Command Palette
Search for a command to run...
TorchX と Ax の統合: より効率的な多目的ニューラル アーキテクチャ検索

NAS の目的は、ニューラル ネットワークに最適なアーキテクチャを発見することです。 Torch と Axe の統合により、ニューラル アーキテクチャ研究の多目的探索が支援されます。この記事では、多目的ベイジアン NAS を使用して完全に自動化されたニューラル アーキテクチャ検索を実行する方法を説明します。
Ax の多目的最適化 (多目的最適化) はニューラル アーキテクチャの検索を効果的に探索できます (ニューラルアーキテクチャ検索) トレード・オフ 、モデルのパフォーマンスとモデルのサイズまたはレイテンシの間のトレードオフなど。
この手法は、オンデバイス AI など、Meta Company のさまざまな製品で使用されて成功しています。
この記事では、TorchX の使用に役立つエンドツーエンドのチュートリアルを提供します。
斧の紹介
ニューラル ネットワークのサイズと複雑さは増大し続けています。最先端のアーキテクチャの開発は、多くの場合、その分野の専門知識と多大なエンジニアリング努力を必要とする、退屈で時間のかかるプロセスです。
これらの課題を克服するために、いくつかのニューラル アーキテクチャ検索 (NAS) 手法が提案されています。人間の監視を必要とせずに、パフォーマンスの高いアーキテクチャを自動的に設計する (Human in the Loop、HITL)。
サンプル効率が低いにもかかわらず、しかし、ハイパーパラメータの最適化や NAS では、ランダム検索やグリッド検索などの単純な手法が依然として人気があります。 NeurIPS 2019 および ICLR 2020 で実施された調査によると、80% の NeurIPS 論文と 88% の ICLR 論文では、ML モデルのハイパーパラメータを調整するために手動チューニング、ランダム検索、またはグリッド検索が使用されていることがわかりました。
モデルのトレーニングには時間がかかり、大量のコンピューティング リソースが必要になる場合があるため、したがって、評価される構成の数を最小限に抑えることが非常に重要です。
Ax はブラックボックス最適化のための一般的なツールであり、ユーザーはベイジアン最適化などの最先端のアルゴリズムを使用して、大規模な検索空間を探索する際にサンプル効率を達成できます。
メタはさまざまな分野でアックスを使用し、ハイパーパラメータ調整、NAS、大規模な A/B テストによる最適な製品設定の特定、インフラストラクチャの最適化、最先端の AR/VR ハードウェアの設計などの領域が含まれます。
多くの NAS アプリケーションでは、複数の関心の指標間には自然なトレードオフが存在します。たとえば、モデルをデバイスにデプロイする場合、デプロイメントの制約を満たすために、消費電力、推論遅延、モデル サイズなどの競合する指標を最小限に抑えながら、モデルのパフォーマンス (精度など) を最大化したいと考えるでしょう。
多くの場合、計算要件や予測レイテンシーの大幅な削減 (場合によっては、精度の向上とレイテンシの短縮の両方) と引き換えに、モデルのパフォーマンスがわずかに低下することは許容されます。
Sustainble AI を実現する鍵となるのは、このトレードオフの影響を効率的に調査するための原則に基づいたアプローチです。
Meta は、Ax の多目的ベイジアン NAS を使用して、このトレードオフを調査することに成功しました。そして、この方法はすでに AR/VR デバイス上の ML モデルを最適化するために日常的に使用されています。
NAS アプリケーションに加えて、Meta は AR 光学システムの高次元の多目的最適化に使用できる手法である MORBO も開発しました。
Ax の多目的ベイジアン NAS:
Ax を使用して完全自動マルチターゲット Nas を実装する
Axe のスケジューラを使用すると、閉ループ方式で非同期に実験を実行できます。このアプローチは、実験を外部システムに継続的にデプロイし、結果をポーリングし、取得したデータを使用してさらに実験を生成し、停止条件が満たされるまでこのプロセスを繰り返すことです。人間の介入や監視は必要ありません。このスケジューラーの特徴は次のとおりです。
- カスタマイズ可能な並列処理、フォールト トレランス、その他の多くの設定。
- 最先端の最適化アルゴリズムを多数取り揃えています。
- 進行中の実験 (SQL DB または json) を保存し、ストレージから実験を復元します。
- 新しいバックエンドに簡単に拡張して実験評価をリモートで実行できます。
Ax スケジューラ チュートリアルの次の図は、スケジューラが実験評価の実行に使用される外部システムとどのように対話するかをまとめたものです。
Axe スケジューラのチュートリアル:
https://ax.dev/tutorials/scheduler.html
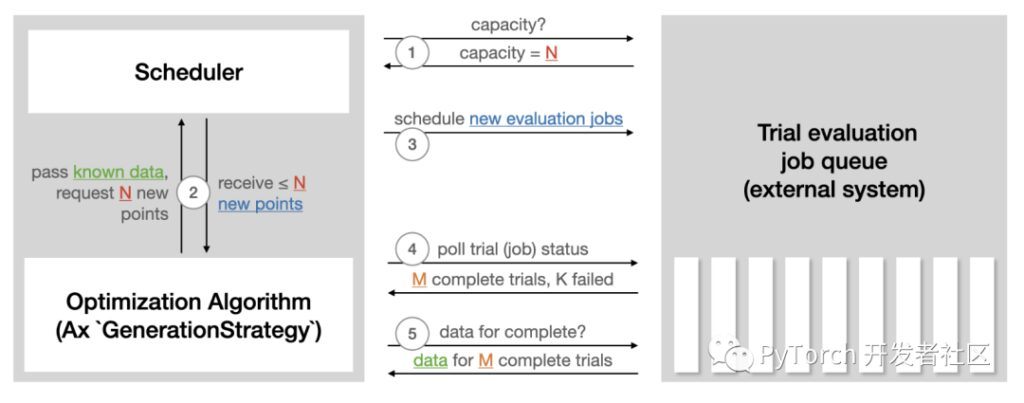
スケジューラを使用して自動 NAS を実行するには、次の準備が必要です。
- ランナーを定義し、選択したプラットフォームでのトレーニング用に、特定のアーキテクチャを備えたモデルを送信する責任を負います。 (たとえば、Kubernetes、または単にローカルの Docker イメージなど)。次のチュートリアルでは、TorchX を使用してトレーニング ジョブのデプロイメントを処理します。
- メトリクスを定義し、トレーニング タスクから客観的な指標 (精度、モデル サイズ、レイテンシなど) を取得する責任を負います。次のチュートリアルでは Tensorboard を使用してデータを記録するため、Ax にバンドルされている Tensorboard メトリクスを使用できます。
チュートリアル
このチュートリアルでは、Ax を使用して、人気のある MNIST データセットで単純なニューラル ネットワーク モデルの多目的 NAS を実行する方法を示します。
基本的な方法論はより複雑なモデルや大規模なデータ セットでも使用できますが、ラップトップで簡単に実行でき、エンドツーエンドで 1 時間以内に完了できるチュートリアルが選択されています。
この例では、2 つの隠れ層の幅、学習率、ドロップアウト確率、バッチ サイズ、トレーニング反復数が調整されます。目標は、多目的ベイジアン最適化を使用してパフォーマンスをトレードオフすることです。(検証セットの精度) とモデル サイズ (モデル パラメーターの数)。
このチュートリアルでは、次の PyTorch ライブラリを使用します。
- PyTorch Lightnig (モデルとトレーニング ループの指定用)
https://github.com/Lightning-AI/lightning
- TorchX (トレーニング ジョブをリモート/非同期で実行するため)
https://github.com/pytorch/torchx
- BoTorch (Ax のアルゴリズムを強化するベイジアン最適化ライブラリ)
https://github.com/pytorch/botorch
完全な実行可能な例については、以下を参照してください。
https://pytorch.org/tutorials/intermediate/ax_multiobjective_nas_tutorial.html
結果
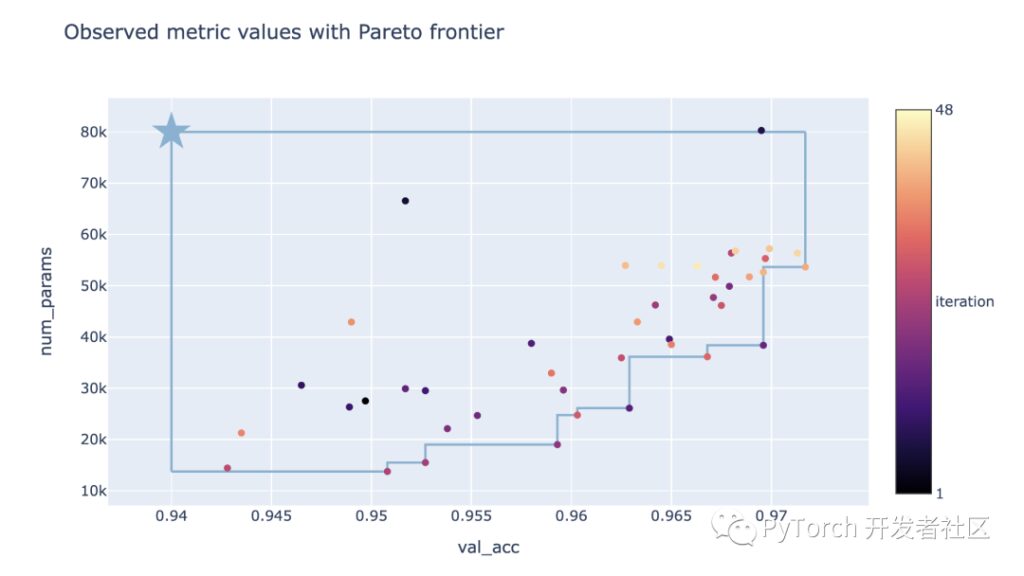
チュートリアルで実行した NAS 最適化の最終結果は、以下のトレードオフ プロットで確認できます。ここで、各点は試行の結果に対応し、色はその反復数を表し、星はターゲットに課せられたしきい値によって定義された参照点を表します。
この方法では、検証精度とパラメータ数の間のトレードオフをうまく調査できることがわかります。検証精度の高い大規模モデルと検証精度の低い小規模モデルの両方を見つけることができます。
意思決定者は、パフォーマンス要件とモデル サイズの制約に応じて、どのモデルを使用するか、またはさらに分析するかを選択できるようになりました。
視覚化
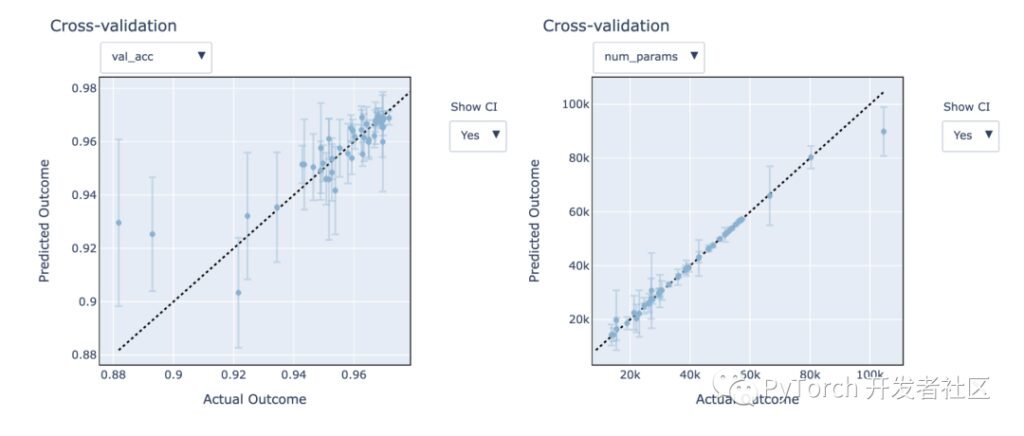
Axe は、実験結果の分析と理解に役立ついくつかの視覚化を提供します。未知のターゲットをモデル化するガウス プロセス モデルのパフォーマンスに注目してください。これらのモデルは、有望な構成をより迅速に発見するのに役立ちます。
Ax は、これらのモデルの精度と、Leave-one-out 相互検証を通じて目に見えないデータに対してモデルがどのように実行されるかをより深く理解するのに役立ちます。
以下の図では、モデルが非常によく適合していることがわかります。予測結果は実際の結果に近く、予測された 95% 信頼区間は、実際の結果を十分にカバーしています。
さらに、モデルのサイズが (num_params) メートル比検証精度 (val_acc) インジケーターのモデル化が容易になります。
アックスの概要
- チュートリアルでは、Ax を使用して完全に自動化された多目的ニューラル アーキテクチャ検索を実行する方法を示します。
- Ax スケジューラを使用すると、完全に非同期で最適化を自動的に実行するか (これはローカルで実行できます)、実験をリモートでクラスタにデプロイします (TorchX スケジューラの構成を変更するだけです)。
- Ax で利用できる最先端の多目的ベイジアン最適化アルゴリズムは、検証精度とモデル サイズの間のトレードオフを効率的に調査するのに役立ちます。
高度な機能
Axe には、上記のチュートリアルでは説明されていない他の高度な機能がいくつかあります。以下のものが含まれます。
早期停止
新しい候補構成を評価する場合、通常、NN トレーニング ジョブの実行中に学習曲線の一部が利用可能になります。
部分曲線に含まれる情報を使用してパフォーマンスの低い実験を特定し、実験を早期に中止して、より有望な候補のためにコンピューティング リソースを解放できます。上記のチュートリアルでは実証されていませんが、Axe はすぐに早期停止をサポートしています。
https://ax.dev/versions/latest/tutorials/early_stopping/early_stopping.html
高次元探索空間
実行時間を短く抑えるために、チュートリアルでは標準のガウス プロセスを使用したベイズ最適化が使用されています。
ただし、これらのモデルは通常、約 10 ~ 20 個の調整可能なパラメーターにしか対応しません。新しい SAASBO メソッドはサンプル効率が非常に高く、数百ものパラメータを調整できます。による 世代戦略の選択 移行 use_saasbo=True , SAASBOは簡単に有効にすることができます。
これは、TorchX の概要であり、PyTorch 開発者コミュニティは、グラフ変換を使用して実稼働 PyTorch モデルのパフォーマンスを最適化することに引き続き注力していきます。
Hyperai01を検索、コメント「 パイトーチ」PyTorch 技術交換グループに参加して、PyTorch の最新の進歩とベスト プラクティスについて学びましょう。








