Command Palette
Search for a command to run...
PyTorch 2.0 ビッグ リリース: コンパイル、コンパイル、コンパイル!

内容概要:昨夜開催されたPyTorch Conference 2022にて、PyTorch 2.0が正式リリースされました。この記事では、PyTorch 2.0 と 1.x の最大の違いを整理します。 キーワード: PyTorch 2.0 コンパイラー 機械学習 この記事は、WeChat パブリック アカウントで最初に公開されました: HypeAI Super Neural
PyTorch Conference 2022 で、PyTorch は PyTorch 2.0 を正式にリリースしました。以前の 1.x バージョンと比較して、2.0 には「破壊的な」変更が含まれていました。
PyTorch 2.0 は、PyTorch の使用方法を変える多数の新機能をリリースします。torch.compile を通じてコンパイル モードを追加しながら、同じ Eager モードとユーザー エクスペリエンスを提供します。モデルはトレーニング中および推論中に高速化され、パフォーマンスが向上し、動的形状と分散のサポートが提供されます。
この記事では、PyTorch 2.0 について詳しく説明します。
長すぎてバージョンを読めません
- PyTorch 2.0 は、元の利点を維持しながらコンパイルを大幅にサポートします。
- torch.compile は、コンパイルを実行するために 1 行のコードだけを必要とするオプションの関数です。
- 4 つの重要なテクノロジー:TorchDynamo、AOTAutograd、PrimTorch、TorchInductor
- 5年前にコンパイルを試みましたが、満足のいく効果は得られませんでした。
- PyTorch 1.x コードを 2.0 に移行する必要はありません* PyTorch 2.0 安定版は来年 3 月にリリースされる予定です
より速く、より優れたコンパイルのサポート
昨夜の PyTorch Conference 2022 では、torch.compile が正式にリリースされました。PyTorch のパフォーマンスがさらに向上し、PyTorch の一部が C++ から Python に戻り始めます。
PyTorch 2.0 の最新テクノロジーには次のものがあります。
トーチダイナモ、AOTAutograd、PrimTorch、TorchInductor。
1.トーチダイナモ
Python フレーム評価フックの助けを借りて、PyTorch プログラムを安全に取得できます。この主要なイノベーションは、過去 5 年間にわたる PyTorch の安全なグラフ キャプチャ (安全なグラフ キャプチャ) の研究開発成果を要約したものです。
2.AOTオートグラード
PyTorch autograd エンジンをトレース autodiff としてオーバーロードし、前方後方トレースを生成します。
3. プリムトーチ
2000 を超える PyTorch 演算子は約 250 のプリミティブ演算子閉集合に要約されており、開発者はこれらの演算子用の完全な PyTorch バックエンドを構築できます。 PrimTorch は、PyTorch 機能またはバックエンドを作成するプロセスを大幅に簡素化します。
4.トーチインダクター 複数のアクセラレータとバックエンド用の高速コードを生成できるディープ ラーニング コンパイラ。 NVIDIA GPU の場合、OpenAI Triton を主要な構成要素として使用します。
TorchDynamo、AOTAutograd、PrimTorch、TorchInductor は Python で書かれています。また、動的シェイプ (再コンパイルせずにさまざまなサイズのベクトルを送信できる機能) のサポートにより、動的シェイプが柔軟で習得しやすくなり、開発者やベンダーの参入障壁が低くなります。
これらのテクニックを検証するには、PyTorch は、機械学習の分野で 163 のオープンソース モデルを公式に使用しています。画像分類、ターゲット検出、画像生成などのタスクに加え、言語モデリング、質問応答、シーケンス分類、推奨システム、強化学習などのさまざまな NLP タスクが含まれます。これらのベンチマークは 3 つのカテゴリに分類されます。
- HuggingFace Transformers の 46 モデル
- Ross Wightman が収集した TIMM: SoTA PyTorch 画像モデルの 61 個のモデル
- TorchBench の 56 モデル: GitHub 上の人気のあるリポジトリのコレクション。
オープンソース モデルの場合、PyTorch はこれを正式に変更していませんが、カプセル化のための torch.compile 呼び出しを追加しただけです。
速度の向上はデータ型に依存する可能性があるため、次に PyTorch エンジニアはこれらのモデルの速度を測定し、精度を検証します。したがって、公式の高速化は float32 と自動混合精度 (AMP) の両方で測定されます。実際には AMP の方が一般的であるため、テスト比率は 0.75 * AMP + 0.25 * float32 に設定されます。
これら 163 のオープンソース モデルの中には、torch.compile は 93% モデルで正常に実行できますが、実行後、NVIDIA A100 GPU でのモデルの実行速度は 43% の向上に達しました。 Float32 精度では、実行速度は平均 21% 増加し、AMP 精度では、実行速度は平均 51% 増加します。
注: デスクトップ クラスの GPU (NVIDIA 3090 など) では、測定された速度はサーバー クラスの GPU (A100 など) よりも低くなります。現時点では、PyTorch 2.0 のデフォルト バックエンド TorchInductor はすでに CPU と NVIDIA Volta GPU および Ampere GPU をサポートしていますが、他の GPU、xPU、または古い NVIDIA GPU は現在サポートしていません。
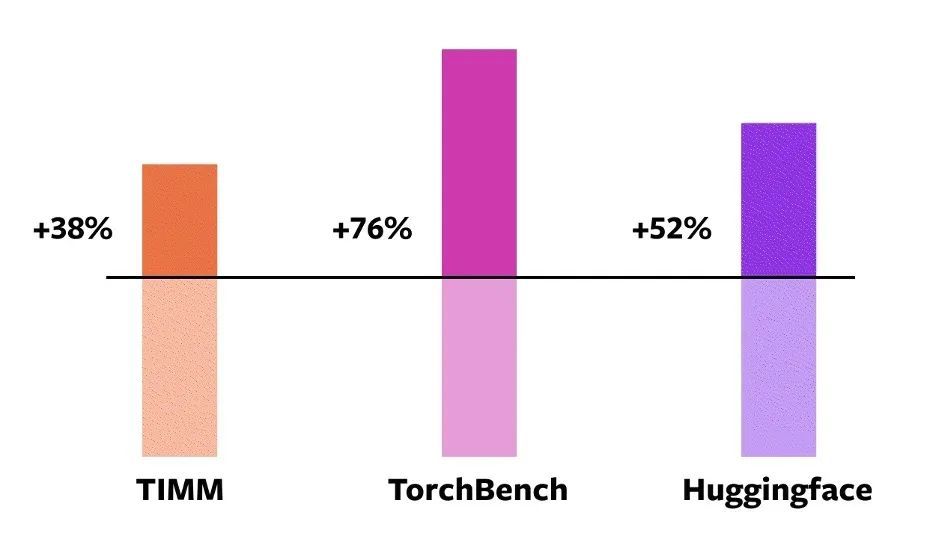 NVIDIA A100 GPU イーガー モード torch.compile のさまざまなモデルのパフォーマンス向上
NVIDIA A100 GPU イーガー モード torch.compile のさまざまなモデルのパフォーマンス向上
torch.compile オンライン トライアル:開発者は、nightly バイナリ ファイルを通じてインストールして試用できます。PyTorch 2.0 安定版は 2023 年 3 月初旬にリリースされる予定です。
PyTorch 2.x ロードマップでは、コンパイル モードのパフォーマンスとスケーラビリティは今後も継続的に強化され、改善されます。
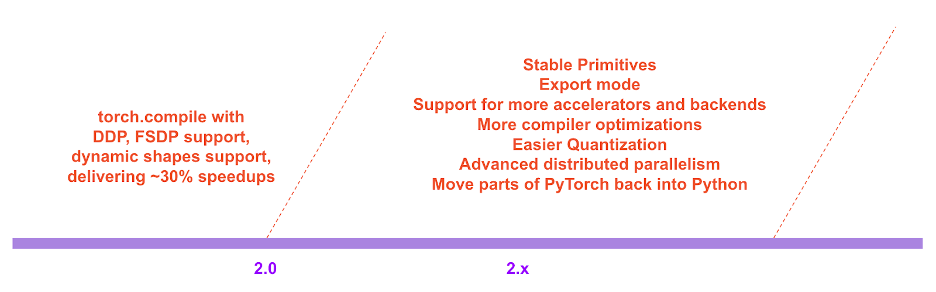 PyTorch 2.x ロードマップ
PyTorch 2.x ロードマップ
開発背景
PyTorch の開発哲学は常に、柔軟性とハッキング可能性を第一に、パフォーマンスを第二に考えてきました。に専心して:
1. 高性能の積極的実行
2. 内部構造を継続的にPython化する
3. 分散、Autodiff、データ読み込み、アクセラレータなどの優れた抽象化。
2017 年に PyTorch が発売されて以来、ハードウェア アクセラレータ (GPU など) の計算速度は約 15 倍、メモリ アクセス速度は約 2 倍に向上しました。
高パフォーマンスの積極的な実行を維持するには、PyTorch の内部コンテンツの大部分を C++ に転送する必要があります。これにより、PyTorch のハッキング可能性が低下し、開発者がコードのコントリビューションに参加するしきい値が高くなります。
PyTorch 関係者は初日から、熱心な実行のパフォーマンスの限界を認識していました。 2017 年 7 月、当局は PyTorch 用のコンパイラーの開発に取り組み始めました。コンパイラは、PyTorch エクスペリエンスを犠牲にすることなく、PyTorch プログラムの実行を高速化する必要があります。重要な基準は、ある程度の柔軟性を維持すること、つまり開発者によって広く使用されている動的形状と動的プログラムをサポートすることです。

PyTorch の技術詳細
創設以来、いくつかのコンパイラ プロジェクトが PyTorch で構築されてきました。これらのコンパイラは、次の 3 つのカテゴリに分類できます。
- グラフ取得
- グラフを下げる
- グラフ構造の編集(グラフ編集)
中でも、グラフ構造を取得することが最も大きな課題に直面しています。
過去 5 年間、関係者は torch.jit.trace、TorchScript、FX トレース、Lazy Tensors を試してきましたが、その中には十分な柔軟性はあるものの十分な速さがないもの、十分な速さはあるが柔軟性がないもの、高速でも柔軟性でもないものもあります。ユーザーエクスペリエンスが劣悪なものもあります。
トーチスクリプトは有望ですが、しかし、これには多くのコードの変更と依存関係が必要であり、あまり現実的ではありません。
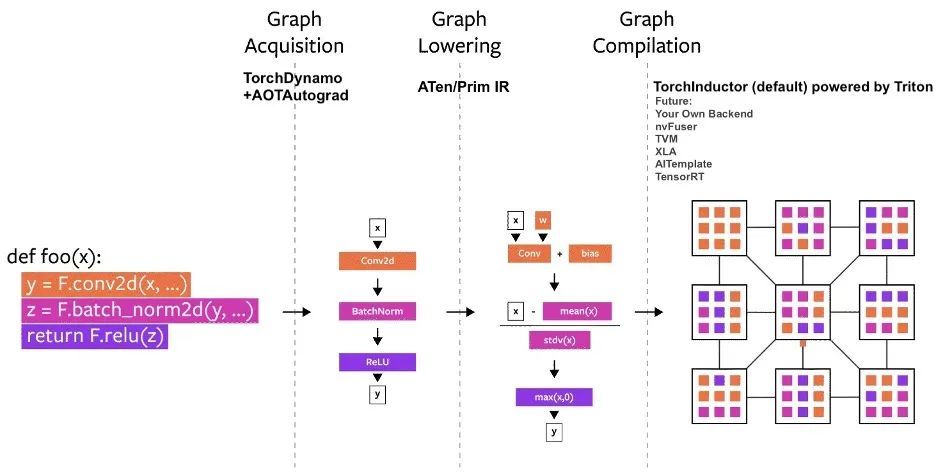 PyTorchのコンパイルプロセス図
PyTorchのコンパイルプロセス図
TorchDynamo: グラフ構造を確実かつ迅速に取得
TorchDynamo は、フレーム評価 API と呼ばれる、PEP-0523 で導入された CPython 機能を使用します。この関係者は、検証セットとして PyTorch で記述された 7,000 以上の Github プロジェクトを使用して、Graph Capture の有効性を検証するためにデータ駆動型のアプローチを採用しました。
実験はそれを示していますTorchDynamo は 99% 時間でグラフ構造を正確かつ安全に取得でき、オーバーヘッドは無視できます。元のコードを変更する必要がないためです。
TorchInductor: 実行による定義 IR による高速コード生成
ますます多くの開発者が高性能のカスタム カーネルを作成すると、トリトン言語を使用します。さらに、PyTorch 2.0 の新しいコンパイラ バックエンドについては、関係者は、PyTorch Eager と同様の抽象化を使用でき、PyTorch の幅広い機能をサポートするのに十分な一般的なパフォーマンスを備えられることを期待しています。
TorchInductor は、Pythonic の実行による定義ループ レベル IR を使用して、PyTorch モデルを GPU 上で生成された Triton コードおよび CPU 上の C++/OpenMP に自動的にマッピングします。
TorchInductor のコア ループ レベル IR には約 50 個の演算子のみが含まれており、Python で実装されているため、ハッキング性と拡張性が高くなります。
AOTAutograd: 事前グラフの場合、Autograd を再利用します。
トレーニングを高速化するために、PyTorch 2.0 はユーザーレベルのコードだけでなく、バックプロパゲーションもキャプチャする必要があります。実績のある PyTorch autograd システムを使用できればより良いでしょう。
AOTAutograd は、PyTorch torch_dispatch 拡張メカニズムを使用して Autograd エンジンを追跡します。開発者が逆方向パスを「事前に」キャプチャできるため、開発者はTorchInductorを使用して順方向パスと逆方向パスを高速化できます。
PrimTorch: 安定したプリミティブ オペレーター
PyTorch のバックエンドを作成するのは簡単ではありません。Torch には 1200 以上の演算子があり、各演算子のさまざまなオーバーロードを考慮すると、その数は 2000 以上にもなります。
 2000 を超える PyTorch オペレーターの分類の概要
2000 を超える PyTorch オペレーターの分類の概要
したがって、バックエンド機能や横断的な機能の作成は労力を要する作業になります。 PrimTorch は、より小規模でより安定した演算子のセットを定義することに取り組んでいます。 PyTorch プログラムは、これらの演算子セットに継続的にダウングレードできます。公式の目標は、2 セットの演算子を定義することです。
* Prim ops には約 250 個の比較的低レベルの演算子が含まれており、これらの演算子は十分に低レベルであるため、開発者はこれらの演算子を融合して良好なパフォーマンスを得る必要があります。
*ATen ops には、直接出力に適した約 750 の正規演算子が含まれています。これらのオペレーターは、ATen レベルで統合されたバックエンド、または基になるオペレーター セット (Prim ops など) からパフォーマンスを復元するようにコンパイルされていないバックエンドに適しています。
よくある質問
1. PyTorch 2.0 をインストールするにはどうすればよいですか?追加の要件は何ですか?
最新のナイトリーをインストールします。
CUDA 11.7
pip3 install numpy --pre torch[dynamo] torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu117CUDA 11.6
pip3 install numpy --pre torch[dynamo] torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu116CPU
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cpu2. PyTorch 2.0 のコードは 1.x と下位互換性がありますか?
はい、2.0 では PyTorch ワークフローを変更する必要はなく、コードを 1 行追加するだけです。 モデル = torch.compile(モデル)2.0 スタックを使用してモデルを最適化し、他の PyTorch コードでスムーズに実行できます。このオプションは必須ではないため、開発者は引き続き以前のバージョンを使用できます。
3. PyTorch 2.0 はデフォルトで有効になっていますか?
いいえ、2.0 は、単一の関数呼び出しを通じてモデルを最適化することにより、PyTorch コードで明示的に有効にする必要があります。
4. PT1.X コードを PT2.0 に移行するにはどうすればよいですか?
以前のコードを移行する必要はありません。2.0 で導入された新しいコンパイル モード機能を使用する場合は、まず 1 行のコードでモデルを最適化します。モデル = torch.compile(モデル)。
速度の向上は主にトレーニング プロセスに反映されます。モデルが Eager モードよりも高速に実行される場合、それは推論に使用できることを意味します。
import torch
def train(model, dataloader):
model = torch.compile(model)
for batch in dataloader:
run_epoch(model, batch)
def infer(model, input):
model = torch.compile(model)
return model(\*\*input)5. PyTorch 2.0 のどの機能が廃止されますか?
現在、PyTorch 2.0 はまだ安定しておらず、まだ nightlies バージョンです。 torch.compile での動的シェイプのサポートはまだ初期段階にあり、2023 年 3 月に安定版 2.0 がリリースされるまで非推奨となります。
つまり、静的形状のワークロードであっても、コンパイル モードでビルドされているため、いくつかのバグが発生する可能性があります。クラッシュするコードの部分については、コンパイル モードを無効にして問題を報告してください。
問題ポータルを送信します:https://github.com/pytorch/pytorch/issues
以上で PyTorch2.0 の詳細な紹介となります。今後は PyTorch 2.0 の導入を完了します。引き続きフォローよろしくお願いします。
WeChat で Hyperai01 を検索し、Neural Star との PyTorch テクノロジー開発グループ ディスカッションに参加することもできます。