Command Palette
Search for a command to run...
PyTorch 公式ライブラリ「新機能」、TorchMultimodal がマルチモーダル人工知能を支援
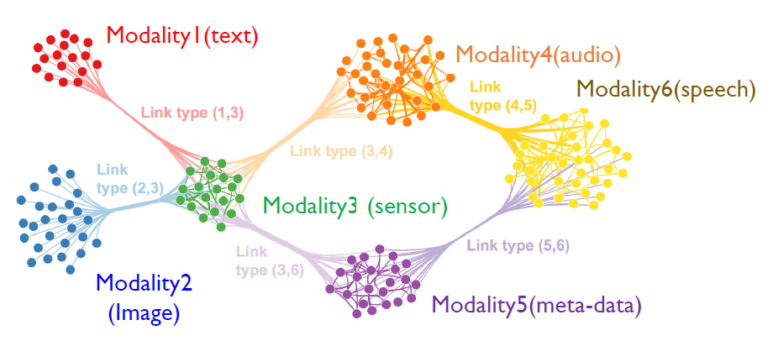
マルチモーダル人工知能は、より高いパフォーマンスを達成するために、画像、テキスト、音声、ビデオなどの複数のデータ タイプとさまざまなインテリジェントな処理アルゴリズムを組み合わせることを指す新しい AI パラダイムです。
最近、PyTorch はドメイン ライブラリである TorchMultimodal を正式にリリースしました。SoTA マルチタスクおよびマルチモーダル モデルの大規模トレーニングに使用されます。
このライブラリは以下を提供します。
- モデル開発をスピードアップするための構成可能なビルディング ブロック (モジュール、変換、損失関数)
- 公開された研究、トレーニング、評価スクリプト (FLAVA、MDETR、Omnivore) から抽出された SoTA モデル アーキテクチャ
- これらのモデルをテストするためのノートブック
TorchMultimodal ライブラリはまだ活発に開発中です。次の点に注意してください。
https://github.com/facebookresearch/multimodal#installation
トーチマルチモーダル開発の背景
テクノロジーの進歩に伴い、複数種類の入力(テキスト、画像、動画、音声信号)を理解し、その理解を利用してさまざまな形式の出力(文章、写真、動画)を生成できるAIモデルがますます注目を集めています。 。
FAIR による最近の研究成果 (FLAVA、Omnivore、data2vec など) は次のことを示しています。理解のためのマルチモーダル モデルは、シングルモーダル モデルよりも利点があり、場合によっては、まったく新しい SOTA の先駆者となります。
Make-a-video や Make-a-scene などの生成モデルは、最新の人工知能システムの機能を再定義しています。
PyTorch エコシステムにおけるマルチモーダル AI の開発を促進するために、 TorchMultimodal ライブラリが登場し、その解決策は次のとおりです。
- 組み合わせ可能なビルディングブロックを提供し、 これらの構成要素を使用すると、研究者は独自のワークフロー内でモデルの開発と実験を加速できます。モジュラー設計により、新しいモーダル データへの移行の難しさも軽減されます。
- 研究における最先端のモデルのトレーニングと評価のためのエンドツーエンドの例が提供されます。 これらの例では、モデルとバッチ サイズをスケーリングするための統合 FSDP やアクティベーション チェックポイントなどの高次機能を使用します。
TorchMultimodal の最初の紹介
TorchMultimodal は PyTorch ドメイン ライブラリです。マルチタスク、マルチモーダル モデルの大規模トレーニング用。 それは以下を提供します:
1.ビルディングブロック
モデル、融合レイヤー、損失関数、データセット、ユーティリティなど、構成可能なビルディング ブロックのモジュールとコレクション。次のようなものです。
- 温度による損失の対比: CLIP や FLAVA など、モデルのトレーニングに一般的に使用される関数。 ALBEF などのモデルで使用される ImageTextContrastiveLoss などの変数も含まれます。
- コードブック層: ベクトル空間での最近傍検索による高次元データの圧縮も、VQVAE の重要な部分です。
- シフトウィンドウ 注意: window はマルチヘッドセルフアテンションに基づいており、Swin 3D Transformer などのエンコーダの重要なコンポーネントです。
- クリップコンポーネント: OpenAI によって公開された、テキストと画像表現を学習するための非常に効果的なモデルです。
- マルチモーダル GPT: ジェネレーターと組み合わせると、OpenAI の GPT アーキテクチャを、マルチモーダル生成により適した抽象化に拡張できます。
- マルチヘッド注意: 自動回帰とデコードをサポートするアテンションベースのモデルの重要なコンポーネント。
2. 例
一連の例では、ビルディング ブロックを PyTorch コンポーネントおよびパブリック インフラストラクチャ (Lightning、TorchMetrics) と組み合わせて、文献で公開されている SOTA モデルを複製する方法を示します。現在、次の 5 つの例が提供されています。
- フラバ: CVPR は、FLAVA の微調整に関するチュートリアルを含む論文の公式コードを受け入れます。
論文を見る:https://arxiv.org/abs/2112.04482
- MDETR: ニューヨーク大学の著者との協力により、フレーズ グラウンディングと視覚的な質問応答に MDETR を使用したノートブックなど、PyTorch エコシステムにおける相互運用性の問題点を軽減する例が提供されます。
論文を見る:https://arxiv.org/abs/2104.12763
- 雑食動物: ビデオおよび 3D データを処理するための TorchMultimodal のモデルの最初の例 (モデルを探索するためのノートブックを含む)。
論文を見る:https://arxiv.org/abs/2204.08058
- ムゲン: OpenAI Coinrun の豊富な大規模合成データ セットを使用したテキスト ビデオの生成と取得のデモを含む、自動回帰の生成と取得に関する基本的な作業。
論文を見る:https://arxiv.org/abs/2204.08058
- アルベフ: モデルコード。視覚的な質問応答の問題を解決するためにモデルを使用するノートブックを含みます。
論文を見る:https://arxiv.org/abs/2107.07651
次のコードは、CLIP に関連するいくつかの TorchMultimodal コンポーネントの使用法を示しています。
# instantiate clip transform
clip_transform = CLIPTransform()
# pass the transform to your dataset. Here we use coco captions
dataset = CocoCaptions(root= ..., annFile=..., transforms=clip_transform)
dataloader = DataLoader(dataset, batch_size=16)
# instantiate model. Here we use clip with vit-L as the image encoder
model= clip_vit_l14()
# define loss and other things needed for training
clip_loss = ContrastiveLossWithTemperature()
optim = torch.optim.AdamW(model.parameters(), lr = 1e-5)
epochs = 1
# write your train loop
for _ in range(epochs):
for batch_idx, batch in enumerate(dataloader):
image, text = batch
image_embeddings, text_embeddings = model(image, text)
loss = contrastive_loss_with_temperature(image_embeddings, text_embeddings)
loss.backward()
optimizer.step()InstallTorchマルチモーダル
Python ≥ 3.7 (CUDA サポートのインストールの有無にかかわらず)。
次のコードでは、例として conda のインストールを取り上げます。
前提条件
1.conda環境をインストールする
conda create -n torch-multimodal python=\<python_version\>
conda activate torch-multimodal2. PyTorch、torchvision、torchtext をインストールする
PyTorch のドキュメントを参照してください。
https://pytorch.org/get-started/locally/
# Use the current CUDA version as seen [here](https://pytorch.org/get-started/locally/)
# Select the nightly Pytorch build, Linux as the OS, and conda. Pick the most recent CUDA version.
conda install pytorch torchvision torchtext pytorch-cuda=\<cuda_version\> -c pytorch-nightly -c nvidia
# For CPU-only install
conda install pytorch torchvision torchtext cpuonly -c pytorch-nightlyバイナリからインストールする
Linux では、Python 3.7、3.8、および 3.9 の Nightly バイナリを pip ホイール経由でインストールできます。現在、PyPI を通じてサポートされているのは Linux プラットフォームのみです。
python -m pip install torchmultimodal-nightlyソースコードのインストール
開発者は、ソースからサンプルをビルドして実行することもできます。
git clone --recursive https://github.com/facebookresearch/multimodal.git multimodal
cd multimodal
pip install -e .以上がTorchMultimodalの簡単な紹介です。コード以外にも、PyTorch は、マルチモーダル モデルの微調整に関する基本チュートリアルも正式にリリースしました。 また、PyTorch Distributed PyTorch (FSDP およびアクティベーション チェックポイント) テクノロジーを使用してこれらのモデルを拡張する方法に関するブログです。
今後、このブログの中国語版も整備する予定です。 PyTorch 開発者コミュニティの公式アカウントに引き続きご注目ください。
- 以上 -








