Command Palette
Search for a command to run...
絶対に! OpenAI は、1 枚のカードで 3D 点群を 1 分で生成できる新モデルを発表し、高いコンピューティング電力消費の時代に別れを告げます。
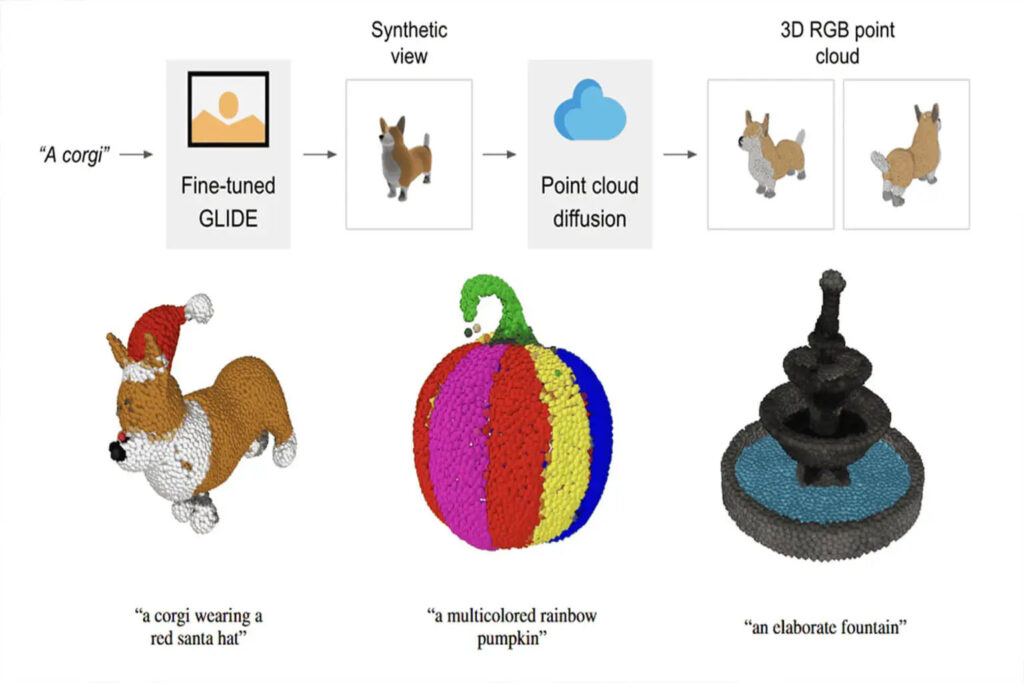
内容の概要:DALL-E と ChatGPT に続いて、OpenAI は別の取り組みを行っており、テキスト プロンプトに基づいて 3D 点群を直接生成できる Point·E を最近リリースしました。 キーワード:OpenAI 3D点群Point・E
OpenAI は年末に向けて成果を上げることを急いでいますが、半月以上前にリリースされた ChatGPT をまだ理解していない人が最近、3D を直接生成できる別の強力なツール Point・E をリリースしました。テキストプロンプトに基づく点群。
text-to-3D: 適切な方法を使用します。一方が他方よりも優れています。
3D モデリングは誰もが知っているはずですが、近年、映画制作、ビデオゲーム、工業デザイン、VR や AR などの分野で 3D モデリングの影が見られます。
ただし、人工知能の助けを借りてリアルな 3D 画像を作成するのは、依然として時間と労力がかかるプロセスです。Google DreamFusion を例に挙げると、指定されたテキストから 3D 画像を生成するには、通常複数の GPU が必要で、実行には数時間かかります。

一般に、テキストから 3D への合成方法は 2 つのカテゴリに分類されます。
方法 1:ペア (テキスト、3D) データまたはラベルのない 3D データに対して生成モデルを直接トレーニングします。
このような方法では、既存の生成モデル方法を利用してサンプルを効果的に生成できますが、大規模な 3D データ セットが不足しているため、複雑なテキスト プロンプトに拡張するのは困難です。
方法 2:事前トレーニングされたテキストから画像へのモデルを活用して、識別可能な 3D 表現を最適化します。
このような方法では、多くの場合、複雑で多様なテキスト プロンプトを処理できますが、サンプルごとの最適化プロセスにはコストがかかります。さらに、強力な 3D 事前情報が欠如しているため、このような方法は極小値 (意味のあるまたは一貫した 3D オブジェクトと 1 対 1 で対応できない) に陥る可能性があります。
Point・E はテキストから画像へのモデルと画像から 3D モデルを組み合わせます。上記 2 つの方法の利点を組み合わせると、3D モデリングの効率がさらに向上します。テキストの 3D 点群への変換には 1 つの GPU と 1 ~ 2 分しかかかりません。
原理分析: 3D 点群を生成する 3 つのステップ
Point·E では、テキストから画像へのモデルは大規模なコーパス (テキスト、画像のペア) を利用するため、複雑なテキスト プロンプトを適切に処理できます。画像から 3D へのモデルはより小さなデータ セットに基づいています (画像、3D ペア)。
Point·E を使用してテキスト プロンプトに基づいて 3D 点群を生成するプロセスは、次の 3 つのステップに分かれています。
1. テキスト プロンプトに基づいて合成ビューを生成する
2. 合成ビューに基づいて、粗い点群(1024 点)を生成します
3. 低解像度の点群と合成ビューに基づいて、微細な点群(4096 ポイント)を生成します

データ形式とデータ品質はトレーニング結果に大きな影響を与えるため、Point・E は Blender を使用して、すべてのトレーニング データを共通形式に変換します。
Blender はさまざまな 3D フォーマットをサポートし、最適化されたレンダリング エンジンを搭載しています。 Blender スクリプトは、モデルを境界立方体に統合し、標準の照明設定を構成し、最後に Blender の組み込みリアルタイム レンダリング エンジンを使用して RGBAD 画像をエクスポートします。
""" 3D モデルを RGBAD 画像としてレンダリングするために Blender 内で実行するスクリプト。使用例 Blender -b -P Blender_script.py -- \ --input_path ../../examples/example_data/corgi.ply \ --output_path render_out CLIP R-Precision 結果の計算に使用されるレンダリングに「--camera_pose z-circular-elevated」を渡します。出力ディレクトリには、レンダリングされた各ビューのメタデータ json ファイルと、各イメージのグローバル メタデータ ファイルが含まれます。ビュー「」の完全なグレースケール レンダリングと同様に、各チャネル (rgbad) の 16 ビット PNG ファイルのコレクションとして保存されます。
Blender スクリプトのパーツコード
スクリプトを実行すると、3D モデルが均一に RGBAD 画像にレンダリングされます。
完全なスクリプトについては、以下を参照してください。
過去のテキストと 3D AI の水平比較
過去 2 年間、テキストから 3D モデルの生成に関する多くの関連研究が行われてきました。GoogleやNVIDIAなどの大手メーカーも独自のAIを発売している。
違いを水平方向に比較できるように、テキストから 3D への合成 AI を 3 つ集めてまとめました。
ドリームフィールズ
発行機関:グーグル
発売時期:2021年12月
プロジェクトアドレス:https://ajayj.com/dreamfields
DreamFields は、ニューラル レンダリングとマルチモーダルな画像およびテキスト表現を組み合わせます。テキストの説明のみに基づいて、3D の監視なしでさまざまな 3D オブジェクトの形状と色を生成できます。

DreamFields で 3D オブジェクトを生成するプロセス中に、大規模なテキスト画像データセットで事前トレーニングされた画像テキストモデルを利用し、複数の視点から導き出されたニューラル放射フィールドを最適化します。これにより、事前トレーニングされた CLIP モデルによってレンダリングされた画像がターゲット テキストの下で良好な結果を達成できるようになります。
ドリームフュージョン
発行機関:グーグル
発売時期:2022年9月
プロジェクトアドレス:https://dreamfusion3d.github.io/
DreamFusion は、事前トレーニングされた 2D テキストから画像への拡散モデルを利用して、テキストから 3D への合成を実装できます。
DreamFusion では確率密度蒸留に基づく損失が導入され、2D 拡散モデルをパラメトリック画像ジェネレーターの最適化の優先順位として使用できるようになります。

この損失を DeepDream と同様のプログラムに適用することで、Dreamfusion はランダムに初期化された 3D モデル (Neural Radiance Field または NeRF) を最適化し、勾配降下法によるランダムな角度からの 2D レンダリングによる比較的低い損失を実現します。
Dreamfusion は 3D トレーニング データを必要とせず、画像拡散モデルを変更する必要もありません。事前学習済み画像拡散モデルの優先順位としての有効性が実証されています。
マジック3D
発行機関:エヌビディア
発売時期:2022年11月
プロジェクトアドレス:deepimagination.cc/Magic3D/
Magic3D は、高品質の 3D メッシュ モデルの作成に使用できる、テキストから 3D へのコンテンツ作成ツールです。Magic3D は、画像調整テクノロジーとテキスト プロンプト ベースの編集方法を使用して、3D 構成を制御する新しい方法を提供し、さまざまなクリエイティブ アプリケーションに新しい道を開きます。
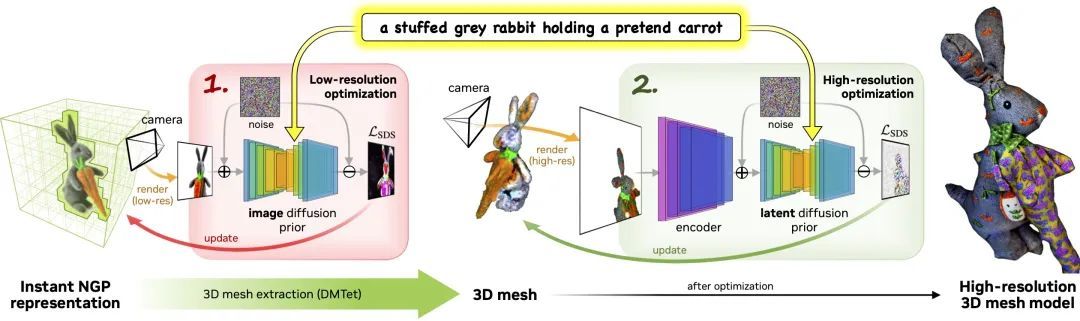
このプロセスは 2 つの段階で構成されます。
ステージ 1:粗いモデルを取得する前に低解像度の拡散を使用し、加速にはハッシュ グリッドとスパース アクセラレーション構造を使用します。
ステージ 2:粗いニューラル表現から初期化されたテクスチャ メッシュ モデルを使用し、高解像度の潜在拡散モデルと相互作用する効率的な微分可能レンダラーを通じて最適化します。
技術の進歩には限界を突破する必要がある
Text-to-3D AI は徐々に利用可能になってきていますが、テキストベースの 3D 合成はまだ開発の初期段階にあります。関連タスクをより公平に評価するために使用できる、業界で認められたベンチマークはありません。
Point・E はテキストから 3D への高速合成にとって非常に重要です。処理効率が大幅に向上し、コンピューティングの消費電力が削減されます。
しかし、それは否定できません、Point・E にはまだ一定の制限がありますが、たとえば、パイプラインには合成レンダリングが必要ですが、生成された 3D 点群の解像度は低いため、きめの細かい形状やテクスチャをキャプチャするには不十分です。
テキストと 3D の合成の将来についてはどう思いますか?今後の開発動向はどうなるでしょうか?ディスカッションのためにコメント領域にメッセージを残していただければ幸いです。








