Command Palette
Search for a command to run...
Him Computing: TVM ベースの DSA AI コンパイラ構築

皆さんこんにちは。Him Computing の Dam Xiaoqiang です。今日は 3 人の同僚と TVM で NPU をサポートする方法を共有します。
DSA コンパイラーによって解決される本質的な問題は、さまざまなモデルをハードウェア上に展開する必要があり、さまざまな抽象化レベルの最適化手法を使用して、モデルがチップ内をできるだけ埋めるように、つまりバブルを圧縮するために使用されることです。スケジュールの立て方に関しては、Halide が説明したスケジューリング トライアングルがこの問題の本質です。
DSA コンパイラによって解決されるべき主な問題は何ですか?まず、DSA アーキテクチャを抽象化します。図に示すように、habana、Ascend、および IPU はすべて、この抽象アーキテクチャのインスタンス化です。一般に、コンピューティング コアの各コアには、ベクトル、スカラー、テンソルのコンピューティング ユニットがあります。命令操作とデータ粒度の観点から、多くの DSA は 2 次元および 3 次元のベクトルおよびテンソル命令など、比較的粒度の粗い命令を使用する傾向があります。また、次のような粒度の細かい命令を使用するハードウェアも数多くあります。 1次元SIMDとVLIW。命令間の依存関係の一部は、ソフトウェア制御用の明示的なインターフェイスを通じて公開され、一部はハードウェア自体によって制御されます。メモリはマルチレベル メモリで、ほとんどがスクラッチパッド メモリです。並列処理には、ストリーム並列処理、クラスター並列処理、マルチコア並列処理、および異なるコンピューティング コンポーネント間のパイプライン並列処理など、さまざまな粒度と次元があります。
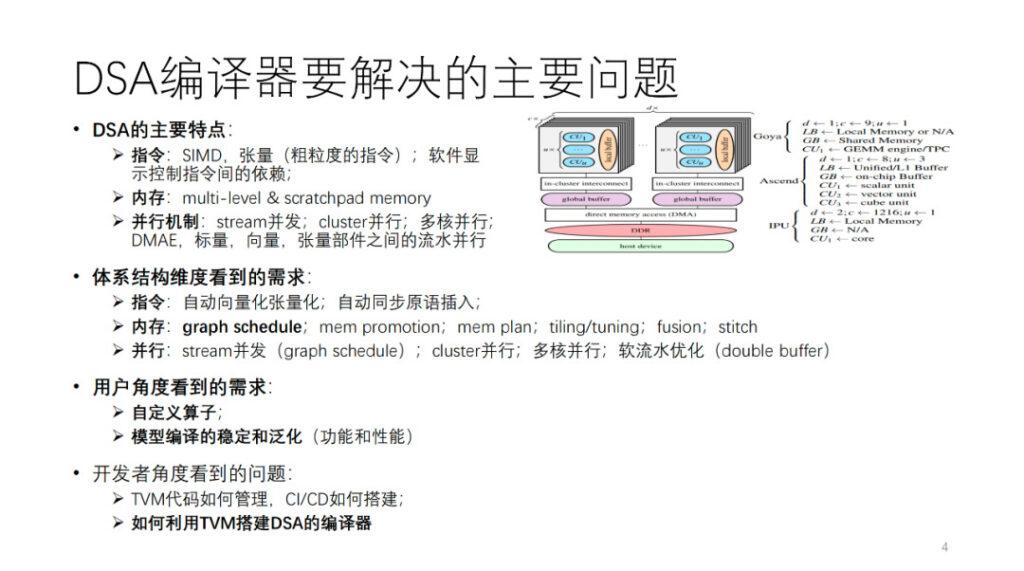
このようなアーキテクチャをサポートするために、コンパイラ開発者の観点から、アーキテクチャの上記の側面から AI コンパイラに対してさまざまな要件が提示されます。この部分については後ほど詳しく説明します。
ユーザーの観点からは、できるだけ多くのモデルや演算子を正常にコンパイルできるように、まず安定した汎用コンパイラーが必要です。また、ユーザーは、コンパイラーが確実にカスタマイズされたプログラミング アルゴリズムと演算子を提供できることを望んでいます。いくつかの主要なアルゴリズムに関する革新的な作業は独立して実行できます。最後に、私たちのようなチームや友人は、TVM を使用して AI コンパイラーを構築する方法 (自己開発のオープンソース TVM コードの管理方法、効率的な CI の構築方法など) にも注目します。これが今日私たちが共有する内容です。次に私の同僚がコンパイルと最適化の部分について話します。
CHIM Computing Wang Chengke: DSA コンパイル最適化プロセス
この部分は、Him のコンピューティング エンジニアである Wang Chengke によってオンサイトで共有されます。
まず、彼の編集実践の全体的なプロセスの概要を紹介しましょう。
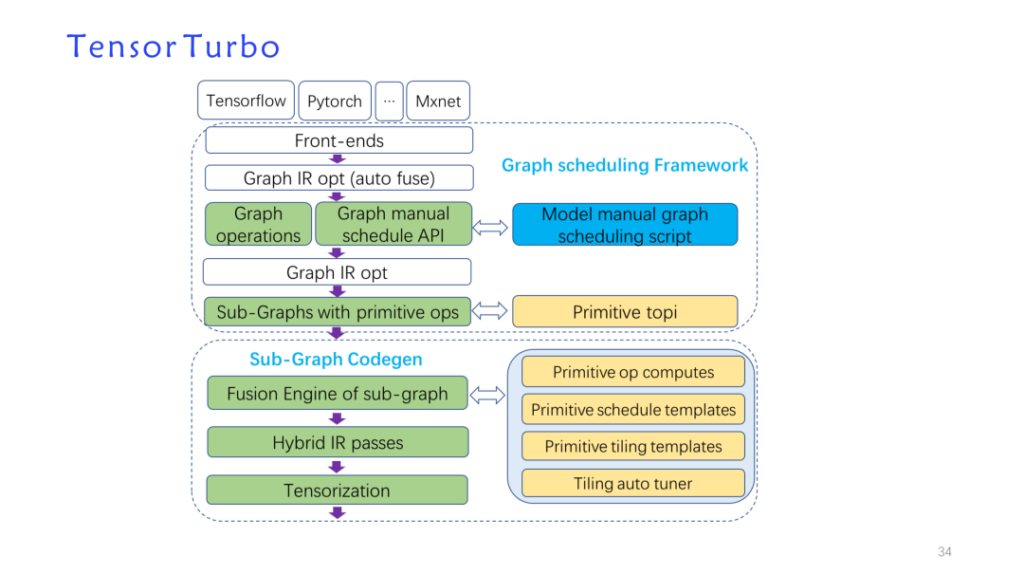
先ほど述べたアーキテクチャ上の特徴に応じて、TVM データ構造に基づいて独自開発の最適化パスを構築し、TVM を再利用して新しいモデル実装である tensorturbo を形成しました。
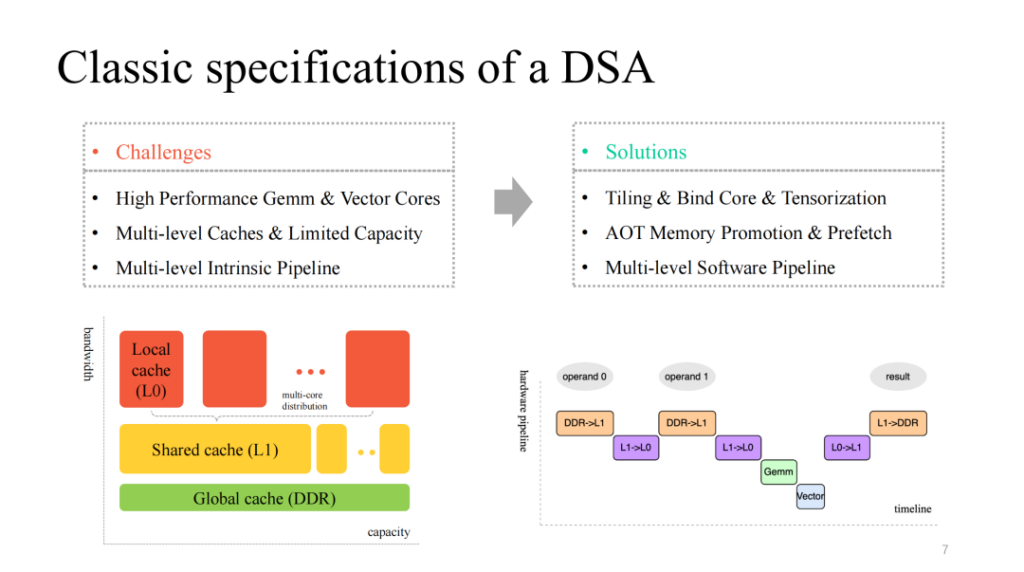
比較的古典的な DSA アーキテクチャは、一般に、効率的でカスタマイズされたマトリックス層およびベクトル層のマルチコア コンピューティング コアを提供し、対応するマルチ層キャッシュ メカニズムを備え、並列実行可能なマルチモジュール実行も提供します。したがって、次のような問題に対処する必要があります。
- データ計算をセグメント化し、コアを効率的にバンドルし、カスタマイズされた命令を効率的にベクトル化します。
- 限られたオンチップ キャッシュを細かく管理し、さまざまなキャッシュ レベルで対応するデータのプリフェッチを実行します。
- マルチモジュール実行用にマルチステージ パイプラインを最適化し、より良い加速率を得るように努めます。
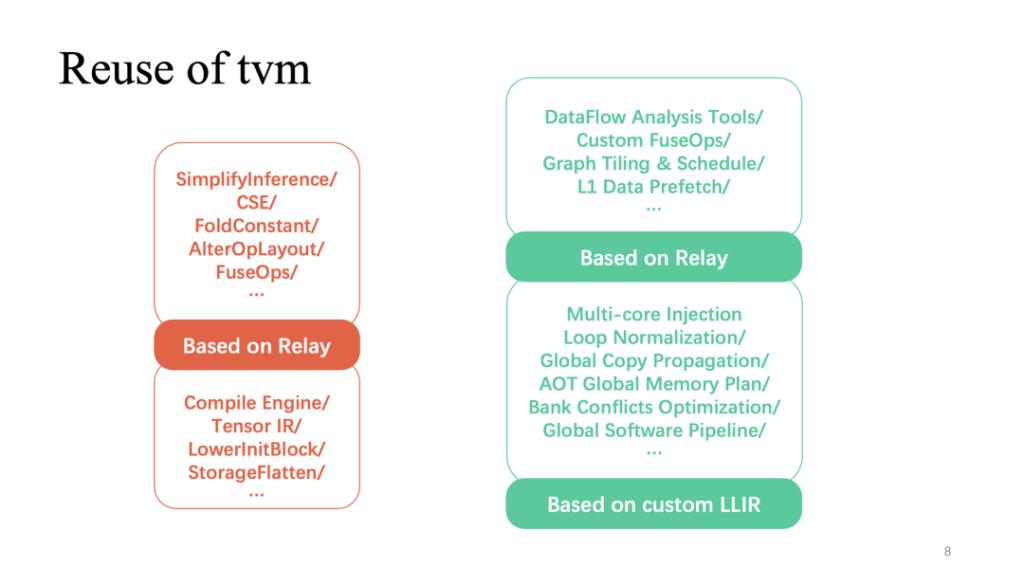
ここの赤い部分 (上の図) は、プロセス全体で TVM の比較的再利用性の高い部分を示しています。リレーに実装されたより一般的なレイヤー関連の最適化は、直接再利用できます。さらに、より再利用性の高い部分は TensorIR と The に基づいています。カスタム LLIR のオペレーター実装部分。先ほど述べたようなハードウェア機能に関連するカスタマイズの最適化には、より多くの自己調査作業が必要です。
まず、レイヤーに関する自主研究作品を見てみましょう。
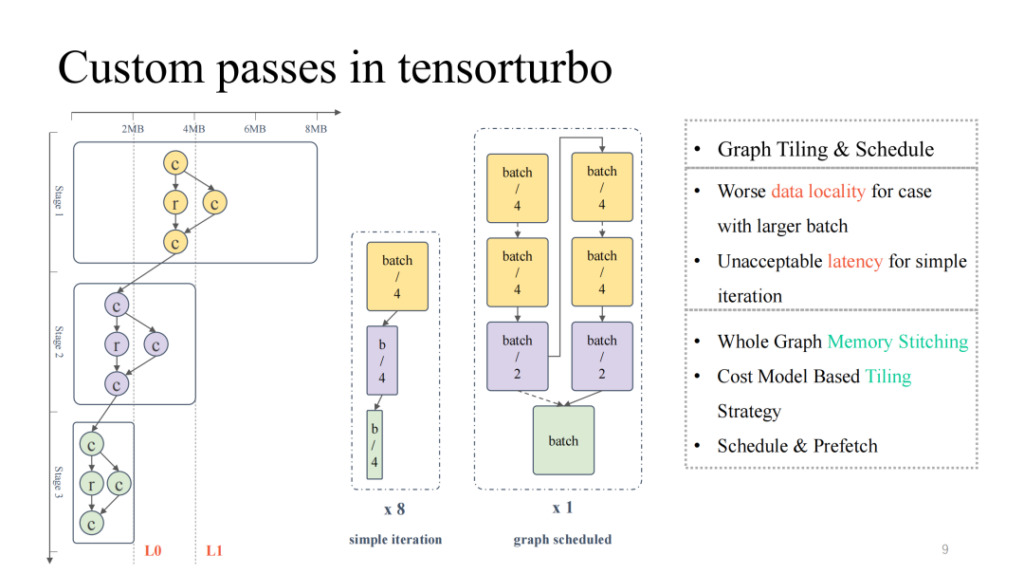
左端の典型的な計算フロー図に注目してください。全体的なキャッシュ占有量と計算占有量が常に減少しており、逆ピラミッド状態を示していることがわかります。モデル規模が大きい前半では、オンチップキャッシュ常駐の問題の解決に重点を置く必要があり、モデル規模が小さい後半では、低コンピューティングの問題に対処する必要があります。ユニットの使用率。バッチ サイズの調整など、モデル サイズを単純に調整する場合、バッチ サイズが小さくなるとレイテンシが低下し、対応するスループットも低下します。同様に、バッチ サイズが大きくなるとレイテンシは高くなりますが、全体的なパフォーマンスは向上する可能性があります。スループット。
次に、グラフ スケジューリングを使用してこの問題を解決できます。まず、プロセス全体で比較的高い計算利用率を確保するために、比較的大きなバッチ サイズの入力が許可されます。次に、セグメント化とスケジューリング戦略に加えて、グラフ全体に対してストレージ分析が実行され、前半の結果が得られます。高い計算コア使用率の結果を達成しながら、モデルをオンチップでより適切にキャッシュできます。実際には、レイテンシとスループットの両方が良好なパフォーマンスを達成することができます (詳細については、OSDI 23 の記事「ドメイン固有のアクセラレータに向けたディープ ニューラル ネットワークの計算グラフの効果的なスケジューリング」を参照してください。このリンクは 6 月に公開されています)。
次に、柔らかい流水の別の加速仕事を紹介します。
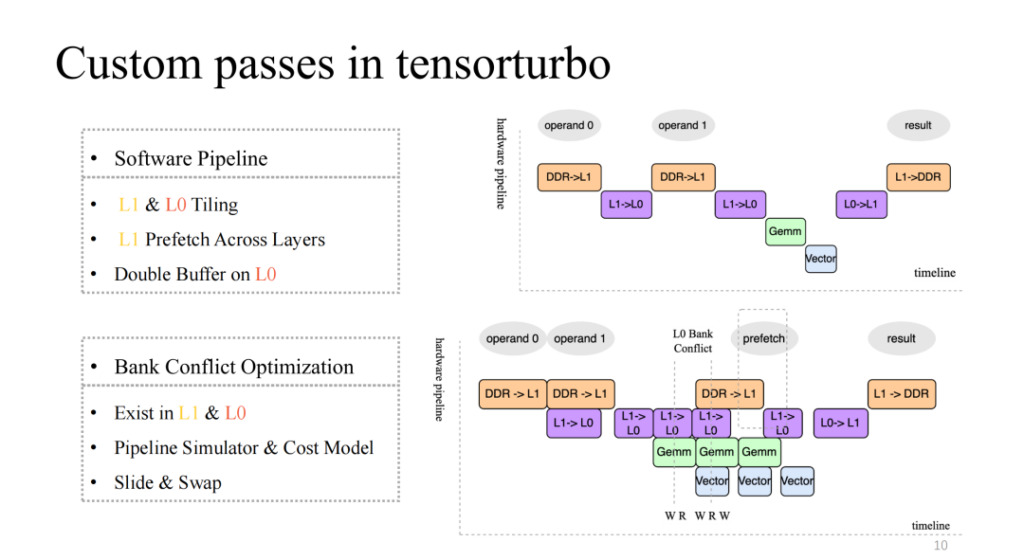
右上の図に注目してください。比較的ネイティブな 4 ステージのパイプラインが実装されていますが、これは明らかに効率的なパイプラインではありません。一般に効率的なパイプラインでは、数回の反復後に 4 つの実行ユニットすべてを同期および並列化できる必要があります。これには、L1 と L0 でのセグメンテーション、L1 でのクロスレイヤー データのプリフェッチ、L0 レベルでのダブル バッファー操作などの作業が必要です。これらの作業により、右下の図に示すように、比較的高速なパイプラインを実現できます。
これにより、たとえば、複数の実行ユニットによるキャッシュへの同時読み取りおよび書き込みの数が、現在のキャッシュがサポートできる同時読み取りおよび書き込みの数よりも多い場合、この問題が発生します。メモリアクセス効率が低下し、これがバンク競合の問題です。この点に関して、コンパイル時にパイプラインを静的にシミュレートし、競合オブジェクトを抽出し、コスト モデルを使用して割り当てられたアドレスを交換および変換することで、この問題の影響を大幅に軽減できます。
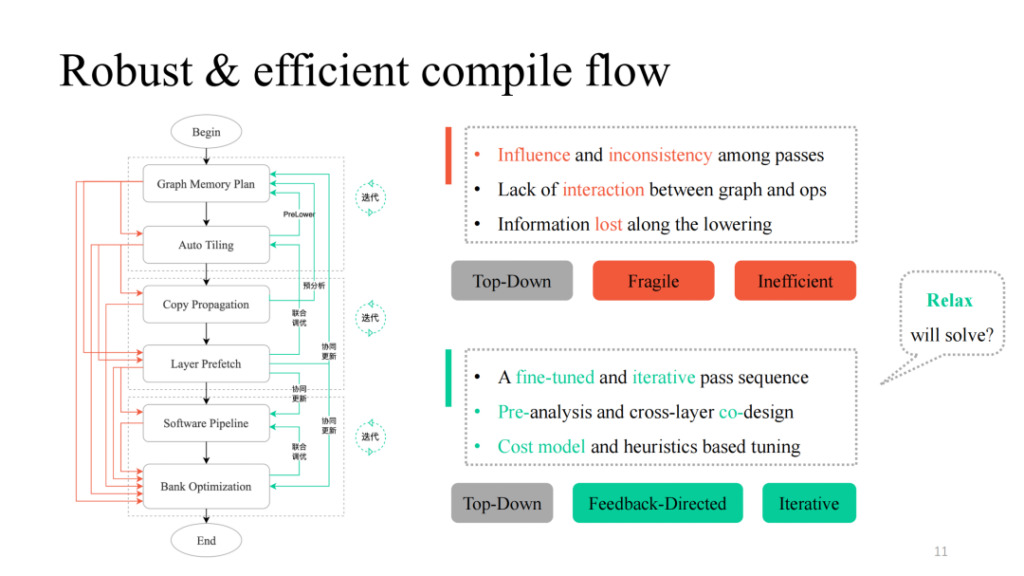
さまざまなパスを用意した後、それらを単純なトップダウン方式で結合し、左図の黒いプロセスに従って、機能的に実行可能なコンパイル パイプラインを取得できます。しかし、実際には、Siyuan氏が言及したパス間の相互影響、相互作用ロジックの欠如、レイヤーとオペレーター間の通信ロジックの欠如など、多くの問題が見つかっています。実際には、各パスまたはその組み合わせによってコンパイル失敗が発生することがわかります。より堅牢にする方法は?彼は、失敗する可能性のある各パスにフィードバック パスを提供し、層と演算子の間に対話型ロジックを導入し、事前分析と事前下位操作を実行し、重要な部分にいくつかの反復調整メカニズムを導入して、最終的に全体的なパイプライン実装は適応性が高く、強力なチューニング機能を備えています。
また、上記の作業におけるデータ構造の変換と関連する設計アイデアには、現在の TVM Unity 設計と多くの類似点があることにも気づきました。また、Relax がより多くの可能性をもたらすことを期待しています。
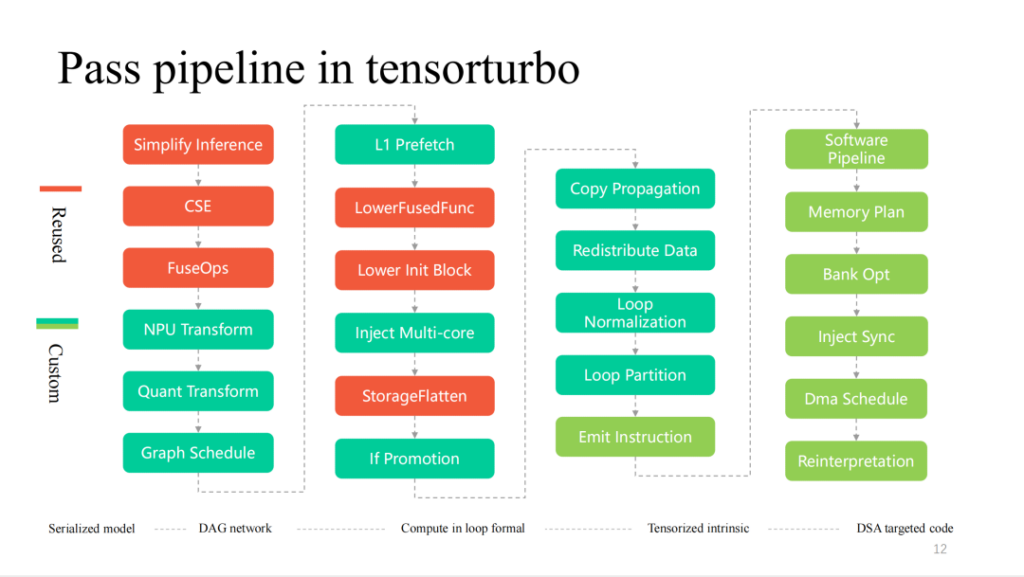
ここに示されているのは、Shim のコンパイル プロセスの詳細なパスで、左から右にレイヤーごとに減少するプロセスです。TVM の再利用がより高くなり、ハードウェア機能の部分に近づきます。さらにカスタマイズされたパス。
以下では、引き続きいくつかのモジュールを詳細に紹介します。
Shim Computing Liu Fei: DSA のベクトル化とテンソル化
この部分は、Him のコンピューティング エンジニアである Liu Fei によってオンサイトで共有されます。
この章では、Shim のベクトル化とテンソル化の作業を紹介します。命令粒度を考えると、命令粒度が粗いほど Tensor IR の多層ループ表現に近づくため、ベクトル化テンソル化の難易度は低くなります。逆に、命令粒度が細かいほど難易度は高くなります。当社の NPU 命令は、1 次元/2 次元/3 次元テンソル データ計算をサポートしています。ネイティブの TVM tensorize プロセスも検討しましたが、Compute Tensorize の複雑な式の表現能力に限界があることを考慮すると、たとえば、if 条件などの複雑な式を Tensorize するのは難しく、Tensorized ベクトル化後にスケジュールすることはできません。
さらに、TensorIR Tensorize は当時開発中であり、開発ニーズを満たすことができなかったため、Him は命令エミッションと呼ぶ独自の命令ベクトル化プロセスのセットを提供しました。このプロセスでは、さまざまな次元の命令を含む、約 120 の Tensor 命令がサポートされています。

私たちの指導プロセスは大きく 3 つのモジュールに分かれています。
- 起動前の最適化。サイクル軸を変換すると、より多くの起動条件とコマンド起動の可能性が提供されます。
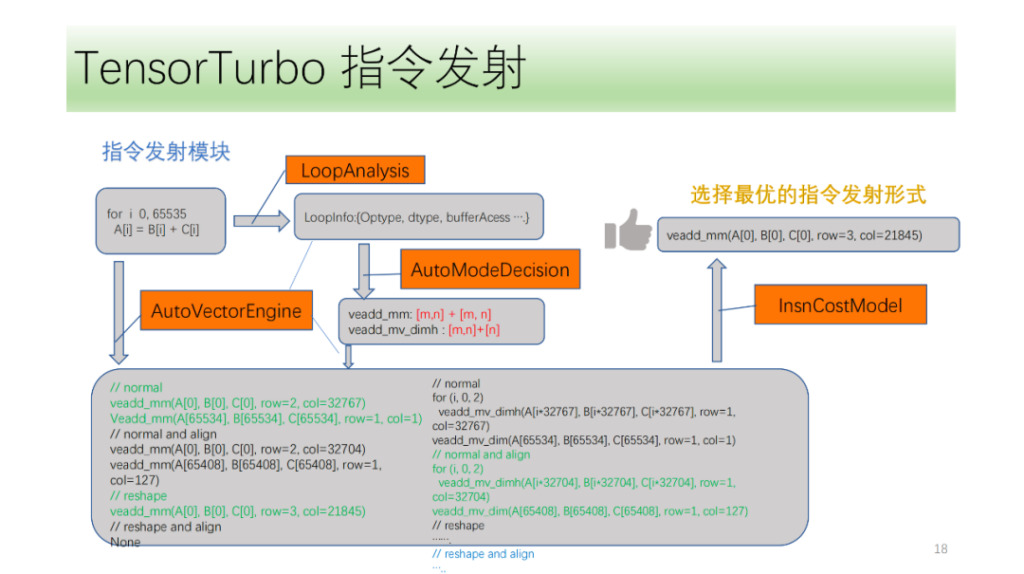
- コマンド発行モジュール。ループの結果と情報を分析し、最適な命令生成方法を選択します。
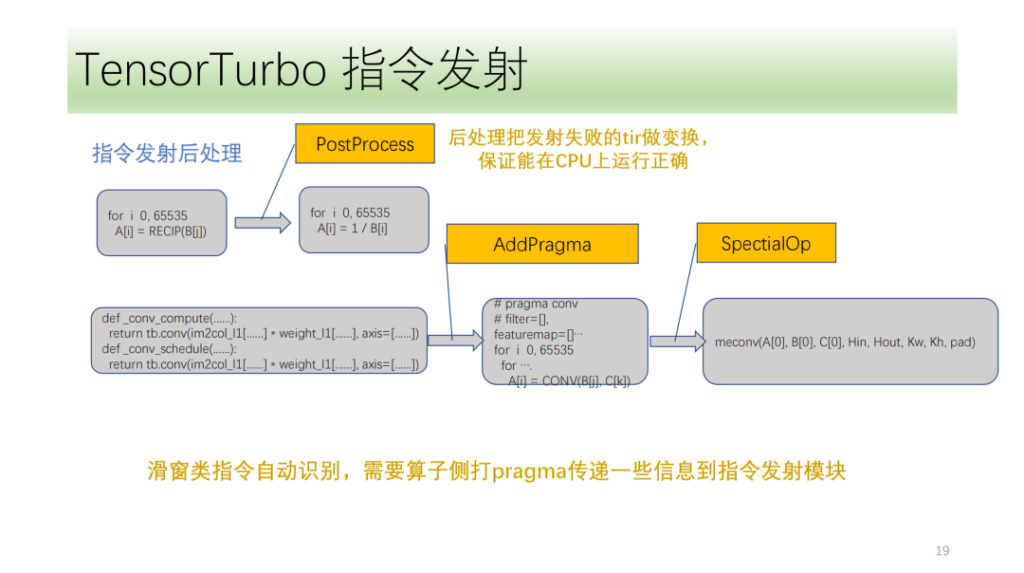
- コマンド発行後のモジュール。 CPU 上で正しく実行されるように、失敗後に指定された起動を処理します。
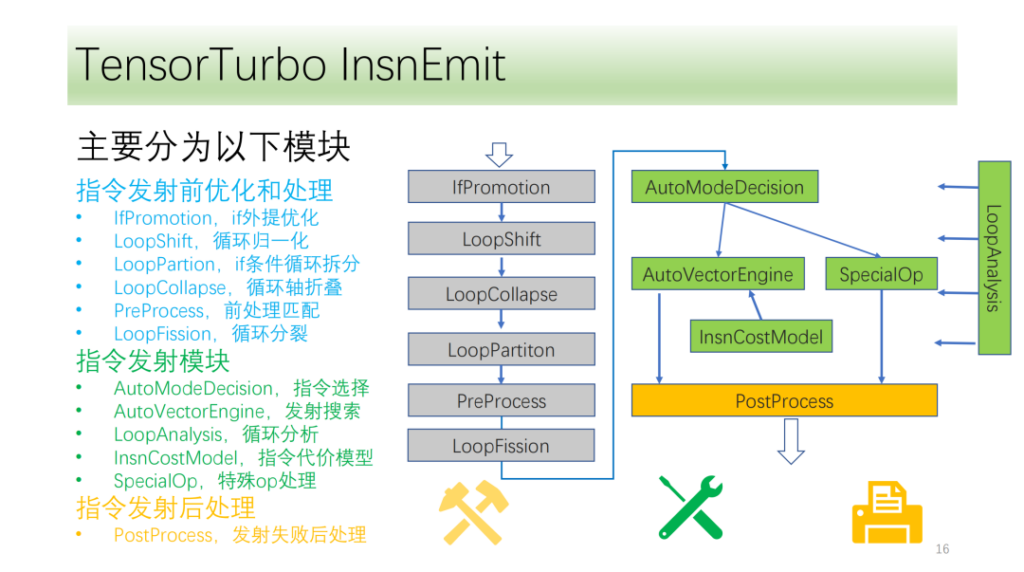
以下はコマンド発行前の最適化および処理モジュール、これらはすべて最適化パスの集合で構成されており、その内、IfPromotion はループ軸の起動を妨げる if 文を可能な限り抽出するもの、PreProcess は対応する命令なしで演算子を分割するもの、LoopShift は境界を正規化するものです。 LoopCallapseは連続するループ軸を可能な限り結合する、LoopPartitionはifに関するループ軸を分割する、LoopFissionはループ内の複数のstore文を分割する。
この例からわかるように、IR は最初は命令を発行できませんが、最適化後、最終的に 2 つの Tensor 命令を発行できるようになり、すべてのサイクル軸が命令を発行できるようになります。
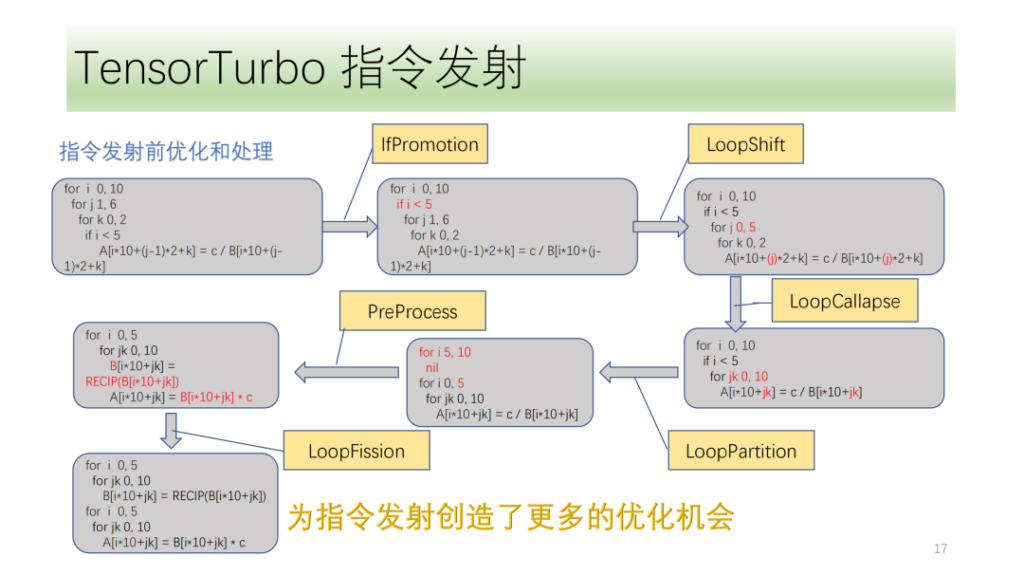
次に、コマンド発行モジュールがあります。まず、命令発行モジュールがループ内の構造を周期的に解析し、Optype、dtype、bufferAcess などの情報を取得した後、命令認識によってループ軸がどの命令を発行できるかを特定します。 IR 構造は複数の NPU 命令に対応する可能性があるため、発行される可能性のあるすべての命令を識別し、VectorEngine 検索エンジンは命令の位置合わせや形状変更などの一連の情報に基づいて各命令を発行できる可能性を検索します。最後に、CostModel が計算を実行して、発射に最適な発射形式を見つけます。
最後は命令後処理モジュールです。主な目的は、命令の発行に失敗した tir を処理して、CPU 上で正しく実行できることを確認することです。いくつかの特別な命令もあります。Sim は、アルゴリズムのフロントエンドにいくつかのマークを付ける必要があります。命令発行モジュールは、これらのマークと独自の IR 分析を使用して、対応する命令を正しく起動します。
上記は、Him の DSA テンソル化およびベクトル化プロセス全体です。また、最近よく議論されているマイクロカーネル ソリューションなど、いくつかの方向性も検討しました。その基本的な考え方は、計算プロセスを 2 つの層に分割し、1 つの層を結合したマイクロカーネルの形で結合し、もう 1 つの層を検索メソッドを使用して見つけます。最後に、2 つの層の結果を結合します。最適な結果を選択します。これには、ハードウェア リソースを最大限に活用しながら、検索の複雑さを軽減し、検索効率を向上させるという利点があります。
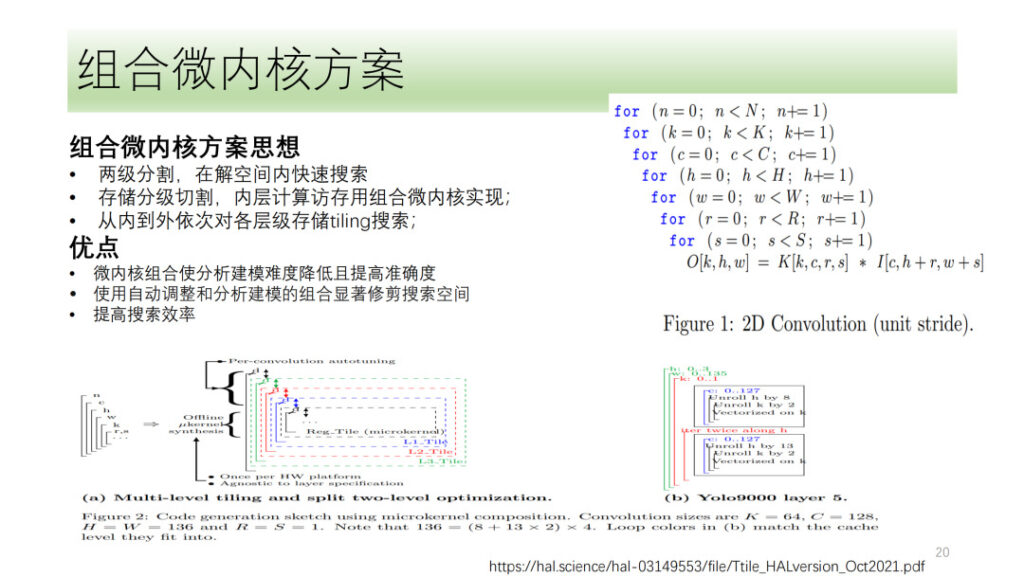

Shim はマイクロカーネルに関する関連調査も行っていますが、マイクロカーネル ソリューションが現在のソリューションと比較してパフォーマンスやその他の側面が大幅に向上していないことを考慮すると、Shim はまだマイクロカーネルの方向で探索段階にあります。
Him Calculation Yuan Sheng: DSA のカスタム オペレーター
この部分は、Him のコンピューティング エンジニアである Yuan Sheng によってオンサイトで共有されます。
まず第一に、オペレーターの開発は現在 4 つの大きな問題に直面していることを私たちは知っています。
- サポートする必要のあるニューラル ネットワーク オペレーターは多数あり、分類すると基本的なオペレーターは 100 を超えます。
- ハードウェア アーキテクチャは常に反復されるため、対応する命令と演算子に含まれるロジックを変更する必要があります。
- パフォーマンスに関する考慮事項。先ほど述べた演算子の融合(ローカルメモリ、共有メモリ)とグラフコンピューティングの情報転送(セグメンテーションなど)。
- オペレーターはユーザーに対してオープンである必要があり、ユーザーはオペレーターをカスタマイズするためにのみソフトウェアを入力できます。
主に以下の3つの観点から紹介します。 1 つ目はグラフ演算子です。グラフ演算子はリレー API に基づいており、基本的な言語演算子に分割されています。
次の図は例です。
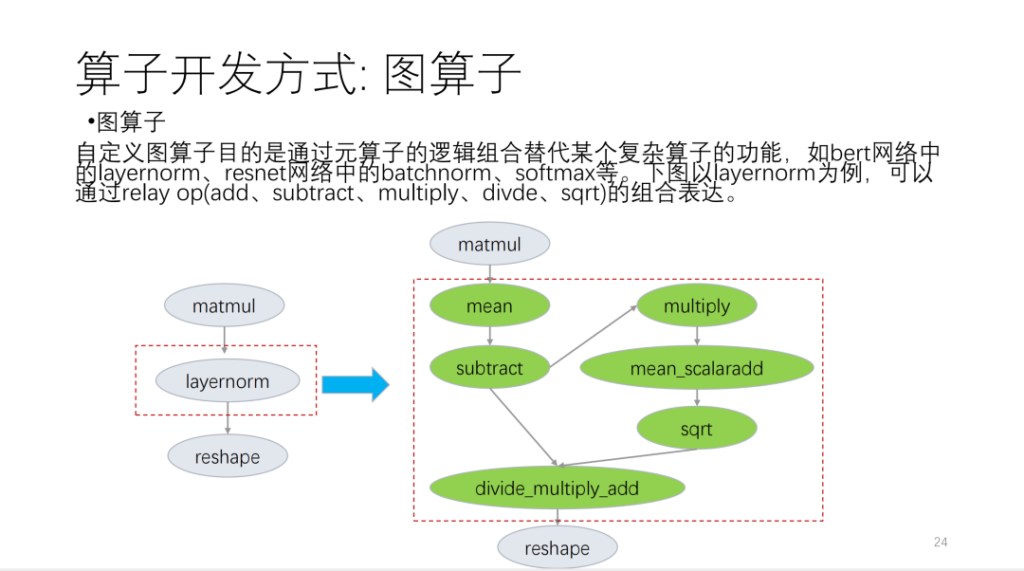
2 つ目はメタオペレーターです。いわゆるメタオペレーターは TVM Topi に基づいており、演算/スケジュールを使用してオペレーター アルゴリズム ロジックとループ変換関連ロジックを記述します。オペレータを開発するとき、この状況に基づいて、多くのオペレータ スケジュールが再利用できることがわかります。Him はスケジュールのようなテンプレートのセットを提供します。現在、オペレータを多くのカテゴリに分類し、これらのカテゴリに基づいて、新しいオペレータはスケジュール テンプレートを大量に再利用します。
次は、NPU に基づいた、より複雑な演算子です。topk、nms、および制御フローを使用するその他のアルゴリズムには、現在、compute/schedule を使用して記述するのが難しい、スカラー計算が含まれていることがわかります。同様の図書館。これは、複雑なロジックをライブラリでコンパイルし、それを IR Builder と組み合わせてオペレーター全体のロジックを出力することに相当します。
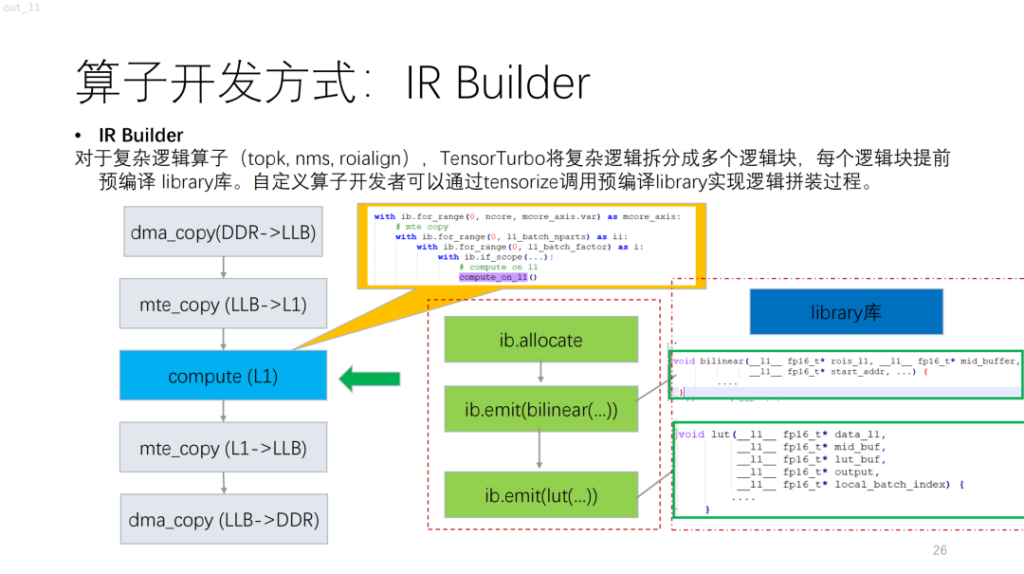
次にオペレーターの細分化です。 NPU の場合、GPU や CPU と比較して、TVM の各命令は連続したメモリ ブロックを操作するため、メモリ サイズの制限があります。また、この場合、探索空間は大きくありません。これらの問題に基づいて、Shim は解決策を提供しました。まず、候補セットがあり、実行可能な問題の解決策がその候補セットに組み込まれます。次に、主にパフォーマンス要件と NPU 命令の制限を考慮して、その実現可能性が説明されます。演算子の特性と使用される計算ユニットの特性を考慮したコスト関数が導入されます。
オペレーター開発にとって次に難しいのは、フュージョン オペレーターです。現在、私たちは 2 つの爆発的な問題に直面しています。1 つ目は、独自の演算子を他の演算子と組み合わせる方法がわからないということです。2 つ目は、NPU 内に多数のメモリ レベルがあり、その結果、メモリ レベルが爆発的に融合してしまうことがわかります。 Him LLB には、この状況に基づいて、共有メモリとローカル メモリの組み合わせがあり、まず、層によって与えられたスケジューリング情報に従って、データ移動操作が挿入されます。スケジュール内のマスター操作とスケジュール スレーブ操作はスケジュール情報を調整し、最後に現在の命令の制限やその他の問題に基づいて後処理を実行します。

最後に、Shim がサポートする演算子が主に表示されます。 ONNX オペレーターは約 124 あり、現在は約 112 をサポートしており、90.3% を占めています。同時に、Sim には、大きな素数、融合の組み合わせ、およびいくつかのパターンの融合の組み合わせをテストできる一連のランダム テストがあります。
要約する
この部分は、コンピューティング エンジニアの Sim Xiaoqiang によってオンサイトで共有されます。
これは TVM に基づいて彼によって構築された CI であり、200 を超えるモデルと多くの単体テストが実行されています。 MR が CI リソースを取得しないと、コードの送信に 40 分以上かかります。計算量は非常に多く、おそらく自社開発のコンピューティングカードは20枚以上、CPUマシンも数台あると思われます。
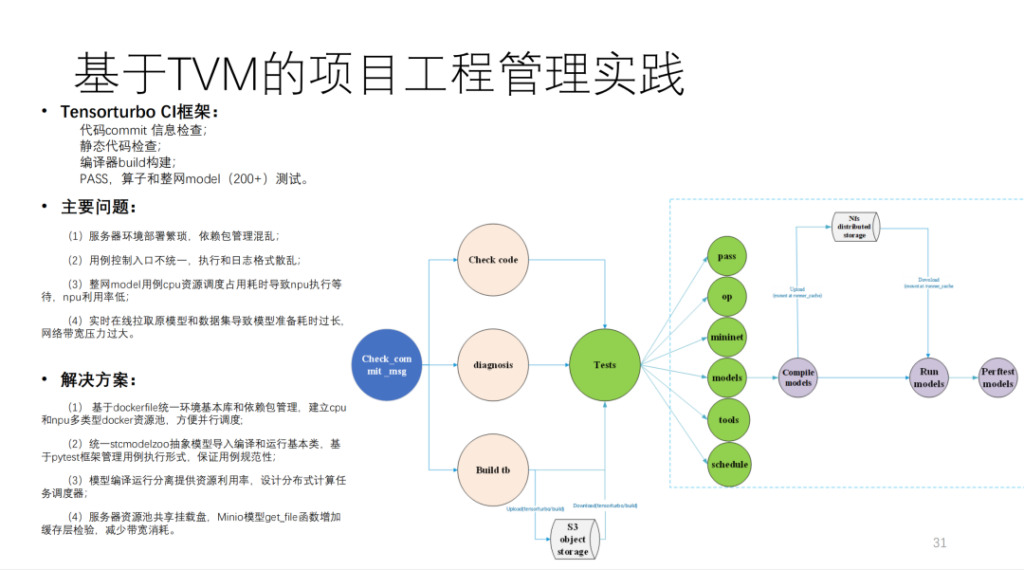
要約すると、以下に示すように、Him のアーキテクチャ図になります。
効果から判断すると、パフォーマンスは大幅に向上しています。また、手書きモデルを自動生成するチームに対してベンチマークを実行すると、基本的に 90% を超える可能性があります。

これは Him のコードの状況です。TVM と独自開発のコードがサードパーティのデータ構造として使用されており、TVM に変更を加える必要がある場合に使用されます。パッチフォルダー内のTVMに変更を加えるだけです。ここには 3 つの原則があります。
- それらのほとんどは、自社開発のパスと自社開発のカスタム モジュールを使用します。
- パッチは TVM ソース コードの変更を制限し、適時にアップストリームすることができます。
- TVM コミュニティと定期的に同期し、最新のコードをウェアハウスに更新します。
上の図にはコード全体のボリュームも示されています。
要約:
- TVM に基づいた Sim の第 1 世代および第 2 世代のチップをエンドツーエンドでサポートします。
- リレーと tir に基づいてすべてのコンパイル最適化要件を実装します。
- tir に基づいた 100 以上のベクトル テンソル命令の自動生成を完了しました。
- TVM に基づいたカスタム オペレーター スキームを実装しました。
- 第 1 世代モデルは 160 以上をサポートし、第 2 世代では 20 以上が有効になりました。
- 手書きの極限に近い性能を持ったモデルです。
Q&A
Q1: フュージョン オペレーターに興味がありますが、TVM の tir とどのように組み合わせることができますか?
A1: 右の図では、同じ計算レベルで、まず、オペレータに 2 つの入力と 1 つの出力がある場合、27 のオペレータ フォームがあります。次に、さまざまな演算子が接続されている場合、スコープは 3 つのうちの 1 つになる可能性があるため、固定パターンを想定しません。では、それを TVM に実装するにはどうすればよいでしょうか?まず、レイヤーのスケジューリングに従って、フロントとリアの追加および中間のスコープがどこにあるかを決定します。レイヤーは非常に複雑なプロセスであり、その出力結果によって、オペレーターがどのキャッシュに存在するか、および使用可能なキャッシュがいくつあるかが決まります。このスケジューリングの結果を利用して、オペレーター層で自動フュージョンオペレーター生成を実行し、例えばスコープ情報に基づいてデータ移動オペレーションを自動挿入し、データフローの構築を完了します。
スケジュール情報は、TVM のネイティブ メカニズムと非常によく似ています。統合プロセスでは、各メンバー スコープのサイズを考慮する必要があるため、ここでは特別なフレームワークを使用して統合し、それを作成します。自動化されています。
これに基づいて、 do スケジュールは開発者が必要とするスケジュールを作成します。また、後処理が必要になる場合もあります。

Q2: CostModel についてさらに詳細を明らかにするのは都合がよいですか?コスト関数はオペレーターレベルの機能に基づいて設計されていますか? それともハードウェアレベルの機能の組み合わせに基づいて設計されていますか?
A1: 大きなアイデアはすでに存在します。まず、候補セットが生成され、NPL 構造に関連して、その後の最適化、マルチコア、ダブルバッファーが考慮されます。 、など、そして最後にコスト関数のペアがあります。それを並べ替えます。
最適化ルーチンの本質は、計算でデータの動きを隠すことであることはわかっています。これは、この標準に従って操作をシミュレートし、最終的にコストを計算することに他なりません。
Q3: TVM でサポートされているデフォルトの融合ルールに加えて、XIM は、計算レイヤーでさまざまなハードウェアのカスタマイズを組み合わせた独自の融合など、新しい融合ルールを生成しましたか。
A3: 融合に関しては、実際には 2 つのレベルがあり、1 つ目はバッファー、2 つ目はループ融合です。 TVM 融合アプローチは実際には後者を目的としています。 Sim は基本的に、あなたが言及した TVM 融合パターンに従いますが、いくつかの制限があります。








