Command Palette
Search for a command to run...
漫画翻訳と埋め込みテキストAI、東大の論文がAAAI'21に掲載されました

最近、漫画テキストの自動翻訳に関する研究が白熱した議論を引き起こした。東京大学の博士号取得者2名で構成されるMantraチームが論文を発表し、その論文はAAAI 2021に掲載された。Mantraプロジェクトは日本人に自動化を提供することを目的としている。漫画の機械翻訳ツール。
最近、東京大学の Mantra チーム、Yahoo (日本) およびその他の機関によって共同リリースされました。 「マンガの全自動翻訳を目指して」(論文アドレス https://arxiv.org/abs/2012.14271)この論文は学術界および二次元界の注目を集めました。

Mantra チームは実装に成功しましたコミック内の会話、ムードワード、ラベルなどのテキストを自動的に認識し、文字を区別し、コンテキストを接続し、最終的に翻訳されたテキストを吹き出し領域に正確に置き換えて埋め込みます。
この翻訳成果物により、翻訳チームとコミックをフォローしている友人たちは楽しい時間を過ごすことができると推測されます。
論文出版からデータセット公開、商品化までのワンストップサービス
科学研究の観点から、この論文はAAAI 2021に採択されました。研究チームはまた、異なるスタイル(ファンタジー、恋愛、バトル、サスペンス、ライフ)の5つの漫画からなる翻訳評価データセットをオープンソース化しました。
OpenMantra コミック翻訳評価データセット
用紙のアドレス:https://arxiv.org/abs/2012.14271
データ形式: 注釈付きの JSON ファイルと生の画像
データ内容:1593 文、848 シーン、214 ページのコミック
データサイズ:36.8MB
更新日:2020年12月7日
ダウンロードアドレス:https://orion.hyper.ai/datasets/14137
製品化という点では、Mantraはパッケージ化された自動翻訳エンジンの発売を計画しているは出版社向けにコミックの自動翻訳・配信サービスを提供するだけでなく、個人ユーザー向けのサービスもリリースしています。
以下はMantra公式Twitterから選んだ日本の漫画「Men Around Us」の翻訳結果の一部です。日常生活でよく使われるデジタルデバイスを擬人化した、楽しさとロマンに満ちた軽快で美しいマルチコマ漫画です。:
スライド「The Peripheral Man」のオリジナル日本語版をチェックしてください。
中国語版と英語版の自動機械翻訳
認識、翻訳、埋め込みはすべて実行する必要がある手順です。
具体的な実装手順については、Mantra 研究チームが論文「完全自動マンガ翻訳に向けて」で詳しく説明しています。
最初のステップはテキストを配置することです
漫画の自動翻訳を実現するための最初のステップは、テキスト領域の抽出です。
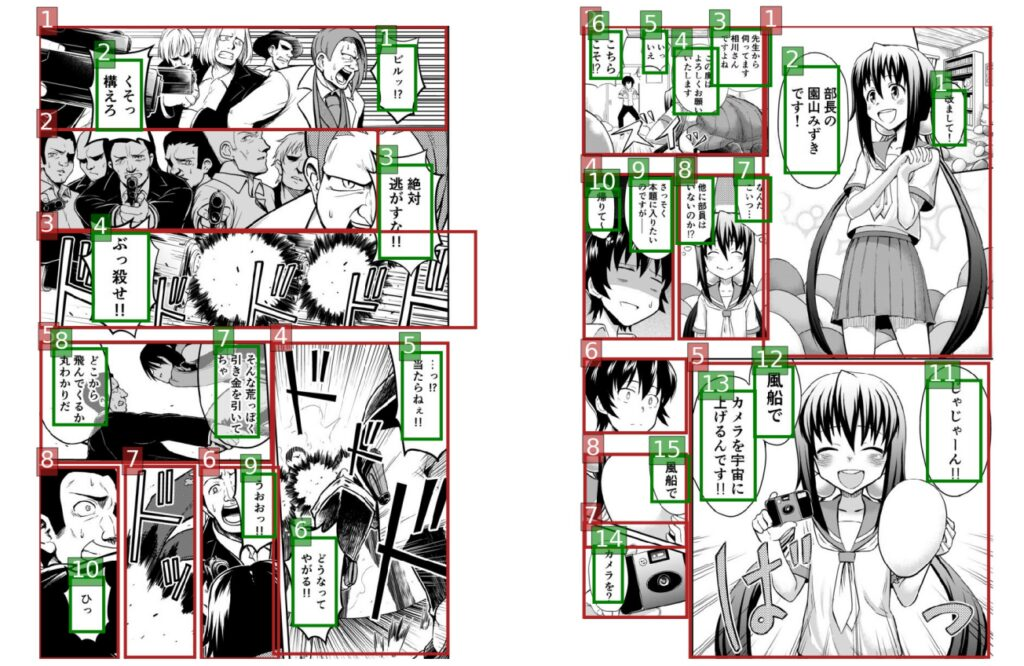
ただし、漫画の特殊性により、さまざまなキャラクターの会話、オノマトペ効果、テキストの注釈などが漫画の絵に表示され、さまざまな効果を示すために漫画家は吹き出し、さまざまなフォント、および誇張されたフォントを使用します。
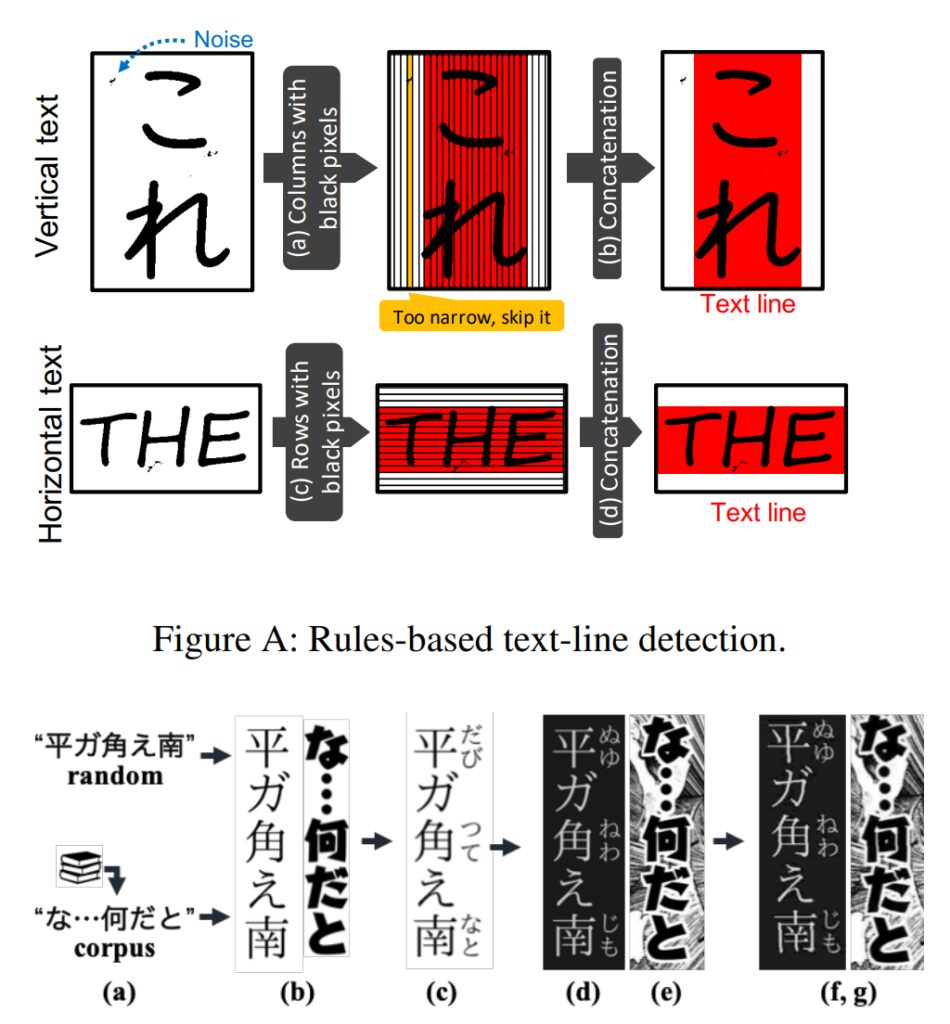
研究チームは、コミックにはさまざまなフォントや手描きスタイルがあるため、最先端の OCR システム (Google Cloud Vision API など) を使用したとしても、コミック テキストのパフォーマンスが非常に満足のいくものではないことを発見しました。
そこで、テキスト行を検出し、各行の文字を識別することで特殊な形状の文字の認識を実現する、漫画に最適化したテキスト認識モジュールを開発しました。
2 番目のステップはコンテンツの識別です。
漫画では、最も一般的なテキストはキャラクター間の会話であり、会話テキストの吹き出しも複数の部分に切り取られます。
これには、役割を正確に区別し、文脈内の主題のつながりに注意を払い、重複を避けるための自動機械翻訳が必要であり、機械翻訳に対するより高い要件が課せられます。
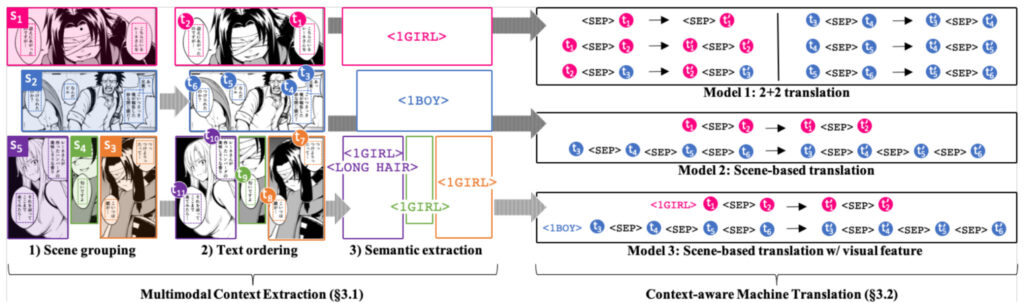
このステップでは、コンテキスト認識、感情認識などを通じてそれが実現されます。コンテキスト認識では、Mantra チームは、テキストのグループ化、テキストの読み取り順序、視覚的意味抽出の 3 つの方法を使用して、マルチモーダルなコンテキスト認識を実現しました。
3番目のステップは、文字を自動的に埋め込むことです
自動化エンジンである Mantra は、文字を区別し、文脈に基づいて正確に翻訳できるだけでなく、コミック翻訳で最も時間と労力がかかるリンクである埋め込みも解決します。

文字を象嵌する作業は、まず象嵌部分を消してから文字を象嵌する必要があり、日本語、中国語、英語の文字は形、綴り、組み合わせ、読み方が異なるため、特に大変な作業となります。
このステップでは、ページマッチング→テキストボックス検出→テキストバブルのピクセル統計→接続されたバブルの分割→言語間の位置合わせ→テキスト認識→コンテキスト抽出を実行する必要があります。
実験: データセットとモデルのテスト
論文の実験部分で、Mantra チームは、現在複数の言語を含むコミック データ セットが存在しないと述べたので、OpenMantra (オープン ソース) と Pubmanga データ セットを作成しました。 OpenMantra は機械翻訳の評価に使用されており、1593 の文、848 のシーン、214 ページの漫画が含まれています。Mantra チームは、データセットを英語と中国語に翻訳するためにプロの翻訳者を雇いました。

Pubmanga データセットは、次の注釈を含む構築されたコーパスを評価するために使用されました: 1) テキストとフレームの境界線、2) 日本語と英語のテキスト (文字列)、3) フレームとテキストの読み上げ順序。
モデルをトレーニングするために、チームは次の準備をしました 日英マンガページ数842097ページ、日英文章合計3979205ペア。具体的な方法は論文で読むことができます。最終的なモデルの効果評価は Mantra チームが手動で行います。プロの日英翻訳者5名、プロの翻訳評価プログラムを使用して文章を採点します。
プロジェクトの裏側: 興味深い魂が一緒に学びます
現在、この論文はAAAI 2021に掲載されており、製品化作業も着々と進んでいます。MantraチームのTwitterからは、多くの漫画が自動機械翻訳にMantraを使用することに成功していることがわかります。
このような宝のプロジェクトは、東京大学博士課程を卒業し、2020年にMantraチームを設立したCEOの石渡祥之助氏とCTOの日南良太氏の二人によって完成されました。

代表取締役社長 石和尚之助私は2010年に東京大学情報科学科に入学し、2019年に博士号を取得しました。彼は主に、機械翻訳や辞書生成などの自然言語処理分野の研究開発に焦点を当てており、この論文の 2 人目の著者です。
特筆すべきは、石和尚之助氏はCMUへの交換留学だけでなく、2016年から2017年にかけて北京のMicrosoft Research Asiaで半年間インターンをし、豊富な研究経験を持っているということです。 MSRA 主任研究員 Liu Shujie (自然言語コンピューティング) のチームの NLC。自然言語コンピューティングの研究。
CTOの日南良太子と祥之助が同年に入学し、画像認識分野に注力。2016 年から 2017 年にかけて、私はマイクロソフト リサーチ アジアで石さんと祥之助とともにインターンをしました。
補完的なスキルを備えたこのペアのパートナーが、量から結果までマントラの仕事のほとんどを完了したのは羨ましいことではないでしょうか。
Mantra についてさらに詳しく知りたい場合は、論文 (https://arxiv.org/abs/2012.14271)、プロジェクト公式サイト(https://mantra.co.jp/)またはデータセットをダウンロードする(https://orion.hyper.ai/datasets/14137)、さらなる研究のために。








