Command Palette
Search for a command to run...
タイプミスの修正 | 中国語のテキストのスペルミス修正モデルを導入する
内容の概要: 中国語のテキスト エラーの種類の 1 つはスペル ミスです。この記事は、BART 事前トレーニング メソッドを使用して中国語のテキスト エラー修正機能を実装するためのモデル展開チュートリアルです。
キーワード: BART 中国語スペル修正 NLP
この記事は、WeChat パブリック アカウントで最初に公開されました: HyperAI Super Neural
中国語の文章エラーに対する 3 つの主な障害: スペル、文法、意味論
中国語テキストの誤り訂正は、自然言語処理の現在の分野の重要な分野であり、中国語テキストの誤りを検出して修正することを目的としています。一般的な中国語のテキスト エラーには、スペル ミス、文法的エラー、意味上のエラーが含まれます。
1. スペルミス:
入力方法や音声合成ソフトウェアなどによって引き起こされる言葉遣いや言葉遣いの誤りを指し、主に「天気は晴れです – 天気は晴れです晴れです」「四方 - しほう」。
2. 構文エラー:
「謙虚さは人を進歩させる - 謙虚さは人を進歩させる」のように、入力方法、不注意な手書き、OCR認識などにより、単語の欠落、冗長、順序の乱れ、不適切な一致を指します。
3. セマンティックエラー:
「1 年は 3 四半期あります – 1 年は 4 四半期あります」など、特定の知識の理解不足や言語体系化スキルの不足によって引き起こされる知識および論理のエラー。
この記事では、最も一般的なスペルミスを例として取り上げます。BART モデルを使用して中国語テキストのエラー修正モデルを展開する方法を示します。
チュートリアルを直接実行するには、次のサイトにアクセスしてください。
BART:「みんなの強みから学ぶ」SOTAモデル
BART は、双方向および自動回帰トランスフォーマーの略です。seq2seq モデルの事前トレーニング用に設計されたノイズ除去オートエンコーダーです。 2019 年に Meta (旧 Facebook) によって提案された、自然言語の生成、翻訳、および理解タスクに適しています。
論文の詳細については、以下を参照してください。
https://arxiv.org/pdf/1910.13461.pdf
BART モデルは、標準の Transformer 構造をベースとして、BERT と GPT の利点を活用しています。
- デコーダ モジュール リファレンス GPT: ReLU アクティベーション関数を GeLU アクティベーション関数に置き換えます。
- エンコーダ モジュールは BERT とは異なります。 フィードフォワード ニューラル ネットワーク モジュールは廃止され、モデル パラメーターは簡素化されました。
- コーデック接続部分は Transformer を指します。 デコーダの各層は、エンコーダの最後の層の出力情報に対してクロスアテンション計算を実行する必要があります (つまり、エンコードおよびデコード アテンション メカニズム)。

このチュートリアルでは、モデルのデプロイには nlp_bart_text-error-correction_chinese モデルを使用します。
詳細については、次のサイトを参照してください。
詳細なチュートリアル: オンライン テキスト修正デモを作成する
環境整備
jupyter ターミナルで次のコマンドを実行して、依存関係をインストールします。
pip install "modelscope[nlp]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
pip install fairseqモデルのダウンロード
ターミナルで次のコマンドを実行してモデルをダウンロードします。
git clone http://www.modelscope.cn/damo/nlp_bart_text-error-correction_chinese.gitモデルのダウンロードには時間がかかります。ダウンロードされたモデルはすでにこのコンテナーにあるため、直接使用できます。 nlp_bart_text-error-correction_chinese ディレクトリ。
すぐに使える
モデルのデプロイメント
サービングサービスライティング
書く predictor.py 書類:
- 依存ライブラリのインポート: ビジネスで使用されるライブラリに加えて、openbayes-serving への追加の依存関係が必要です。
import openbayes_serving as serv
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks- Predictor クラス: 他のクラスから継承する必要はありません。少なくとも次のクラスを提供します。 初期化 そして 2 つのインターフェースを予測します。
- 存在する
__init__でモデルのパスを指定してモデルをロードします - 存在する
predict推論を実行して結果を返す
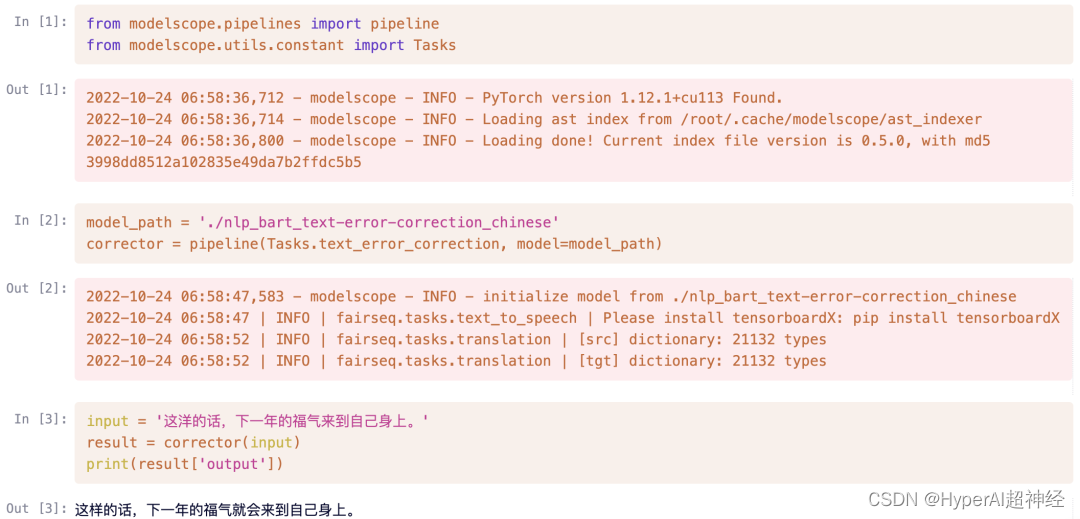
class Predictor:
def __init__(self):
self.model_path = './nlp_bart_text-error-correction_chinese'
self.corrector = pipeline(Tasks.text_error_correction, model=self.model_path)
def predict(self, json):
text = json["input"].lower()
result = self.corrector(text)
return result- 実行: サービスを開始します
if __name__ == '__main__':
serv.run(Predictor)テスト
ターミナルで実行 python predictor.py、サービスが正常に開始されたら、テストのためにこのノートブックで次のコードを実行します。
注: コンテナーでテストする場合、フラスコのバージョンが 2.1 より大きい場合、重複登録エラーが発生する可能性があります。実行するバージョンを下げてください。
import requests
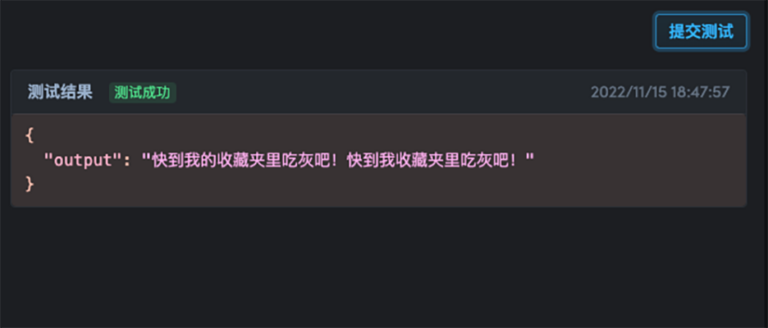
text = {"input": "这洋的话,下一年的福气来到自己身上。"}
result = requests.post('http://localhost:8080', json=text)
result.json()
{'output': '这样的话,下一年的福气就会来到自己身上。'}ローカル経由でアドレスにアクセスするだけでなく、 http://localhost:8080、ターミナルに表示される外部からアクセス可能な URL を介してテストすることもできます。

注: OpenBayes コンピューティング パワー コンテナーが異なると、外部からアクセスできる URL が異なります。このチュートリアルのリンクを直接使用することは無効であるため、ターミナルでプロンプトが表示されるリンクに置き換える必要があります。。
result = requests.post('https://openbayes.com/jobs-auxiliary/open-tutorials/t23g93jjm95d', json=text)
result.json()展開する
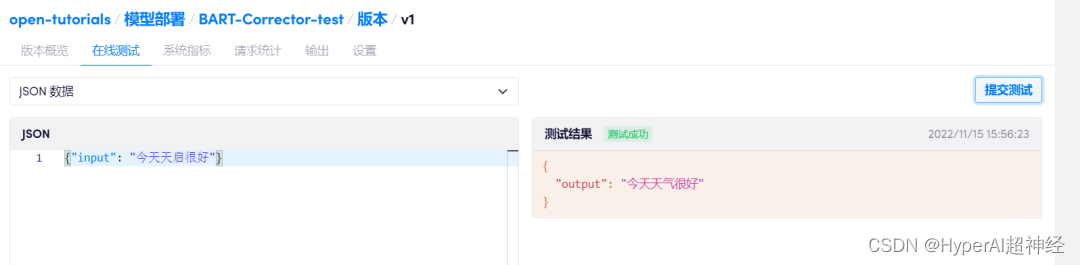
テストが成功したら、コンピューティング パワー コンテナーを停止し、データが同期されるまで待ちます。
「Computing Power Container - Model Deployment」の「Create New Deployment」をクリックし、開発時と同じイメージを選択し、このComputing Power Containerをバインドして「Deploy」をクリックします。オンラインテストが利用できるようになりました。
モデルのデプロイメントの詳細については、以下を参照してください。
この時点で、オンライン テストをサポートする中国語テキストのエラー修正モデルがトレーニングされ、デプロイされました。
完全なチュートリアルを表示して実行するには、以下のリンクにアクセスしてください。
中国語の誤り訂正モデルをぜひ試してみてください。
- 以上 -
参考リンク:
[1] https://www.51cto.com/article/715865.html
[2] https://arxiv.org/pdf/1910.1346








