")
Google 翻訳がリリースされてから 15 年近くが経ちますが、これまで Google 翻訳は Android スマートフォンが非常に速いと頑なに信じていました。
GT の最新のメジャー アップデートは、2016 年にニューラル機械翻訳 (GNMT) の使用を開始したシステムです。これには、9 言語の翻訳用に 8 つのエンコーダーと 8 つのデコーダーが含まれています。
文を分割するだけでなく、単語も分割することで、珍しい単語にアプローチします。単語が辞書にない場合、NMT は参照できません。たとえば、文字グループ「Vas3k」を翻訳すると、この場合、GMNT は単語を単語のチャンクに分割し、その翻訳を復元しようとします。
しかし、なぜ「スタック」が「非常に速い」と翻訳されるのかはまだ説明できず、この翻訳が最近国内のエンジニアの間で広く広まっているジョークになっているとき、Googleが誇るクラウドソーシングによるエラー修正はまだこの問題にうまく介入していません。
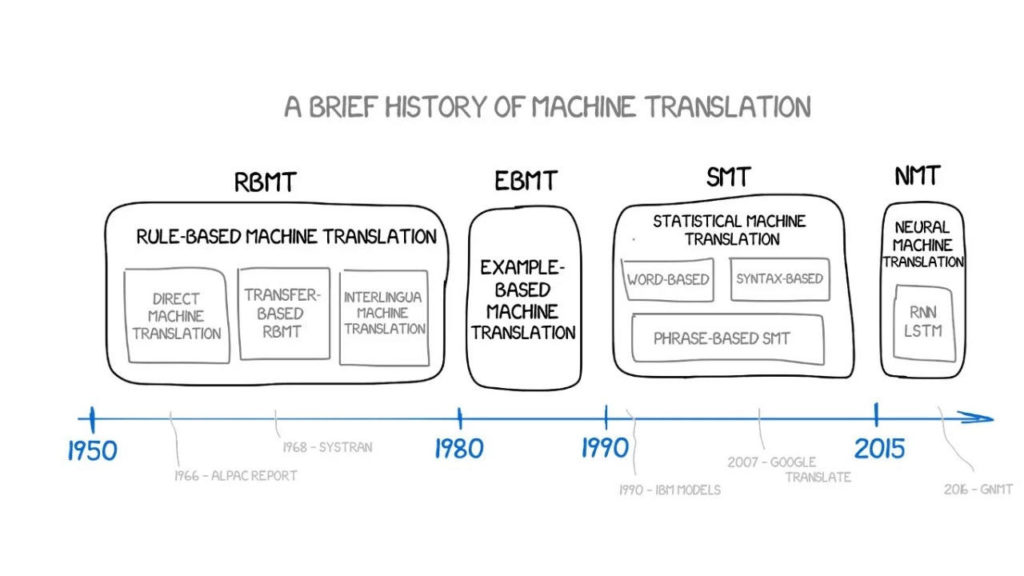
私たちが機械翻訳の研究を始めたいと思ったのは、このちょっとした冗談のせいです。この記事では、ルールベース機械翻訳 (RBMT)、インスタンスベース機械翻訳 (EBMT)、統計的機械翻訳 (SMT)、ニューラル機械翻訳 (NMT) など、過去 60 年間の機械翻訳の発展を概説します。他の主流の手法に加え、Google、Yandex、その他のメーカーの主要なアルゴリズムも分析に利用できます。
あなたはこの連載記事の前半「機械翻訳 1933-1984」を読んでいます。
最初の40年間はゆっくりとした進歩であった
機械翻訳は冷戦中の 1933 年に初めて登場しました。
当時、ソ連の科学者ピーター・トロヤンスキーは、ソ連科学アカデミーで「言語翻訳とテキストの印刷に使用できる機械の開発」を提案した。この機械の構造は非常にシンプルで、4 か国語のカード、タイプライター、そして昔ながらのムービーカメラだけでした。
オペレーターはテキストから最初の単語を取り出し、対応するカードを見つけて写真を撮り、その形態学的特徴 (名詞、複数形、属格など) をタイプライターで入力します。タイプライターはこれらの特徴の一部を翻訳し、テープやカメラのフィルムに記録しました。
")
たとえ簡単に翻訳できたとしても、当時はまだ「役に立たない」発明とみなされていました。残念なことに、トロヤンスキーはこの発明に 20 年を費やしましたが、最終的に狭心症で亡くなり、発明は終わりを迎えました。 1965 年にソ連の科学者がこの機械を発見するまでは、世界中でその存在をほとんど誰も知りませんでした。
冷戦が始まった 1954 年 1 月 7 日、史上初の本物の翻訳機 IBM701 がニューヨークの IBM 本社に登場しました。これは有名なジョージシティの IBM です。実験。
")
しかし、小さなディテールをカバーする完璧なギミックが存在します。翻訳された例が慎重に選択され、曖昧さを排除するためにテストされたことについては誰も言及しませんでした。日常的に使用する場合、このシステムは簡単な翻訳マニュアルと何ら変わりません。
それでも、現代の自然言語処理の基礎は、米国を含む科学者によって継続的な実験、研究、開発を通じて構築されています。今日の検索エンジン、スパム フィルター、パーソナル アシスタントはすべてこれに基づいています。
ルールベースの機械翻訳 (RBMT)
ルールベースの機械翻訳に関するアイデアは 1970 年代に初めて登場し、科学者が翻訳者の作業を注意深く観察し、コンピューターにこれらの動作を強制的に繰り返させようとしました。これらのシステムには次のものが含まれます。
-
対訳辞書 (RU -> EN)
-
各言語の一連の言語ルール (-heit、-keit、-ung などの特定の接尾辞が接尾辞として付けられた名詞など)。これが品詞の根元になります。
必要に応じて、システムは名前リスト、スペル修正ツール、音訳ツールなどのトリックを追加することもできます。
")
PROMPT と Systran は、いくつかのニュアンスや亜種はありますが、RBMT システムの最もよく知られた例です。
-
直接機械翻訳
これは最も単純なタイプの機械翻訳です。テキストを単語ごとに翻訳し、形態をわずかに修正し、文法を調和させて、段落全体がより正確に翻訳されたように見せます。これらの修飾ルールはすべて専門の言語学者によって設定されています。
ただし、これらの変換ルールが失敗し、翻訳が不十分になる場合があります。現代のシステムではこのルールはまったく使用されていませんが、現代の言語学者はこのルールを好んでいます。
")
-
文法構造ベースの機械翻訳
直訳と比較して、学校で先生が教えてくれたのと同じように、まず文の文法構造を決定します。次に、個々の単語ではなく全体の構造を分析します。これは、理論的には、翻訳時に適切な語順変換を実現するのに役立ちます。
ただし、実際には、このアプローチにはまだ限界があります。一般的な文法規則が簡素化される一方で、単一の単語に比べて単語構造が増加するため、翻訳はより複雑になります。
")
-
言語間機械翻訳
この方法では、原文が中間表現に変換され、すべてのエスペラント言語 (インターリングア) で統一されます。それはまさにデカルトが夢見ていたもの、つまり普遍的なルールに従い、翻訳を単純な「行ったり来たり」のタスクに変換するメタ言語です。これにより、interlingua はあらゆるターゲット言語を変換できるようになります。
この変換のため、インターリングアは転移ベースのメタ言語システムと混同されることがよくあります。違いは、言語ルールが言語のペアではなく、それぞれの言語と言語に固有であることです。これは、間言語システムに 3 番目の言語を追加し、3 言語間で変換できることを意味します。これは、文法構造に基づく翻訳システムでは実現が困難です。
")
完璧に見えますが、実際はそうではありません。この中間言語を作成することは非常に困難であり、多くの科学者が生涯をかけてこの言語の研究を行っています。それらは大成功とは言えませんでしたが、それらのおかげで、形態論的、構文的、さらには意味論的なレベルの表現が得られるようになりました。
")
ただし、RBMT には、形態学的正確さ (単語が混在しない)、結果の再現性 (すべての翻訳者が同じ結果を得る)、主題分野 (例: 経済学の科学者を教育する場合など) に適応させる能力などの利点もあります。または工学用語)。
たとえ誰かが理想的な RBMT の作成に成功し、言語学者がすべてのスペリング ルールを使用してそれを強化し続けたとしても、対処できない例外が常に存在します。たとえば、英語の不規則動詞、ドイツ語の分離可能な接頭辞、ロシア語の接尾辞、人々が自分自身を表現するさまざまな方法などです。
これらの微妙な違いを補ったり、修復したりする必要がある場合、その費用は非常に膨大になります。同音異義語について忘れないでください。つまり、同じ単語が異なる文脈では異なる意味を持つ可能性があり、同じ文が多数の翻訳される可能性があります。たとえば、私が「山で望遠鏡を使っている人を見た」と言ったとき、そこにはどのくらいの意味が含まれていると思いますか。
言語は一定の規則に基づいて発達するものではありません。これは言語学者が好む事実です。冷戦時代の 40 年間、機械翻訳は発展していましたが、翻訳の精度と利便性を向上させるための明確な解決策は見つかりませんでした。
したがって、RBMT はずっと前に冷え込んでいます。
用例ベースの機械翻訳 (EBMT)
1980年代、来るべきグローバル化への足場をできるだけ早く掴むために、英語を理解できる人がほとんどいなかった日本では、機械翻訳が急務となっていました。国策の強力な後押しもあり、日本は当時機械翻訳に最も関心のある国となった。
ルールベース機械翻訳 (RBMT) は、英日翻訳を行うのが難しく、翻訳プロセスではほぼすべての単語を並べ替える必要があり、また新しい単語も含まれるため、日本は新しい翻訳のアイデアを模索する必要があります。
")
そこで、1984 年に京都大学の長尾誠氏は、繰り返しの翻訳の代わりに既製のフレーズを使用するというアイデア、いわゆる用例ベースの機械翻訳 (EBMT) を提案しました。入力するケースの数が多いほど、翻訳はより速く、より正確になります。
EBMT のアイデアの出現は、科学者の革新的なインスピレーションを呼び起こす火のようなものでした。これは、革命的な取り組みとは程遠いものの、機械翻訳の開発にとって非常に重要です。しかし5年後にはこれをベースにした革新的な統計翻訳が登場するでしょう。
次の記事のプレビュー
-
1990 年代から 2000 年代の機械翻訳の時代は統計的機械翻訳 (SMT) が主流でした。
-
ニューラル機械翻訳 (NMT) は 2015 年についにデビューしました。
-
Google と Yandex 間の高度なゲームプレイ。
")
")
歴史記事(画像をクリックするとご覧いただけます)
")
「なぜ 10.24 がプログラマーの日なのですか?」 》
")
「この紙は有毒です!」 》
")
「人工知能を親戚や友人にどう説明するか?」 》
")
")








