Command Palette
Search for a command to run...
PipeTransformer: 大規模モデルの分散トレーニング用の自動化された弾性パイプライン

論文のタイトル:
PipeTransformer: 大規模モデルの分散トレーニングのための自動化された弾性パイプライン (PipeTransformer: 大規模モデルの分散トレーニングのための自動化された弾性パイプライン)
Pipeptransformer は、自動化された弾性パイプラインを使用して、Transformer モデルの効率的な分散トレーニングを実行します。 PipeTransformer では、トレーニング プロセス中に特定のレイヤーを徐々に識別してフリーズできる適応型動的フリーズ アルゴリズムを設計し、残りのアクティブなレイヤーをトレーニングするためにリソースを動的に割り当てることができるエラスティック パイプライン システムを設計しました。
具体的には、PipeTransformer は、パイプラインからフリーズしたレイヤーを自動的に除外し、アクティブなレイヤーをより少ない GPU にパックし、より多くのレプリカに分岐してデータの並列処理幅を増やします。
ViT (ImageNet データセットを使用) と BERT (SQuAD および GLUE データセットを使用) の評価では、PipeTransformer が精度を損なうことなく、最先端のベースラインと比較して最大 2.83 倍の高速化を達成することが示されています。
この文書には、ユーザーがアルゴリズムとシステム設計をより包括的に理解できるようにするためのさまざまなパフォーマンス分析も含まれています。
次に、この記事では、システムの研究背景、動機、設計思想、設計ソリューション、および PyTorch 分散 API を使用したアルゴリズムとシステムの実装方法を詳しく紹介します。
導入

大規模な Transformer モデルは、自然言語処理とコンピューター ビジョンの両方で精度の飛躍的な進歩を達成します。 GPT-3 は、ほとんどの NLP タスクで新しい高精度記録を樹立しました。 ImageNet では、Vision Transformer (略して ViT) も 89% のトップ 1 の精度を達成し、そのパフォーマンスは最先端の畳み込みネットワーク ResNet-152 や EfficientNet よりも優れていました。
増大するモデルの問題に対処するために、研究者は、パラメーター サーバー、パイプライン並列処理、層内並列処理、ゼロ冗長データ並列処理など、さまざまな分散トレーニング テクノロジを提案してきました。
ただし、既存の分散トレーニング ソリューションは単なる研究シナリオであり、すべてのモデルの重みはトレーニング プロセス中に最適化する必要があります (つまり、計算と通信のオーバーヘッドは、さまざまな反復中に比較的安定していなければなりません)。プログレッシブ トレーニングに関する最近の研究では、ニューラル ネットワークのパラメーターを動的にトレーニングできることが示されています。
- 深層学習のダイナミクスと解釈性のための特異ベクトル正準相関分析 NeurIPS 2017。
- ICML 2019 のプログレッシブスタッキングによる効率的な BERT トレーニング。
- プログレッシブ レイヤ ドロップによるトランスフォーマー ベースの言語モデルのトレーニングの高速化。
- プログレッシブ BERT トレーニング 2021 のトランスフォーマーの成長について。

図 2: 解釈可能なフリーズ トレーニング: DNN ボトムアップ コンバージェンス (結果は ResNet を使用した CIFAR10 でテスト) 各ペインには SVCCA を介した各レイヤーの類似性が表示されます。
たとえば、フリーズ トレーニングでは、ニューラル ネットワークは通常、ボトムアップで収束します (つまり、特定の結果を得るためにすべての層をトレーニングする必要があるわけではありません)。
上の画像は、同様のアプローチでトレーニング中にウェイトが徐々に安定する様子の例を示しています。これに基づいて、Transformer モデルの分散トレーニングにはフリーズ トレーニングを活用し、減らされたアクティブ レイヤーのセットに集中するようにリソースを動的に割り当てることでトレーニングを加速します。
この層のフリーズ戦略は、パイプラインの並列処理に特に適しています。これは、パイプラインから連続する最下層を除外することで、計算、メモリ、通信のオーバーヘッドを削減できるためです。
図 3: PipeTransformer の自動化と弾力性のあるパイプライン プロセスにより、Transformer モデルの分散トレーニングが加速されます。
PipeTransformer は、パイプライン モデルのスコープとパイプライン レプリカの数を動的に変換することで、フリーズしたレイヤーに自動的に反応できる弾性パイプライン トレーニング アクセラレーション フレームワークです。
私たちの知る限り、これはパイプラインとデータ並列トレーニングのコンテキストでレイヤーのフリーズを研究した最初の論文です。
図 3 は、この組み合わせの利点を示しています。
まず、パイプラインからフリーズしたレイヤーを除外することで、同じモデルをより少ない数の GPU にパックできるため、GPU 間の通信が減り、パイプライン バブルが小さくなります。
次に、モデルをより少ない GPU にカプセル化した後、同じクラスターにより多くのパイプライン コピーを収容できるため、データの並列処理の幅が広がります。
さらに重要なことは、2 つの利点が加算されるのではなく相乗され、トレーニングの進行がさらに加速されることです。
PipeTransformer の設計は 4 つの大きな課題に直面しています。
まず、凍結アルゴリズムは動的かつ適応的な凍結決定を行う必要がありますが、既存の研究では事後分析ツールしか提供されていません。
次に、パイプラインの再パーティション化の効率は、パーティションの粒度、パーティション間のアクティブ化サイズ、小さなバッチの数など、多くの要因によって影響を受けます。これには、ソリューション空間での大規模な推論と検索が必要です。
次に、パイプラインの追加コピーを動的に導入するために、PipeTransformer は集団通信の静的な性質を克服し、新しいプロセスがオンラインになったときに複雑になる可能性のあるクロスプロセス メッセージング プロトコル (パイプラインは 1 つのプロセスのみで処理できる) を回避する必要があります。
最後に、キャッシュによってフリーズ レイヤーの繰り返しの前方伝播にかかる時間を節約できますが、システムはコピーごとに専用のキャッシュを作成してウォームアップできないため、既存のパイプラインと新しく追加されたパイプラインの間でキャッシュを共有する必要があります。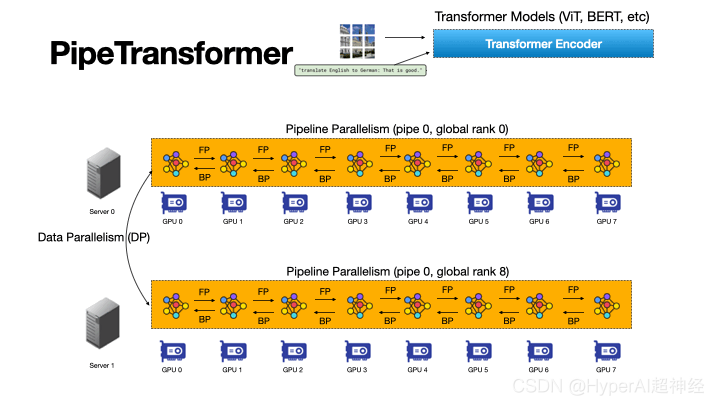
図 4: PipeTransformer のダイナミクス図
図 4 に示すように、上記の課題に対処するには、PipeTransformer の設計は 4 つのコア構成要素で構成されています。
1 つ目は、さまざまな反復でフリーズ層の選択をガイドする信号を生成する調整可能な適応アルゴリズム (フリーズ アルゴリズム) です。これらの信号によってトリガーされると、エラスティック パイプライン モジュール (AutoPipe) は、異種パーティション (凍結層とアクティブ層) のアクティブ サイズとワークロードの変化を評価することにより、残りのアクティブ層をより少ない GPU にパックします。
次に、さまざまなパイプライン長に関する以前の分析結果に基づいて、ミニバッチが一連のより適切なマイクロバッチに分解されます。
次のモジュールである AutoDP は、追加のパイプライン コピーを生成して解放された GPU を占有し、階層通信プロセス グループを維持して集合通信の動的なメンバーシップを取得します。
最後のモジュールである AutoCache は、既存のデータと新しいデータの並列プロセス間でアクティベーションを効率的に共有し、変換中に古いキャッシュを自動的に置き換えます。
全体として、PipeTransformer は、フリーズ アルゴリズム、AutoPipe、AutoDP、および AutoCache モジュールを組み合わせて、トレーニングを大幅に高速化します。
ViT (ImageNet データセットを使用) モデルと BERT (SQuAD および GLUE データセットを使用) モデルを使用して PipeTransformer を評価しました。その結果、PipeTransformer は精度を損なうことなく、最先端のベースラインと比較して最大 2.83 倍のパフォーマンスを達成できることがわかりました。速度増加。
また、設計のアルゴリズムおよびシステムの側面をより包括的に理解できるように、さまざまなパフォーマンス分析も提供します。最後に、私たちは、フリーズ アルゴリズム、モデル定義、トレーニング アクセラレーションを明確に分離し、同様のフリーズ戦略を必要とするアルゴリズムへの移行を可能にする、PipeTransformer 用のオープン ソースの柔軟な API を開発しました。
全体的なデザイン
私たちの目標は、分散トレーニング システムで大規模モデルをトレーニングすることだとします。このシステムは、パイプライン モデルの並列処理とデータの並列処理を組み合わせたもので、次のシナリオの処理に使用できます。
モデルが単一の GPU デバイスのメモリに収まらないか、メモリの枯渇を避けるためにロード時のバッチ サイズが小さくなっています。具体的には、次のような設定が定義されています。
- トレーニング タスクとモデルの定義。 大規模な画像またはテキスト データ セットで Transformer モデル (Vision Transformer、BERT など) をトレーニングします。 Transformer モデル mathcalF には合計 L 層があり、そのうち i 番目の層は順計算関数 fi と対応するパラメーターのセットで構成されます。
- トレーニングインフラストラクチャ。 トレーニング インフラストラクチャが N 個の GPU サーバー (ノード) を備えた GPU クラスターで構成されていると仮定します。各ノードには I 個の GPU があります。クラスターは同種です。これは、各 GPU とサーバーのハードウェア構成が同一であることを意味します。各GPUのメモリ容量はMGPUです。サーバーは、高帯域幅ネットワーク インターフェイス (InfiniBand など) を介して相互に接続されます。
- パイプラインの並列処理。 各マシンで、モデル F を K 個のパーティションを持つパイプラインにロードします (K はパイプラインの長さも表します)。 k 番目のパーティションは Pk 個の連続したレイヤーで構成されます。各パーティションは GPU デバイスによって処理されることが想定されています。 1≤K≤I は、単一デバイス上で複数のモデルのコピーに対して複数のパイプラインを構築できることを意味します。
パイプライン上のすべての GPU デバイスが同じマシンに属し、パイプラインが同期パイプラインであり、期限切れのグラジエントを含まず、マイクロバッチの数が M であると仮定します。 Linux オペレーティング システムでは、各パイプラインはプロセスによって処理されます。詳細については、GPipe を参照してください。
- データの並列処理。 DDP は、R 並列ワーカー内のクロスマシン分散データ並列処理グループです。各ワーカーはパイプライン (単一プロセス) のコピーです。 r 番目の Worker のインデックス (ID) はレベル r です。
DDP の 2 つのパイプラインは、同じ GPU サーバーまたは異なる GPU サーバーに属することができ、AllReduce アルゴリズムを使用してグラデーションを交換することもできます。
このような場合、トレーニング プロセス全体を通じてすべてのレイヤーをトレーニングする必要がなくなる、フリーズ トレーニングを利用してトレーニングを高速化することを目指しています。
さらに、これは計算、通信、メモリの損失を節約し、連続したフリーズ層によって引き起こされる過剰適合をある程度回避するのにも役立ちます。
ただし、これらの利点を活用するには、前述の 4 つの課題、つまり、適応フリーズ アルゴリズムの設計、動的なパイプラインの再分割、効率的なリソースの再割り当て、およびクロスプロセス キャッシュを克服する必要があります。
図 5: PipeTransformer トレーニング システムの概要
PipeTransformer は、パイプライン モデルの範囲とパイプライン レプリカの数を動的に変換できる、オンザフライ フリーズ アルゴリズムと自動エラスティック パイプライン トレーニング システムを共同設計します。全体的なシステム アーキテクチャを図 5 に示します。
PipeTransformer の弾性パイプラインをサポートするために、PyTorch Pipeline のカスタマイズされたバージョンを維持しています。データの並列処理には、ベースラインとして PyTorch DDP を使用します。他のライブラリはオペレーティング システムの標準メカニズム (マルチプロセッシングなど) であるため、ソフトウェアやハードウェアをカスタマイズする必要もありません。
フレームワークの普遍性を確保するために、トレーニング システムを 4 つのコア コンポーネント (フリーズ アルゴリズム、AutoPipe、AutoDP、および AutoCache) に分離しました。
フリーズ アルゴリズム (灰色の部分) はトレーニング ループからメトリクスをサンプリングし、レイヤーごとにフリーズ決定を行います。これは AutoPipe (緑色の部分) と共有されます。
AutoPipe は、パイプラインからフリーズしたレイヤーを除外し、アクティブなレイヤーを少数の GPU (ピンク色の部分) にパックすることでトレーニングを高速化するエラスティック パイプライン モジュールです。これにより、GPU 間の通信が削減され、パイプラインのストールが小さく抑えられます。
その後、AutoPipe はパイプラインの長さの情報を AutoDP (紫色の部分) に渡し、可能な場合にはさらに多くのパイプラインのコピーを生成して、データの並列処理の幅を増やします。
この図には、AutoDP が新しいレプリカ (紫色) を導入する例も含まれています。 AutoCache (オレンジ色の下線部分) は、クロスパイプライン キャッシュ モジュールです。読みやすさと汎用性を考慮して、ソース コード アーキテクチャは図 5 と一致しています。
PyTorch APIを使用して実装
図 5 からわかるように、PipeTransformer には、Freeze Algorithm、AutoPipe、AutoDP、および AutoCache の 4 つのコンポーネントが含まれています。
このうち、AutoPipe と AutoDP はそれぞれ PyTorch DDP (torch.nn.Parallel.DistributedDataParallel) とパイプライン (torch.distributed.pipeline) に依存します。
このブログでは、AutoPipe と AutoDP の主要な実装の詳細のみを取り上げます。凍結アルゴリズムと AutoCache の詳細については、論文を参照してください。
AutoPipe: 弾力性のあるパイプライン
AutoPipe は、パイプラインからフリーズしたレイヤーを除外し、アクティブなレイヤーをより少ない GPU に圧縮することで、トレーニングを高速化できます。このセクションでは、AutoPipe の主要コンポーネントについて詳しく説明します。
1) 動的パーティションパイプライン。
2) パイプライン設備の数を減らす。
3) ミニバッチのチャンク サイズをそれに応じて最適化します。
PyTorch パイプラインの基本的な使用法
AutoPipe の詳細を掘り下げる前に、まず PyTorch Pipeline (torch.distributed.pipeline.sync.Pipe) の基本的な使用方法を理解しましょう。
実際のパイプライン設計を理解するには、次の簡単な例を参照してください。
# Step 1: build a model including two linear layers
fc1 = nn.Linear(16, 8).cuda(0)
fc2 = nn.Linear(8, 4).cuda(1)
# Step 2: wrap the two layers with nn.Sequential
model = nn.Sequential(fc1, fc2)
# Step 3: build Pipe (torch.distributed.pipeline.sync.Pipe)
model = Pipe(model, chunks=8)
# do training/inference
input = torch.rand(16, 16).cuda(0)
output_rref = model(input)この簡単な例では、Pipe を初期化する前に、モデル nn.Sequential を複数の GPU デバイスに分割し、最適なチャンク数を設定する必要があることがわかります。
ステージ間でワークロードが不均一に分散されると遅延が発生し、ワークロードの低いデバイスが待機せざるを得なくなる可能性があるため、パーティション間で計算のバランスを取ることはパイプライン トレーニングの速度にとって重要です。チャンクの数も、パイプラインのスループットに非常に大きな影響を与える可能性があります。
バランスの取れたパイプラインゾーン
PipeTransformer などの動的トレーニング システムでは、各パーティションには同じ数のパラメーターしかなく、最速のトレーニング速度が保証されるわけではありません。他の要因も重要な役割を果たします。
図 6: パーティション境界はスキップ接続の中央にあります
1. パーティション間の通信オーバーヘッド。 スキップ接続の途中にパーティション境界を配置すると、スキップ接続内のテンソルを別の GPU にコピーする必要があるため、追加の通信が作成されます。
たとえば、図 6 の BERT パーティションの場合、パーティション k はパーティション k-2 とパーティション k-1 から中間出力を取得する必要があります。対照的に、境界が追加層の後に配置される場合、パーティション k-1 とパーティション k の間の通信オーバーヘッドは大幅に小さくなります。
測定によると、クロスデバイス通信は、軽度に不均衡なパーティションよりもコストがかかるため、スキップ接続の切断は考慮していません。
2. レイヤーのメモリ使用量をフリーズします。 トレーニング中、AutoPipe は 2 つの異なるタイプのレイヤー (フリーズ層とアクティブ層) のバランスを取るためにパーティション境界を複数回再計算する必要があります。
フリーズ レイヤーには後方アクティブ化マップ、オプティマイザーの状態、および勾配が必要ないため、フリーズ レイヤーのメモリ コストは非アクティブ レイヤーのメモリ コストの数分の 1 になります。
メモリとコンピューティングのコストの基本的な指標を取得するために侵入型プロファイラーを起動する代わりに、同じアクティブ レイヤーに対してフリーズされたレイヤーのメモリ使用量を評価するための調整可能なコスト係数 lambdafrozen を定義します。実験用ハードウェアでの経験的な測定に基づいて、1/6 に設定しました。
上記 2 つの点に基づいて、AutoPipe はパラメータ サイズに基づいてパイプライン パーティションのバランスをとることができます。具体的には、AutoPipe は貪欲なアルゴリズムを使用してフリーズ レイヤーとアクティブ レイヤーを割り当て、パーティションのサブレイヤーを K 個の GPU デバイス間で均等に分散できるようにします。
疑似コードは、アルゴリズム 1 のload_balance() 関数です。フリーズ レイヤーは元のモデルから抽出され、パイプラインの最初のデバイスの別のモデル インスタンス Ffrozen に保存されます。
この記事で使用されているセグメンテーション アルゴリズムが唯一のオプションではないことに注意してください。PipeTransformer はモジュール式であり、任意の代替手段と組み合わせて実行できます。
パイプライン圧縮
パイプライン圧縮により、GPU が解放されてより多くのパイプライン コピーに対応できるようになり、パーティション間のクロスデバイス通信の量が削減されます。圧縮時間を決定するには、圧縮後の最大パーティションのメモリ消費量を推定し、それをタイムステップ T=0 でのパイプラインの最大パーティションのメモリ消費量と比較します。
大規模なメモリ プロファイリングを回避するために、圧縮アルゴリズムはメモリ使用量をトレーニングするためのプロキシとしてパラメータ サイズを使用します。この単純化に基づいて、パイプライン圧縮の基準は次のようになります。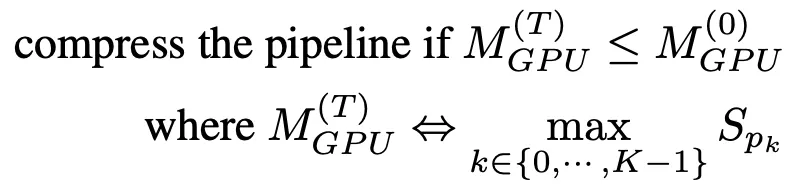
フリーズ通知を受信すると、AutoPipe はパイプラインの長さ K を 2 で除算しようとします (たとえば、8 から 4、次に 2)。 K/2 を入力することで、圧縮アルゴリズムは圧縮結果が式 (1) の基準を満たしているかどうかを検証できます。
擬似コードはアルゴリズム 1 の 25 ~ 33 行目に示されています。この圧縮により、トレーニング中の速度向上が指数関数的に増加することに注意してください。つまり、GPU サーバーにさらに多くの GPU (たとえば 8 つ以上) が含まれている場合、速度向上はさらに増加します。 図 7: パイプライン バブル
図 7: パイプライン バブル
Fd、b、および Ud は、それぞれデバイス d 上の micro=batch b の順方向、逆方向、およびオプティマイザの更新を表します。
各反復の合計バブル サイズは、マイクロ = バッチあたりの前方および後方コストの K-1 倍です。
さらに、この手法では、パイプライン バブルのサイズを小さくすることでトレーニングを高速化できます。パイプライン内のバブル サイズを説明するために、図 7 は 4 つのデバイス パイプライン K=4 で 4 つのマイクロバッチがどのように実行されるかを示しています。
一般に、バブルの合計サイズは、各マイクロバッチの前後の消費量の K-1 倍になります。したがって、パイプラインが短いほどバブル サイズも小さくなるのは明らかです。
マイクロバッチの動的数
以前のパイプライン並列システムでは、ミニバッチ (M) ごとに固定数のマイクロバッチが使用されていました。 GPipe は M≥4 x K を推奨します。ここで、K はパーティションの数 (パイプラインの長さ) です。ただし、PipeTransformer が K を動的に構成することを考慮すると、トレーニング中に M を静的に保つのは効果的ではないことがわかります。
さらに、DDP と統合する場合、M の値は DDP 勾配同期の効率にも影響します。 DDP は、勾配同期の前に最後のマイクロバッチが特定のパラメーターの逆方向計算を完了するまで待機する必要があるため、マイクロバッチが薄くなるほど、計算と通信の重複が少なくなります。
したがって、PipeTransformer は静的な値を使用せず、K-6K の範囲で M の値を列挙することによって、DDP 環境のハイブリッドで最適な M 値を動的に検索します。特定のトレーニング環境の場合、プロファイリングは 1 回だけ実行する必要があります (アルゴリズム 1 の 35 行目を参照)。
AUTODP: パイプラインのコピーをさらに生成します
AutoPipe が同じパイプラインをより少ない GPU に圧縮できることを考慮すると、AutoDP は新しいパイプラインのコピーを自動的に生成して、データの並列処理の幅を増やすことができます。
概念的には単純ですが、通信と状態への依存関係は微妙であり、慎重な設計が必要です。潜在的な課題は主に 3 つあります。
1.DDP通信: PyTorch DDP の集団通信には静的メンバーシップが必要です。これにより、新しいパイプラインが既存のパイプラインに接続できなくなります。
2. ステータスの同期: 新しくアクティブ化されたプロセスは、トレーニング プロセス (エポック番号や学習率など)、重みとオプティマイザーのステータス、フリーズ層の境界、パイプラインの GPU 範囲の点で既存のパイプラインと一致している必要があります。
3. データセットの再配布: パイプラインの動的な数に一致するようにデータ セットを再バランスする必要があります。これにより、遅れを避けるだけでなく、すべての DDP プロセスの勾配が均等に重み付けされるようになります。
図 8: AutoDP: 2 つのプロセス グループ間の情報を利用して動的データの並列処理を処理する
注: プロセス 0 ~ 7 はマシン 0 に属し、プロセス 8 ~ 15 はマシン 1 に属します。
これらの課題に対処するために、DDP 用のデュアル通信プロセス グループを作成しました。図 8 に示すように、情報プロセス グループ (紫色) は軽量の制御情報を担当し、すべてのプロセスをカバーしますが、アクティブなトレーニング プロセス グループ (黄色) にはアクティブなプロセスのみが含まれ、トレーニング中の重量級テンソル通信のツールとして機能します。
情報セットは静的ですが、トレーニング セットはアクティブなプロセスに一致するように分割および再構築されます。 T0 では、プロセス 0 と 8 のみがアクティブです。 T1 への移行中に、プロセス 0 はプロセス 1 と 9 (新しく追加されたパイプライン コピー) をアクティブ化し、情報グループを使用して上記の必要な情報を同期します。
次に、4 つのアクティブなプロセスが新しいトレーニング グループを形成し、静的な集団コミュニケーションを動的なメンバーに適応させます。データセットを再配布するために、アクティブなパイプライン レプリカの数に一致するようにデータ サンプリングをシームレスに調整する DistributedSampler 変数を実装しました。
上記の設計により、DDP の通信ロスが軽減されます。より具体的には、T0 から T1 に移行するとき、プロセス 0 と 1 は既存の DDP インスタンスを破棄することができ、アクティブなプロセスはキャッシュされたパイプライン モデルを使用して新しい DDP トレーニング グループを構築します (AutoPipe は凍結されたモデルとキャッシュされたモデルをそれぞれ保存します)。
上記の操作を実現するために、次の API を使用します。
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
# initialize the process group (this must be called in the initialization of PyTorch DDP)
dist.init_process_group(init_method='tcp://' + str(self.config.master_addr) + ':' +
str(self.config.master_port), backend=Backend.GLOO, rank=self.global_rank, world_size=self.world_size)
...
# create active process group (yellow color)
self.active_process_group = dist.new_group(ranks=self.active_ranks, backend=Backend.NCCL, timeout=timedelta(days=365))
...
# create message process group (yellow color)
self.comm_broadcast_group = dist.new_group(ranks=[i for i in range(self.world_size)], backend=Backend.GLOO, timeout=timedelta(days=365))
...
# create DDP-enabled model when the number of data-parallel workers is changed. Note:
# 1. The process group to be used for distributed data all-reduction.
If None, the default process group, which is created by torch.distributed.init_process_group, will be used.
In our case, we set it as self.active_process_group
# 2. device_ids should be set when the pipeline length = 1 (the model resides on a single CUDA device).
self.pipe_len = gpu_num_per_process
if gpu_num_per_process > 1:
model = DDP(model, process_group=self.active_process_group, find_unused_parameters=True)
else:
model = DDP(model, device_ids=[self.local_rank], process_group=self.active_process_group, find_unused_parameters=True)
# to broadcast message among processes, we use dist.broadcast_object_list
def dist_broadcast(object_list, src, group):
"""Broadcasts a given object to all parties."""
dist.broadcast_object_list(object_list, src, group=group)
return object_list実験部分
このセクションでは、最初に実験セットアップを要約し、次にコンピューター ビジョンおよび自然言語処理タスクにおける PipeTransformer のパフォーマンスを評価します。
ハードウェア。 実験は、InfiniBand CX353A (GB/s) で接続された 8 台の NVIDIA Quadro RTX 5000 (16GB GPU メモリ) を搭載した 2 台の同一のマシンで実施されました。マシンの GPU 間の帯域幅 (PCI 3.0、16 レーン) は 15.754GB/s です。
成し遂げる。 構築ブロックとして PyTorch Pipe を使用します。 BERT モデルの定義、構成、および関連するトークナイザーはすべて HuggingFace 3.5.0 からのものです。 PyTorch の TensorFlow 実装を通じて Vision Transformer を実装しました。
モデルとデータセット。 実験では、CV と NLP の分野における 2 つの代表的な Transformer モデル、Vision Transformer (ViT) と BERT を使用しました。 ViT は、初期化時に ImageNet21K で事前トレーニングされた重みを使用して画像分類タスクに適用され、ImageNet と CIFAR-100 で微調整されます。 BERT は 2 つのタスクで実行されます。1 つは一般言語理解評価 (GLUE) ベンチマークの SST-2 データセットでのテキスト分類、もう 1 つは SQuAD v1.1 データセット (スタンフォード質問応答) でのインテリジェントな質問応答です。 SQuAD v1.1 データセットには、クラウドソーシングされた 100,000 の質問と回答グループが含まれています。
トレーニング計画。 大規模なモデルは通常、数千 GPU 日 (\emph{例}、GPT-3) を必要とし、ゼロからトレーニングする場合、事前トレーニングされたモデルを利用して下流のタスクを微調整することが CV および NLP 分野のトレンドになっています。 。さらに、PipeTransformer は、複数のコア コンポーネントが関与する複雑なトレーニング システムです。したがって、PipeTransformer の最初のバージョンのシステム開発およびアルゴリズム研究では、大規模な事前トレーニングを使用して最初から開発および評価することが非常にコスト効率が高くなります。したがって、このセクションで説明する実験は、事前トレーニングされたモデルに焦点を当てています。事前トレーニングと微調整のモデル アーキテクチャは同じであるため、PipeTransformer は両方の要件を満たすことができることに注意してください。事前トレーニングの結果については付録で説明します。
ベースライン。 このセクションの実験では、PipeTransformer、最も先進的なフレームワークである PyTorch Pipeline (PyTorch の GPipe 実装)、および PyTorch DDP の 3 つのソリューションを水平方向に比較します。これは、層をフリーズすることによる分散トレーニングの高速化を調査した最初の論文であるため、完全に一貫した対応するソリューションはありません。
ハイパーパラメータ。 データセット ImageNet および CIFAR-100 の場合、実験では ViT-B/16 が使用されました (トランスフォーマー層番号は 12、入力パッチ サイズは 16 x 16)。 SQuAD 1.1 の場合、実験では BERT-large-uncased (24 レイヤー) が使用されました。 SST-2 は BERT-base-uncased (12 層) を使用します。 PipeTransformer を通じて、ViT トレーニングと BERT トレーニングは per=pipeline のバッチ サイズをそれぞれ約 400 と 64 に設定できます。他のハイパーパラメータ (エポック、学習率など) については、付録を参照してください。
全体加速トレーニング
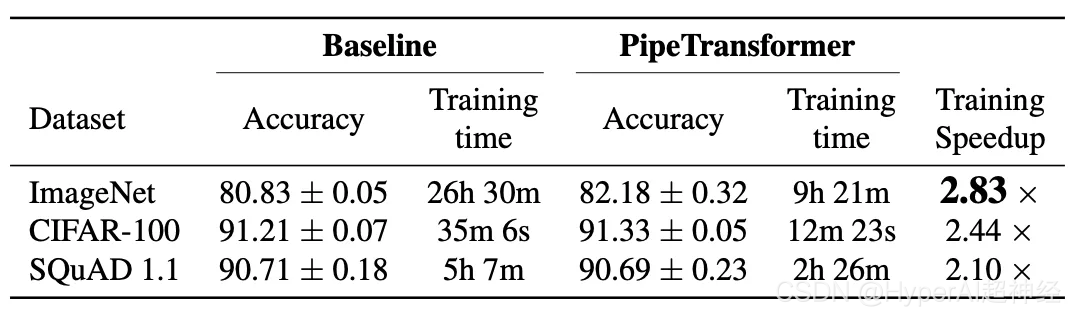
上の表は全体的な実験結果をまとめたものです。ここでの高速化は保守的な値に基づいていることに注意してください。(1/3)、この値は同等またはさらに高い精度を達成できます。値が(2/5、1/2) を使用すると高速化が可能になりますが、精度がわずかに低下します。また、BERT(24層)はViT-B/16(12層)よりも容量が大きいため、通信時間が長くなります。
パフォーマンス分析
速度向上率の内訳
このセクションでは、評価結果を示し、/AutoPipe のさまざまなコンポーネントのパフォーマンスを分析します。
これら 4 つのコンポーネントの有効性とトレーニング速度への影響を理解するために、さまざまな組み合わせで実験を実施し、トレーニング サンプルのスループット (サンプル/秒) と高速化率を指標として使用しました。結果を図 9 に示します。実験結果から得られる重要な点は次のとおりです。
1. 主な加速率は、AutoPipe と AutoDP によって共同実装された弾性パイプラインの結果です。
2. AutoCache の役割は AutoDP によって強化されます。
3. フリーズトレーニングは、システムの調整やトレーニングの速度低下なしで、独立して実行されます。
フリーズアルゴリズムで a を調整する

図 10: フリーズ アルゴリズムの調整 a
フリーズ アルゴリズムがトレーニング速度にどのような影響を与えるかを説明するために、いくつかの実験を実施しました。結果は、a (過剰なフリーズ) が大きいほど高速化率は大きくなりますが、パフォーマンスが若干低下することがわかります。図 10 に示す例では、a=1/5 の場合、フリーズ トレーニングの効果は通常のトレーニングよりも優れており、加速比は 2.04 に達します。
エラスティック パイプライン内の最適なチャンク数

図 11: エラスティック パイプラインの最適なチャンク数
さまざまなパイプライン長 K に対する最適なマイクロバッチ数 M を分析しました。結果を図 11 に示します。見てわかるように、K の値が異なると、それに応じて最適な数 M も変化します。M の値が異なると、スループット ギャップも大きくなります (K=8 の場合の図に示すように)。また、弾性パイプラインで前方プロファイラーを使用する必要性も確認しています。
キャッシュのタイミングを理解する

図 12: キャッシュのタイミング
AutoCache を評価するために、AutoCache を使用したエポック 0 から開始するトレーニング タスク (青線) と、AutoCache を使用しないトレーニング タスク (赤線) のサンプル スループットを比較しました。
図 12 は、キャッシュを有効にするのが早すぎると、少数のフリーズ層での順伝播よりもコストがかかるため、トレーニングの速度が低下することを示しています。より多くのレイヤーをフリーズした後、キャッシュのアクティブ化は、対応する前方パスよりも大幅にパフォーマンスが向上します。したがって、AutoCache はプロファイラーを使用して、キャッシュを有効にする正しい時間を決定します。
私たちのシステムでは、キャッシュは ViT (12 レイヤー) の場合は 3 番目のフリーズ層から、BERT (24 レイヤー) の場合は 5 番目のフリーズ層から始まります。
要約する
この記事では、PyTorch 分散 API を使用した分散トレーニング用の弾性パイプライン並列処理とデータ並列処理を組み合わせた総合的なソリューションである PipeTransformer を紹介します。
具体的には、PipeTransformer はパイプライン内のレイヤーを段階的にフリーズし、残りのアクティブなレイヤーをより少ない GPU にパックし、より多くのパイプライン コピーをフォークしてデータの並列処理幅を増やすことができます。 ViT および BERT モデルの評価では、PipeTransformer が精度を損なうことなく、最先端のベースラインと比較して 2.83 倍の高速化を達成していることが示されています。








