Command Palette
Search for a command to run...
DALL-E の論文を読んだ後、大規模なデータ セットにも代替バージョンがあることがわかりました。

OpenAI チームの新しいモデル DALL-E が登場しました。この新しいニューラル ネットワークは、「特別なトレーニング」を経て、任意の説明テキストを入力すると、対応する画像を生成できます。現在、チームはプロジェクトの論文とモジュール コードの一部をオープン ソースにし、このアーティファクトの背後にある原理を理解できるようにしました。
今年の初めに、OpenAI は、自然言語と画像の間の次元の壁を完全に打ち破った画像生成モデル DALL-E をリリースしました。
テキストの説明がどれほど誇張されているか非現実的であっても、それが DALL-E に入力されると、対応する画像が生成され、その効果は技術界全体に驚異的です。

力強い努力が奇跡を生む: 錬金術の世界におけるコストの上限
計算能力: 1024 ブロック V 100
モデルが公開されるとすぐに、開発者はモデルの背後にある実装プロセスについて推測し、公式論文を楽しみにしていました。最近、DALL-E の論文とその実装コードの一部がついに公開されました。

論文アドレス: https://arxiv.org/abs/2102.12092
案の定、一部の開発者の以前の推測と一致して、大手メーカーである OpenAI は再びその強力な「マネー機能」を実証しました。この論文では、トレーニング全体で合計 1,024 個の 16GB NVIDIA V100 GPU を使用したことが明らかになりました。
コードに関しては、公式は現在、画像再構成用の dVAE モジュールのみを開きます。このモジュールの目的は、テキスト画像生成タスクでトレーニングされた Transformer のメモリ占有量を削減することです。 Transformerのコード部分はまだ公開されていないので、今後のアップデートに期待するしかありません。ただし、コードを使用しても、誰もがこの GPU 使用率を再現できるわけではありません。
データセット: 2 億 5,000 万の画像とテキストのペア + 120 億のパラメータ
論文の中で、OpenAI チームは、機械学習合成手法を使用してテキストから画像への変換を実現する関連研究が 2015 年に開始されたことを紹介しました。
しかし、これらの先行研究で提案されたモデルは、テキストから画像への生成を実行することはできたものの、その生成結果には、オブジェクトの変形、不合理なオブジェクトの配置、前景要素と背景要素の不自然な混合など、依然として多くの問題が残されています。

研究の結果、チームは以前の研究が通常、より小規模なデータセット (MS-COCO や CUB-200 など) で評価されていたことを発見しました。これに基づいて、チームは次のアイデアを提案しました。データセットのサイズとモデルのサイズが現在の手法の開発を制限する要因である可能性はありますか?
したがって、チームはこれを突破口として利用しました、2 億 5,000 万の画像とテキストのペアを含むデータセットがインターネットから収集されました。このデータセットで 120 億のパラメーターを使用して自己回帰 Transformer をトレーニングします。
さらに、この論文では、dVAE モデルのトレーニングが共通することを紹介しています。 64 個の 16GB NVIDIA V100 GPU、判別モデルCLIPを合計で使用 256 個の GPU がトレーニング済み 14 空。
集中的なトレーニング (shao) (qian) を経て、チームは最終的に、自然言語で制御できる柔軟で現実的な画像生成モデル DALL-E を取得しました。
チームは、DALL-E モデルと他のモデルによって生成された結果を比較および評価しました。その結果は次のとおりです。90% の場合、DALL-E の生成結果は以前の研究よりも良好でした。

写真とテキストがデータセットに相当するのでおいしい
DALL-E モデルの成功は、モデルの大規模なトレーニング データの重要性も証明しています。
民間の錬金術師が DALL-E と同じデータセットを望む場合、それを入手するのは難しいかもしれませんが、大手ブランドには代替バージョン (手頃な価格の代替バージョン) があります。
OpenAI は、トレーニング データセットはまだ公開されないと述べていますが、ただし、このデータセットには、Google が公開した Conceptual Captions データセットが含まれていることを明らかにしました。
大規模な画像とテキストのペア データ セット ミニ代替バージョン
概念キャプション データセット。ACL 2018 で公開された論文「Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning」で Google によって提案されました。

この論文はデータとモデリングの分類の両方に貢献します。初め、チームは、新しい画像キャプション アノテーション データ セットである Conceptual Captions を提案しました。これには、MS-COCO データ セットよりも桁違いに多くの画像が含まれており、合計約 330 万の画像と説明のペアが含まれています。
概念的なキャプション(概念的なタイトル)データセットの詳細
データソース:Google AI
発売時期:2018年
含まれる数量:330万の画像とテキストのペア
データ形式:.tsv データサイズ:1.7GB
ダウンロードアドレス:https://orion.hyper.ai/datasets/14682
ResNet+RNN+Transformer を使用して逆 DALL-E を作成する
モデリングに関しては、これまでの研究結果を踏まえ、チームは、Inception-ResNet-v2 を使用して画像の特徴を抽出し、RNN と Transformer に基づくモデルを使用して画像のキャプションを生成しました (DALL-E はテキスト説明から画像を生成し、Conceptual Captions は画像からテキスト注釈を生成します)。
このデータセットを生成するために、チームは、約 10 億のインターネット Web ページを並行して処理する Flume パイプラインから開始し、これらの Web ページから候補となる画像とキャプションのペアを抽出、フィルタリング、処理し、いくつかのフィルターを通過したものをタイトルとともに保持しました。
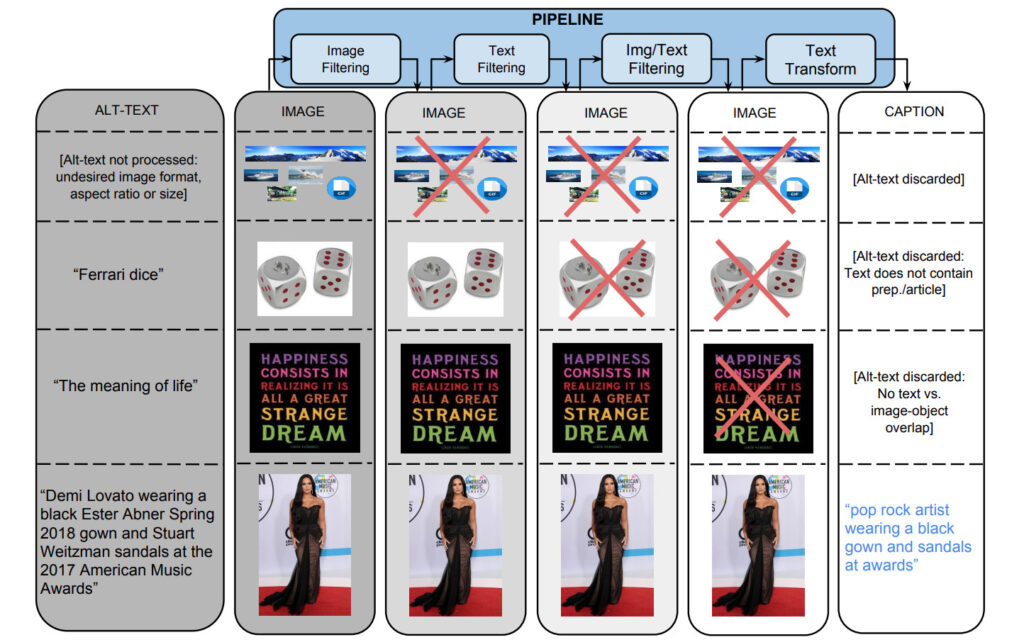
1: 画像ベースのフィルタリング
アルゴリズムは、エンコード形式、サイズ、アスペクト比、および不快なコンテンツに基づいて画像をフィルタリングします。両次元で 400 ピクセルを超える JPEG 画像のみが保存され、サイズ次元の比率が 2 を超えません。ポルノや冒涜的な行為の検出を引き起こす画像は除外されます。最終的に、これらのフィルターは 65% を超える候補データを除外しました。
2: テキストベースのフィルタリング
このアルゴリズムは、HTML Web ページから説明テキスト (代替テキスト) を取得し、非説明テキスト (SEO タグやハッシュタグなど) を含むタイトルを削除し、ポルノ、罵り言葉、冒涜、プロフィール写真などの事前設定された指標に基づいて注釈を付けます。 . 、フィルタリングされます。最終的に、3% の候補テキストのみが審査を通過しました。
画像コンテンツとテキスト コンテンツに基づいた個別のフィルタリングに加えて、テキスト タグが画像コンテンツにマップされていないデータもフィルタリングされます。
Google Cloud Vision API を通じて提供される分類子を使用して、画像にクラス ラベルを割り当てます。
3: テキスト変換と超語彙化
データセット収集プロセス中に、約 10 億の英語 Web ページから 50 億以上の画像が処理されました。高精度のフィルタリング基準では、0.2% の画像とタイトルのペアのみがフィルタリングを通過し、残りのタイトルは固有名詞 (人物、場所、場所など) が含まれているために除外されることがよくありました。
著者は、ハイパー同期されていない代替テキスト データで RNN ベースの字幕モデルをトレーニングし、出力例を次の図に示しました。

モデル出力の説明: 歌手のジャスティン ビーバーが MGM のビルボード ミュージック アワードでパフォーマンスします
チームは、Google Cloud Natural Language API を使用して、名前付きエンティティと構文依存関係のアノテーションを取得しました。次に、Google Knowledge Graph (KG) 検索 API を使用して、名前付きエンティティと KG エントリを照合し、関連する上位用語を利用します。
たとえば、「Harrison Ford」と「Calista Flockhart」はどちらも名前付きエンティティとして識別されるため、対応する KG エントリと照合されます。これらの KG エントリには接続詞として「actor」があり、この接続詞は元の表面タグを置き換えるために使用されます。
成果の評価
データセットのテストセットから、チームは4000 例のサンプルがランダムに抽出され、手動で評価されました。 3 つのアノテーションのうち、90% を超えるアノテーションが過半数の良い評価を獲得しました。
チームは、COCO によってトレーニングされたモデルと Conceptual によってトレーニングされたモデルの違いを比較しました。
で、1 つ目の違いは、Conceptual に基づいたトレーニング結果は、自然の写真に基づいた COCO のトレーニング結果よりも社会性が高いことです。
たとえば、以下の一番左の画像では、COCO でトレーニングされたモデルは画像内の人々を指すのに「男性のグループ」を使用していますが、コンセプトでトレーニングされたモデルはより適切で有益な用語「卒業生」を使用しています。

2 番目の違いは、COCO でトレーニングされたモデルが、多くの場合、それ自体で「関連付け」られ、何もないところからいくつかの記述を「作り上げ」ているように見えることです。たとえば、最初の写真では「建物の前にいる」という幻覚があり、2 番目の写真では「時計と 2 つのドア」という幻覚がありました。 「建物の前」; 3 番目の画像は、誕生日ケーキのような錯覚を生み出します。対照的に、チームのモデルではそのような問題は見つかりませんでした。
3 番目の違いは、適用可能な画像タイプが異なることです。COCO には自然画像のみが含まれているため、上の図の 4 番目のような漫画画像は、「ぬいぐるみ」、「魚」、「車の側面」など、COCO でトレーニングされたモデルに「連想」干渉をもたらします。のようなものは存在しません。対照的に、概念でトレーニングされたモデルは、これらの画像を簡単に処理できます。
DALL-E モデルの発表により、この分野の多くの研究者も「データこそが AI の基礎である」と嘆きました。あなたも奇跡を勢いよく起こしてみませんか? Conceptual Captions データセットから始めましょう。
アクセス https://orion.hyper.ai/datasets またはクリックしてください元の記事を読む、さらに多くのデータセットを取得できます。
ニュースソース:
https://openai.com/blog/dall-e/
DALL-E の論文アドレス:
https://arxiv.org/abs/2102.12092
DALL-E プロジェクトの GitHub アドレス:
https://github.com/openai/dall-e
概念的なキャプションの論文アドレス:








