Command Palette
Search for a command to run...
PyTorch の新しいライブラリ TorchMultimodal の使用手順: マルチモーダル一般モデル FLAVA を 100 億パラメータに拡張

前回の記事では、TorchMultimodal について紹介しました。今日は、Torch Distributed テクノロジーをサポートして、TorchMultimodal ライブラリのマルチモーダル基本モデルを拡張する方法を具体的なケースから説明します。
近年、大型模型が注目を集めている研究分野です。自然言語処理を例にとると、言語モデルは数億のパラメータ (BERT) から数千億のパラメータ (GPT-3) に発展し、下流タスクのパフォーマンスの向上に重要な役割を果たしています。
業界は、大規模な言語モデルを拡張する方法について広範な研究を行ってきました。同様の傾向がビジョンの分野でも観察され、ますます多くの開発者がトランスフォーマー ベースのモデル (ビジョン トランスフォーマー、マスクされたオート エンコーダーなど) に注目しています。
明らかに、大規模モデルの開発により、単一モダリティ (テキスト、画像、ビデオなど) 関連の研究は改善され続けており、フレームワークはより大規模なモデルに迅速に適応されています。
同時に、画像とテキストの検索、視覚的な質問応答、視覚的な対話、テキストから画像への生成などのタスクが現実世界に適用されるにつれて、マルチモダリティへの注目がますます高まっています。
次のステップは、大規模なマルチモーダル モデルをトレーニングすることです。この分野では、OpenAI の CLIP、Google の Parti、Meta の CM3 などの取り組みも行われています。
この記事では、ケース スタディを使用して、PyTorch 分散テクノロジを使用して FLAVA を 100 億パラメータに拡張する方法を説明します。
追加の資料:HyperAI Super Neural: Meta の内部で使用される FX ツールが出発点です: Graph Transformation を使用して PyTorch モデルを最適化します。
編集
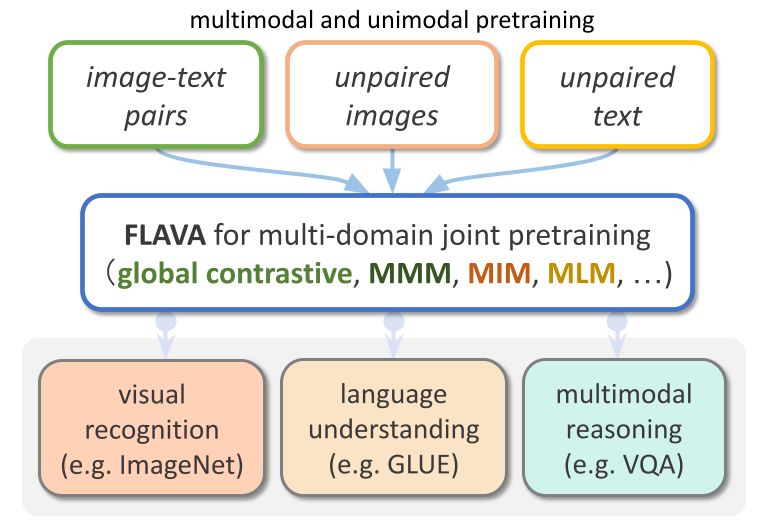
FLAVA は、TorchMultimodal で利用できるビジョンと言語ベースのモデルです。
FLAVA は、シングルモーダル ベンチマークとマルチモーダル ベンチマークの両方で非常に優れたパフォーマンスの利点を示します。この記事では、関連するコード例を組み合わせて、FLAVA を拡張する方法を示します。
コードの詳細については、以下を参照してください。
マルチモーダル/例/flava/メインでネイティブ · facebookresearch/マルチモーダル · GitHub
拡張 FLAVA の概要
FLAVA は、トランスフォーマー ベースの画像およびテキスト エンコーダーと、トランスフォーマー ベースのマルチモーダル フュージョン モジュールで構成される基本的なマルチモーダル モデルです。
FLAVA は、マスクされた言語、画像、マルチモーダル モデルの損失など、さまざまな損失を伴うシングルモーダル データとマルチモーダル データの両方で事前トレーニングされており、コンテキストの生の入力 (自己教師あり学習) からモデルを再構築する必要があります。
さらに、位置合わせされた画像とテキストのペアの正の例と負の例を含む画像テキストのマッチング損失と、CLIP スタイルのコントラスト損失を使用します。
FLAVA は、マルチモーダル タスク (画像とテキストの検索など) に加えて、シングルモーダル ベンチマーク (NLP の GLUE タスクや視覚的画像分類など) でも優れたパフォーマンスを示します。
編集
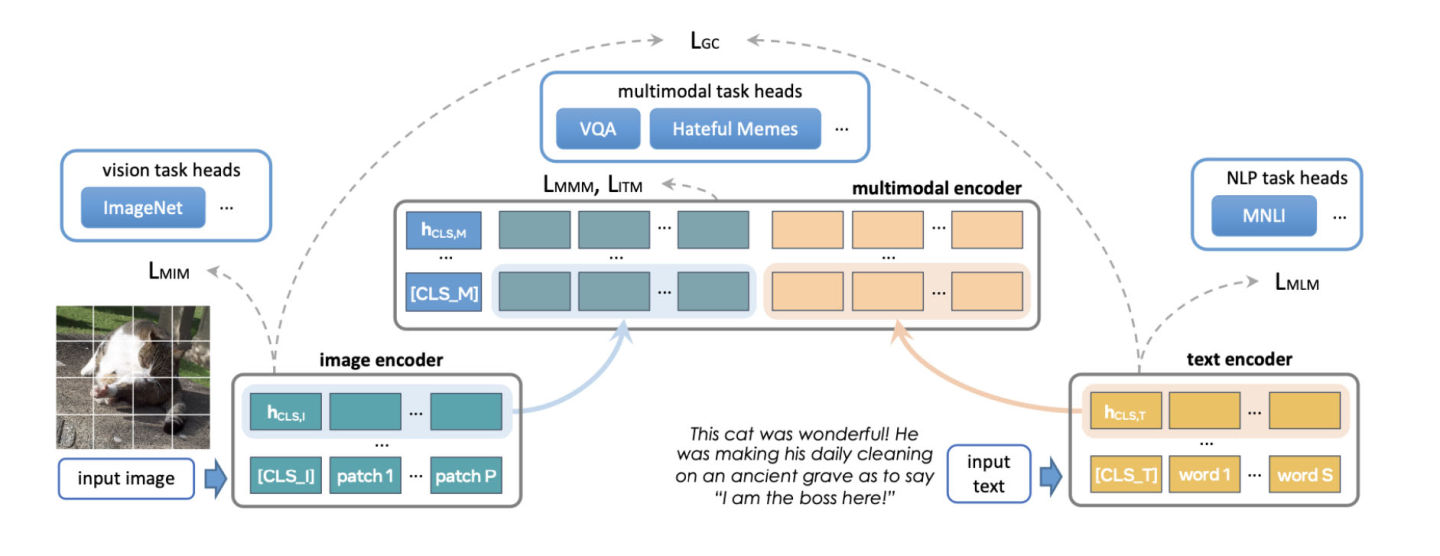
オリジナルの FLAVA モデルには約 3 億 5,000 万のパラメータがあり、画像およびテキスト エンコーダに ViT-B16 を使用して構成されました。
参照:https://arxiv.org/pdf/2010.11929.pdf
マルチモーダル フュージョン トランスフォーマーはシングルモーダル エンコーダーに続きますが、レイヤーの数は前のものの 1/2 にすぎません。 PyTorch 開発チームは、より大きな ViT バリアントに対応するためにエンコーダのサイズを増やすことを検討してきました。
FLAVA を拡張するもう 1 つの側面は、バッチ サイズを増やすことです。 FLAVA は、通常はバッチ サイズでのみ利用できるバッチ内ネガのコントラスト損失を巧みに利用します。
参照:https://openreview.net/pdfid=U2exBrf_SJh
一般に、最大のトレーニング効率またはスループットは、操作が可能な最大バッチ サイズに近づいたときにも達成されます。バッチ サイズは、利用可能な GPU メモリの量によって決まります (「実験」セクションを参照)。
以下の表は、さまざまなモデル構成の出力を示しています。各構成は、メモリ内の最大バッチ サイズに収まるように実験的に決定されています。

編集
最適化の概要
PyTorch は、モデルを効率的に拡張するためのいくつかのネイティブ テクノロジを提供します。次の章では、3 つの方法を詳細に紹介し、これらの技術を適用して FLAVA モデルを 100 億のパラメータに拡張する方法を示します。
分散データ並列処理
分散トレーニングの一般的な開始点はデータの並列処理です。データ並列処理では、GPU 間でモデルをコピーし、データセットを分割します。異なる GPU は異なるデータ パーティションを並行して処理し、モデルの重みを更新する前にそれらの勾配を (All Reduce 経由で) 同期します。
次の図は、データ並列処理のプロセス (順方向反復、逆方向反復、および重み更新ステップ) を示しています。

編集
データ並列処理を実現するために、PyTorch は、次に示すように、モジュール ラッパー (モジュール ラッパー) として使用できるネイティブ API である DistributedDataParallel (DDP) を提供します。
from torchmultimodal.models.flava.model import flava_model_for_pretraining
import torch
import torch.distributed as dist
model = flava_model_for_pretraining().cuda()
# Initialize PyTorch Distributed process groups
# Please see https://pytorch.org/tutorials/intermediate/dist_tuto.html for details
dist.init_process_group(backend=”nccl”)
# Wrap model in DDP
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[torch.cuda.current_device()])完全にシャード化されたデータ並列処理
トレーニング アプリケーションの GPU メモリ使用量は、モデル入力、中間アクティベーション ストレージ (勾配計算に必要)、モデル パラメーター、勾配、およびオプティマイザーの状態に大別できます。
モデルを拡張する場合、多くの場合、これらの要素が一緒に追加されます。単一の GPU がメモリ不足になった場合、DDP を使用してモデルをスケーリングすると、パラメータ、勾配、オプティマイザーの状態がすべての GPU にコピーされるため、メモリ不足の動作が発生する可能性があります。
この重複を減らし、GPU メモリを節約するために、モデル パラメーター、勾配、およびオプティマイザーの状態をすべての GPU でシャーディングし、各 GPU が 1 つのシャードのみを管理することができます。この手法はMicrosoft社が提案するZeRO-3を参考にしています。
このメソッドのネイティブ PyTorch 実装は、PyTorch 1.12 のベータ機能としてリリースされた FullyShardedDataParallel (FSDP) API として利用できます。
モジュールの順方向および逆方向の反復中に、FSDP は計算のニーズに応じてモデル パラメーターを (オールギャザーを使用して) 統合し、計算後に再シャーディングします。散乱低減のアンサンブルを使用して勾配を同期し、タイル全体の勾配がグローバルに平均化されるようにします。 FSDP におけるモデルの順方向反復プロセスと逆方向反復プロセスは次のとおりです。

編集
FSDP を使用する場合、特定のサブモジュールが断片化されるかどうかを制御するには、API を使用してモデルのサブモジュールをカプセル化する必要があります。 FSDP は、すぐに使える自動ラッピング API、いくつかのラッピング ポリシー、およびポリシーを作成する機能を提供します。
次の例は、FSDP を使用して FLAVA モデルをカプセル化する方法を示しています。自動ラッピング ポリシーをtransformer_auto_wrap_policyとして指定します。これにより、単一のトランスフォーマー レイヤー (TransformerEncoderLayer)、イメージ トランスフォーマー (ImageTransformer)、テキスト エンコーダー (BERTTextEncoder)、およびマルチモーダル エンコーダー (FLAVATransformerWithoutEmbeddings) が単一の FSDP ユニットにカプセル化されます。
これは、効率的なメモリ管理のために再帰的カプセル化アプローチを使用します。たとえば、単一のトランス層の順方向または逆方向の反復が完了すると、パラメータが削除され、メモリが解放されるため、ピーク時のメモリ使用量が削減されます。
FSDP には、この例の limit_all_gathers の使用など、アプリケーションのパフォーマンスを調整するための構成可能なオプションもいくつか用意されています。これにより、すべてのモデル パラメーターの時期尚早な収集が防止され、アプリケーションのメモリ負荷が軽減されます。
import torch
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.wrap import transformer_auto_wrap_policy
from torchmultimodal.models.flava.model import flava_model_for_pretraining
from torchmultimodal.models.flava.text_encoder import BertTextEncoder
from torchmultimodal.models.flava.image_encoder import ImageTransformer
from torchmultimodal.models.flava.transformer import FLAVATransformerWithoutEmbeddings
from torchmultimodal.modules.layers.transformer import TransformerEncoderLayer
model = flava_model_for_pretraining().cuda()
dist.init_process_group(backend=”nccl”)
model = FSDP(
model,
device_id=torch.cuda.current_device(),
auto_wrap_policy=partial(
transformer_auto_wrap_policy,
transformer_layer_cls={
TransformerEncoderLayer,
ImageTransformer,
BERTTextEncoder,
FLAVATransformerWithoutEmbeddings
},
),
limit_all_gathers=True,
)アクティベーションチェックポイント
上記のように、中間アクティベーション ストレージ (中間アクティベーション)、モデル パラメーター、勾配、オプティマイザーの状態は GPU メモリの使用量に影響します。 FSDP は、後の 3 つによって発生するメモリ消費を削減できますが、アクティブ化によって消費されるメモリを削減することはできません。アクティベーションによって使用されるメモリは、バッチ サイズまたは隠れ層の数とともに増加します。
アクティベーション チェックポイントは、特定のチェックポイントが設定されたモジュールのメモリにアクティベーションを保存するのではなく、逆方向の反復中にアクティベーションを再計算することでメモリ使用量を削減します。
たとえば、アクティベーション チェックポイントを 27 億パラメータ モデルに適用すると、前方反復後のピーク アクティブ メモリが 4 分の 1 に削減されます。
PyTorch は、ラッパーベースのアクティブ化チェックポイント API を提供します。また、checkpoint_wrapper を使用すると、ユーザーはチェックを通じて単一のモジュールをカプセル化でき、apply_activation_checkpointing を使用すると、モジュール全体でチェックポイントを使用してモジュールをカプセル化する戦略を指定できます。
これら 2 つの API は、モデル定義コードを変更する必要がないため、ほとんどのモデルに適用できます。
ただし、モジュール内の特定の関数にチェックポイントを設定するなど、チェックポイントが設定されたセグメントをより詳細に制御する必要がある場合は、モデル コードの変更が必要な torch.utils.checkpoint API を使用できます。
単一の FLAVA トランスフォーマー層 (TransformerEncoderLayer で表される) へのアクティベーション チェックポイント設定ラッパーの適用は次のとおりです。
from torchmultimodal.models.flava.model import flava_model_for_pretraining
from torch.distributed.algorithms._checkpoint.checkpoint_wrapper import apply_activation_checkpointing, checkpoint_wrapper, CheckpointImpl
from torchmultimodal.modules.layers.transformer import TransformerEncoderLayer
model = flava_model_for_pretraining()
checkpoint_tformer_layers_policy = lambda submodule: isinstance(submodule, TransformerEncoderLayer)
apply_activation_checkpointing(
model,
checkpoint_wrapper_fn=checkpoint_wrapper,
check_fn=checkpoint_tformer_layers_policy,
)
上に示したように、アクティベーション チェックポイントを使用して FLAVA トランスフォーマ層をカプセル化し、FSDP を使用してモデル全体をカプセル化すると、FLAVA を 100 億のパラメータに拡張できます。
実験
上記のさまざまな最適化方法について、システム パフォーマンスへの影響をさらに実験していきます。
背景の紹介:
- 8 つの A100 40 GB GPU を備えた単一ノードの使用
- 事前トレーニングを 1000 回繰り返し実行する
- bfloat16 データ型を使用した PyTorch 混合精度トレーニング (自動混合精度)
- TensorFloat32 形式を有効にして A100 での matmul パフォーマンスを向上させる
- スループットを 1 秒あたりに処理されるアイテムの平均数として定義します (スループットの測定時に最初の 100 回の反復は無視されます)。
- トレーニングの収束とその下流タスク指標への影響は、将来の研究の新たな方向性として機能します。
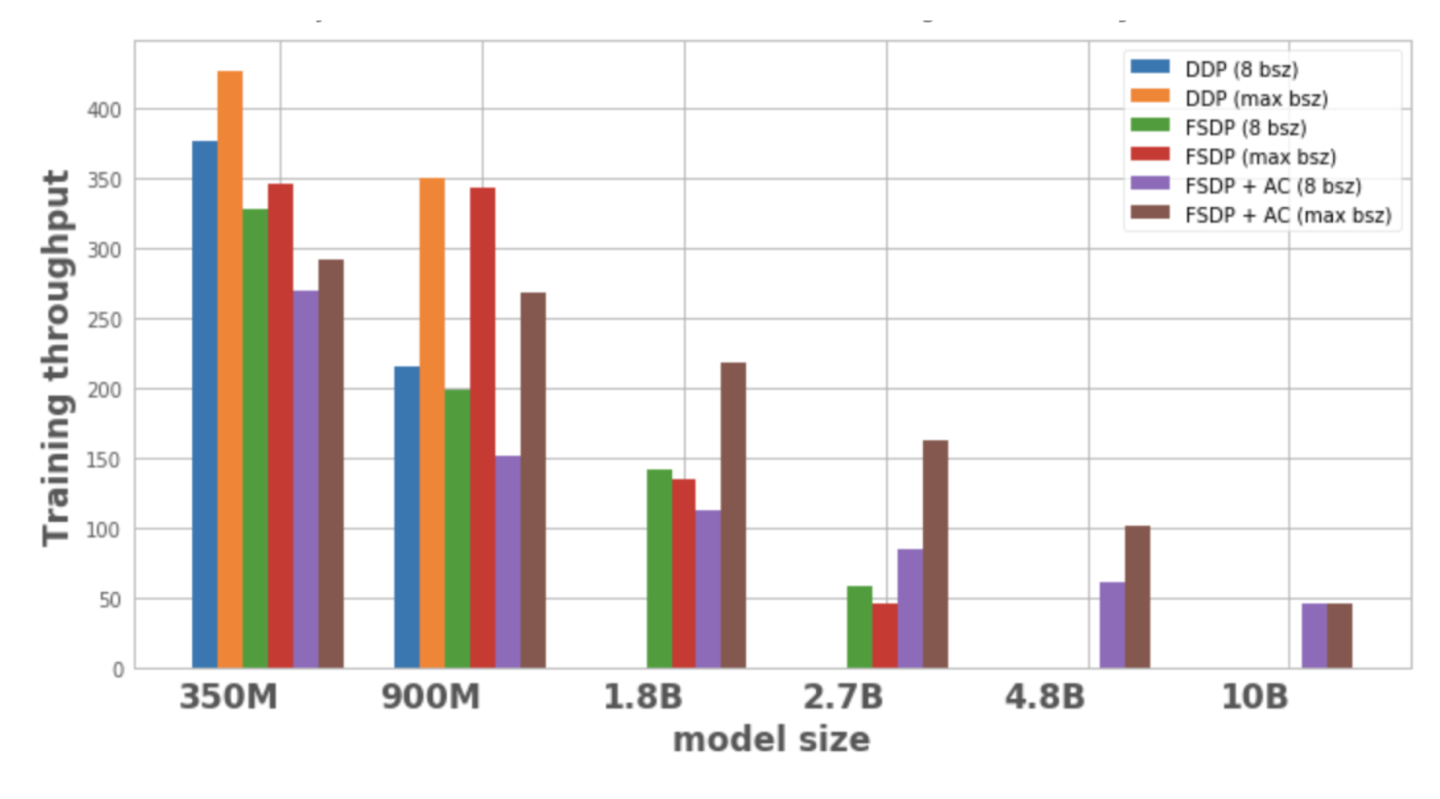
図 1 は、ローカル バッチ サイズ 8 と 1 ノードで可能な最大バッチ サイズを使用した場合の、各モデルの構成と最適化のスループットを示しています。最適化されたモデル バリアントにはデータ ポイントがなく、モデルを単一ノードでトレーニングできないことを示しています。
編集
図 1: さまざまな構成でのトレーニング スループット
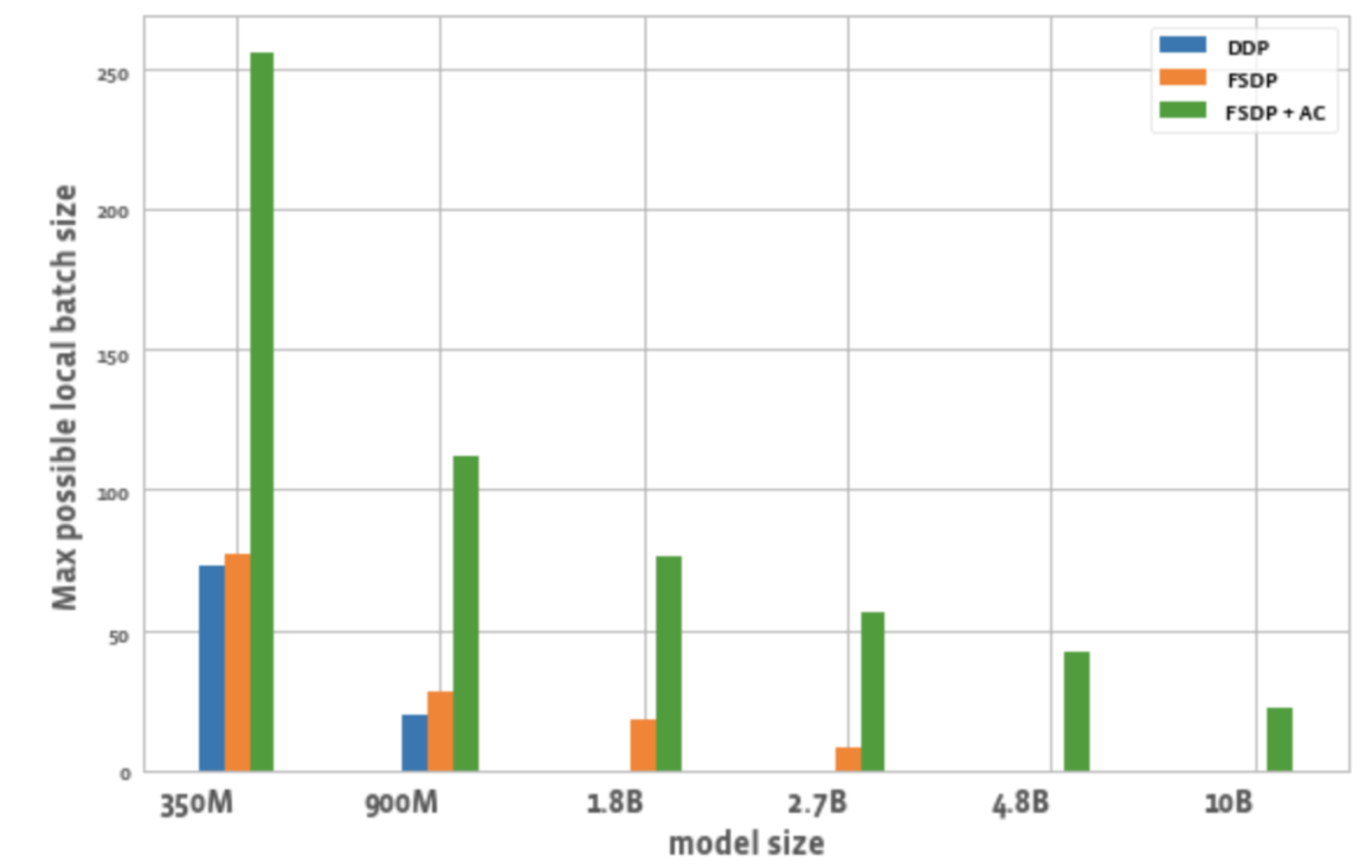
図 2 は、各最適化におけるすべての GPU で可能な最大バッチ サイズを示しています。
編集
図 2: さまざまな構成で可能な最大ローカル バッチ サイズ
このことから次のことがわかります。
1. モデルのサイズを拡張します。
DDP は、1 つのノード上で 350M モデルと 900M モデルのみを収容できます。 FSDP を使用するとメモリが節約されるため、DDP の 3 倍の大きさのモデル (つまり、1.8B および 2.7B のバリアント) をトレーニングすることが可能です。アクティベーション チェックポイント (AC) と FSDP を組み合わせると、DDP (4.8B および 10B バリアントなど) の約 10 倍の大規模なモデルをトレーニングできます。
2. スループット:
– 小規模なモデルの場合、バッチ サイズが 8 の場合、DDP のスループットは FSDP よりわずかに高いか同等になります。これは、FSDP が追加の通信を必要とするという事実によって説明できます。 FSDP と AC を組み合わせた場合のスループットは最も低くなります。これは、AC が逆方向反復プロセス中にチェックポイントが設定された順方向反復チャネルを再実行し、メモリを節約するために追加の計算を犠牲にするためです。ただし、2.7B モデルの場合、実際には FSDP + AC は FSDP 単独と比較してスループットが高くなります。これは、FSDP を使用する 2.7B モデルはバッチ サイズ 8 であってもメモリの制限に近く、CUDA malloc の再試行がトリガーされ、トレーニングの速度が低下するためです。 AC はメモリ負荷を軽減し、再試行を行わないようにするのに役立ちます。
– DDP および FSDP + AC の場合、バッチ サイズが増加するにつれてモデルのスループットが増加します。 FSDP は、より小さなバリアントに対しても同じことを行います。ただし、1.8B および 2.7B パラメータ モデルの場合、バッチ サイズを増やすとスループットが低下します。考えられる理由の 1 つは、メモリ制限に達すると、PyTorch の CUDA メモリ管理が、ワークロードのメモリ ニーズを処理するためにメモリの空きブロックを見つけるために cudaMalloc 呼び出しを再試行するか、コストのかかるデフラグメンテーションを実行する必要があり、これによりトレーニングが遅くなる可能性があることです。
– FSDP でのみトレーニングできる大規模モデル (1.8B、2.7B、4.8B) の場合、最高のスループット設定は、FSDP+AC で最大バッチ サイズにスケーリングします。 10B の場合、スループットは小さいバッチ サイズと最大バッチ サイズでほぼ等しいことがわかります。これは、AC により計算量が増加し、最大バッチ サイズにより CUDA メモリ制限下で実行されるため、デフラグ操作にコストがかかる可能性があるためです。ただし、これらの大規模なモデルの場合、バッチ サイズの増加はこのオーバーヘッドを補って余りあるものになります。
3. バッチサイズ:
DDP と比較して、FSDP だけでわずかに大きいバッチ サイズを実現できます。 350M パラメータ モデルの場合、FSDP+AC を使用すると DDP の 3 倍のバッチ サイズを達成でき、900M パラメータ モデルの場合、5.5 倍のバッチ サイズを達成できます。 10B であっても、最大バッチ サイズは約 20 であり、これはかなり優れています。 FSDP+AC は基本的に、より少ない GPU でより大きなグローバル バッチ サイズを実現でき、特に対照的な学習タスクに効果的です。
結論は
マルチモーダルな基本モデルの開発に伴い、モデル パラメーターの拡張と効率的なトレーニングが重点分野になりつつあります。 PyTorch エコシステムは、さまざまなツールを提供することで、マルチモーダル モデルのトレーニングとスケーリングを加速することを目的としています。
将来的には、PyTorch はマルチモーダル生成モデルなどの他のタイプのモデルのサポートを追加し、関連テクノロジーの自動化を改善する予定です。皆様、引き続き PyTorch 開発者コミュニティの公式アカウントをフォローしてください。QR コードをスキャンして「PyTorch」とメモして PyTorch コミュニティに参加することもできます。

PyTorch 公式ブログとチュートリアル
最新の開発とベストプラクティス
QR コードをスキャンしてメモし、ディスカッション グループに参加してください








