Command Palette
Search for a command to run...
5 章、25 の仕様、Get データ セットの選択と作成を包括的に行うための「百科事典」

内容の概要:適切なデータセットを作成または選択する方法を学習している場合、この記事では、データセットを選択および作成する際に情報に基づいた意思決定を行うのに役立つ実践的なアドバイスを提供します。
キーワード:機械学習データセット
この記事は、HyperAI Super Neural WeChat パブリック プラットフォームで初めて公開されました。~
著者 |
レビュー | 三陽
高品質のデータセットは、モデルの精度と操作効率を向上させるだけでなく、トレーニング時間とコンピューティング リソースを節約することもできます。
この記事では、Jan Marcel Kezmann の記事「知っておくべき機械学習のデータセット選択の推奨事項と禁止事項」を参照します。では、データ サイエンス エンジニアが落とし穴を回避し、モデル トレーニングのベスト プラクティスを実践できるように、データ セットの作成と選択の方法について詳しく説明します。ヒントを見てみましょう。
英語の原文を読んでください:
目次
1. データセットを選択するためのベストプラクティス
2. 避けるべき罠に注意する
3. 5 つのヒント
4. データセット作成のベストプラクティス
5. データセットの評価
対象者:
初心者、データサイエンティスト、機械学習関連の実務者
1. データセットを選択するためのベストプラクティス
このセクションでは、公開データセットを選択するためのベスト プラクティスについて詳しく説明します。覚えておくべき 6 つの重要な手順を次に示します。
1.1 問題を理解する
入力変数と出力変数、問題の種類 (分類、回帰、クラスタリングなど)、パフォーマンス指標の特定など、解決しようとしている問題を理解することが重要です。
1.2 問題を定義する
業界またはドメイン、必要なデータの種類 (テキスト、画像、音声など)、およびデータ セットに関連付けられた制約を指定して、データ セットの範囲を絞り込みます。
1.3 品質を重視する
信頼性があり、正確で、問題に関連するデータ セットを探します。これらの問題はモデルのパフォーマンスに悪影響を与える可能性があるため、欠損データ、外れ値、不一致がないか確認してください。
1.4 データセットのサイズを考慮する
データセットのサイズは、モデルの精度と汎化能力に影響します。データ セットが大きくなると、モデルの精度と堅牢性が向上しますが、コンピューティング リソースが増え、トレーニング時間が長くなることも意味します。
1.5 バイアスのチェック
データセットにバイアスがあると、不公平または不正確な予測が生じる可能性があります。サンプリングバイアスなどのデータ収集プロセスに関連するバイアスや、性別、人種、社会経済的地位などの社会問題に関連するバイアスに注意してください。
1.6 多様性の追求
さまざまなソース、人、または場所から多様なデータセットを選択すると、モデルがさまざまな例から学習し、過剰適合を回避するのに役立ちます。
2. 避けるべき罠に注意する
このセクションは、事前定義されたデータセットと自分で作成したデータセットに適用されます。
2.1 データが不足している
データが不十分であると、モデルがデータ内の基礎となるパターンを捕捉できず、パフォーマンスが低下する可能性があります。十分なデータがない場合は、データ拡張や転移学習などの手法を使用して、データ セットまたはモデルの機能を強化することを検討できます。ラベルが一貫していれば、複数のデータセットを 1 つにマージできます。
2.2 不均衡なカテゴリー
クラスの不均衡とは、あるクラスに別のクラスよりもサンプルが大幅に多いことを意味し、予測バイアスやその他のモデル エラーにつながる可能性があります。この問題を解決するには、オーバーサンプリング、アンダーサンプリング、クラスの重み付けなどの手法を使用することをお勧めします。過小評価されているクラスを強化すると、この問題も軽減できます。
親切なヒント:
機械学習タスクが異なれば、モデルに対するクラスの不均衡の影響も異なります。たとえば、異常検出タスクでは、標準的な画像分類問題では深刻なクラスの不均衡は通常の現象ですが、この状況は比較的まれです。
2.3 外れ値
外れ値は、他のデータ サンプルと大きく異なるデータ ポイントであり、モデルのパフォーマンスに悪影響を与える可能性があります。データセットに含まれる外れ値が多すぎると、機械学習または深層学習モデルが目的の分布を学習することが困難になることがよくあります。
ウィンゾリゼーションなどの手法を使用して外れ値を削除または修正するか、平均/中央値代入法を使用してサンプル内に発生するすべての欠損値を平均または中央値に置き換えることを検討してください。
2.4 データの覗き見と漏洩
データ スヌーピングはオーバーフィッティングやパフォーマンスの低下につながる可能性があります。これを回避するには、次のようにします。データ セットはトレーニング セット、検証セット、テスト セットに分割する必要があり、モデルのトレーニングにはトレーニング セットのみを使用する必要があります。
一方で、テスト セットからのデータを使用してモデルをトレーニングすると、データ漏洩が誘発され、過度に楽観的なパフォーマンス推定が行われる可能性があります。データ漏洩を回避するには、検証セットとテスト セットを常に分離し、最終モデルの評価にのみ使用する必要があります。
3. 5 つのヒント
- 転移学習では、事前トレーニングされたモデルを使用して関連する問題を解決し、特定の問題については、より小さなデータセットを微調整に使用できます。
- 複数のデータセットを結合してデータセットのサイズと多様性を高め、より正確で堅牢なモデルを作成します。データの互換性と品質の問題に注意する必要があります。
- クラウドソーシングを使用して、大量のラベル付きデータを迅速かつ安価に収集します。品質管理と逸脱の問題に注意を払う必要があります。
- コードでデータにアクセスするためのさまざまな企業や組織のデータ API に注目してください。
- 標準化されたデータセットと評価指標を提供する利用可能なベンチマークを確認して、同じ問題に対する異なるモデルのパフォーマンスの違いを比較しやすくします。
4. データセット作成のベストプラクティス
4.1 問題と目標を定義する
データを収集する前に、予測したいターゲット変数、解決したい問題の範囲、データセットの使用目的を明確にしてください。
質問と目標を明確にすると、関連するデータの収集に集中できます。データセットの前提と制限を理解しながら、無関係なデータやノイズの多いデータに時間とリソースを浪費することを避けます。
4.2 多様で代表的なデータセットを収集する
多様なソースやドメインからデータを収集することで、データセットが現実世界の問題を確実に表していることが保証されます。これには、さまざまな場所、人口統計、期間からデータを収集し、データ セットが特定のグループや地域に偏らないようにすることが含まれます。
さらに、データに交絡変数、推定される原因と推定される結果に影響を与える 3 番目の未測定の変数が含まれていないことを確認してください。これは結果に影響を与えます。
4.3 データに慎重にラベルを付ける
ラベルを使用して、明確でグラウンド トゥルースを明確に反映できるデータにラベルを付けます。また、複数のアノテーターまたはクラウドソーシングを使用して、データに対する個人的な偏見の影響を軽減し、ラベルの品質と信頼性を向上させます。トレーニングと評価プロセスの追跡、共有、再現を容易にするために、データにバージョンを付けることをお勧めします。
親切なヒント:
データセットに 80% の正しいラベルのみが含まれている場合、ほとんどの場合、最良のモデルであっても 80% よりも正確ではありません。
4.4 データの品質と整合性を確保する
データ品質とは、データの正確性、完全性、一貫性を指します。データ クリーニング、外れ値の検出、欠損値の代入などの手法を使用して、データ セットの品質を向上させます。さらに、データ形式が機械学習アルゴリズムにとって理解しやすく、処理しやすいものであることを確認する必要があります。
4.5 データのプライバシーとセキュリティを確保する
プライバシーを保護するには、データが安全に収集および保管され、機密情報が匿名化または暗号化されていることを確認してください。さらに、転送中および保存中のデータを保護するために暗号化テクノロジーの使用を検討してください。
親切なヒント:
検証データの利用仕様には法令等を遵守するようご注意ください。
5. データセットの評価
データセットが次の 5 つの基準を完全に満たしているかどうかを確認します。
- データサイズ:一般的に言えば、データは多いほど良いです。
- データ配信:データセットがバランスが取れており、代表的であることを確認してください。
- データ品質:クリーンで一貫性があり、エラーのないデータが重要です
- データの複雑さ:データが過度に複雑でないことを確認してください。
- データの依存関係:データは問題に関連している必要があります。
上記は、データセットの選択と作成ガイドの完全な内容です。適切なデータセットを選択することが機械学習の鍵となります。このガイドが、高品質のデータセットを選択または作成し、正確で堅牢なモデルをトレーニングするのに役立つことを願っています。
大規模な公開データセットのオンラインダウンロード
これまでのところ、HyperAI 公式 Web サイトは 1,200 以上の高品質パブリック データ セットを公開し、約 500,000 件のダウンロードを完了し、2,000 TB 以上のトラフィックに貢献し、国内外の高品質パブリック データ セットへのアクセスのしきい値を大幅に下げています。
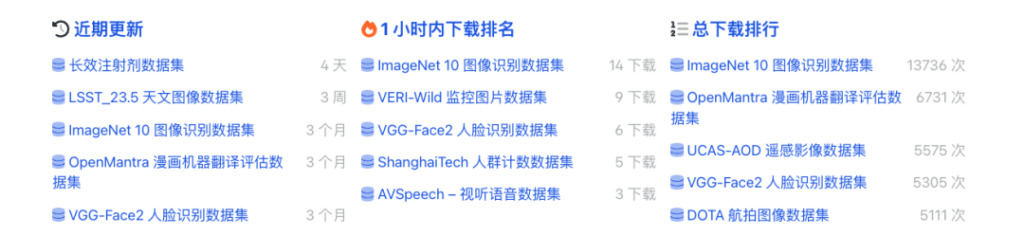
以下のリンクにアクセスして、必要なデータセットを検索してすぐにダウンロードし、モデルのトレーニングを開始してください。
公式ウェブサイトにアクセスしてください: https://orion.hyper.ai/datasets
この記事は、HyperAI Super Neural WeChat パブリック プラットフォームで初めて公開されました。~








