Command Palette
Search for a command to run...
Animated Drawings APP を例として、TorchServe を使用したモデルのチューニング
内容紹介 前のセクションでは、TorchServe モデルのデプロイメントと、モデルを運用環境にデプロイするためのチューニングの 5 つのステップを紹介しました。このセクションでは、アニメーション描画アプリを例として、TorchServe のモデル最適化効果を実際に示します。 この記事は最初に WeChat 公開アカウントから公開されました。PyTorch 開発者コミュニティ
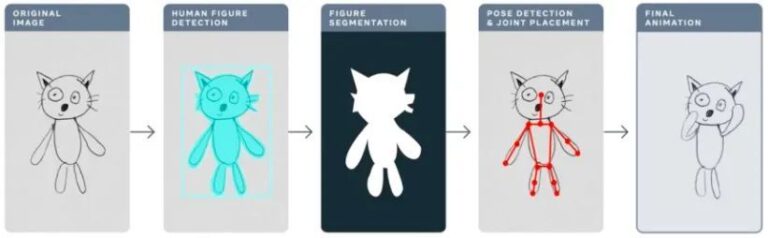
昨年、Meta は Animated Drawings アプリケーションを使用して、AI を使用して子供の手描きを「アニメーション」にし、静的な単純な描画を数秒でアニメーションに変換しました。


アニメーション図面sketch.metademolab.com/
AIにとってこれは簡単ではありません。 AI は本来、現実世界の画像を処理するために設計されており、実際の画像と比較すると、子供の絵はより複雑で予測不可能であるため、類似のタスクの処理には適していない可能性があります。
この記事では、アニメーション描画を例として、TorchServe を使用して実稼働環境にデプロイされるモデルを調整する方法を詳しく説明します。
実稼働環境でのモデルのチューニングに影響を与える 4 つの主な要因
次のワークフローは、TorchServe を使用して実稼働環境にモデルをデプロイする一般的なアイデアを示しています。

ほとんどの場合、実稼働環境へのモデルのデプロイは、スループットまたはレイテンシーのサービス レベル アグリーメント (SLA) に基づいて最適化されます。
通常、リアルタイム アプリケーションは遅延をより重視し、オフライン アプリケーションはスループットをより重視します。
実稼働環境にデプロイされたモデルの場合、パフォーマンスに影響を与える多くの要因がこの記事では次の 4 つに焦点を当てています。
1. モデルの最適化
これはモデルを運用環境にデプロイするための前段階であり、量子化、プルーニング、IR グラフ (PyTorch の TorchScript) の使用、フュージョン カーネル、およびその他の多くのテクニックが含まれます。現在、多くの同様のテクノロジーが、TorchPrep の CLI ツールとして利用可能です。
2.バッチ推論
これは、モデルに複数の入力を入力することを指し、トレーニング プロセス中に頻繁に使用され、推論段階でのコストの制御にも非常に役立ちます。
ハードウェア アクセラレータは並列処理用に最適化されており、バッチ処理によりコンピューティング能力を最大限に活用できるため、多くの場合、スループットが向上します。推論の主な違いは、あまり長く待たずにクライアントからバッチを取得できることです。これは、私たちがよく動的バッチ処理と呼ぶものです。
3. 従業員数
TorchServe はワーカーを通じてモデルをデプロイします。 TorchServe のワーカーは Python プロセスに属しており、推論に使用されるモデルの重みのコピーを持っています。ワーカーが少なすぎると、十分な並列処理によるメリットが得られません。ワーカーが多すぎると、ワーカーの競合が発生し、エンドツーエンドのパフォーマンスが低下します。
4.ハードウェア
モデル、アプリケーション、レイテンシーとスループットの予算に基づいて、TorchServe、CPU、GPU、AWS Inferentia から適切なハードウェアを選択します。
ハードウェア構成には、クラス最高のパフォーマンスを実現するためのものと、予想されるコスト管理をより適切に満たすためのものがあります。実験によると、バッチ サイズが大きい場合は GPU が適しており、バッチ サイズが小さい場合、または低レイテンシが必要な場合は CPU と AWS Inferentia の方がコスト効率が高いことが示されています。
ヒントの共有:TorchServe のパフォーマンス調整に関するメモ
始める前に、まず、TorchServe を使用してモデルをデプロイし、最高のパフォーマンスを実現するためのヒントをいくつか共有しましょう。
ハードウェアの選択とモデル最適化の選択も密接に関連しています。
* モデル展開のためのハードウェアの選択は、レイテンシー、スループットの期待値、推論あたりのコストと密接に関係しています。
モデル サイズとアプリケーションの違いにより、CPU 実稼働環境では、同様のコンピューター ビジョン モデルを展開する余裕がないことがよくあります。OpenBayes.com を使用するために登録すると、登録時に 3 時間の RTX3090 が無料で提供され、一般的な GPU のニーズを満たすために毎週 10 時間の RTX3090 が無料で提供されます。
さらに、TorchServe に最近追加された IPEX などの最適化により、そのようなモデルの導入がより安価になり、より CPU に優しいものになります。
IPEX 最適化モデルの導入の詳細については、を参照してください。
* TorchServe のワーカーは Python プロセスに属します。並列処理を提供できます。ワーカーの数は慎重に設定する必要があります。デフォルトでは、TorchServe はホスト上の VCPU または利用可能な GPU の数と同じ数のワーカーを開始するため、TorchServe の起動にかなりの時間がかかる場合があります。
TorchServe は、ワーカーの数を設定するための構成プロパティを公開します。複数のワーカーが効率的な並列処理を提供し、リソースの競合を回避できるようにするには、CPU と GPU に次のベースラインを設定することをお勧めします。
CPU:ハンドラーに設定 torch.set_num_thread(1) 。次に、ワーカーの数を次のように設定します。 物理コア数 / 2 。ただし、Intel CPU ランチャー スクリプトを利用すると、最適なスレッド構成を実現できます。
GPU:利用可能な GPU の数は config.properties で決定できます。 数値_gpus 設定を行います。 TorchServe はラウンドロビンを使用してワーカーを GPU に割り当てます。提案:ワーカーの数 = (利用可能な GPU の数) / (固有のモデルの数)。プリアンペア GPU は、マルチ インスタンス GPU からのリソース分離を提供しないことに注意してください。
* バッチ サイズは、レイテンシとスループットに直接影響します。コンピューティング リソースをより有効に活用するには、バッチ サイズを増やす必要があります。レイテンシとスループットの間にはトレードオフがあり、バッチ サイズを大きくするとスループットは向上しますが、レイテンシも高くなります。
TorchServe でバッチ サイズを設定するには 2 つの方法があります。1 つは config.properties のモデル設定を使用する方法、もう 1 つは管理 API を使用してモデルを登録する方法です。
次のセクションでは、TorchServe のベンチマーク スイートを使用して、モデルの最適化におけるハードウェア、ワーカー、バッチ サイズの最適な組み合わせを決定する方法を示します。
トーチサーブ ベンチマーク スイートのご紹介
TorchServe ベンチマーク スイートを使用するには、まず、上で説明したアーカイブ ファイルが必要です。 .mar 書類。このファイルには、推論のロードと実行に使用されるモデル、ハンドラー、その他すべてのアーティファクトが含まれています。アニメーション描画アプリは、Detectron2 の Mask-rCNN ターゲット検出モデルを使用します
ベンチマークスイートを実行する
TorchServe の自動ベンチマーク スイートは、異なるバッチ サイズとワーカー設定で複数のモデルをベンチマークし、レポートを出力できます。
学ぶ 自動ベンチマークスイート
実行を開始します:
git clone https://github.com/pytorch/serve.git cdserve/benchmarks pip install -rrequirements-ab.txt apt-get install apache2-utils
yaml ファイルでモデル レベルの設定を構成します。
Model_name:eager_mode: benchmark_engine: "ab" url: ".mar ファイルへのパス" ワーカー: - 1 - 4 バッチ遅延: 100 バッチサイズ: - 1 - 2 - 4 - 8 リクエスト: 10000 同時実行数: 10 入力: "モデル入力へのパス" backend_profiling: False exec_env: "ローカル" プロセッサ: - "cpu" - "gpus": "all"
この yaml ファイルは次のようになります。 benchmark_config_template.yaml 引用。 Yaml ファイルにはレポートを生成するための追加設定が含まれており、ログは AWS クラウドを使用して表示することもできます。
python benchmarks/auto_benchmark.py --input benchmark_config_template.yaml
ベンチマークを実行すると、結果が CSV ファイルに保存されます。このファイルは次の場所にあります。 _/tmp/benchmark/ab_report.csv_ または完全なレポート /tmp/ts_benchmark/report.md で見つかりました。
結果には、TorchServe の平均レイテンシー、モデル P99 レイテンシー、スループット、同時実行性、リクエスト数、ハンドラー時間、その他のメトリクスが含まれます。
モデルのチューニングに影響を与える次の要素の追跡に重点を置きます: 同時実行性、モデル P99 レイテンシー、およびスループット。
これらの数値は、バッチ サイズ、使用する機器、作業者の数、モデルの最適化が行われたかどうかと組み合わせて考慮する必要があります。
このモデルのレイテンシー SLA は 100 ミリ秒に設定されています。これはリアルタイム アプリケーションであり、レイテンシーは非常に重要な問題であり、スループットはレイテンシー SLA に違反しない範囲でできるだけ高いことが最適です。
サーチ スペースを通じて、さまざまなバッチ サイズ (1 ~ 32)、ワーカー数 (1 ~ 16)、デバイス (CPU、GPU) で一連の実験が実行され、表に示すように最良の実験結果がまとめられました。下に:

CPU レイテンシ、バッチ サイズ、同時実行性、ワーカー数に関するこのモデルの試みは SLA を満たしておらず、レイテンシは実際に 13 分の 1 に短縮されました。
モデルのデプロイメントを GPU に移動すると、レイテンシが 305 ミリ秒から 23.6 ミリ秒に即座に短縮されます。
モデルに対して実行できる最も簡単な最適化の 1 つは、1 行のコードで精度を fp16 に下げることです。 (モデルの半分()) 、32% のモデル P99 レイテンシーを削減し、ほぼ同じ量だけスループットを向上させることができます。
モデルの最適化方法には、モデルを TorchScript に変換して使用することも含まれます。 推論のための最適化 または、アグレッシブな融合を利用する他の技術 (onnx または tensor ランタイム最適化を含む)。
CPUとGPUで設定します。 ワーカー数=1 この記事の場合、これが最適に機能します。
*モデルをGPUにデプロイして設定 従業員の数 = 1、 バッチサイズ = 1、CPU と比較してスループットが 12 倍向上し、レイテンシが 13 倍削減されます。
*モデルをGPUにデプロイして設定 モデル.half()、 従業員の数 = 1 、 バッチサイズ = 8、スループットと手頃な遅延の点で最高の結果が得られます。 CPU と比較して、スループットは 25 倍向上し、レイテンシーは依然として SLA (94.4 ミリ秒) を満たしています。
注: ベンチマーク スイートを実行している場合は、適切な設定を行ってください。 バッチ遅延、リクエストの同時実行数をバッチ サイズに比例した数に設定します。ここでの同時実行とは、サーバーに送信される同時リクエストの数を指します。
要約する
この記事では、実稼働環境でモデルをチューニングする際の TorchServe の考慮事項と、パフォーマンス最適化手法である TorchServe ベンチマーク スイートを紹介し、ユーザーがモデルの最適化、ハードウェアの選択、および全体的なコストの可能な選択肢についてより深く理解できるようにします。
焦点を当てる PyTorch 開発者コミュニティPyTorch テクノロジーの最新情報、ベスト プラクティス、関連情報をさらに入手できる公式アカウントです。








