Command Palette
Search for a command to run...
浙江大学チームが新しい3Dビュー合成手法を公開、その効果はNeRFやNVをはるかに超える
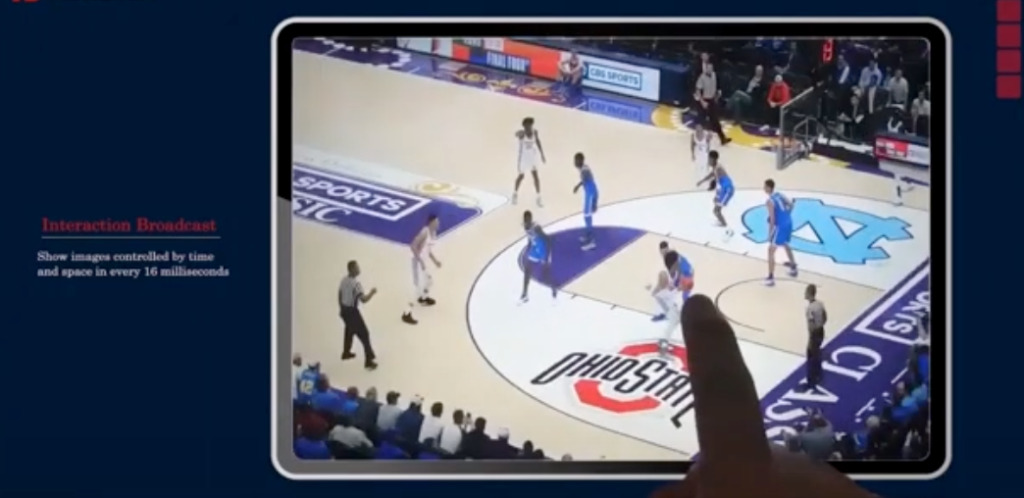
さまざまな視点からのほんの数本のビデオだけで、死角なく人体全体の画像を 360 度構築できるようになり、AI の脳補正機能はますます強力になっていると言わざるを得ません。このようなツールは、将来、映画やテレビ業界、スポーツ番組のプレゼンテーションに新たなブレークスルーをもたらす可能性があります。
将来的には、映画やサッカー、コンサートなどの観方が「自由視点映像」によって一変するかもしれません。
「無料視聴ビデオ」が何なのかご存じないかもしれませんが、VR や AR 動画を体験したり、3D ゲームをプレイしたりしたことはあるはずです。これらはすべて無料視聴ビデオのカテゴリに属し、その特徴は次のとおりです。どの角度からでも見ることができ、完全に没入感のある外観と感触を提供します。

いったいどうやってこのようなビデオを撮ることができるのでしょうか?一般に、従来の方法では、複数のカメラで異なる角度から撮影し、すべての角度からのビデオを組み合わせる必要があります。

しかし、この方法は複数のカメラを使用するため、コストがかかるだけでなく、撮影場所の環境にも制限があります。
これらの制限を解除する別の方法があります。いくつかの角度から撮影した人体のショットを数枚入力するだけで、人体の新しい 360° 3D ビューを合成します。これは浙江大学の研究者らが最近発表した最新の結果だ。
12 月末、チームは arxiv に関する新しい論文を発表しました。「ニューラルボディ:動的人間の斬新なビュー合成のための構造化潜在コードを備えた暗黙的神経表現」は、まばらなマルチビュー ビデオを使用して新しい動的 3D 人体ビューを合成する、新しい人体表現 Neural Body を提案しました。実験による検証の結果、この方法は他の以前の方法よりも優れていることがわかりました。
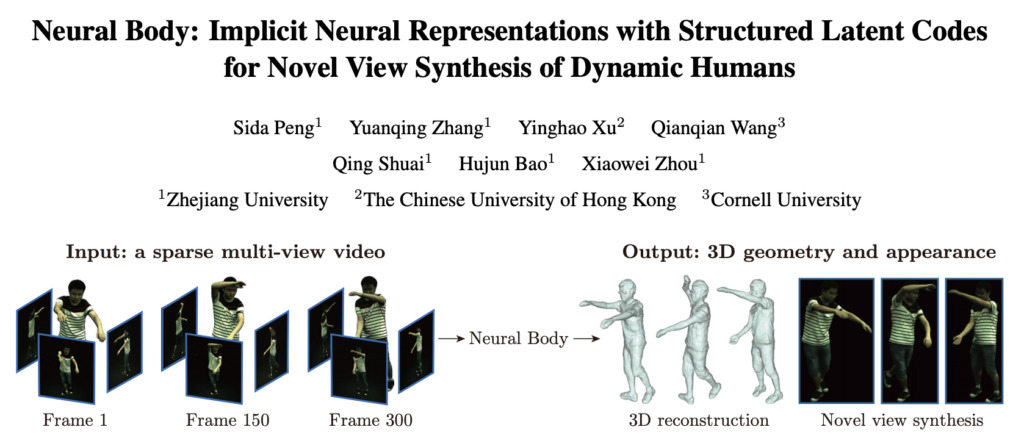
論文アドレス: https://arxiv.org/pdf/2012.15838.pdf
この論文の執筆者 7 人は全員、浙江大学を卒業または卒業しており、浙江大学のコンピュータ支援デザインおよびグラフィックスの国家重点研究所の出身であることは言及する価値があります。その中で、Hujun Bao (Bao Hujun) と Xiaowei Zhou (周 Xiaowei) はどちらも研究室の教授であり、Yinghao Xu (Xu Yinghao) と Qianqian Wang は香港中文大学で博士号を取得しました。それぞれコーネル大学。
少量のマテリアルでも高品質の 3D ビューを生成できます。
現在、映画であれ、テレビ番組であれ、スポーツ観戦であれ、私たちが見ているのは一台のカメラで撮影された映像です。もし「無料で視聴できる動画」を手に入れて、好きな場所で視聴できたら、それは間違いなく神のような体験となるでしょう。
実際、AI も近年この問題を研究しており、NeRF やニューラル ボリューム (NV) などのビュー合成ソリューションを開発しています。
ただし、既存の研究では、高密度入力ビュー条件下では、3D シーンの暗黙的ニューラル表現を学習することで良好なビュー合成品質を達成できることが示されています。ただし、ビューが非常にまばらな場合、表現学習は不適切な状態になります。

そこで、この不適切な問題を解決するために、浙江大学、香港中文大学、コーネル大学の研究チームは、ビデオフレーム上の観測結果を統合するという重要なアイデアを提案しました。
チームの最新の研究結果の中で、Neural Body が提案されています。これは、異なるフレームで学習された神経表現が、変形可能なグリッドに固定された同じ潜在コードのセットを共有することを前提とした新しい人体表現であり、フレーム間の観察を自然に統合できます。変形可能なメッシュは、3D 表現をより効率的に学習するための幾何学的ガイドもネットワークに提供します。

研究者らは、新たに収集したマルチビュー データセットで実験を実施し、この方法がビュー合成の品質の点で以前の方法に比べて大きな利点があることを示しました。
デモデモでチームは、さまざまな動作をするキャラクターの単眼ビデオから動くキャラクターを再構築するこの方法の能力を実証した。

この方法は、フリービュー ビデオ合成のコストを大幅に削減し、少なくともカメラのコストを節約できるため、より幅広い適用可能性があります。
5 つのステップで Neural Body を取得
1. 構造化された潜在コード
潜在コードの空間位置と人間の姿勢を制御するために、研究チームはこれらの潜在コードを変形可能人体モデル (SMPL) に固定しました。 SMPL は、SMPL 座標系に対する形状パラメータ、姿勢パラメータ、および剛体変換関数として定義されるスキン頂点に基づくモデルです。
潜在コードは、ニューラル ネットワークとともに、人の局所的な形状と外観を表現するために使用されます。これらのコードを変形可能なモデルに固定すると、動的な人物を表現できます。動的な人間の表現を使用して、チームは、同じ潜在コードのセットを異なるフレームにわたる密度と色の暗黙の領域にマッピングする潜在変数モデルを構築し、観察を自然に統合しました。
2. コードの拡散
構造化された潜在コードは 3 次元空間では比較的まばらであるため、潜在コードを直接補間すると、ほとんどの 3 次元点のベクトルがゼロになります。この問題を解決するために、チームは表面に定義された潜在コードを近くの 3 次元空間に拡散しました。
コードの普及は世界座標系における人の位置と向きに影響されるべきではないため、コードの位置を SMPL 座標系に変換しました。
コード拡散では、構造化された潜在コードのグローバル情報とローカル情報も収集され、暗黙のドメインを学習するのに役立ちます。
3. 密度と色回帰
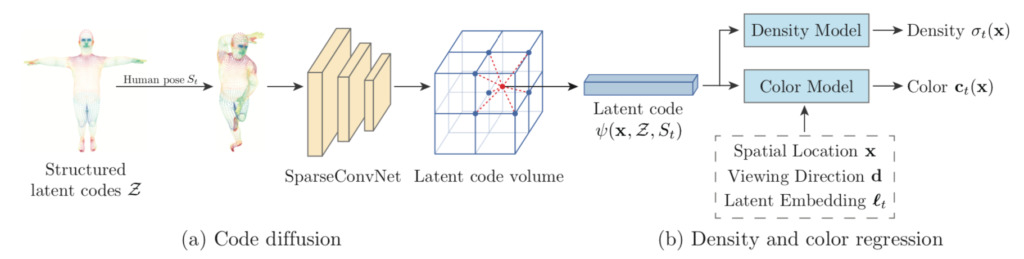
研究チームは、二次照明やセルフシャドウイングなど、時間とともに変化する要因が人体の外観に影響を与える可能性があることを発見しました。自動デコーダにヒントを得て、チームは各ビデオ フレームに潜在的な埋め込みフレーム t を割り当て、時間的に変化する要素をエンコードしました。
4. ボリュームレンダリング
研究チームは、特定の視点で、古典的なボリューム レンダリング (3 次元レンダリングとも呼ばれる) テクノロジーを使用して、神経体を 2 次元画像にレンダリングしました。
次に、SMPL モデルに基づいてシーンの境界が推定され、Neural Body がこれらの点のボリューム密度と色を予測します。
ボリュームレンダリングに基づいて、レンダリング画像と観察画像を比較することでモデルを最適化しました。
5. トレーニング
フレームベースの再構成方法と比較して、この方法はビデオ内のすべての画像を利用してモデルを最適化し、3D 構造を復元するためのより多くの情報を取得します。
さらに、チームは Adam オプティマイザーを使用して Neural Body をトレーニングします。トレーニングは 4 つの 2080 Ti GPU で実行されます。合計 300 フレームの 4 ビュー ビデオの場合、トレーニングには通常約 14 時間かかります。
上記の 5 つのステップを経て、Neural Body は少数のビューに基づいてフリービュービデオ合成を実現でき、他の方法と比較して効果は前者よりも大幅に優れています。
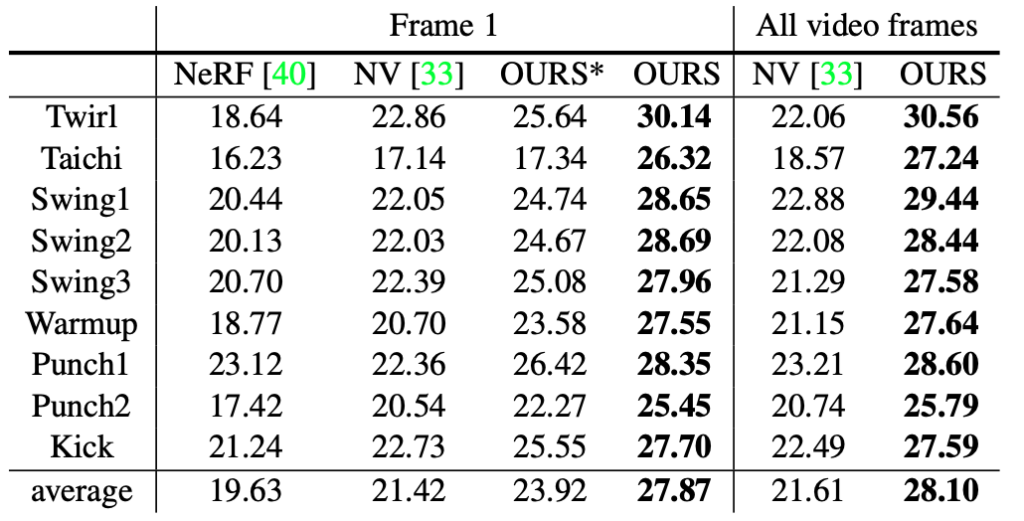
注: 「OURS*」と「OURS」は、それぞれビデオの 1 フレームのみと 4 フレームのトレーニングの結果を表します)
AI の脳補正テクノロジーにより、3D 効果をより簡単に実現できるようになり、そのアプリケーションは映画やテレビ業界、ライブ スポーツ イベントに限定されず、ゲーム開発者、フィットネス インストラクター、3D 広告プロバイダーなどにも応用されているツールです。作業効率と有効性が大幅に向上します。

プロジェクトのホームページ:








