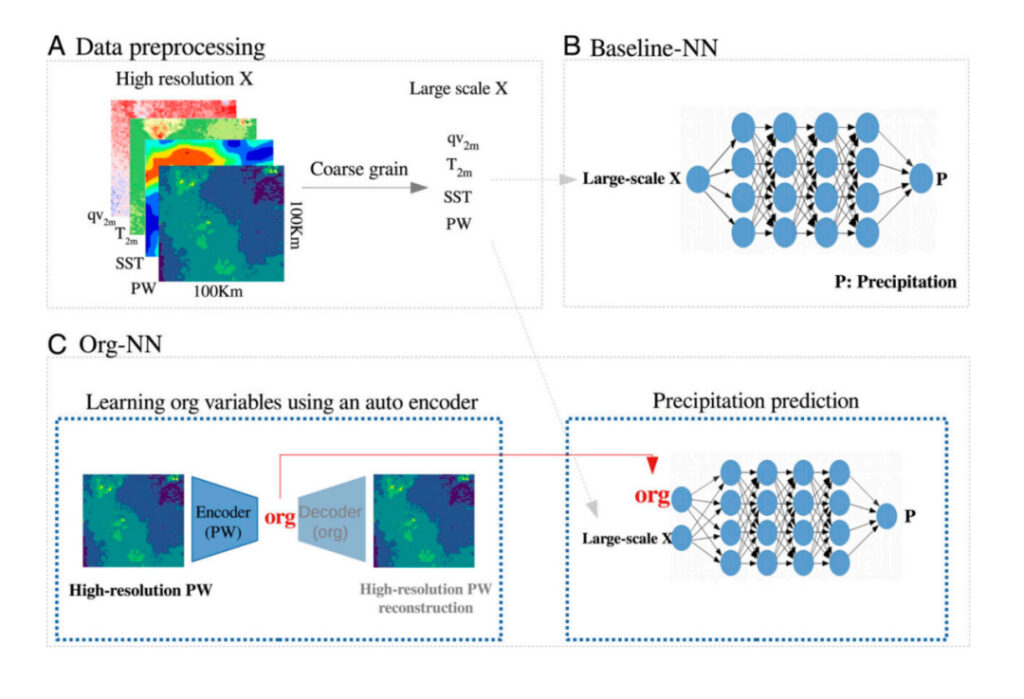
図 5: 実験プロセスの概要
あ:データ処理プロセス: 粗粒度高解像度データ
B: ベースライン-NN: このネットワークは、大まかなスケールの変数 (SST や PW など) を入力として受け取り、大まかなスケールの降水量を予測します。
C:Org-NN: 左の画像は、高解像度の PW を入力として受け取り、ボトルネックを通過した後にそれを再構築するオートエンコーダーを示しています。右側の画像は、大規模な降水量を予測するニューラル ネットワークを示しています。
従来の気候モデルに変化が訪れる
この実験のチームは次のようなところから来ています。 人工知能と物理学で地球を学ぶ (LEAP)、2021年にコロンビア大学に設立されたNSF科学技術センター、その主な研究戦略は、物理モデリングと機械学習を組み合わせ、気候科学、気候シミュレーション、最先端の機械学習アルゴリズムの専門知識を利用して、短期的な気候予測を改善することです。。これは気候科学とデータサイエンスの発展に利益をもたらします。

LEAP Labメンバー紹介
|研究室公式サイト:https://leap.columbia.edu
現在、研究者らは機械学習手法を気候モデルに適用しています。降水強度と変動性の予測を改善し、科学者が地球温暖化に伴う水循環の変化と異常気象パターンをより正確に予測できるようにする。
同時に、この研究は、降水に記憶効果がある可能性を探るなど、新たな研究の方向性も切り開いた。記憶効果とは、大気が最近の気象状況に関する情報を保持し、それがその後の大気状況に影響を及ぼすというものである。新しい方法は、氷床や海洋表面のより優れたシミュレーションなど、降水モデリングを超えた幅広い用途に応用できる可能性があります。
この記事は、HyperAI Super Neural WeChat パブリック プラットフォームで初めて公開されました~








