Command Palette
Search for a command to run...
「Instant Universe」を開発した AI 企業は、Stable Diffusion の開発に参加し、昨年 5,000 万米ドルの資金調達を受けました。

この記事は、HyperAI Super Neural WeChat パブリック アカウントから最初に公開されました~
北京時間3月13日午前、2023年オスカー賞授賞式がロサンゼルスで開催された。、映画『インスタント・ユニバース』が一挙に7部門を受賞し、最大の受賞者となった。主演のミシェル・ヨーも本作でアカデミー賞主演女優賞を受賞し、オスカー史上初の中国系アメリカ人女優となった。

この話題の SF 映画の視覚効果チームには 5 人しかいないことがわかっており、これらの特殊効果ショットをできるだけ早く完成させるために、緑の背景を削除するなど、特定のシーンの作成に役立つランウェイのテクノロジーを選択しました。グリーン スクリーン ツール。
「数回クリックするだけで数時間を節約でき、その時間を使ってビデオをより良くするために 3 つまたは 4 つの異なるエフェクトを試すことができました。」と監督兼脚本家のエヴァン・ハレックはインタビューで述べています。

滑走路: 第 1 世代の Stable Diffusion の開発に参加
2018年末、クリストバル・バレンズエラらはランウェイを設立した。同社は、コンピューター グラフィックスと機械学習の最新の進歩を活用して、デザイナー、アーティスト、開発者のコンテンツ作成の敷居を下げ、クリエイティブなコンテンツの開発を促進することに注力している人工知能ビデオ編集ソフトウェア プロバイダーです。

従業員はわずか40名ほど
その上、Runway には、Stable Diffusion の初期バージョンに関与した大手企業としてのあまり知られていないアイデンティティもあります。
2021年、Runwayはドイツのミュンヘン大学と協力してStable Diffusionの最初のバージョンを構築し、その後、英国のスタートアップStability AIがStable Diffusionにモデルトレーニングに必要なコンピューティングリソースと資金を提供するために「資本をグループに導入」した。ただし、Runway AI と Stability AI は連携しなくなりました。
2022年12月、ランウェイはシリーズCで5,000万米ドルの資金調達を受け、「インスタント・ユニバース」チームに加え、メディアグループのCBSとMBC、広告会社のAssemblyとVaynerMedia、デザイン会社のPentagramなどが顧客に名を連ねた。
2023年2月6日、ランウェイ公式TwitterにてGen-1モデルがリリースされました。テキストヒントや参照画像で指定されたスタイルを適用することで、既存のビデオを新しいビデオに変換できます。
Gen-1: 構造 + コンテンツの 2 つのアプローチ
研究者らは、予想される出力の視覚的またはテキストによる説明に基づいてビデオを編集できる、構造とコンテンツに基づいたビデオ普及モデル Gen-1 を提案しました。
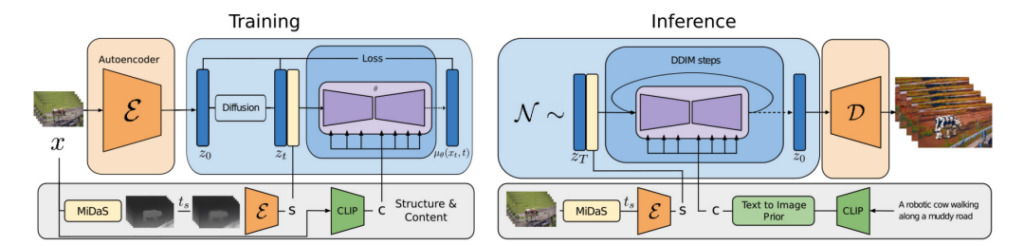
いわゆるコンテンツとは、ターゲット オブジェクトの色やスタイル、シーンの照明など、ビデオを説明する外観および意味論的な特徴を指します。
構造とは、対象物の形状、位置、時間変化などの幾何学的および動的特性を記述することを指します。
Gen-1 モデルの目標は、ビデオ構造を保持しながらビデオ コンテンツを編集することです。
モデルのトレーニング プロセス中、研究者らは、字幕なしのビデオとテキストと画像のペアで構成される大規模なデータ セットを使用しました。同時に、単眼シーンの奥行き推定値を使用して構造を表現し、事前トレーニングされたニューラル ネットワークを使用しました。ネットワークはコンテンツを表すために埋め込みを予測します。
この方法では、生成プロセス中にいくつかの強力な制御モードが提供されます。
1. 画像合成モデルを参照して、推定されたビデオ コンテンツ (プレゼンテーションやスタイルなど) とユーザーが提供した画像またはプロンプトを照合するようにモデルをトレーニングします。

2. 拡散プロセスを参照すると、構造表現に対して情報の隠蔽が実行されます。これにより、開発者は、特定の構造に従うモデルの類似度を設定できます。
3. 分類子を使用しないガイダンスを参照し、カスタム ガイダンス方法を使用して推論プロセスを調整し、生成されたクリップの時間の一貫性を制御します。
この実験では、研究者は次のことを行いました。
- 事前トレーニングされた画像モデルに時間層を導入し、画像とビデオを共同でトレーニングすることにより、潜在拡散モデルはビデオ生成まで拡張されます。
- サンプル画像やテキストに基づいてビデオを変更できる、構造とコンテンツを認識したモデルが提案されています。ビデオ編集は完全に推論フェーズで行われ、ビデオごとのトレーニングや前処理は必要ありません。
- 時間、内容、構造の一貫性を完全に制御します。実験により、画像データとビデオデータの共同トレーニングにより、推論中の時間的一貫性を制御できることが示されました。構造の一貫性を保つために、表現のさまざまな詳細レベルでトレーニングすることで、ユーザーは推論中に必要な設定を選択できるようになります。
- ユーザー調査によると、この方法が他のいくつかの方法よりも人気があることがわかりました。
- 少数の画像セットを微調整することで、トレーニングされたモデルをさらにカスタマイズして、より正確な主題固有のビデオを生成できます。
Gen-1 のパフォーマンスを評価するために、研究者らは DAVIS データセットのビデオやその他のさまざまな評価資料を使用しました。編集プロンプトを自動的に作成するために、研究者らはまずキャプション モデルを実行して元のビデオ コンテンツの説明を取得し、次に GPT3 を使用して編集プロンプトを生成しました。
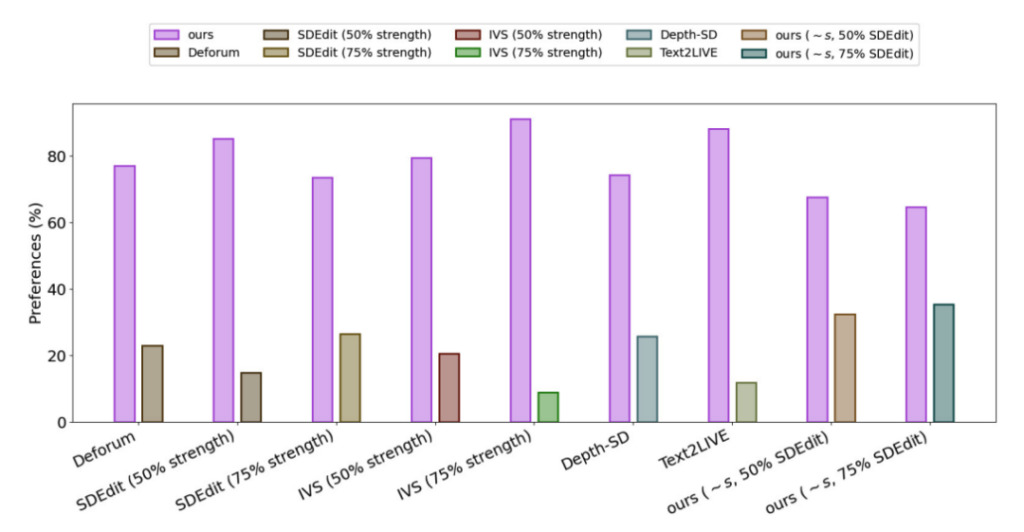
実験結果によると、すべての方法の発電効果に関する満足度調査では、75% ユーザーは Gen-1 世代のエフェクトを好みます。
AIGC: 論争の中で前進
2022 年、生成人工知能は 10 年以上前のモバイルとクラウド コンピューティングの台頭以来、最も魅力的なテクノロジーとなっており、私たちは幸運にもそのアプリケーション層の出現を目の当たりにしています。多くの大規模なモデルが研究室から現実世界のシナリオに急速に登場しています。
しかし、効率の向上やコスト削減など多くの利点があるにもかかわらず、生成人工知能はモデルの出力品質と多様性を向上させる方法、生成速度を向上させる方法、生成方法など、依然としてさまざまな課題に直面していることも認識する必要があります。セキュリティ、プライバシー、倫理、宗教などの問題を改善するため。
AI による芸術作品の創造に疑問を抱く人もいますし、AI による芸術への「侵略」であるとさえ考える人もいます。このような声に直面して、Runway の共同創設者兼 CEO であるクリストバル・バレンズエラ氏は、AI はツールボックスの中のツールにすぎないと考えています。画像やその他のコンテンツに色を付けたり変更したりするためのツールは、Photoshop や LightRoom と何ら変わりません。生成型人工知能はまだ多少の議論の余地がありますが、技術者ではない人々や創造的な人々に創作への扉を開き、コンテンツ制作の分野を新たな可能性に導くでしょう。
参考リンク:
[1]https://hub.baai.ac.cn/view/23940
[2]https://cloud.tencent.com/developer/article/2227337?








