Command Palette
Search for a command to run...
Feng Siyuan: Apache TVM と機械学習コンパイルの開発

この記事は、HyperAI Super Neural WeChat パブリック アカウントから最初に公開されました~
こんにちは。今日は 2023 Meet TVM にご参加ください。 Apache TVM PMCとして、TVM の開発と、TVM の将来の Unity フレームワークについてお話しします。
Apache TVM の進化
まず第一に、なぜ MLC (Machine Learning Compilation) があるのでしょうか? AI モデルが拡大し続けるにつれて、実際の本番アプリケーションではより多くの要求が発生するでしょう (図に示すように) AI アプリケーションの最初の層は、ResNet、BERT、Stable Diffusion およびその他のモデルを含む多くのアプリケーションで共有されます。

2 番目のレイヤーのシナリオは異なります。開発者は、これらのモデルをさまざまなシナリオにデプロイする必要があります。1 つ目は、GPU アクセラレーションを必要とするクラウド コンピューティングとハイ パフォーマンス コンピューティングです。 AI の分野が加速するにつれて、最も重要な課題は、それを何千もの家庭、つまり個人の PC、携帯電話、エッジ デバイスに導入することです。
ただし、シナリオが異なれば、コスト削減やパフォーマンスの向上などの要件も異なります。たとえば、ユーザーがすぐに Web ページを開いたり、アプリケーションをダウンロードしたりして、それをすぐに使用できるようにする必要があります。また、Edge は、OS なしでハードウェア上で動作する必要もあります。低電力、低コンピューティングのテクノロジーを活用します。これらは、さまざまなアプリケーションで誰もが遭遇する問題です。どのように解決すればよいでしょうか。
これについては、MLC 分野、すなわちマルチレベル IR 設計においてコンセンサスがあります。コアには 3 つの層があり、最初の層はグラフ レベル IR、中間層はテンソル レベル IR、次の層はハードウェア レベル IR です。モデルがグラフであり、中間層が Tensor レベル IR であるため、これらの層が必要です。MLC の核心は Tensor コンピューティングを最適化することです。ハードウェア レベル IR とハードウェアの下の 2 つの層は相互にバインドされています。つまり、TVM にはアセンブリ命令の直接生成が含まれません。これは、中間にさらに詳細な最適化テクニックがあり、この層はメーカーまたはコンパイラで解決するには。

ML Compiler には、設計の開始時に次の目標がありました。
- 依存関係の最小化
最初のポイントは、依存関係のデプロイメントを最小限に抑えることです。AI アプリケーションが現在実際に実用化されていないのは、まさに導入の敷居が高すぎるからです。 Stable Diffusion よりも多くの人が ChatGPT を実行しているという事実は、Stable Diffusion が十分強力ではないからではなく、ChatGPT がすぐに使用できる環境を提供しているためです。私の意見では、Stable Diffusion を使用するには、最初に GitHub からモデルをダウンロードし、それから GPU サーバーを開いてそれをデプロイする必要がありますが、ChatGPT はそのまま使用できます。そのまま使用する場合の重要なポイントは、依存関係を最小限に抑え、誰でも、すべての環境で利用できるようにすることです。
- さまざまなハードウェアのサポート
2 番目のポイントは、さまざまなハードウェアをサポートできることです。ハードウェア展開の多様化は、開発の初期段階では最も重要な問題ではありませんが、国内外の AI チップの開発に伴い、特に現在の国内環境と国内チップ企業の現状を考慮すると、ますます重要になります。それぞれを理解する必要があります。ハードウェアのサポートは非常に優れています。
- コンパイルの最適化
3 番目のポイントは、一般的なコンパイルの最適化です。IR の上位層のコンパイルを通じて、動作効率の向上、メモリ使用量の削減など、パフォーマンスを最適化できます。
現在、ほとんどの人がコンパイルと最適化が最も重要なポイントであると考えていますが、コミュニティ全体にとっては、最初の 2 つのポイントが重要です。これはコンパイラの観点からのものであり、これら 2 つのポイントはゼロから 1 へのブレークスルーであるため、多くの場合、パフォーマンスの最適化はおまけです。
講演の話に戻りますが、TVMの開発を4つの段階に分けて、あくまで個人的な見解を表します。
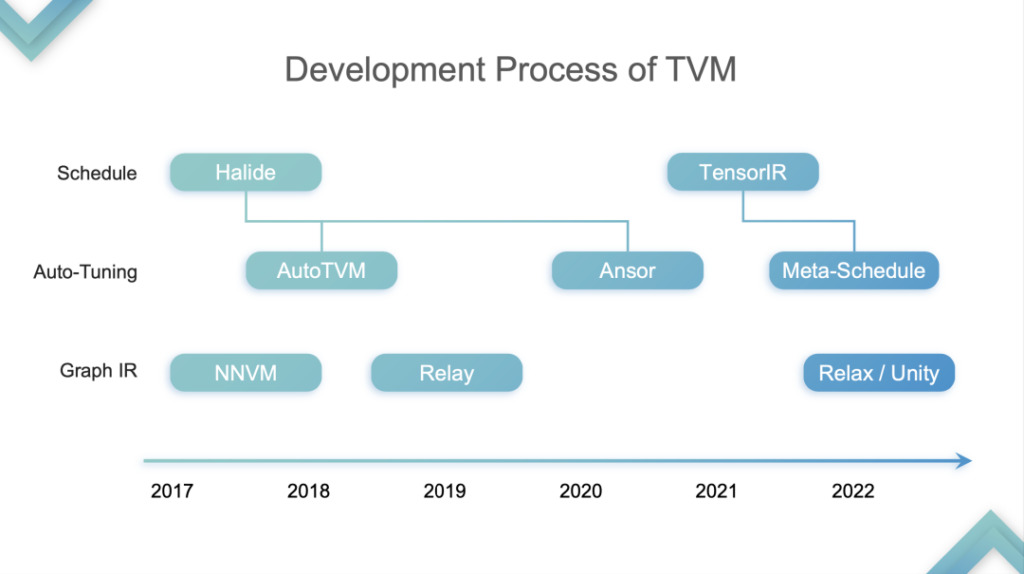
TensorIR の抽象化
ステージ 1:この段階では、TVM は CPU と GPU 上の推論を最適化し、高速化します。これは、特に SIMT のハードウェア部分を指します。この段階で、多くのクラウド コンピューティング ベンダーが TVM を使用し始めました。これは、TVM が CPU と GPU の両方を高速化できることを発見したためです。なぜ?先ほど、CPU と GPU にはテンソル化がサポートされていないと述べました。 TVM TE Schedule の第 1 世代は Halide に基づいており、適切な Tensorization Support を備えていませんでした。そのため、その後の TVM の開発は、Tensorization Support に適していなかった Auto TVM や Ansor など、Halide によって開発された技術的なルートに従いました。
まず、ハードウェアの開発プロセスを見てみましょう。CPU から GPU への移行は 2015 年から 2016 年頃で、GPU から TPU への移行は 2019 年頃でした。 Tensorization サポートを提供するために、TVM は最初に Tensorized Programs の特性を分析しました。
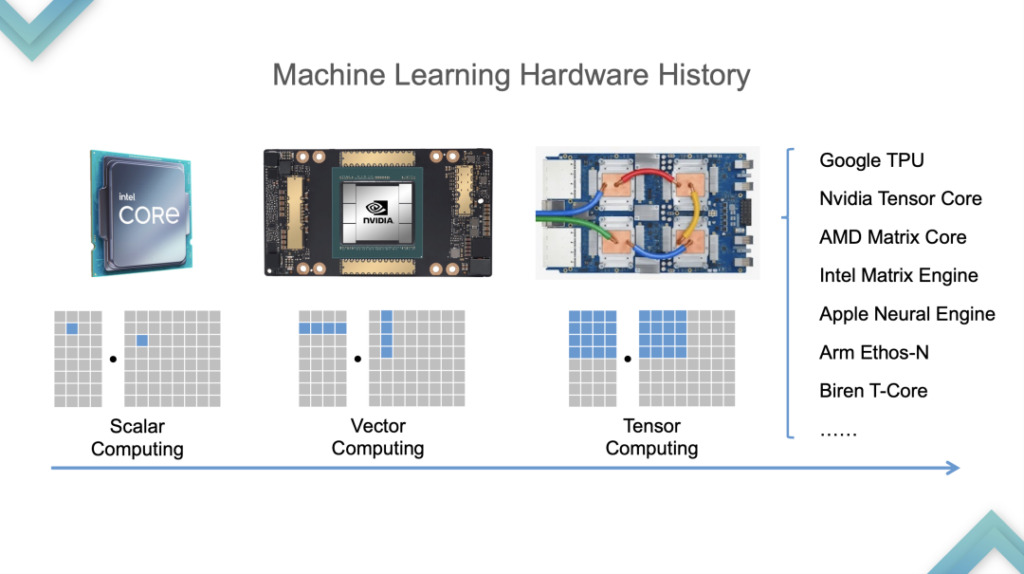
- スレッドバインディングによる最適化されたループネスト
まず、ループ テストが必要です。これは、すべてのテンソル化プログラムに必要です。これは、CMT や CPU とは異なり、スカラーではなくテンソルの単位で保存および計算されます。
- 多次元データを専用のメモリ バッファにロード/ストアする
次に、特別なメモリ バッファに保存されます。
- 不透明なテンソル化計算本体 16×16 行列乗算
第三に、コンピューティングを可能にするハードウェアのプールが存在します。次の Tensor プリミティブは、16*16 の行列乗算を計算する例として使用されます。この計算はスカラー結合の計算モードでは表現されなくなり、1 つの命令でアカウント単位に計算されます。

TVM は Tensorized Program の上記 3 点の定性分析に基づいて、Computational Block を導入しました。ブロックは、最外層にネスト、中間に反復反復子と依存関係、最下位に本体を備えた計算ユニットであり、その概念は内部計算と外部計算を分離すること、つまり内部計算テンソル化計算を分離することです。
ステージ 2:この段階で、TVM は自動テンソル化を実行します。実装方法については、例を示して詳しく説明します。

自動テンソル化
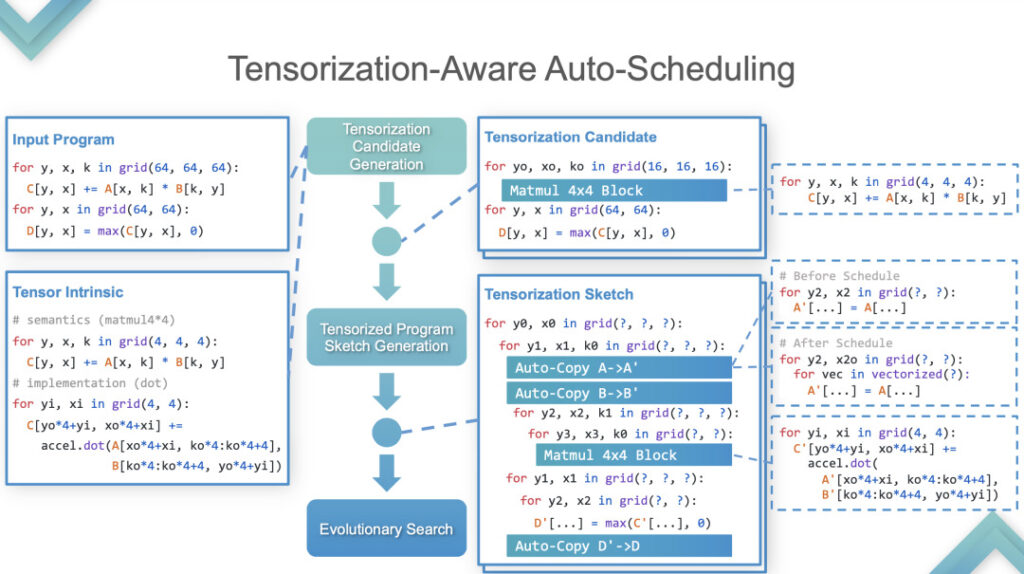
[入力プログラム] と [Tensor Intrinsic] を入力すると、結果は TensorIR と TensorRT が基本的に GPU 上で連携していることを示していますが、一部の標準モデルのパフォーマンスはあまり良くありません。標準モデルは ML Perf の標準メトリクスであるため、NVIDIA エンジニアはその作業に多くの時間を費やします。標準モデルで TensorRT よりも優れたパフォーマンスを発揮することは比較的まれであり、これは業界の最先端テクノロジーを打ち負かすことと同じです。
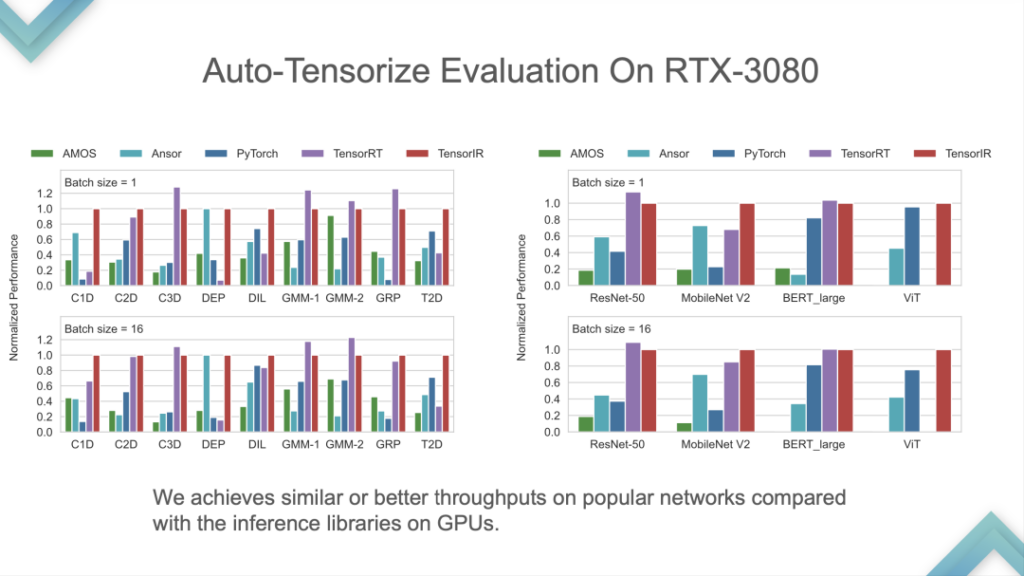
これは ARM の自社開発 CPU でのパフォーマンス比較であり、TensorIR と ArmComputeLib は Ansor と PyTorch よりもエンドツーエンドで約 2 倍高速です。最も重要なのはパフォーマンスではなく、自動テンソル化の考え方が中心です。
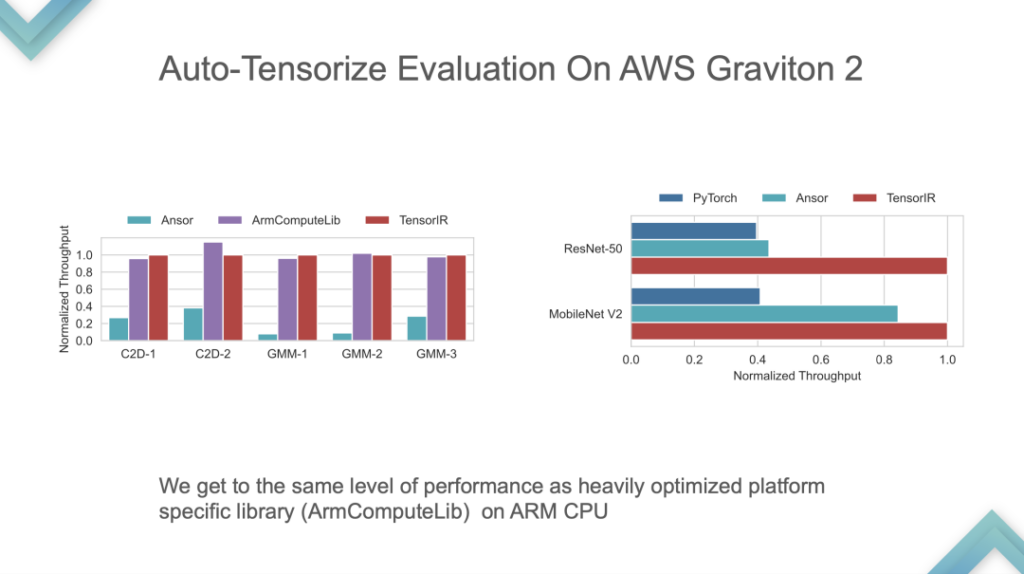
ステージ 3:テンソル化されたハードウェア用のエンドツーエンドの ML コンパイラー。この段階では、GPU またはすでにサポートされているアクセラレータ チップに投入できます。次に、自己一貫性のあるシステムである自動チューニングとモデルのインポートが行われます。現段階での TVM の中核はエンドツーエンドであり、直接使用するモデルを開発できますが、カスタマイズは非常に困難です。
次に、Relax と Unity の開発と考え方について少しゆっくり話します。理由は次のとおりです。
- 個人的には、リラックスと統一感の方が重要だと思います。
- まだ実験段階にあり、多くはアイデアにすぎず、エンドツーエンドのデモや完全なコードが不足しています。
Apache TVM スタックの制限:
- リレーとTIRの間には大きなギャップがあります。 TVM の最大の問題は、リレーから TIR へのコンパイル パラダイムが急すぎることです。
- ほとんどのハードウェアのパイプラインを修正しました。リレーからTIRまでのTVM標準プロセス?実際、コンパイル後、多くのハードウェアは BYOC のみをサポートしているか、BYOC+TIR を使用したいと考えていますが、Relay は TIR もライブラリもサポートしていません。 GPU アクセラレーションを例にとると、Relay の最下層は固定されており、自動チューニング用の CUDA を作成するか、TensorRT 用の BYOC を使用するか、サードパーティ ライブラリをチューニングするために cuBLAS を使用します。選択肢はたくさんありますが、どれか 1 つを選択するだけです。この問題は比較的大きな影響を及ぼし、Relay で解決するのは困難です。
解決策: TVM Unity。
Apache TVM Unity
IR の 2 つの層、Relax と TIR を全体として扱い、それらを Graph-TIR プログラミング パラダイムにマージします。融合の形式: 最も単純な線形モデルを例に挙げます。この場合、言語の Graph-TIR 層を使用すると、下位レベルの演算子が急峻すぎるという問題が解決されます。段階的に変更することもできます。BYOC または関数呼び出しに自分で変更することもできます。

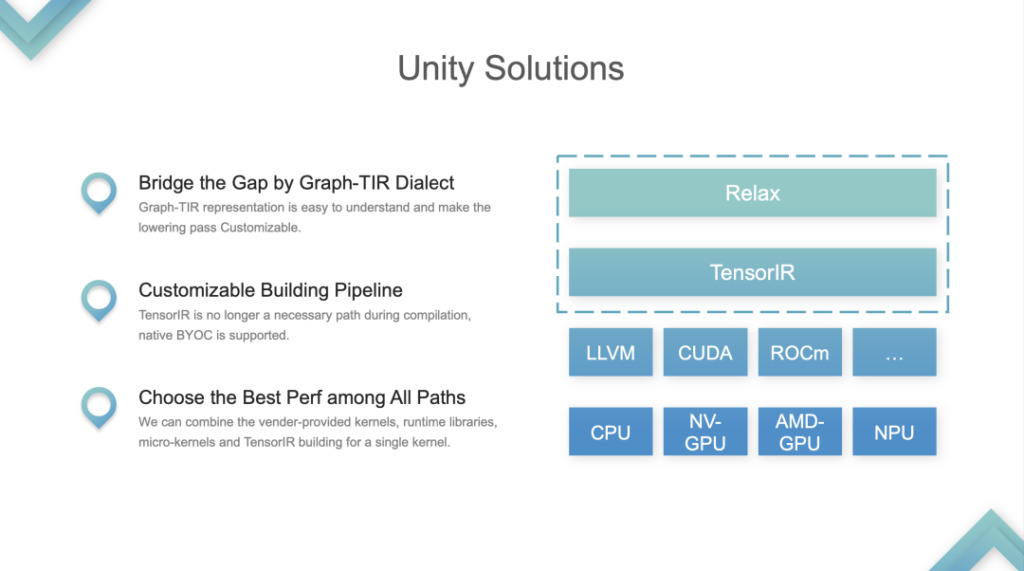
1. パイプライン構築の問題に対するカスタマイズされたソリューションをサポートします。元々、TVM パイプラインはリレーの追加 TIR であり、チューニングが完了すると、その TIR が LLVM または CUDA に渡され、パイプラインが変更されました。
2. すべてのパスの中から最高のパフォーマンスを選択します。開発者は、ライブラリまたは TIR 内のあらゆるものを調整することを選択できます。これは Unity が解決する最も重要な問題であり、コミュニティではこれが統合された ML コンパイル ソリューションであると考えられています。
誤解
- TVMとMLIRは競合関係にある
実際、TVM と MLIR には同じレベルで明確な競合関係はありません。TVM は MLC 機械学習コンパイルに重点を置いているのに対し、MLIR はマルチレベルを重視しており、その機能は ML コンパイルにも使用できます。開発者は機械学習のコンパイルに MLIR を使用します。これは、MLIR が PyTorch などのフレームワークとネイティブに統合しているため、また、Unity が登場する前は TVM のカスタマイズ機能が比較的弱かったためです。
- TVM = CPU/GPU 用の推論エンジン
TVM はこれまでにない推論エンジンであり、コンパイル可能であり、開発者は推論を高速化するために使用できます。 TVM はコンパイラのインフラストラクチャですが、「TVM は高速化のためだけに使用できる」という考えは間違っています。 TVM を使用して高速化できる本質的な理由は、Compiler が PyTorch などの Eager Mode 実行方法よりも高速であるためです。
- TVM = オートチューニング
Relax が登場する前、TVM に対する誰もが最初に感じたのは、オート チューニングによってより良いパフォーマンスが得られるということでした。 TVM の次のステップは、この概念を軽視することです。 TVM は、パフォーマンスを向上させ、コンパイル プロセス全体をカスタマイズするためのさまざまな方法を提供します。 TVM Unity が行うべきことは、さまざまな利点を組み合わせた構造を提供することです。
次のステップ
TVM の次のステップは、クロスレイヤ機械学習コンパイラ インフラストラクチャを構築し、さまざまなバックエンド向けにカスタマイズ可能な構築パイプラインとなり、さまざまなハードウェアでのカスタマイズをサポートすることです。これには、さまざまな方法を組み合わせ、各企業の強みを統合する必要があります。
Q&A
Q 1: TVM には大規模モデルを最適化する計画はありますか?
A 1: 大型モデルに関しては、いくつかの予備的なアイデアがあります。現在、TVM は分散推論といくつかの簡単なトレーニングを開始していますが、実際に実装されるまでにはしばらく時間がかかります。
Q2: 今後、Relax は Dynamic Shape に関してどのようなサポートと進化を行うことになりますか?
A 2: Relay vm は動的形状をサポートしますが、記号演繹は生成しません。たとえば、nmk の行列乗算の出力は n と m ですが、Relay の式は総称して Any と呼ばれる 3 nmk、つまり未知の次元です。その出力も未知の次元です。 Relay VM はこれらのタスクを実行できますが、コンパイル段階で一部の情報が失われるため、Relax はこれらの問題を解決します。これは Relay の Dynamic Shape に対する Relax の改良です。
Q 3: TVM 最適化とデバイス最適化の組み合わせ。 Graph を使用して命令を直接生成する場合、TE と TIR はデバイスの最適化ではあまり使用されないようです。 BYOC を使用すると、TE と TIR がスキップされるようです。共有の中で、Relax にはいくつかのカスタマイズがある可能性があることが記載されており、これによりこの問題が解決されるようです。
A 3: 実際、多くのハードウェア メーカーは TIR 方式を採用していますが、一部のメーカーは関連テクノロジに注意を払わず、依然として BYOC 方式を選択しています。 BYOC は厳密な意味でのコンパイルではなく、ビルド パターンに制限があります。要約すると、企業がコミュニティ テクノロジーを使用できないのではなく、企業がそれぞれの状況に応じて異なる選択を行っているということです。
Q 4: TVM Unity の登場により、移行コストは高くなりますか? TVM PMC の観点から、ユーザーが TVM Unity にスムーズに移行できるようにするにはどうすればよいでしょうか?
A 4: TVM コミュニティは Relay を放棄したわけではなく、Relax のオプションを追加しただけです。そのため、古いバージョンは今後も進化し続けますが、一部の新しい機能を使用するには、コードとバージョンの移行が必要になる場合があります。
Relax が完全にリリースされた後、コミュニティは、Relax への Relay モデルの直接インポートをサポートするための移行チュートリアルと特定のツールのサポートを提供します。ただし、Relay をベースに開発したカスタマイズ版を Relax に移行するには、やはりある程度の作業が必要で、社内の十数名のチームでは 1 か月程度かかります。
Q 5: TensorIR は以前に比べて大きな進歩を遂げていますが、TensorIR は主に SIMT や SIMD などの成熟したプログラミング手法向けに設計されていることに気付きました。TensorIR は多くの新しい AI チップやプログラミングで使用されています。ここ?
A 5: コミュニティの観点から見ると、TensorIR が SIMT モデルを作成する理由は、現在、多くのメーカーのハードウェアと命令セットがオープンソースではないためです。主要なメーカーがアクセスできる唯一のハードウェアは、CPU です。 GPU および一部の携帯電話 SoC は基本的に他のメーカーのコミュニティにアクセスできないため、そのプログラミング モデルに基づくことができません。また、コミュニティと企業が協力して同様のレベルの TIR を作成したとしても、商用運用の観点からオープンソースにすることはできません。
上記は、2023 Meet TVM Shanghai Stationでの馮思源氏のスピーチの要旨です。今後、このイベントの他のゲストが共有した詳細な内容もこの公開アカウントで順次公開されていく予定ですので、引き続きご注目ください。
PPT を入手:WeChat 公開アカウント「HyperAI Super Neural」をフォローし、バックグラウンドでキーワードを返信してください TVM上海、完全な PPT を入手してください。
TVM 中国語ドキュメント:https://tvm.hyper.ai/
GitHub アドレス:https://github.com/apache/tvm








